基于隐Markov模型的视频行为活动识别关键算法的制作方法
本发明涉及一种活动识别算法。
背景技术:
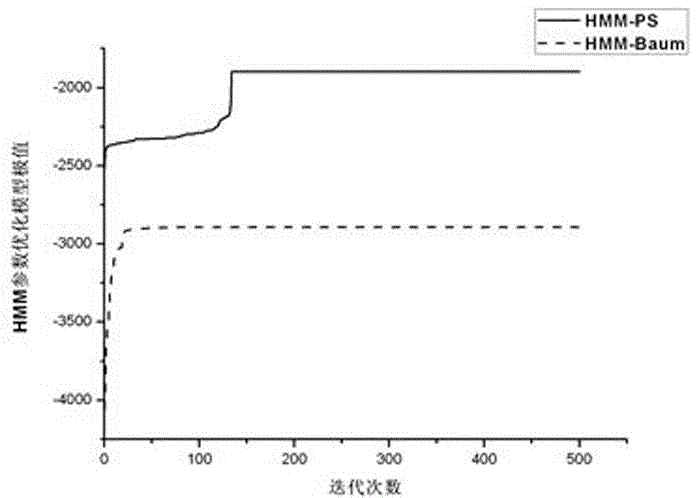
:随着多媒体技术和信息技术的发展,众多的研究领域如智能监控、感知接口、基于内容的视频检索等,对视频内容智能分析的要求越来越高,因此近年来多媒体信息的内容理解和分析引起了越来越多的学者关注。基于人体运动的视觉行为分析系统一般遵从以下的处理流程,如图1所示:(1)运动目标检测,(2)目标分类,(3)目标跟踪,(4)视频行为理解与描述。其中,运动检测、目标分类、目标跟踪属于视觉中低级和中级处理部分,而行为理解和描述则属于高级处理。而PSO算法基本思想:粒子群优化(ParticleSwarmOptimization,PSO)由Kennedy和Eberhart在1995受鸟群和鱼池社会和认知行为启发而提出。令PSO初始化为一群随机粒子,在每一次迭代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最好解,叫做个体极值点(用x_pbest表示其位置),全局版PSO中的另一个极值点是整个种群目前找到的最好解,称为全局极值点(x_gbest表示其位置),而局部版PSO不用整个种群而是用其中一部分作为粒子的邻域,邻域的最优解就是局部极值点(用x_lbest表示其位置)。在找到这两个最优解后,粒子根据公式(4-l3)和(4-14)来更新自己的速度和位置。粒子i的信息可以用N维向量表示,位置表示为Xi=(xi1,xi2,…,xin),速度为Vi=(vi1,vi2,…,vin),其它向量类似。公式(4-l3)和(4-14)是其速度和位置的更新方程(对局部PSO,用x_lbest替换(4-l3)中的x_gbest):vid(k+1)=w*vid(k)+c1*rand()*[pbestid(k)-xid(k)]+c2*Rand()*[gbestgd(k)-xid(k)](4-13)xid(k+1)=xid(k)+vid(k+1)(4-14)其中,w为权值系数,其更新如下式:w=(wfinal-winitial)(max_gen-gen)nmax_genn+winitial---(4-15)]]>其中,winitial初始权值系数,wfinal线性下降末端的权值系数,max_gen是最大的搜索迭代次数,gen是当前的迭代次数,n为常量系数。式中vid是粒子i在第k次迭代中第d维的速度;cl和c2是学习因子,分别可以调节当前粒子向全局最优粒子和个体最优粒子方向飞行的最大步长。若太小,则粒子可能远离目标区域,若太大则会导致突然向目标区域飞去,或飞过目标区域。合适的cl和c2可以加快收敛且不易陷入局部最优。rand和Rand是[0,1]之间的随机数;xid是粒子i在第k次迭代中第d维的当前位置;pbestid是粒子i在第d维的个体极值点的位置;gbestgd是整个粒子群的全局极值点在第d维的位置。基本PSO的流程可以描述为:Step1.随机初始化种群的大小、位置xi及其速度值vi,初始化每个粒子的x_pbest和计算种群最优值x_gbest;Step2.结束条件不满足时循环执行:根据公式(4-13)和(4-14)对每个粒子的速度和位置进行更新;计算每个粒子的适应度值fitness(xi),如果fitness(xi)>x_pbesti,则将x_pbesti=fitness(xi)。如果max(fitness(xi))>x_gbesti,则x_gbesti=max(fitness(xi)),并记录该粒子的索引。以上即为PSO的基本流程,HMM的学习问题主要在于参数模型λ=(A,B,π)的求解,从而使得对于给定的观察值序列O={o1,o2,...,oT},都能满足P(O|λ)最大。求解λ使得P(O|λ)最大的问题是一个泛函极值问题,由于给定的训练数据有限,暂时没有一个最佳的方法来估计λ。