兴趣识别方法及系统与流程
本发明涉及一种兴趣识别方法及系统。
背景技术:
随着互联网的迅猛发展及普及,互联网用户的使用习惯已从最初的自己寻找内容转变为依赖服务方给予的内容推送,因此精确地了解每个用户兴趣点,能有效帮助服务方提供个性化的服务,提高用户的使用体验。
现有的用户兴趣识别主要有以下几种方式:
1. 通过用户及其他用户的描述;
2. 通过用户的浏览交互行为,人为定义;
3. 通过对用户访问内容预设标签,统计得出。
上述几种方式存在以下的缺陷:
1. 兴趣标签的不规范,当将设定兴趣的权利给予用户时,用户对于同一件事物的描述往往不尽相同,导致大量相同的标签被异化,加大识别难度并影响精度;
2. 同语义或相近语义标签无法归并,降低了兴趣识别的精准度;
3. 网络爬虫、水军等非正常访问用户会对识别造成干扰;
4. 用户的兴趣是变化的,系统对于陈旧数据无法做到合理滤除,导致识别精度下降;
5. 随着各年龄段的用户涌入,同样的内容对于不同年龄段的用户的意义是不同的,系统无法结合人口基本属性进行识别。
技术实现要素:
本发明的目的在于提供一种兴趣识别方法及系统,能够帮助提升对于内容的搜索及推荐的精准度。
为解决上述问题,本发明提供一种兴趣识别方法,包括:
收集文本内容和结构化数据,对所述文本内容进行处理,得到非结构化的带顺序的词组集合;
对所述非结构化的带顺序的词组集合和/或结构化数据进行语义实体的抽取、文本实体的抽取、语义实体间关系的抽取、及文本实体与语义实体间关系的抽取;
对抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系进行语义实体的归并;
将归并后的抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系形成知识图谱;
根据所述知识图谱,将每个用户的一定时间范围内的访问行为数据和互动行为数据中的文本实体关联到对应的语义实体,通过统计学判断每个用户访问时是否有侧重的语义实体;
若有,将所述侧重的语义实体作为该用户的兴趣标签。
进一步的,在上述方法中,将所述侧重的语义实体作为该用户的兴趣标签,包括:
获取用户的基本标签,将所述基本标签归入到对应预设类别的分组标签;
将所述侧重的语义实体和分组标签进行组合作为该用户的兴趣标签。
进一步的,在上述方法中,所述一定时间范围内为最近一定时间范围内。
进一步的,在上述方法中,通过统计学判断每个用户访问时是否有侧重的语义实体之后,还包括:
若无,判断用户是否访问量过高,若是,判断该用户可能是爬虫。
进一步的,在上述方法中,通过统计学判断每个用户访问时是否有侧重的语义实体之后,还包括:
判断用户访问的语义实体是否相悖,且互动量较高,若是,则判断该用户是水军。
进一步的,在上述方法中,将所述侧重的语义实体作为该用户的兴趣标签之后,还包括根据用户的兴趣标签向用户推荐内容。
进一步的,在上述方法中,对所述文本内容进行处理,包括:
对所述文本内容依次进行分词、歧义词处理、词性识别、去除停用词、消除脏数据的处理。
进一步的,在上述方法中,对所述文本内容进行分词包括:
对所述文本内容依次进行原子切分、根据分词词典和歧义词词典并采用预设的多种算法进行分词、未登录词识别、嵌套未登录词识别、基于类的隐马分词。
进一步的,在上述方法中,所述预设的多种算法包括正向最大匹配法、逆向最大匹配法和统计分词。
进一步的,在上述方法中,所述基于类的隐马分词之后还包括进行词性标注。
进一步的,在上述方法中,未登录词识别之后,还包括将识别到的未登录词更新补充入所述分词词典和歧义词词典。
进一步的,在上述方法中,嵌套未登录词识别之后,还包括将识别到的嵌套未登录词更新补充入所述分词词典和歧义词词典。
根据本发明的另一面,提供一种兴趣识别系统,包括:
收集处理模块,用于收集文本内容和结构化数据,对所述文本内容进行处理,得到非结构化的带顺序的词组集合;
抽取模块,用于对所述非结构化的带顺序的词组集合和/或结构化数据进行语义实体的抽取、文本实体的抽取、语义实体间关系的抽取、及文本实体与语义实体间关系的抽取;
