一种神经网络关系抽取方法与流程
本发明涉及自然语言处理技术领域,特别涉及一种神经网络关系抽取方法。
背景技术:
随着社会飞速发展,目前已经进入信息爆炸时代,每天都有海量新的数据产生。互联网作为目前最为便捷的信息获取平台,用户对有效信息筛选与归纳的需求日益迫切,如何从海量数据提取有效信息成为一个难题。为了解决这个难题,提出了知识图谱概念,知识图谱将海量数据中的专用名词及事物的名词表示为实体,专用名词为世界上所有人物、地名、书名或球队等,将实体之间的内在联系表示为关系,旨在将海量数据表示为实体之间利用关系作为桥梁的三元关系组。例如,“北京是中国的首都”这一数据,在知识图谱中则利用三元组关系表示为:北京,是…首都,中国。
虽然已经建立的知识图谱包含了上亿个数据,但是相比于无尽的数据,其仍然远远没有完善。为了不断地对知识图谱进行自动完善,采用了很多技术。其中就有关系抽取技术,该技术能够自动的从自然语言文本中抽取有结构数据。
目前,在关系抽取技术中常常采用基于监督学习的关系抽取技术,这个技术需要大量的人工标注训练数据,非常的耗时费力。针对这个问题,基于远程监督的关系抽取技术提出了可以通过对纯文本及已经设置的知识库之间进行对比,自动产生训练数据的技术,基于远程监督的关系抽取技术假设如果两个实体同时出现在一个句子中,那么这个句子就表达这两个实体之间的关系,通过这个假设,可以使用设置的知识库中所有包含这两个实体的句子作为这两个实体关系的训练数据。但是,基于远程监督的关系抽取技术得到训练数据存在一个严重的问题,就是产生的训练数据的噪声非常严重,因为并不是所有的包含两个实体的句子都会反映这两个实体之间的关系。为了减小训练数据的噪声,在产生训练数据时通过概率图模型的方法对基于远程监督的关系抽取技术进行处理,即通过联合概率化句子与两个实体之间的关系解决。
更进一步地,如果关系抽取技术采用非神经网络方法,则由于非神经网络引入了自然语言处理工具抽取关系特征,也不可避免地引入了一些噪声。目前,关系抽取技术采用神经网络的模型实现,但是,神经网络的模型在处理远程监督数据产生的噪音上还没有行之有效的方法。因此,如何解决神经网络方法在远程监督数据上的应用是一个十分重要的问题。
技术实现要素:
有鉴于此,本发明实施例提供一种神经网络关系抽取方法,该方法能够对远程监督数据的噪音进行处理,提高关系抽取效果。
根据上述目的,本发明是这样实现的:
一种神经网络关系抽取方法,该方法包括:
对每个句子和其相关的一对实体,采用卷积神经网络构建所述一对实体的句子向量表示;
采用设置的句子级别注意力机制选择其中的表达了所述一对实体间的关系的句子向量表示,得到所述一对实体的综合句子向量表示;
根据所述一对实体的综合句子向量表示进行所述一对实体间的关系预测,得到预测值。
较佳地,所述构建所述一对实体的句子向量表示为:
对句子中的一对实体分别构建词向量,所述词向量包括词义向量与位置向量的拼接信息;
通过卷积、池化和非享有操作将所述词向量转换为句子向量表示。
较佳地,所述通过卷积、池化和非享有操作将所述词向量转换为句子向量表示为:
首先,将一个词向量序列w和卷积矩阵W之间进行操作,卷积操作可以通过一个长度为l的滑动窗口对局部特征进行提取。首先定义qi为在第i个窗口内部的所有的词向量的拼接信息:
qi=wi-l+1:i(1≤i≤m+l-1);
其次,将所有超出句子边界的词的词向量看成似乎零向量;
然后,卷积得到的第i维特征定义为:pi=[Wq+b]i;其中b为偏置向量;
再次,句子向量表示的第i维通过池化定义为:[x]i=max(pi);或者采用分段池化,将卷积得到的每一维特征pi从头实体和尾实体分为三段(pi1,pi2,pi3),然后分别对每一段进行池化:[x]ij=max(pij);
最后,[x]i定义为[x]ij的拼接,在对向量x进行非线性化,得到最终的句子向量表示。
夹角地所述采用设置的句子级别注意力机制选择其中的表达了所述一对实体间的关系的句子向量表示,得到所述一对实体的综合句子向量表示的过程为:
定义所有句子的综合向量表示;
采用平均的方式定义每一个句子向量的权重;
采用设置的句子级别注意力机制定义每一个句子向量表示的权重。
较佳地,所述定义所有句子的综合向量表示为:
假设所有句子的表示向量为x1,x2,…,xn,将句子的综合向量表示定义为所有句子向量表示向量的加权和:
其中αi定义为每一个句子向量xi的权重。
较佳地,所述采用平均的方式定义每一个句子向量的权重为:
假设所有句子向量表示对于最终得到的所述对实体的综合句子向量表示的贡献均等,得到的所述对实体的综合句子向量表示即为每一个句子向量表示的平均值,如下公式所示:
较佳地,所述采用设置的句子级别注意力机制定义每一个句子向量表示的权重为:
采用设置的选择双线性函数衡量每一个句子的向量表示xi和最终要预测的所述对实体间的关系r之间的关联程度,如下公式:
ei=xiAr;
其中,A为对角的参数矩阵,r为查询的目标关系r的向量表示,通过选择注意力机制定义每一个句子向量表示的权重如下:
较佳地,所述根据所述一对实体的综合句子向量表示进行所述一对实体间的关系预测,得到预测值为:
首先,定义最终预测的关系的概率,所述概率定义为:
其中nr为所有关系种类的个数,o为最终神经网络的输入,定义如下:
o=Ms+d
其中d为偏置向量,M为所有关系向量表示矩阵;
其次,通过随机梯度下降,最小化评价函数,对所有参数进行学习与更新,包括:通过最小化评价函数学习所有的参数。评价函数公式如下:
其中s为所有训练句子集合的个数,θ表示所有的模型参数,采用随机梯度下降算法进行参数优化。
最后,通过信号丢失防止训练过拟合,包括:采用信号丢失机制,最终的输出o进一步定义为:其中h为每一维概率为p的伯努利分布的向量,将最终的所有句子表示向量乘以p,得到
由上述方案可以看出,本发明实施例提出了基于句子级别选择注意力机制的神经网络关系抽取方法,具体为:对每个句子和其相关的一对实体,采用卷积神经网络构建所述一对实体的句子向量表示;采用设置的句子级别注意力机制选择其中的表达了所述一对实体间的关系的句子向量表示,得到所述一对实体的综合句子向量表示;根据所述一对实体的综合句子向量表示进行所述一对实体间的关系预测。这样,本发明实施例不但可以在神经网络关系抽取中降低远程监督数据中噪音的干扰,还可以同时考虑不同句子的信息,提高模型的稳定性,具有良好的实用性。
