音乐信息网络中用户兴趣发现方法与流程
本发明涉及信息检索领域,特别是一种音乐信息网络中用户兴趣发现方法。
背景技术:
音乐信息网络实际上是由一个信息子网和社交子网构成的异构信息网络,信息子网通常包含歌曲以及与歌曲相关的类型节点,如歌手、作词者、流派等等,网络中存在的关系有歌曲-歌手之间的被演唱与演唱关系、歌曲-作词者之间的被作词与作词关系、歌曲-流派之间的被包含与包含关系等等,社交子网中包含用户之间的好友关系、歌曲-用户之间的被播放与播放关系。
目前,音乐信息网络中用户兴趣发现方法主要是将歌曲的歌手、作词者、流派等信息作为歌曲的属性特征,然后将用户-歌曲的评分映射到这些属性特征中,得到用户-歌曲特征偏好矩阵。这种基于内容的用户兴趣发现方法本质上是基于统计信息,没有充分利用到异构信息网络中不同类型的对象、不同的交互语义等全面的结构信息和丰富的语义信息,并不能很好地体现出用户对歌曲的真正兴趣点。
技术实现要素:
本发明的目的在于提供一种音乐信息网络中用户兴趣发现方法,以克服现有技术中存在的缺陷。
为实现上述目的,本发明的技术方案是:一种音乐信息网络中用户兴趣发现方法,包括如下步骤:
步骤S1:获取一音乐信息网络,在所述音乐信息网络中通过N步长随机游走得到与用户相关的信息子网G以及信息子网G的网络模式HG;
步骤S2:对所述信息子网G进行剪枝,并在剪枝后的信息子网G'中计算不同类型边的权重;
步骤S3:在所述信息子网G'中计算所有歌曲对之间的最短路径集和最短路径权重,根据所述最短路径集和最短路径权重计算出元路径集和元路径权重;
步骤S4:在所述信息子网G'中利用PathSelClus算法基于元路径将歌曲聚成三类,根据聚类结果分析出用户对歌曲的兴趣爱好。
在本发明一实施例中,在所述步骤S1中,还包括如下步骤:
步骤S11:从豆瓣音乐网站中获取音乐网络数据信息,提取网络实体及实体间存在的关系,实体与实体间的关系构成了一个音乐信息网络;其中,实体包括歌曲M、歌手S、作词者A、流派T以及用户U;实体间存在的关系如下:歌曲m-歌手s之间的被演唱与演唱关系、歌曲m-作词者a之间的被作词与作词关系、歌曲m-流派t之间的被包含与包含关系、用户u-歌曲m之间的播放与被播放关系以及用户之间的好友关系;
步骤S12:从所述音乐信息网络中获取与用户相关的信息子网G;
步骤S13:获取G的网络模式HG;网络模式HG包含不同类型的节点和边;不同类型的节点表示为:歌曲M、歌手S、,作词者A以及流派T;不同类型的边代表节点之间的不同关系,具体为:歌曲-歌手之间的被演唱与演唱关系、歌曲-作词者之间的被作词与作词关系以及歌曲-流派之间的被包含与包含关系。
在本发明一实施例中,在所述步骤S12中,还包括如下具体步骤:
步骤S121:根据用户与歌曲之间的播放关系,得到用户播放的歌曲节点集
步骤S122:分别以mx(x=1,...,X)为中心,查找与mx相关的歌手、作词者以及流派的节点集
步骤S123:分别以vj(j=1,2,..,J)为中心,查找与节点vj相关的其他歌曲节点集
步骤S124:重复所述步骤S121至所述步骤S123,直至找到Um中,以每个节点mx为中心的N步长内,且与该节点mx相关的节点集U包括歌曲节点集歌手节点集作词者节点集流派节点集由U构成的子网络即为用户的信息子网G。
在本发明一实施例中,在所述步骤S2中,还包括如下步骤:
步骤S21:在所述信息子网G中,保留歌曲-歌手之间的被演唱关系边、歌曲-作词者之间的被作词关系边、歌曲-流派之间的被包含关系边,得到信息子网G';从所述信息子网G中歌手-歌曲之间的演唱关系边、作词者-歌曲之间的作词关系边、流派-歌曲之间的包含关系边构成的集合中随机添加一条边至信息子网G'中,直到信息子网G'为强连通图为止,即可得到所述信息子网G通过剪枝枝后的信息子网G';