归并模块,用于对抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系进行语义实体的归并;
知识图谱形成模块,用于将归并后的抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系形成知识图谱;
第一判断模块,用于根据所述知识图谱,将每个用户的一定时间范围内的访问行为数据和互动行为数据中的文本实体关联到对应的语义实体,通过统计学判断每个用户访问时是否有侧重的语义实体;
兴趣标签模块,用于若有所述侧重的语义实体,将所述侧重的语义实体作为该用户的兴趣标签。
进一步的,在上述系统中,所述兴趣标签模块,用于获取用户的基本标签,将所述基本标签归入到对应预设类别的分组标签;将所述侧重的语义实体和分组标签进行组合作为该用户的兴趣标签。
进一步的,在上述系统中,所述一定时间范围内为最近一定时间范围内。
进一步的,在上述系统中,还包括:
第二判断模块,用于若无侧重的语义实体,判断用户是否访问量过高,若是,判断该用户可能是爬虫。
进一步的,在上述系统中,还包括:
第三判断模块,用于若无侧重的语义实体,判断用户访问的语义实体是否相悖,且互动量较高,若是,则判断该用户是水军。
进一步的,在上述系统中,还包括推荐模块,用于根据用户的兴趣标签向用户推荐内容。
进一步的,在上述系统中,所述收集处理模块,用于对所述文本内容依次进行分词、歧义词处理、词性识别、去除停用词、消除脏数据的处理。
进一步的,在上述系统中,所述收集处理模块,用于对所述文本内容依次进行原子切分、根据分词词典和歧义词词典并采用预设的多种算法进行分词、未登录词识别、嵌套未登录词识别、基于类的隐马分词。
进一步的,在上述系统中,所述预设的多种算法包括正向最大匹配法、逆向最大匹配法和统计分词。
进一步的,在上述系统中,所述收集处理模块,用于在所述基于类的隐马分词之后进行词性标注。
进一步的,在上述系统中,所述收集处理模块,用于在未登录词识别之后,将识别到的未登录词更新补充入所述分词词典和歧义词词典。
进一步的,在上述系统中,所述收集处理模块,用于在嵌套未登录词识别之后,将识别到的嵌套未登录词更新补充入所述分词词典和歧义词词典。
与现有技术相比,本发明使用用户浏览的文本内容构建知识图谱,并从中抽取用户兴趣点,能够帮助提升对于内容的搜索及推荐的精准度。
附图说明
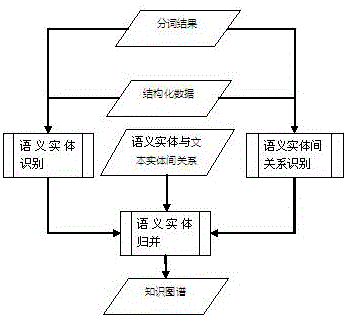
图1是本发明一实施例的兴趣识别方法的原理示意图;
图2是本发明一实施例的知识图谱构建的原理图;
图3是本发明一实施例的对文本内容进行分词的原理图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例一
如图1和2所示,本发明提供一种兴趣识别方法,包括:
步骤S1,收集文本内容和结构化数据,对所述文本内容进行处理,得到非结构化的带顺序的词组集合;具体的,所述文本内容为用户浏览的文本内容;
步骤S2,对所述非结构化的带顺序的词组集合和/或结构化数据进行语义实体的抽取、文本实体的抽取、语义实体间关系的抽取、及文本实体与语义实体间关系的抽取;具体的,名词、人名、机构名是天然的语义实体,每一篇新闻、每一个帖子则是一个文本实体,如果对非结构化的带顺序的词组集合进行语义实体间的关系抽取,比如:在大量的文本中,科比/nr 和 瓦妮莎/nr 这两个人名同时出现,并且另外两个词 丈夫/n和妻子/n共现的概率也较高,因此可以判断“科比”这个实体和“瓦妮莎”这个实体的关系是夫妻关系;如果对结构化数据进行语义实体间的关系抽取,比如:已知 湖人/nt 这个实体在NBA球队表中,因此这个词的其中一个属性为“NBA球队”,科比/nr 这个词在NBA球员表中,因此这个词其中一个属性为“NBA球员”。而在业务数据库中两个词在关系型数据库中是关联的(“科比”这条记录的球队ID对应是“湖人”),因此可以知道 科比/nr 和 湖人/nt 之前的关系是“效力于”,即:“科比”->“效力于”->“湖人”;详细的,文本实体与语义实体间的关系抽取,具体如下:
