本发明涉及一种GPU虚拟化实现系统及方法。
背景技术:
在GPU(Graphics Processing Unit图形处理器)虚拟化领域,目前存在三类典型的技术方案。
(1)NVIDIA主导的GRID GPU虚拟化技术
NVIDIA的GPU虚拟化方案基于其特殊设计的一款GPU显卡,该类型GPU可以模拟若干GPU的能力,从而同时为若干台虚拟机提供服务,这些模拟出来的GPU单元称为vGPU。每台虚拟机绑定一个独立的vGPU,使得GUEST操作系统和其中运行的3D应用直接使用vGPU的处理能力,达到接近于物理计算机使用本地硬件GPU处理的效果体验。
目前,Citrix、VMware以及Microsoft(RemoteFX)都基于GRID硬件,推出了自己的桌面/应用虚拟化方案,以提升其产品对3D应用的支持能力。
GRID GPU虚拟化技术已经取得一些商业化应用,但在实际中主要面临成本过高的问题。以入门级GRID K1显卡(支持8个vGPU)为例,目前其市场价格在一万元左右。而实际中,虚拟化环境需要支持的客户虚拟机数量可能达到数十台至上百台,所以显卡的投入会占据建设投资的主要比重。同时,在服务器上额外增加GRID卡,通常要受到服务器类型、设计能力等因素的影响,PCI总线能力、内存容量等都是软硬件升级方案需要考虑的方面,这也显著增加了相关成本和实施的复杂性。
(2)INTEL的XENGT/KVMGT GPU虚拟化技术方案
Intel XENGT/KVMGT方案的主要原理是,在虚拟化层为每台虚拟机模拟一块独立GPU显卡(以下也称为vGPU),vGPU对上层应用提交的3D操作请求,按照其类型识别为两类:显存操作请求和寄存器IO操作请求。对于显存操作请求,直接映射操作宿主机层硬件GPU中的一块对应显存,称为Passthrough方式,由于跨过中间若干环节,可以减少时间资源的消耗,提高整体处理效率;对于寄存器IO操作请求,采用陷入再模拟的方式统一安排调度,称为Trap方式,达到一套硬件GPU计算单元分时复用的目的。所以,XENGT/KVMGT方案试图通过一块成本较低GPU卡,同时支持多台虚拟机对GPU的需求。
该方案面临的主要问题是,必须依赖于Intel特定型号的芯片支持。Intel的GPU是与CPU集成的,不同型号用途的CPU搭载相应的GPU或者根本没有集成GPU。对于服务器而言,出于用途和成本考虑,其使用的CPU大多不集成GPU。因而在实际环境中,XENGT/KVMGT技术的应用推广具有很大的局限性。
(3)利用纯软件库模拟GPU
前面所述两种技术方案最终都需要硬件GPU支持,与它们相对应,还有一种纯软件模拟的技术方案。其原理是:在API层实现一个软件库,使得在没有GPU或仅具备低端GPU的设备上,可以模拟运行3D应用。最典型的实现是MESA,一个用于模拟OpenGL设备的开源软件库,它最基本的运行模式是纯软件模拟方式;Microsoft的Directx也支持类似的软设备模拟模式。这类软件库无论是安装到虚拟机操作系统还是实体机操作系统中,都可以模拟GPU能力,从而运行各种主流3D应用。
纯软件库模拟GPU技术,其最大的问题是性能很差,因而主要用于软件调试环境或作为硬件GPU部分特性的补充;目前不适合应用到实际生产环境中。
技术实现要素:
本发明为了解决上述问题,提出了一种GPU虚拟化实现系统及方法,本发明为虚拟机提供虚拟GPU能力,支持主流3D应用的流畅运行。能够适应现实情况,不要求服务器外接或内置GPU硬件;从vGPU运行效率出发,整体上调整了系统虚拟化的体系结构,克服传统软件模拟库效率低下的问题。
为了实现上述目的,本发明采用如下技术方案:
一种GPU虚拟化实现系统,包括vGPU驱动模块、vGPU前端模块以及vGPU后端模块,其中:
所述vGPU驱动模块,隶属于客户机操作系统,向应用层提供vGPU支持的操作类型和支持的级别,同时截获虚拟设备层的3D请求,同时确认虚拟设备的特性信息;
所述vGPU前端模块,被配置为模拟能够被客户机操作系统发现的GPU显卡设备,具备PCI设备特性、VGA设备特性以及GPU设备特性,为vGPU驱动模块和vGPU后端模块提供衔接渠道;