Baum-Welch估计算法利用递归的思想,通常只能求得P(O|λ)达到局部极大,其参数的学习训练不够充分,会对HMM的识别正确率有较大影响。PSO算法利用进化计算技术和群体智能的概念,根据个体的适应值在解空间中进行搜索求得优化问题的最优解。该方法不需要函数的导数信息及连续性要求,执行简单而能快速收敛到最优解。离散的HMM模型参数的学习问题可以看成约束优化问题:maxP(O|λ)=max(Σi=1NΣj=1Nαt(i)aijbj(Ot+1)βt+1(j)),1≤t≤T-2---(4-16)]]>St.∀i,j,t,πi≠1,aij≠1,bj(Ot+1)≠1,]]>πi≥0,aij≥0,bj(Ot+1)≥0,Σjπj=1,Σi,jaij=1,Σj,tbj(Ot+1)=1]]>而由于本文使用观测向量为运动轨线的特征信息,其观测向量为连续值,因此,应该采用连续的HMM模型进行参数训练。技术实现要素:有鉴于此,本发明第一目的是提供一种PSO改进的HMM学习方法。本发明第二目的是提供一种HMM结构的最优参数判断方法。本发明第三目的是提供一种基于视频人体运动的行为活动建模方法。本发明第四目的在于提供一种基于PSO的隐Markov模型参数学习算法。为了解决上述技术问题,本发明的技术方案是:为了实现本发明的第一目的,提供一种PSO改进的HMM学习方法,步骤1,采用新的目标优化函数log(P(O|λ))构建优化模型;步骤2,对粒子位置的向量X=(x1,…,xN*N+3N*M*D+N),如果X满足约束条件,则跳出,如果xi<Xmin,则xi=Xmin-xi;若xi>Xmax,则xi=Xmax;步骤3,如果X满足约束条件,则跳出,若则xi=1/N,其中k={0,…,N-1};步骤4,如果X仍然不满足约束条件,则采用归一化方法对粒子位置进行修正,定义X为违反约束条件的粒子位置,X*为修正后的粒子位置,其公式描述如下:对转移矩阵A,即粒子的前N2维:1≤i≤N,k={0,…,N-1};对表示权值系数c的维数,即粒子的N2+1到N2+N*M*D维:N2+1≤i≤N2+N*M*D;对表示协方差矩阵Σ的维数,即粒子的N2+N*M*D+1到N2+2N*M*D维:N2+N*M*D+1≤i≤N2+2N*M*D;对HMM的初始分布π,即粒子的后N维:N2+3N*M*D+1≤i≤N2+3N*M*D+N。进一步地,所述优化模型为各态遍历模型。为了实现本发明的第二目的,提供一种HMM结构的最优参数判断方法,步骤1,初始化种群的大小,定义粒子位置xi为HMM的参数结构,初始化速度值vi且满足Vmin≤vi≤Vmax,初始化每个粒子的x_pbest为当前位置,计算种群最优值x_gbest;步骤2,步骤2-1,根据速度和位置公式对每个粒子的速度和位置进行更新,并判断粒子是否满足约束条件,如满足则进入步骤三,如果不满足,则通过FV算法对粒子进行可行性检验;步骤2-2,根据公式1≤t≤T-2计算每个粒子的目标函数f(xi),如果f(xi)>x_pbesti,则将x_pbesti=f(xi),记录该粒子为局部最优粒子;如果max(f(xi))>x_gbesti,则x_gbesti=max(f(xi)),并记录该粒子的索引为全局最优粒子;步骤3,记录全局最优粒子的位置为HMM结构的最优参数。为了实现本发明的第三目的,提供一种基于视频人体运动的行为活动建模方法,步骤1,对每一个行为活动类,至少定义一个HMM模型;步骤2,根据确定的拓扑结构和参数,通过如权利要求1中所述的一种PSO改进的HMM学习方法进行参数训练,确定每一个HMM结构参数;步骤3,计算训练样本的事件概率序列。进一步地,步骤3中,计算方法如下,步骤3-1,得到K个候选事件概率序列;步骤3-2,通过DTW算法对测试的事件概率序列的匹配得到识别结果。