先将每个文本实体与它内容中的每个语义实体建立关系,再根据每个语义实体与文本实体间的关系数,确定每个语义实体的重要程度;
根据上一步得到的每个语义实体的重要程度,对每个文本实体内所包含的文本实体排序,每个文本实体保留3-5个与最重要的语义实体间的关系,将其他关系剔除;
步骤S3,对抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系进行语义实体的归并;具体的,在此计算每个文本实体与其他文本实体以及同属性语义实体间关系的重合度,将重合度高的语义实体归并,从而避免了现有技术中兴趣标签的不规范,当将设定兴趣的权利给予用户时,用户对于同一件事物的描述往往不尽相同,导致大量相同的标签被异化,加大识别难度并影响精度的问题,同时,也解决了现有技术中同语义或相近语义标签无法归并,降低了兴趣识别的精准度的问题;
步骤S4,如图2所示,将归并后的抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系形成知识图谱;具体的,在此形成一个基于语义实体、语义实体间关系、语义实体与文本实体间关系组成的一个知识图谱;
步骤S5,根据所述知识图谱,将每个用户的一定时间范围内的访问行为数据和互动行为数据中的文本实体关联到对应的语义实体,通过统计学判断每个用户访问时是否有侧重的语义实体;具体的,网页端可通过JS代码、APP端可通过采集SDK,收集用户的浏览行为数据,例如用户A在时间x访问了一个新闻,新闻ID为100,并且点了赞;通过业务数据库中发帖、回复表,来收集访问行为数据,例如用户B在时间y发布了一个帖子,帖子ID是200;
步骤S6, 若有,将所述侧重的语义实体作为该用户的兴趣标签。
优选的,将所述侧重的语义实体作为该用户的兴趣标签,包括:
获取用户的基本标签,将所述基本标签归入到对应预设类别的分组标签;
将所述侧重的语义实体和分组标签进行组合作为该用户的兴趣标签。具体的,所述基本标签可以来自一用户图谱系统中现有的标签,在此,可对用户根据用户的基本标签进行分组,比如按照年龄段或者性别进行分组,以便于后续分析区别不同年龄段或者性别的用户对于同一语义实体的不同理解。举例来说“王朝”这个名词的语义实体,对于年龄较大的球迷,他们访问和互动的新闻、帖子在包含“王朝”这个语义实体的同时,大部分还包含“公牛”这个语义实体;而对于年龄稍轻一些的球迷,他们访问和互动新闻、帖子在包含“王朝”这个语义实体的同时,大部分还包含“湖人”这个语义实体。说明对于两个不同年龄段的用户来说“王朝”分别代表了“公牛”“王朝”和“湖人”“王朝”。
优选的,所述一定时间范围内为最近一定时间范围内,由于每次计算都是使用最近一定时间范围内的用户访问行为数据和互动行为数据,因此能避免历史数据造成的误差。
优选的,步骤S7,若无,判断用户是否访问量过高,若是,判断该用户可能是爬虫。
优选的,步骤S8,若无,判断用户访问的语义实体是否相悖,且互动量较高,若是,则判断该用户是水军。
优选的,将所述侧重的语义实体作为该用户的兴趣标签之后,还包括根据用户的兴趣标签向用户推荐内容。具体如:
1.内容推荐:一篇新的新闻或者新的帖子,推送给兴趣点为与其相关联的语义实体一致的用户。
2.商品推荐:如果一个用户对于“篮球鞋”和“科比”这两个语义实体感兴趣,那么当电商平台上出现一件商品同样与“篮球鞋”和“科比”这两个语义实体存在关联时,将这件商品推荐给这个用户。
3.智能搜索:如果用户搜索“科比的妻子”,则根据知识图谱“科比”语义实体以及“妻子”这个关系实体,关联到“瓦妮莎”这个语义实体,并将于这个语义实体相关的文本实体作为结果返回给用户。
详细的,例如将每个用户的一定时间范围内的访问行为数据和互动行为数据中的文本实体(如文本实体ID)关联到对应的语义实体,通过统计学获得每个用户访问时侧重的语义实体,作为其兴趣标签。若用户无明显访问重点,且访问量较高,则说明这个用户可能是爬虫,若用户访问重点通常相悖,且互动量较高,则说明其可能是水军。