步骤S22:利用HeteSim算法计算所述信息子网G'中每一对不同类型节点间的相关性,包括:歌曲-歌手之间的被演唱关系相关性、歌曲-作词者之间的被作词关系相关性、歌曲-流派之间的被包含关系相关性、歌手-歌曲之间的演唱关系相关性、作词者-歌曲之间的作词关系相关性以及流派-歌曲之间的包含关系相关性;
步骤S23:将所述步骤S22得到的相关性取倒数,得到所述信息子网G'不同类型边的权重。
在本发明一实施例中,在所述步骤S3中,在所述信息子网G'中计算所有歌曲对之间的最短路径集shortPath和最短路径权重wShortPath;将所述最短路径集抽象为元路径实例集mshPath,并计算元路径集metaPath、元路径实例路径数q和元路径权重wMetaPath,具体步骤如下:
步骤S31:对于所述信息子网G'中所有歌曲节点集计算所有歌曲对之间的最短路径集shortPath:利用单源最短路径算法计算歌曲mi到歌曲mj之间的最短路径shortPathij,其中,i,j=1,2,...,Q,i≠j;
步骤S32:计算所有歌曲对之间的最短路径权重wShortPath:对于最短路径集shortPath中的每一条最短路径shortPathij,计算最短路径shortPathij的权重wShortPathij,计算公式为:
其中,R为shortPathij的跳数;heteSimr为每一跳对应边er=<vs,vt>的相关性,s=1,..,N;t=1,...,N;
步骤S33:根据所述信息子网G的网络模式HG,将最短路径集shortPath中的每一条最短路径shortPathij抽象为元路径mshPathij,得到所有歌曲对之间的元路径实例集mshPath和元路径实例权重wmshPath,计算为:wmshPath=wShortPath;
步骤S34:将所述元路径实例集mshPath抽象为元路径集对每一条元路径metaPathm,获取对应的所有元路径实例计算为:
mshPath'l=mshPathij;
步骤S35:计算所有的元路径权重wMetaPath。
在本发明一实施例中,在所述步骤S35中,计算所有的元路径权重wMetaPath,具体步骤如下:
步骤S351:对每一条元路径metaPathm对应的所有元路径实例计算每一条元路径实例mshPath'l对应的元路径实例权重wmshPath'l,计算为:wmshPath'l=wmshPathij;
步骤S352:计算出元路径metaPathm的权重wMetaPathm,计算公式如下:
其中,qm表示元路径metaPathm对应的实例路径数。
在本发明一实施例中,在所述步骤S4中,还包括如下步骤:
步骤S41:初始化PathSelClus算法中的各类参数;
步骤S42:使用EM算法估计Θt和Βmt,具体步骤如下:
步骤S421:计算歌曲mi与歌曲mj之间基于元路径metaPathm的连接关系分别属于(T|M),(S|M),(A|M)类别的连接概率zij,m,计算公式为:
P(zij,m=k|Θt-1,Βmt-1)∞θikt-1βkj,mt-1
步骤S422:计算歌曲mi分别属于(T|M),(S|M),(A|M)类别的后验概率θikt,计算公式为:
步骤S423:计算基于元路径metaPathm下歌曲mj分别出现在(T|M),(S|M),(A|M)类别的概率βkj,mt,计算公式为:
步骤S424:重复步骤S421至步骤S423,直到Θt和Βmt收敛为止,其中Θt={θikt}(i=1,...,Q;k=1,...,K),Βmt={βkj,mt}(k=1,...,K;j=1,...,Q);
步骤S43:计算元路径metaPathm的关系权重αm;计算公式为:
步骤S44:重复步骤S42至S43,直到Θ、Βm和αm都收敛为止;
步骤S45:计算用户对歌曲的流派T、歌曲的歌手S以及歌曲的作词者A之间的爱好程度。
在本发明一实施例中,所述步骤S41中,按照如下步骤初始化PathSelClus算法中的各类参数:
步骤S411:初始化聚类数目K、用户置信度λ、元路径{P}Mm=1、每条关系矩阵权重Wm、元路径的关系权重α0以及Bm0;
步骤S412:初始化聚类种子节点{L1,L2,L3};
步骤S413:初始化聚类参数Θ0,计算公式为:
其中,Θ0是Q×3的矩阵,表示歌曲在每个类中出现的概率,得到Θ0后再进行归一化。
在本发明一实施例中,所述步骤S45中,还包括如下步骤:
步骤S451:根据所述步骤S44得到的歌曲聚类参数Θ,将Θi中最大值所在类作为歌曲mi的最终类簇;
步骤S452:统计每一类歌曲数目占所有歌曲的比例,并进行归一化,得到(T|M),(S|M),(A|M)每一类的概率,即用户对歌曲的流派T、歌曲的歌手S以及歌曲的作词者A之间的爱好程度。
相较于现有技术,本发明具有以下有益效果:本发明提出了一种音乐信息网络中用户兴趣发现方法,该方法建立在包含不同类型的对象和关系等全面的结构信息和丰富的语义信息的信息子网基础上,利用异构信息网络中元路径这一重要特性来发现用户兴趣点,其效果比传统的统计方法更能体现出用户个人对歌曲的兴趣爱好。
附图说明
图1为本发明中一种音乐信息网络中用户兴趣发现方法。
图2为本发明一实施例中音乐信息网络。
图3为本发明一实施例中音乐信息网络中信息子网的网络模式。
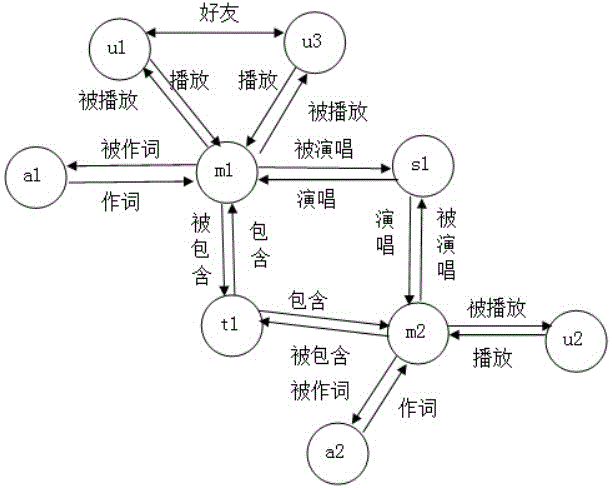
图4为本发明-实施例中音乐信息网络中一个用户的信息子网例子。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
下面通过具体实施例对本发明做进一步的说明,但是需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
本发明所提出的音乐信息网络中用户兴趣发现方法的的流程图,如图1所示,具体包括如下步骤:
步骤S1:获取音乐信息网络,在所述音乐信息网络中通过N步长随机游走得到与用户相关的信息子网G以及信息子网G的网络模式HG;具体步骤如下:
步骤S11:从豆瓣音乐网站中获取音乐网络数据信息,提取网络实体及实体间存在的关系,实体与实体间的关系构成了一个音乐信息网络。其中,实体包括歌曲(M),歌手(S),作词者(A),流派(T),用户(U),实体间存在的关系如下:歌曲m-歌手s之间的被演唱与演唱关系、歌曲m-作词者a之间的被作词与作词关系、歌曲m-流派t之间的被包含与包含关系、用户u-歌曲m之间的播放与被播放关系,用户之间的好友关系。
步骤S12:从音乐信息网络中获取与用户相关的信息子网G,具体步骤如下:
步骤S121:根据用户与歌曲之间的播放关系,得到用户播放的歌曲节点集
步骤S122:分别以mx(x=1,...,X)为中心,查找与mx相关的歌手、作词者、流派的节点集
步骤S123:分别以vj(j=1,2,..,J)为中心,查找与节点vj相关的其他歌曲节点集
步骤S124:重复步骤S121至步骤S123,直至找到Um中每个节点mx为中心的N步长内与之相关的节点集U包括歌曲节点集歌手节点集作词者节点集流派节点集由U构成的子网络就是用户的信息子网G,如图4所示。
步骤S13:获取G的网络模式HG。网络模式HG包含不同类型的节点和边。不同类型的节点具体表示为:歌曲(M),歌手(S),作词者(A),流派(T);不同类型的边代表节点之间的不同关系,具体为:歌曲-歌手之间的被演唱与演唱关系、歌曲-作词者之间的被作词与作词关系、歌曲-流派之间的被包含与包含关系,信息子网G的网络模式如图3所示。