进一步地,步骤3-2中,DTW算法具体实现如下,步骤3-2-1,依次将测试序列通过HMM建模;步骤3-2-2,通过公式计算每个候选概率序列与该类运动的平均距离D(Ci,ecj),其中,NCi表示Ci活动类的训练样本得到的事件概率序列数,Ci表示第i个行为活动,而ek表示属于Ci的事件概率序列,D(ek,ecj)表示根据式(4-20)计算得到的两个事件概率序列的路径距离;步骤3-2-3,根据公式Opt*=argminD(Ci,ecj)计算最短的距离确定最优的测试事件概率序列并识别出行为运动的模式。为了实现本发明的第四目的,提供一种基于PSO的隐Markov模型参数学习算法,步骤1,从视频序列中提取行为活动的目标运动轨线特征,利用隐Markov模型以语义事件概率的方式对行为活动进行表示,完成对行为活动的建模;步骤2,如权利要求4中所述的一种基于视频人体运动的行为活动建模方法计算样本的时间概率序列;步骤3,采用时间规整法对视频人体运动建模得到的事件概率序列进行匹配以识别目标行为活动。进一步地,步骤1中,提取行为活动的目标运动轨线特征方法如下,步骤1-1,运动曲线方程可以定义为:r(t)=[x(t)y(t)t],其中1≤t≤n,n为视频序列的时间帧数;步骤1-2,通过曲率量化步骤1-1中的特征,得其中,r’(t),r”(t),||r’(t)||分别表示轨线速率,加速度和速度;步骤1-3,通过速度向量公式和加速度向量公式化简得到k(t)=y′′(t)2+x′′(t)2+(x′(t)y′′(t)-x′′(t)y′(t))2y′(t)2+x′(t)2+13.]]>本发明技术效果主要体现在以下方面:首先从视频序列中提取行为活动的目标运动轨线特征,利用隐Markov模型以语义事件概率的方式对行为活动进行表示,从而完成对行为活动的建模。同时,基于粒子群优化算法对隐Markov模型中的参数学习算法进行改进,使得HMM的学习问题可以跳出局部最优,并有效解决传统参数估计方法的数据溢出问题。然后,采用时间规整法对视频人体运动建模得到的事件概率序列进行匹配以识别目标行为活动。通过CentralFlorida大学的人体运动数据集(UCFHumanActionDataset)和来自UCI-KDD的ASL(AustraliaSignLanguage)复杂运动轨迹数据集实验表明,本文提出的方法与Baum-Welch参数估计方法相比,在行为建模的学习性能上具有较高的优越性,在识别率上取得更好的结果。附图说明图1:本发明视觉行为识别框架图;图2:本发明基于事件概率法的行为识别系统框架图;图3:本发明视频人体运动参数训练算法流程图;图4:本发明视频人体运动的参数学习过程示意图;图5:本发明视频人体运动的测试过程示意图;图6:本发明采用DTW的事件概率匹配过程示意图;图7:拾起粉笔擦-擦黑板-放下粉笔擦的行为活动轨线图;图8:对于图7(a)的事件概率序列;图9:对于图7(b)的事件概率序列;图10:PSO和BaumWelch对行为Pourwater建模时的参数模型极值;图11:PSO和BaumWelch对行为Closedoor建模时的参数模型极值;图12:不同事件粒度参数下的行为活动平均识别率比较图;图13:符号alive的在不同视角下的手势活动轨线;图14:符号alive在不同视角下的事件概率序列。具体实施方式以下结合附图,对本发明的具体实施方式作进一步详述,以使本发明技术方案更易于理解和掌握。1理论介绍,在运动特征的表示中,运动轨迹的变化可以反映目标的方向、速度以及位置等信息,因此运动轨线给行为活动的建模和识别提供了很重要的特征描述。时间和空间上运动轨线的显著变化与语义事件的变化是紧密联系的,因此可以通过对运动轨线的信息挖掘提取语义事件,并以这些事件的概率序列来表示行为活动。本章通过对运动轨线特征的提取,提出基于PSO改进的隐Markov模型视频人体运动对运动轨线进行分析建模,提出基于PSO的隐Markov模型参数学习算法.这个是需要保护的从而得到行为活动的事件概率序列表示模型。然后采用动态时间规整法对视频人体运动模型计算得到的事件概率序列进行匹配,以对行为活动进行识别。