优选的,对所述文本内容进行处理,包括:
对所述文本内容依次进行分词、歧义词处理、词性识别、去除停用词、消除脏数据的处理。例如,输入的文本内容为“学校的学费要一次性交一千元”,经过本步骤后,输出的处理结果为“学校/n, 学费/n, 要/v, 一次性/d, 交/v, 一千元/m”。
详细的,歧义词处理如下:
对于一些特殊的句式比如“林书豪比萨克雷强”,正向匹配结果为:林书豪/比萨/克雷/强,逆向匹配结果为:林书豪/比/萨克雷/强。
实际上萨克雷是一个人名,但是由于正常情况下“比萨”这个词比“萨克雷”这个词出现的概率大,导致正向分词结果从统计学上比逆向分词更好,但实际这是一个错误的分词结果。
因此会通过歧义词处理来纠正这个错误,即存在一个歧义词词典,当出现“比萨克雷”这样的组合是系统强制分词为“比/萨克雷”结果。
歧义词由人工在日常对分词结果的随机抽检中发现分词错误后添加进词典。
详细的,词性识别如下:
中文中同一个词会有不同的词性,比如“统计”即是一个名词又是一个动词。
系统在识别词性时,会根据多词性词的前后词的词性来判断这个词属于什么词性。
比如:我是一个学统计的学生。系统发现“统计”前面的词“学”是一个动词,因此“统计”这个词再这边属于名词的概率更大。
又如:领导叫我统计总数。这边的“统计”前面是一个主语,且是一个人称代词,后面是一个名词,因此这边的“统计”是一个动词的概率更大。
详细的,去除停用词如下:
根据停用词典,将分词结果中的无用的停用词滤除,停用词如:“的”、“了”、“地”等。
详细的,消除脏数据如下:
脏数据主要是水军发布的包含敏感词的分词结果、整个句子中存在较少词,较多单字的分词结果。
优选的,如图3所示,对所述文本内容进行分词包括:
对所述文本内容依次进行原子切分、根据分词词典和歧义词词典并采用预设的多种算法进行分词、未登录词识别、嵌套未登录词识别、基于类的隐马分词。具体的,基于类的隐马科夫分词是对于多个分词结果选择最优分词结果的一个过程,通过对每个分词结果,计算其整个结果出现的概率值,取其概率值最大的分词结果作为输出结果,该模型已被证明在语音识别、行为识别等领域非常适用。
较佳的,所述预设的多种算法包括正向最大匹配法、逆向最大匹配法和统计分词。
详细的,正向最大匹配法如下:
例句:中华民族从此站起来了
算法逻辑:
1.取出第一个字“中”,去词典匹配发现这不是一个词,但存在一些词以“中”字开头,因此需要继续匹配;
2.取出前两个字“中华”,去词典匹配发现这是一个词,但同样存在词以“中华”开头,因此继续匹配;
3.取出前三个字“中华民”,去词典匹配发现这不是一个词,但同样存在词以“中华民”开头,因此继续匹配;
4.取出前四个字“中华民族”,去词典匹配发现是一个词,并且没有其他词以“中华民族”开头,因此将“中华民族”切分出来;
5.将整个句子中去除“中华民族”,继续按照逻辑从第1点开始同样的匹配,直至整个句子匹配完毕。
最后得到结果:中华民族/从此/站起来/了
详细的,逆向最大匹配法如下:
例句:我们在野生动物园玩
算法逻辑:
1.整个句子去词典匹配,发现不是一个词;
2.去掉第一个字,即用“们在野生动物园玩”去词典匹配,发现不是一个词;
3.再去掉第一个字,用“在野生动物园玩”去词典匹配,发现不是一个词;
最后得到第一个分词结果“玩”;
整个句子去掉“玩”字,继续按照逻辑从第1点开始匹配,直至整个句子匹配完毕。
最后得到结果:我们/在/野生动物园/玩
由于字典在匹配时会动态的计数,没当1个词出现1次,就会在其权重上加1,当文本正向和逆向匹配完成后,计算哪种分词结果出现的概率更大。
两种分词结果中,每个词出现的概率相乘,计算得到的概率更大的分词结果作为实际的输出结果。
详细的,统计分词如下:
将整个文本以每个字为单位切分,计算所有文本中每个字出现的次数n,以及整个文本的总字数N。
每个字出现的概率为p=n/N。
将整个文本以2个字为单位切分,计算这两个字连续情况下在整个文本中出现的次数n1,以及整个文本中2个字的总次数N1,
