一种用户浏览行为的兴趣挖掘方法与流程
本发明属于大数据处理和分析的技术领域,具体地涉及一种用户浏览行为的兴趣挖掘方法。
背景技术:
在互联网逐渐步入大数据时代后,随着大数据技术的深入研究与应用,企业的专注点日益聚焦于利用大数据来刻画“用户画像”,进而深入挖掘潜在的商业价值,用户兴趣挖掘可以挖掘出不同的兴趣人群,方便做精准营销服务。
用户上网会浏览很多网站,从这众多的网站中挖掘出用户的兴趣偏好就是兴趣挖掘,现有的技术中,方法A是对一些网站进行兴趣标注,如京东、天猫网站对应着“电商购物偏好”,爱奇艺、优酷土豆对应着“影音娱乐偏好”,设定一个阈值,当用户一定时间内访问京东、天猫网站超过这个阈值时,即判定这个用户有“电商购物偏好”。
方法B是首先有大量的标注样本,如用户A的标注兴趣是“电商购物偏好”,用户B的标注兴趣是“影音娱乐偏好”等,然后通过有监督的机器学习方法以这些标注样本做训练集,训练多分类器,来对其他未标注样本进行兴趣预测、分类;还有一种做法是类似于推荐系统里面的协同过滤,通过计算未标注用户与已标注用户的相似度,将相似度高的已标注用户的兴趣赋给未标注用户。
方法A简单有效、易实现,但是效果的好坏受限于网站标注规模的大小,如只把京东、天猫网站标注为“电商购物偏好”,那么有用户访问了“唯品会”、“国美”、“苏宁”等网站,就会被忽略,对应不到“电商购物偏好”,而人工不可能标注上所有的电商购物类网站,标注规模越大,人工成本越高。
方法B利用有监督的机器学习模型来解决兴趣挖掘问题,首先得需要大量用户的兴趣标注样本,这个在多数场景下不容易解决,面临着冷启动的问题,最初始的那一批用户兴趣标注样本不容易获得,另外标注的这批用户访问网站信息随着时间更新时,用户兴趣发生变化时,通过用户之间的相似度来给用户预测兴趣标签会存在问题。
技术实现要素:
本发明的技术解决问题是:克服现有技术的不足,提供一种用户浏览行为的兴趣挖掘方法,其人工标注成本大大降低,当用户访问网站信息更新、兴趣发生变化时,只需要每周或者每月用模型重新计算一下所有用户的兴趣标签即可。
本发明的技术解决方案是:这种用户浏览行为的兴趣挖掘方法,用户u1,u2,u3,指定时间内用户u1访问了网站标签t1,t2,t3,用户u2访问了网站标签t2,用户t3访问了网站标签t2,t3,该方法包括以下步骤:
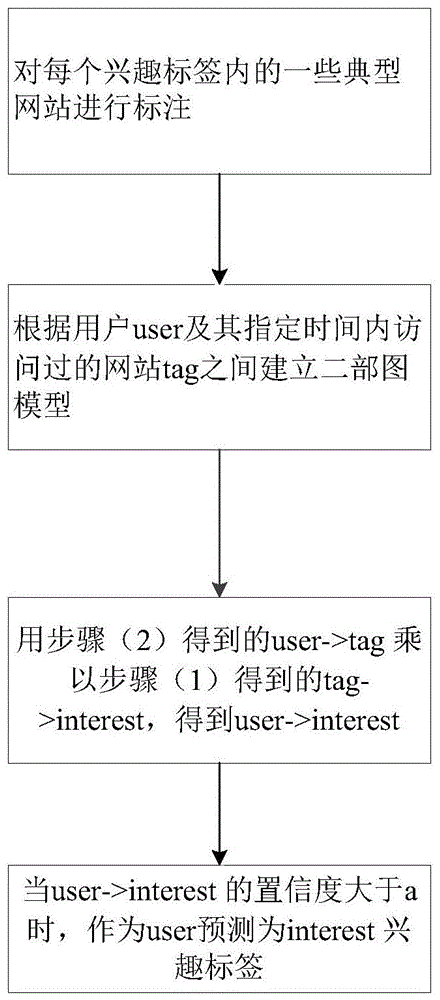
(1)对每个兴趣标签内的一些典型网站进行标注,此时这些标注的网站tag->interest对应兴趣的权重默认为1.0;
(2)根据用户user及其指定时间内访问过的网站tag之间建立二部图模型,通过n轮随机游走,其中n为正整数,user1->tag1->user2->tag2->user3->tag3,汇总多轮游走的结果,计算出user->tag的权重;
(3)用步骤(2)得到的user->tag乘以步骤(1)得到的tag->interest,得到user->interest,user->interest是每个用户到所有兴趣标签的一个置信度值,介于0-n之间,n是随机游走迭代的次数;
(4)设置一个阈值a,当user->interest的置信度大于a时,作为user预测为interest兴趣标签。
本发明对用户和其访问过的网站标签进行二部图建模,通过随机游走,只需要人工标注少量的网站,即可计算出用户的兴趣标签,因此人工标注成本大大降低;因为是对网站进行标注,而不是对用户标注,所以用户访问网站信息更新,兴趣发生变化时,只需要每周或者每月用模型重新计算一下所有用户的兴趣标签即可。