本文的行为活动识别方法框架如图2所示。1.1HMM的学习问题,由前面推导可知,HMM的学习问题主要在于参数模型λ=(A,B,π)的求解,从而使得对于给定的观察值序列O={o1,o2,...,oT},都能满足P(O|λ)最大。求解λ使得P(O|λ)最大的问题是一个泛函极值问题,由于给定的训练数据有限,暂时没有一个最佳的方法来估计λ。Baum-Welch估计算法利用递归的思想,通常只能求得P(O|λ)达到局部极大,其参数的学习训练不够充分,会对HMM的识别正确率有较大影响。PSO算法利用进化计算技术和群体智能的概念,根据个体的适应值在解空间中进行搜索求得优化问题的最优解。该方法不需要函数的导数信息及连续性要求,执行简单而能快速收敛到最优解。离散的HMM模型参数的学习问题可以看成约束优化问题:maxP(O|λ)=max(Σi=1NΣj=1Nαt(i)aijbj(Ot+1)βt+1(j)),1≤t≤T-2---(4-16)]]>St.∀i,j,t,πi≠1,aij≠1,bj(Ot+1)≠1,]]>πi≥0,aij≥0,bj(Ot+1)≥0,Σjπj=1,Σi,jaij=1,Σj,tbj(Ot+1)=1]]>而由于本文使用观测向量为运动轨线的特征信息,其观测向量为连续值,因此,应该采用连续的HMM模型进行参数训练。同时,考虑到传统HMM的前向概率计算中的数据溢出问题,因此采用新的目标优化函数log(P(O|λ)),在多观察序列情况下,其参数的优化模型如下:maxlog(Πk=1KP(Ok|λ))=maxΣk=1KlogP(Ok|λ)=maxΣk=1Klog(Σi=1NΣj=1Nαt(i)aijbj(Ot+1k)βt+1(j))---(4-17)]]>其中,St.∀1≤i,j≤N,1≤m≤M,πi≠1,aij≠1,]]>πi≥0,aij≥0,cjm≥0,Σjm≥0,Σjπj=1,Σi,jaij=1,Σj,mcjm=1]]>针对上式的函数优化问题,在本文中HMM结构采取各态遍历模型,因此,转移概率矩阵A中系数aij都是正值,且维数为N2。另外,令观测向量的特征维数为D,则待优化的参数λ=(A,B,π)可以看成粒子群优化算法中的粒子,即X=λ=({aij},{cjm,μjm,Σjm},{πi})=(x1,…,xN*N,xN*N+1,…,xN*N+3N*M*D,xN*N+3N*M*D+1,…,xN*N+3N*M*D+N),其粒子的维数为N2+3N*M*D+N,其中前N2维表示转移矩阵A,从N2+1到N2+3N*M*D维表示观察概率密度函数的参数,后N维表示初始概率分布π。由于该优化问题为带约束问题,因此粒子的可行搜索会受到约束条件的限制。在本文中,采用修复的策略对违反约束的粒子进行修正,即如果粒子在迁移过程中违反约束条件,则通过修正算法将其映射到可行空间,本文设计的修正算法如下。1.2PSO粒子可行空间修正算法FV(FeasibilityVerification):Step1:对粒子位置的向量X=(x1,…,xN*N+3N*M*D+N),如果X满足约束条件,则跳出。如果xi<Xmin,则xi=Xmin-xi;若xi>Xmax,则xi=Xmax。Step2:如果X满足约束条件,则跳出。若则xi=1/N,其中k={0,…,N-1}。同理,对其它表示参数cjm,πi的变量x以同样方式处理。Step3:如果X仍然不满足约束条件,则采用归一化方法对粒子位置进行修正,定义X为违反约束条件的粒子位置,X*为修正后的粒子位置,其公式描述如下:对转移矩阵A,即粒子的前N2维1≤i≤N,k={0,…,N-1}对表示权值系数c的维数,即粒子的N2+1到N2+N*M*D维:N2+1≤i≤N2+N*M*D对表示协方差矩阵Σ的维数,即粒子的N2+N*M*D+1到N2+2N*M*D维:N2+N*M*D+1≤i≤N2+2N*M*D对HMM的初始分布π,即粒子的后N维:N2+3N*M*D+1≤i≤N2+3N*M*D+N通过上述可行修正算法FV后,不满足约束条件的粒子其解空间可以得到修正,从而确保在可行解空间中。