这两个字在整个文本中出现的概率为p1=n1/N1。
比如一个词:“统计”,如果“统”字出现的概率为1%,“计”字出现的概率为2%,则如果“统计”这两个字连续出现的概率为1%*2%。
若实际在文本中计算得到“统计”这个词组实际出现的概率远大于1%*2%(一般为50到100倍),则说明实际上“统计”这是一个词,而非是两个无关的字。
统计分词主要用来发现新词,即字典中没有的词,但是通过统计后发现其应该是一个词,之后在后台上列出,由人工审核后决定是否添加入词典。
较佳的,所述基于类的隐马分词之后还包括进行词性标注。具体的,词性标注主要用以在构建知识图谱时能很快找出名词、人名等语义实体。
较佳的,未登录词识别之后,还包括将识别到的未登录词更新补充入所述分词词典和歧义词词典。相应的,嵌套未登录词识别之后,还包括将识别到的嵌套未登录词更新补充入所述分词词典和歧义词词典。具体的,将未登陆词及嵌套未登录词更新入分词词典以及歧义词词典,是为了下一次分词时能直接识别出这些词,而不是再一次去识别未登录词,以提高分词效率。
实施例二
本发明还提供另一种兴趣识别系统,包括:
收集处理模块,用于收集文本内容和结构化数据,对所述文本内容进行处理,得到非结构化的带顺序的词组集合;
抽取模块,用于对所述非结构化的带顺序的词组集合和/或结构化数据进行语义实体的抽取、文本实体的抽取、语义实体间关系的抽取、及文本实体与语义实体间关系的抽取;
归并模块,用于对抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系进行语义实体的归并;
知识图谱形成模块,用于将归并后的抽取到的语义实体、语义实体间关系、及文本实体与语义实体间关系形成知识图谱;
第一判断模块,用于根据所述知识图谱,将每个用户的一定时间范围内的访问行为数据和互动行为数据中的文本实体关联到对应的语义实体,通过统计学判断每个用户访问时是否有侧重的语义实体;
兴趣标签模块,用于若有所述侧重的语义实体,将所述侧重的语义实体作为该用户的兴趣标签。
优选的,所述兴趣标签模块,用于获取用户的基本标签,将所述基本标签归入到对应预设类别的分组标签;将所述侧重的语义实体和分组标签进行组合作为该用户的兴趣标签。
优选的,所述一定时间范围内为最近一定时间范围内。
优选的,所述系统还包括:
第二判断模块,用于若无侧重的语义实体,判断用户是否访问量过高,若是,判断该用户可能是爬虫。
优选的,所述系统,还包括:
第三判断模块,用于若无侧重的语义实体,判断用户访问的语义实体是否相悖,且互动量较高,若是,则判断该用户是水军。
优选的,所述系统还包括推荐模块,用于根据用户的兴趣标签向用户推荐内容。
优选的,所述收集处理模块,用于对所述文本内容依次进行分词、歧义词处理、词性识别、去除停用词、消除脏数据的处理。
优选的,所述收集处理模块,用于对所述文本内容依次进行原子切分、根据分词词典和歧义词词典并采用预设的多种算法进行分词、未登录词识别、嵌套未登录词识别、基于类的隐马分词。
优选的,所述预设的多种算法包括正向最大匹配法、逆向最大匹配法和统计分词。
优选的,所述收集处理模块,用于在所述基于类的隐马分词之后进行词性标注。
优选的,所述收集处理模块,用于在未登录词识别之后,将识别到的未登录词更新补充入所述分词词典和歧义词词典。
优选的,所述收集处理模块,用于在嵌套未登录词识别之后,将识别到的嵌套未登录词更新补充入所述分词词典和歧义词词典。
实施例二的其它详细内容,具体可参见实施例一的对应部分,在此不再赘述。
综上所述,本发明使用用户浏览的文本内容构建知识图谱,并从中抽取用户兴趣点,能够帮助提升对于内容的搜索及推荐的精准度。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
显然,本领域的技术人员可以对发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包括这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!