附图说明
图1为本发明实施例提供的神经网络抽取关系的方法流程图;
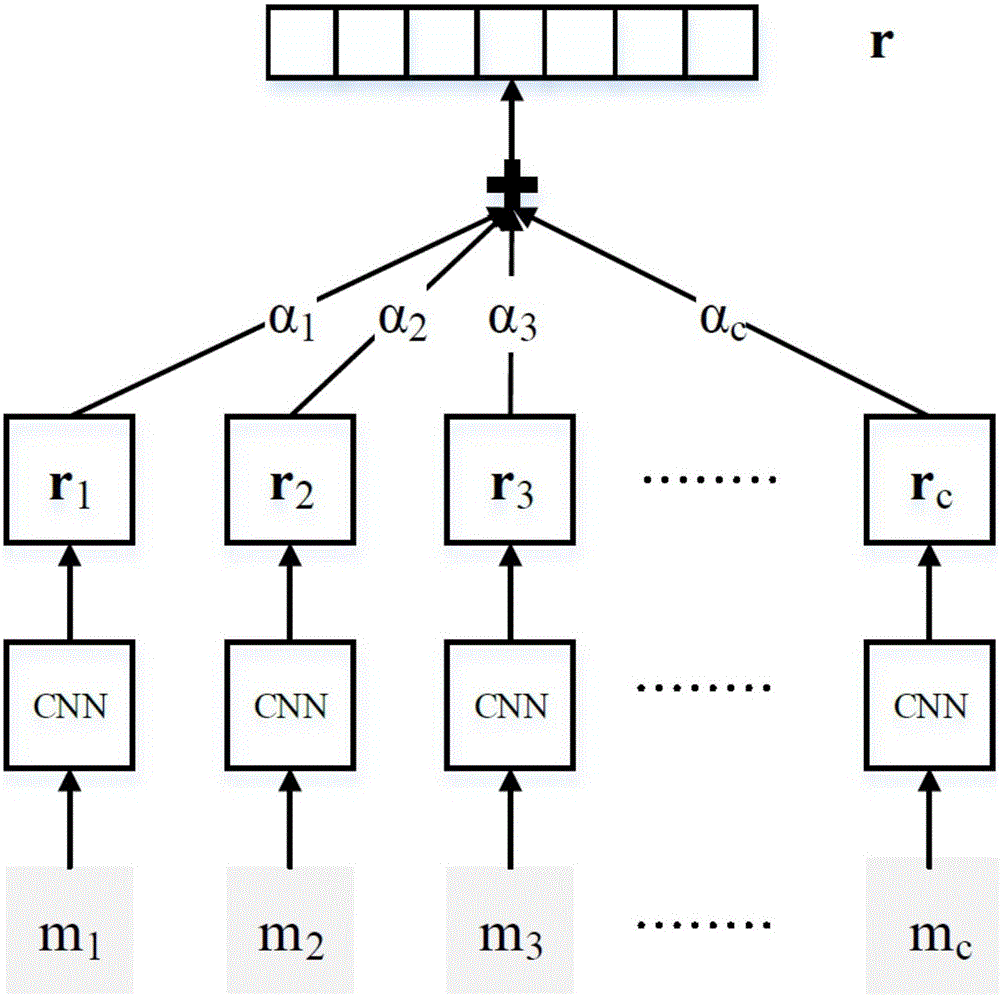
图2为本发明实施例提供的采用设置的句子级别注意力机制选择其中的表达了所述对实体间的关系的句子向量表示后,得到所述对实体的综合句子向量表示的示意图;
图3为本发明实施例提供的图1所述的方法具体例子示意图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本发明作进一步详细说明。
图1为本发明实施例提供的神经网络抽取关系的方法流程图,其具体步骤为:
步骤101、对每个句子和其相关的一对实体,采用卷积神经网络构建所述一对实体的句子向量表示;
步骤102、采用设置的句子级别注意力机制选择其中的表达了所述一对实体间的关系的句子向量表示,得到所述一对实体的综合句子向量表示;
步骤103、根据所述一对实体的综合句子向量表示进行所述一对实体间的关系预测,得到预测值。
在该方法中,所述步骤101的具体过程为:
步骤1011、对句子的输入的单词进行表示,得到词向量;
在本步骤中,卷积神经网络的输入为句子的所有单词。首先将句子中的所有单词转化为连续的向量表示。这里,每一个输入的单词转化为一个词向量矩阵中的向量;
进一步地,本步骤还使用位置向量对两个实体的位置区分。这里,词向量用于标识每个单词的语法和语义信息,采用文本深度表示模型(word2vec)学习得到;位置向量用于表示实体的位置信息,定义为每个单词和头实体、尾实体之间的相互位置差的向量表示。最终的词向量定义为word2vec学习到的词义向量与位置向量的拼接信息。
步骤1012、通过卷积,池化和非线性操作将输入的单词表示转化为句子的向量表示;
在本步骤中,卷积操作定义为将一个词向量序列w和卷积矩阵W之间的操作,卷积操作可以通过一个长度为l的滑动窗口对局部特征进行提取。首先定义qi为在第i个窗口内部的所有的词向量的拼接信息:
qi=wi-l+1:i(1≤i≤m+l-1)
由于窗口滑动时可能会超过句子的边界,在句子的边界加入一些空白词,也就是说,将所有超出句子边界的词的词向量看成似乎零向量。然后,卷积得到的第i维特征定义为:
pi=[Wq+b]i
其中b为偏置向量;
进一步地,最终句子的表示的第i维通过池化定义为:
[x]i=max(pi)
此外,在关系抽取任务中,考虑了两个实体的位置之后,池化可以进一步改进为分段池化,将卷积得到的每一维特征pi从头实体和尾实体分为三段(pi1,pi2,pi3),然后分别对每一段进行池化:
[x]ij=max(pij)
然后[x]i定义为[x]ij的拼接。
在本步骤中的最后,在对向量x进行如tanh函数的非线性化,得到最终的句子向量表示。
在该方法中,所述步骤102具体为:
步骤1021、定义所有句子的综合向量表示;
很直观地,假设所有句子的表示向量为x1,x2,…,xn,将句子的综合向量表示定义为所有句子向量表示向量的加权和:
其中αi定义为每一个句子向量xi的权重;
步骤1022、采用平均的方式定义每一个句子向量的权重;
在本步骤中,假设所有句子向量表示对于最终得到的所述对实体的综合句子向量表示的贡献均等,那么最终得到的所述对实体的综合句子向量表示即为每一个句子向量表示的平均值,如下公式所示:
步骤1023、采用设置的句子级别注意力机制定义每一个句子向量表示的权重;
在本步骤中,采用一个基于查询的函数来衡量每一个句子的向量表示xi和最终要预测的所述对实体间的关系r之间的关联程度。这里采用选择双线性函数来定义:
ei=xiAr;
其中,A为对角的参数矩阵,r为查询的目标关系r的向量表示,可以通过选择注意力机制定义每一个句子向量表示的权重如下:
由于考虑了最终要预测的所述对实体间的关系r的信息,采用设置的句子级别注意力机制进行选择之后,每一个句子向量的权重可以有效的将噪音句子的最终权重降低。
在该方法中,所述步骤103进一步步骤:
步骤1031、定义最终预测的关系的概率;
在本步骤中,将给定所有句子的集合和所述对实体,最终预测得到的每一种关系的概率定义为:
其中nr为所有关系种类的个数,o为最终神经网络的输入,定义如下:
o=Ms+d
其中d为偏置向量,M为所有关系向量表示矩阵;
步骤1032、通过随机梯度下降,最小化评价函数,对所有参数进行学习与更新;
具体地,通过最小化评价函数学习所有的参数。评价函数公式如下:
其中s为所有训练句子集合的个数,θ表示所有的模型参数,采用随机梯度下降算法进行参数优化。
步骤1033、通过信号丢失防止训练过拟合;
在本步骤中,为了防止训练过拟合,采用了现有的信号丢失机制,最终的输出o进一步定义为:
其中h为每一维概率为p的伯努利分布的向量。在最终的预测里,将最终的所有句子表示向量乘以p,也就是
图2为本发明实施例提供的采用设置的句子级别注意力机制选择其中的表达了所述对实体间的关系的句子向量表示后,得到所述对实体的综合句子向量表示的示意图,其中,m1,m2,…,mc为每个句子向量表示,r1,r2,…,rc为各个所述对实体间的关系表示,将两者进行关联后,采用公式通过选择注意力机制定义每一个句子向量表示,得到最终的r。
图3为本发明实施例提供的图1所述的方法具体例子示意图,如图所示,由下到上,一个句子中的一对实体按照图1所述的方法,经过层层粗粒之后,最终得到了所述对实体间的关系预测值。
由上述方案可以看出,本发明实施例提出了基于句子级别选择注意力机制的神经网络关系抽取方法,不但可以在神经网络关系抽取中降低远程监督数据中噪音的干扰,还可以同时考虑不同句子的信息,提高模型的稳定性,具有良好的实用性。
以上举较佳实施例,对本发明的目的、技术方案和优点进行了进一步详细说明,所应理解的是,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!