1.3基于PSO的HMM参数优化算法视频人体运动可以描述如下所示,其算法流程图如图3所示:Step1.初始化种群的大小,定义粒子位置xi为HMM的参数结构,初始化速度值vi且满足Vmin≤vi≤Vmax,初始化每个粒子的x_pbest为当前位置,计算种群最优值x_gbest;Step2.满足结束条件时转Step3,否则循环执行下列步骤:2.1根据公式(4-13)和(4-14)对每个粒子的速度和位置进行更新,并判断粒子是否满足约束条件,如果不满足,则调用算法FV对粒子进行可行性检验;2.2根据公式(4-16)计算每个粒子的目标函数f(xi),如果f(xi)>x_pbesti,则将x_pbesti=f(xi),记录该粒子为局部最优粒子。如果max(f(xi))>x_gbesti,则x_gbesti=max(f(xi)),并记录该粒子的索引为全局最优粒子;Step3.记录全局最优粒子的位置为HMM结构的最优参数。基于视频人体运动的行为活动建模主要包括HMM结构的学习训练过程和测试过程,其示意图分别如图4和5所示。对每一个行为活动类,至少定义一个HMM模型,也可以根据不同的事件尺度参数p定义多个HMM。在学习过程中,对每一个HMM模型,确定其基本的拓扑结构和参数,并用PSO优化算法进行HMM的参数训练,从而确定每一个HMM结构参数,并计算出训练样本的事件概率序列。在测试过程,运动轨线的测试序列O0经过各行为活动类对应的HMM模型(假设有K个),由公式(4-12)可以计算得到K个候选事件概率序列,并通过DTW算法对测试的事件概率序列的匹配得到识别结果。1.4参数研究,在本节中,主要讨论基于视频人体运动的行为活动建模方法的参数选择问题,比如HMM的隐含状态数N,基于事件概率建模的参数p,以及视频人体运动中相关的PSO参数。1.4.1隐含状态数N,采用HMM建模,首先需要确定隐含状态数,从而才能通过参数训练的方法进一步确定状态转移概率等其他参数。在状态数N的选取问题上,已经有许多学者提出了相关的准则。在此采用贝叶斯信息准则(BayesianInformationCriterion,BIC)的经验公式作为参数选择的基准。因此,其最优的参数N*如下:N*=argminN∈N(Logl(N)+kN2logT)---(4-18)]]>其中,Logl为T帧运动轨线观测序列的负Log似然性,kN为对应于N阶模型的自由度。1.4.2事件尺度因子p,采用BIC准则的条件最优尺度参数公式,参数p*可如下式估计:p*=argminp∈P(Σt=1t=Tetp(k,l)+p2logT)---(4-19)]]>一般情况下,满足参数N*可使得运动轨线的表示方法参数最优,而p*的满足使得表示事件序列的参数最优,但两者的同时满足并不一定计算出最优的事件概率序列表示,因此在中采取求(N,p)*联合最优的参数方案。在本文,因为隐含状态的参数N直接影响建模的性能,因此优先考虑满足参数N*,而参数p*则通过实验对比的方法确定。1.4.3PSO相关参数,视频人体运动中,用于HMM学习的PSO算法的相关参数由经验值确定。公式(4-13)中的学习因子cl=1.8,c2=1.8,自适应调整权值系数winitial=0.4,wfinal=0.9。另外,种群的规模和最大迭代次数,根据需要训练的HMM规模大小而定,HMM的结构越复杂隐含状态数越多,最大迭代次数越多,而种群的规模也越大。1.5视角无关性分析,所谓的视角指观察角度,即摄像机观察运动目标的方向。在视频序列的行为识别中,观察视角的变化可以由两种原因:目标运动或者摄像机运动引起。视角变化一般有三种情况:缩放、平移和旋转。当观察视角发生变化时,动作识别变得格外困难。至今为止,关于动作识别和手势识别的大多数研究工作都是围绕着视角相关的表达展开的。