步骤S2:对所述信息子网络G进行剪枝,并在剪枝后信息子网G'中计算异构不同类型边的权重,具体步骤如下:
步骤S21:对所述信息子网G进行剪枝,具体为:保留G中歌曲-歌手之间的被演唱关系边、歌曲-作词者之间的被作词关系边、歌曲-流派之间的被包含关系边,得到子网G';接着,从信息子网G中歌手-歌曲之间的演唱关系边、作词者-歌曲之间的作词关系边、流派-歌曲之间的包含关系边构成的集合中随机添加一条边至子网G'中,直到子网G'为强连通图为止,即可得到信息子网G通过剪枝枝后的信息子网G';
步骤S22:利用HeteSim算法计算信息子网G'中每一对不同类型节点间的相关性,具体为:歌曲-歌手之间的被演唱关系相关性、歌曲-作词者之间的被作词关系相关性、歌曲-流派之间的被包含关系相关性、歌手-歌曲之间的演唱关系相关性、作词者-歌曲之间的作词关系相关性、流派-歌曲之间的包含关系相关性。
本实施例中歌曲-歌手之间的被演唱关系边、歌曲-作词者之间的被作词关系边、歌曲-流派之间的被包含关系边的具体相关性计算结果如表1所示,歌手-歌曲之间的演唱关系边、作词者-歌曲之间的作词关系边、流派-歌曲之间的包含关系边的具体相关性计算结果分别与歌曲-歌手之间的被演唱关系边、歌曲-作词者之间的被作词关系边、歌曲-流派之间的被包含关系边的具体相关性相同。
表1
步骤S23:将步骤S22得到的相关性取倒数,得到信息子网G'不同类型边的权重。
步骤S3:在所述信息子网G'中计算所有歌曲对之间的最短路径集shortPath和最短路径权重wShortPath,将所述最短路径集抽象为元路径实例集mshPath,并计算元路径集metaPath、元路径实例路径数q和元路径权重wMetaPath,按照如下步骤计算:
步骤S31:对于所述信息子网G'中所有歌曲节点集计算所有歌曲对之间的最短路径集shortPath。具体步骤为:利用单源最短路径算法计算歌曲mi到歌曲mj,(i,j=1,2,...,Q,i≠j)之间的最短路径shortPathij;
步骤S32:计算所有歌曲对之间的最短路径权重wShortPath。具体步骤为:对于最短路径集shortPath中的每一条最短路径shortPathij(i,j=1,2,...,Q,i≠j),计算最短路径shortPathij的权重wShortPathij,具体计算公式为:
其中,R为shortPathij的跳数;heteSimr为每一跳对应边er=<vs,vt>(s=1,..,N;t=1,...,N)的相关性;
步骤S33:根据信息子网G的网络模式HG,将最短路径集shortPath中的每一条最短路径shortPathij(i,j=1,2,...,Q,i≠j)抽象为元路径mshPathij,得到所有歌曲对之间的元路径实例集mshPath和元路径实例权重wmshPath,具体计算为:wmshPath=wShortPath;
步骤S34:将元路径实例集mshPath抽象为元路径集对每一条元路径metaPathm,获取对应的所有元路径实例具体计算为:mshPath'l=mshPathij;
步骤S35:计算所有的元路径权重wMetaPath。具体步骤为:
步骤S351:对每一条元路径metaPathm对应的所有元路径实例计算每一条元路径实例mshPath'l对应的元路径实例权重wmshPath'l,具体计算为:wmshPath'l=wmshPathij;
步骤S352:计算出元路径metaPathm的权重wMetaPathm,具体计算公式如下:
其中,qm表示元路径metaPathm对应的实例路径数。
在本实施例中所有歌曲对之间的最短路径集shortPath计算结果如表2所示,所有歌曲对之间的元路径实例集mshPath的计算结果如表3所示,元路径集metaPath、元路径实例路径数目q和元路径权重wMetaPath的计算结果如表4所示。