附图说明
图1是根据本发明的用户浏览行为的兴趣挖掘方法的流程图。
图2示出了用户及其访问网站tag的二部图模型。
具体实施方式
如图1、2所示,这种用户浏览行为的兴趣挖掘方法,用户u1,u2,u3,指定时间内用户u1访问了网站标签t1,t2,t3,用户u2访问了网站标签t2,用户t3访问了网站标签t2,t3,该方法包括以下步骤:
(1)对每个兴趣标签内的一些典型网站进行标注,此时这些标注的网站tag->interest对应兴趣的权重默认为1.0;
(2)根据用户user及其指定时间内访问过的网站tag之间建立二部图模型,通过n轮随机游走,其中n为正整数,user1->tag1->user2->tag2->user3->tag3,汇总多轮游走的结果,计算出user->tag的权重;
(3)用步骤(2)得到的user->tag乘以步骤(1)得到的tag->interest,得到user->interest,user->interest是每个用户到所有兴趣标签的一个置信度值,介于0-n之间,n是随机游走迭代的次数;
(4)设置一个阈值a,当user->interest的置信度大于a时,作为user预测为interest兴趣标签。
本发明对用户和其访问过的网站标签进行二部图建模,通过随机游走,只需要人工标注少量的网站,即可计算出用户的兴趣标签,因此人工标注成本大大降低;因为是对网站进行标注,而不是对用户标注,所以用户访问网站信息更新,兴趣发生变化时,只需要每周或者每月用模型重新计算一下所有用户的兴趣标签即可。
更进一步地,所述步骤(2)包括以下分步骤:
(2.1)通过用户user访问网站tag的次数pv和天数dv进行加权求和,然后归一化得到初始的user->tag和tag->user的权重;
(2.2)用tag->user的权重乘以user->tag的权重,得到tag->tag的权重;
(2.3)设第1轮游走迭代的user->tag的权重为步骤(2.1)中得到的user->tag的值,记为I1,那么设第n轮游走迭代的结果为In,则In+1=In*(tag->tag);
(2.4)汇总求和:tag->user=I1+I2+…..In。
更进一步地,所述步骤(2.1)中,用户访问所有网站的pv和dv都是相同的,那么user1->tag1=1/3,user1->tag2=1/3,user1->tag3=1/3,user2、user3的计算与user1的计算相同;tag3->user1=1/2,tag3->user3=1/2,tag1、tag2的计算与tag3的计算相同。
更进一步地,所述步骤(2.2)中计算结果为:
tag2->tag1=(tag2->user1)*(user1->tag1)=1/3*1=1/3,
tag2->tag3=(tag2->user1)*(user1->tag3)+(tag2->user3)*(user3->tag3)
=1/3*1/3+1/3*1/2=5/18,
tag1,tag3计算同tag2。
更进一步地,所述步骤(2.3)中第2轮随机游走:
user1->tag3=(user1->tag1)*(tag1->tag3)+(user1->tag2)*(tag2->tag3)=1*1/3+1/3*5/18=23/54。
本发明的有益效果如下:
1.人工标注量少,依赖人工少。
2.模型方便定期更新,能够及时跟踪用户兴趣变化。
以上所述,仅是本发明的较佳实施例,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!