有一小部分利用了视角不变的表示开展研究,可依然存在一些局限性,比如缺少用于识别的足够信息,依赖鲁棒的语义特征点的检测等。基于运动轨线的信息采用HMM对行为活动的事件概率进行建模和表述的方法,在中被证明,只要产生事件概率序列的HMMs模型是一致的,则该事件概率的生成与视角变化无关。而关于不同的HMM之间的一致性,可以定义成:如果两个HMM模型,在其状态集之间存在一个同胚映射,则它们是一致的。基于Cuntoor在文中证明的充分条件,在本文中,计算事件概率序列的HMM模型之间必须基于一致性的前提,以保证其视角无关性,以提高行为识别的准确率。1.6采用DTW的事件概率序列匹配和识别,给定一个测试序列O0,按照4.2节的方法对运动轨线进行语义事件描述。假设在测试集中有R个运动轨线,有K类行为活动,则对于给定的p值,至少采用K个HMM建模计算得到R个事件概率序列集。一般说来,用于建模的HMM模型数少于训练的运动轨线样本数。多个轨线样本可能对应于同一个HMM,但每个轨线样本只对应一个事件概率序列。R个测试样本的运动轨线,通过HMM的建模后可以得到R个候选的事件概率序列。而测试序列O0通过HMM建模后,得到K个候选的事件概率序列Ec=(ec1,ec2,…,ecK),计算每个候选概率序列与该类运动的平均距离D(Ci,ecj),计算公式如式(4-21),选取平均距离最小的事件概率序列作为最优结果,并确定该测试序列所属的行为活动模式,整个计算过程如图4-7所示。D(Ci,ecj)=Σek∈CiD(ek,ecj)NCi---(4-21)]]>其中,NCi表示Ci活动类的训练样本得到的事件概率序列数,Ci表示第i个行为活动,而ek表示属于Ci的事件概率序列,D(ek,ecj)表示根据式(4-20)计算得到的两个事件概率序列的路径距离。经过DTW用式(4-21)计算候选事件概率序列与所有行为活动类的距离,从而根据最短的距离确定最优的测试事件概率序列,如公式(4-22),并识别出行为运动的模式。Opt*=argminD(Ci,ecj)(4-22)通过CentralFlorida大学的人体运动数据集(UCFHumanActionDataset)和来自UCI-KDD的ASL(AustraliaSignLanguage)复杂运动轨迹数据集实验表明,本文提出的方法与Baum-Welch参数估计方法相比,在行为建模的学习性能上具有较高的优越性,在识别率上取得更好的结果。2.1仿真实验与分析,本章采用视频人体运动方法对行为活动进行建模,并通过对建模后的事件概率序列的匹配实现视频行为活动的识别。为了检验视频人体运动建模方法的稳健性和该方法在视频行为活动识别中的性能,本章设计了两部分的实验,即行为活动建模分析和识别性能分析。在实验仿真中,实验数据主要采用CentralFlorida大学的人体运动数据集(UCFhumanactiondataset)和来自UCI-KDD的复杂运动轨迹数据集ASL(AustraliaSignLanguage)。本文的仿真试验在2.66GHZPC、512MROM、VisualC++6.0上执行。本文采用的轨线特征为连续向量,为了在HMM模型中更准确地描述连续信号,实验中采用单高斯分布的连续HMM模型进行活动建模,其中HMM模型的观测向量为轨线的特征向量。而为了对多个样本进行参数训练并防止计算过程中数据的溢出,实验中的Baum-Welch参数估计方法采用多观测序列尺度变化的HMM模型,如上文介绍,本章中称为HMM-Baum。在HMM_PS的参数训练过程中,参数的学习问题可看成约束优化问题,并由log(P(O|λ))表示目标优化函数。实验过程充分体现视频人体运动在参数学习问题中的优越性,比如在计算过程中可以防止数据的溢出,使得HMM参数训练的泛极值问题得以跳出局部最优。2.1UCF-Humanactiondatasets数据仿真实验分析,UCF数据集为CentralFlorida大学计算机视觉实验室所采集的日常视频行为,由7个活动者在摄像机位置可变化的情况下拍摄的。