表2
表3
表4
步骤S4:在所述信息子网G'中利用PathSelClus算法基于元路径将歌曲聚成三类,根据聚类结果分析出用户对歌曲的兴趣爱好,按照如下步骤计算:
步骤S41:初始化PathSelClus算法中的各类参数。具体步骤为:
步骤S411:初始化K,λ,{P}Mm=1,Wm,α,Βm0。具体为:参数K取值为3;用户置信度λ取值为100;元路径{P}Mm=1取值为元路径集metaPath;Wm取值为metaPath中的每一条元路径metaPathm中所有邻接矩阵连乘得到的正则化后的关系矩阵;α的初始值取为元路径权重wMetaPath;将Βm0随机化为0到1之间的概率后,再进行正则化;
进一步的,在本实施例中,M=5,{P}5m=1=metaPath={MTM,MSM,MAM,MTMAM,MAMTM},α=wMetaPath=[0.418,0.441,0.535,0.567,0.567];
步骤S412:初始化{L1,L2,L3}。具体为:L1取值为元路径实例集中值为‘MTM’对应的行和列位置上的所有不重复歌曲;L2取值为元路径实例集中值为‘MSM’对应的行和列位置上的所有不重复歌曲;L3取值为元路径实例集中值为‘MAM’对应的行和列位置上的所有不重复歌曲;
进一步的,在本实施例中,L1={m1,m2,m3,m4},L2={m1,m2,m3,m4,m5,m6},L3={m1,m2,m3,m4,m5,m6};
步骤S413:初始化Θ0。具体计算公式为:
其中,Θ0是Q×3的矩阵,表示歌曲在每个类中出现的概率,得到Θ0后再进行归一化;
进一步的,在本实施例中,Θ0是6×3的矩阵,具体值为:
步骤S42:使用EM算法估计Θt和Βmt;具体步骤如下:
步骤S421:计算歌曲mi与歌曲mj之间基于元路径metaPathm的连接关系分别属于(T|M),(S|M),(A|M)类别的连接概率zij,m,计算公式为:
P(zij,m=k|Θt-1,Βmt-1)∞θikt-1βkj,mt-1
步骤S422:计算歌曲mi分别属于(T|M),(S|M),(A|M)类别的后验概率θikt,计算公式为:
步骤S423:计算基于元路径metaPathm下歌曲mj分别出现在(T|M),(S|M),(A|M)类别的概率βkj,mt,计算公式为:
步骤S424:重复步骤S421至步骤S423,直到Θt和Βmt收敛为止,其中Θt={θikt}(i=1,...,Q;k=1,...,K),Βmt={βkj,mt}(k=1,...,K;j=1,...,Q)。
步骤S43:计算元路径metaPathm的关系权重αm;计算公式为:
步骤S44:重复步骤S422至S423,直到Θ、Βm和αm都收敛为止;
在本实施例中,迭代收敛后的歌曲聚类参数
步骤S45:计算用户对歌曲的流派T、歌曲的歌手S以及歌曲的作词者A之间的爱好程度。具体步骤为:
步骤S451:根据步骤S44得到的歌曲聚类参数Θ,将Θi中最大值所在类作为歌曲mi的最终类簇;
步骤S452:统计每一类歌曲数目占所有歌曲的比例,并进行归一化,得到(T|M),(S|M),(A|M)每一类的概率,即用户对歌曲的流派T、歌曲的歌手S以及歌曲的作词者A之间的爱好程度。
在本实施例中,用户对歌曲的流派T、歌曲的歌手S以及歌曲的作词者A之间的爱好程度如表5所示,由表5可得,用户ID3播放歌曲过程中,有50%的可能性选择某种流派包含的歌曲,有16.667%的可能性选择某个歌手演唱的歌曲,有33.333%的可能性选择某个作词者作词的歌曲。
表5
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!