本文基于该数据集所提取的运动轨线特征对日常行为活动进行识别,主要的行为活动在文献[15]中分为七类简单动作,关于数据集介绍如表2-1。表2-1UCF数据集介绍本节实验中相关参数设置主要为:隐含状态数N=7,事件粒度p=5,PSO中的最大迭代次数Maxgen=500,学习因子cl=1.8,c2=1.8,自适应调整权值系数winitial=0.4,wfinal=0.9。而HMM模型中,状态转移概率A和初始概率π随机初始化,单高斯概率密度函数的均值矢量和协方差矩阵,通过K均值聚类得到,即将已经聚为一个轨迹模式类的观察序列值依据K均值自动聚类,类的个数取为HMM模型的状态个数N。2.1.1行为活动建模分析,本文采用事件概率方式对行为活动进行建模,通过采用视频人体运动模型从原始的轨线信息中挖掘语义事件的发生概率,从而对行为活动进行表示。视频人体运动的建模性能在本节实验中主要体现在以下两点:(1)对同一行为活动类中存在较大差异的运动轨线,视频人体运动活动建模方法仍能挖掘出内在的事件发生概率。图7为使用粉笔擦擦黑板的行为动作运动轨线,通过视频人体运动方法进行建模后得到图8和图9的事件概率序列。从图中可以看出,尽管图7(a)和(b)表示同一个行为活动时,其动作执行方式存在较大差异,但从视频人体运动建模表示的事件概率序列图中可以看出,对于行为活动表示形态存在差异但属于同一类的行为,视频人体运动建模仍能挖掘其内在的联系并有效提取同类活动中所共有的相似性。在运动轨线变化较显著的时候,事件发生概率最高。另外,该建模方法从数据层面中挖掘隐含的事件转移概率,并通过事件发生概率来表示行为活动,在一定程度上达到视频行为语义表示的效果。(2)视频人体运动方法在建模过程的学习训练中可以取得更优的参数模型,即视频人体运动方法更好地求解HMM参数训练的泛极值问题并得以跳出参数训练的局部最优,其衡量指标主要反映在参数优化目标值是否更优。图10和图11是视频人体运动和HMM-Baum对行为活动类Pourwater和Closedoor建模时,在算法的迭代过程中所求得的优化目标值。从图中可明显看出,相比HMM-Baum方法,视频人体运动可跳出局部最优值并求得更优目标值,即更好地训练参数λ使得对所有的学习样本∑log(P(O|λ))最大。表2-2表示在不同的参数下,HMM_PS与HMM_Baum在学习问题求解上的对比,从表中不难看出,视频人体运动能求得更大的学习问题目标值,即视频人体运动相比HMM-Baum具有更优的参数学习性能。通过实验不难看出,视频人体运动的学习性能优于传统的Baum-Welch算法,尤其可以避免参数训练陷入局部最优。表2-2HMM_PS与HMM_Baum在参数优化问题的对比2.1.2识别性能分析通过上一节的视频人体运动行为活动建模,本节中计算出行为活动的事件概率序列,采用DTW方法匹配事件概率序列从而对视频行为进行识别。文献[通过运动轨线的曲率变化描述行为活动的事件,然后通过匹配进行识别。本节实验与文献中的方法进行对比,表明视频人体运动方法在视频行为识别中的优势。表2-3为HMM_PS方法与文献的方法在UCF行为活动轨线数据集的识别率比较。该表中斜杠表示暂不能从文献中获取的识别数据。从表中数据的对比可以看出,HMM_PS方法相比于文献采用的根据曲率变化表示行为活动的方法具有更高的识别率。尤其在Opendoor和Pourwater等行为活动类中,其优势更加明显。但由于训练数据的不充分,在总体的识别性能上,视频人体运动方法仍有待提高。表2-3HMM_PS与文献[16]求解UCF识别率比较图12表示在不同事件粒度参数下的识别率比较。图中实线的表示HMM-Baum求解得到的平均识别率,虚线表示视频人体运动的求解结果。从图中实验可以看出,当参数p=5时,识别效果最优。在本文中的参数研究中,首先根据经验公式确定隐含状态N,再通过实验对比的方法确定参数p,从图12中可以看出,参数p=5可作为本节实验事件粒度参数的取值。另外,从图中可以看出,对比HMM-Baum方法,本文提出的视频人体运动在行为活动的平均识别率上具有较大的优势。2.2ASL数据集仿真实验分析,ASL(AustralianSignLanguage)数据集可从UCI-KDD中获得,是表示人体手势活动的数据集。该数据集收集5名专业手势活动表演者的运动轨线,包括95个单词的手势轨线,其中每个单词类约70个样本。整个数据集约有6650个运动轨线的样本,每个样本中包含多个特征量。在本文中,运动轨线主要提取手部在x和y方向的位置向量构成的二维轨线,并依据本文的轨线特征提取方法进行表示,从而对其手势活动进行识别。本节实验中相关参数设置主要为:隐含状态数N=12,事件粒度p=8,PSO中的最大迭代次数Maxgen=500,学习因子cl=1.8,c2=1.8,自适应调整权值系数winitial=0.4,wfinal=0.9。而HMM模型中,状态转移概率A和初始概率π随机初始化,单高斯概率密度函数的均值矢量和协方差矩阵,通过K均值聚类得到,即将已经聚为一个轨迹模式类的观察序列值依据K均值自动聚类,类的个数为HMM模型的状态个数N。在识别过程中,每一个手势活动类的样本数为69,其中用于学习的样本在60%左右,测试样本约60%。2.2.1行为活动建模分析,在UCF数据集的行为建模实验中,已经分析了视频人体运动对行为活动建模的有效性以及它在学习训练过程的优势。而在本节中,主要分析视频人体运动方法在行为活动建模中的视角无关性,即针对不同角度观察到的行为活动,视频人体运动方法建模的准确性并不受到视角的影响。图13分别表示在观察视角旋转60°,0°,-60°后所得到的手势活动alive的运动轨线,通过视频人体运动对不同观察角度的运动轨线建模后得到其相应的事件概率序列如图14所示。从图13、14中可看出,在不同的观察视角下,运动轨线具有不同的表示形态,但通过视频人体运动建模后,其相应的事件概率表示基本一致,即表明视频人体运动方法在表示存在视角差异的行为活动时具有一定的适应性。2.2.2识别性能分析表2-4视频人体运动与HMM-Baum在求解多类手势活动的识别率比较在本节,对不同的活动类数的行为进行识别,其主要识别率如表2-4。从表中可以看出,相比HMM-Baum方法,本文提出的视频人体运动具有更高的识别率,从而表明本文改进的视频人体运动方法由于在学习训练中的充分性,使得模型参数具有更优的性能,从而在识别率上稍具优势。虽然改进的方法对识别效果有所提高,但总的说来,识别率仍有待提高,尤其在活动类的规模增大时。对于规模增大识别率欠缺的问题,经过分析主要存在两点原因:一、本文的观测概率采用单高斯密度函数,对于复杂的活动信息其概率逼近欠缺精确;二、采用DTW方法对事件概率的匹配距离计算是否能恰当反映测试样本与训练活动类别的距离,仍然需要进一步的验证。2.3实验总结,在本章实验中,主要基于两个视频行为活动数据集,设计了两部分的实验验证视频人体运动方法的可行性和准确性:行为活动建模分析和识别性能分析。从实验结果可以看出,本文设计的视频人体运动方法在行为运动的建模中具有三点优势:(1)视频人体运动对存在形态差异的运动轨线仍能挖掘出其内在的事件发生概率,具有一定的语义表示作用。(2)视频人体运动方法在建模过程的学习训练中可以取得更优的参数模型,从而提高识别率。(3)视频人体运动方法在表示存在视角差异的行为活动时具有一定的适应性。由于在行为建模上具备的上述优势,相比HMM-Baum方法和其他文献的相关方法,本文提出的视频人体运动在识别率上可取得更优的识别效果。当然,以上只是本发明的典型实例,除此之外,本发明还可以有其它多种具体实施方式,凡采用等同替换或等效变换形成的技术方案,均落在本发明要求保护的范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1