所述vGPU后端模块,被配置为基于物理层硬件,通过调度并处理vGPU前端模块提交的3D请求,对服务器的物理CPU进行分组,然后选择其中一组CPU专用于GPU功能模拟从而最终完成vGPU功能。
所述vGPU后端模块,被配置在宿主机操作系统内,与物理层通讯,同时与客户机虚拟设备层的vGPU前端模块通讯,所述vGPU前端模块接收客户机操作系统的vGPU驱动模块发出的驱动请求。
所述vGPU前端模块,被配置为通过Qemu模拟向vGPU驱动模块提供ROM、RAM和I/O寄存器组三种形式的交互接口,所述ROM提供vGPU显卡的硬件信息和资源设置,RAM提供显示资源缓冲区,I/O寄存器组提供刷新命令和配置命令。
所述vGPU前端模块与vGPU后端模块共享内存实现通信,所述共享内存提供命令队列和资源缓存两种形式的接口,命令队列负责传递操作命令,资源缓存负责维护与命令相关的资源。
所述vGPU前端模块通过Qemu进程通过共享内存接口发出服务请求,vGPU后端模块为流水线进程,基于共享内存接口响应请求,提供GPU服务,前端Qemu进程由支持虚拟机的CPU组负责调度运行;流水线进程专门由Backend组CPU运行,两进程采用并发运行模式。
所述vGPU驱动模块提供一个支持特性集,说明vGPU能够支持的操作类型和支持的级别,如果集合中标记了对某项特性的支持,则必须在vGPU前端模块和vGPU后端模块的实现中支持此特性。
所述vGPU前端模块在虚拟机启动阶段被客户机操作系统发现,其被配置为表现为挂载在一级PCI总线的设备,具备独立的开发商型号和设备型号,同时保证vGPU前端模块模拟的信息与vGPU驱动模块指定的信息一致。
所述vGPU前端模块被设置有VGA设备特性,通过修改虚拟化设施中的显存资源地址范围,I/O寄存器地址范围和中断向量表地址范围来实现。
所述vGPU前端模块被设置有GPU设备特性,当增加显存段或显存页表机制时,vGPU前端模块能够任意分配显存资源,满足GPU对渲染目标平面和纹理操作的要求,支持GPU特性集合的设置与维护。
一种GPU虚拟化实现方法,包括以下步骤:
(1)进行宿主机操作系统的进程绑定CPU操作,对物理CPU进行分组使用;
(2)利用一个独立进程来承载GPU的计算能力,作为vGPU后端,构建支持多线程/多上下文的内存区域与3D处理流水线;
(3)修改虚拟化设施的设备特性,向上层驱动提供I/O寄存器组和内存映射方式两种接口,利用基于内存的前后端协同通信方式与vGPU后端通信;
(4)以vGPU前端为基础,向操作系统和应用层报告3D方面的支持特性集,并把3D操作请求转给vGPU前端处理,在驱动层截获系统渲染请求数据和进程渲染请求数据,基于Spice协议转至终端完成实际渲染。
所述步骤(1)中,对物理CPU分为三组使用,具体包括第一组用于支持虚拟机、第二组用于支持vGPU和第三组用于支持宿主机常规进程。
本发明的有益效果为:
(1)相对于GRID技术和XENGT/KVMGT等硬件辅助技术,本发明不要求外插/内置GRID显卡,也不要求升级更换搭载具备GPU功能的CPU型号。因而在适应性和实施成本控制方面具备优势;
(2)针对现有软件库模拟方式性能低的问题,本发明以调整系统虚拟化体系结构的方式,在物理层隔离出若干物理CPU专门用于执行GPU功能,解决因为虚拟机/进程上下文切换导致的无谓损耗问题。同时,这组CPU与虚拟机使用的CPU组并行工作,原理上相当于真实GPU与CPU协同并行工作的方式,有利3D系统处理性能的发挥;
(3)本发明在驱动层截获3D请求的高级语义,通过合并优化请求,显著的提升3D处理效率。
附图说明
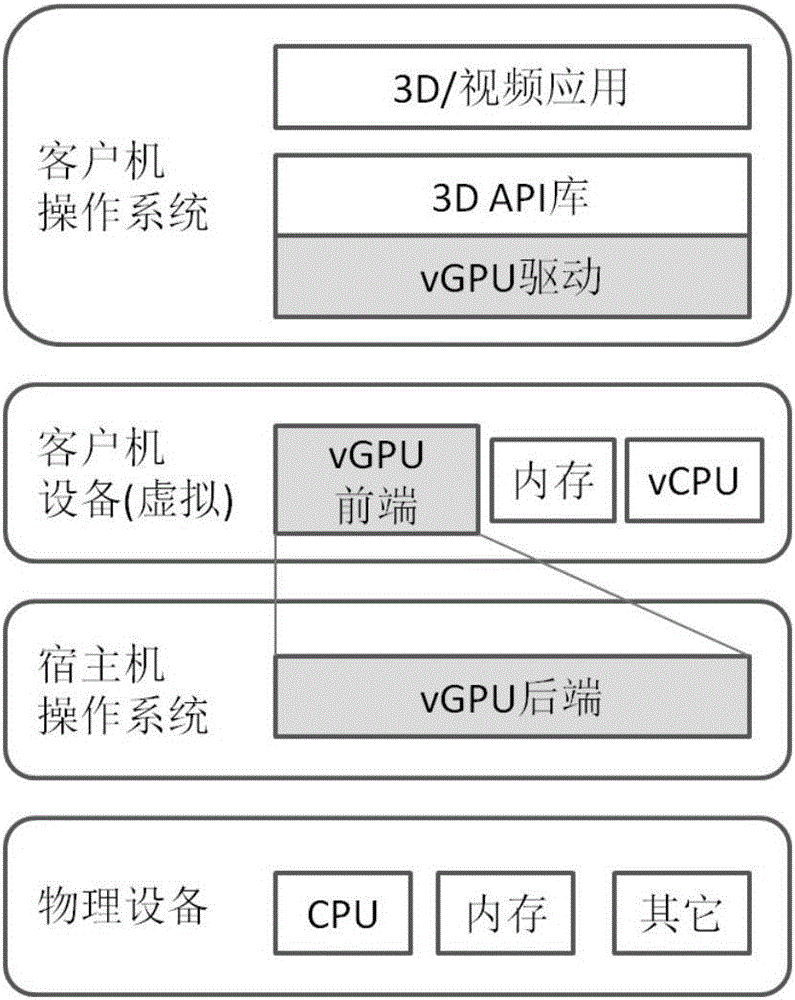
图1为本发明的整体逻辑框架示意图;
图2为本发明的CPU分组控制示意图;
图3为本发明的vGPU驱动与vGPU前端的交互过程示意图;
图4为本发明的vGPU前端与vGPU后端的交互过程示意图。
具体实施方式:
下面结合附图与实施例对本发明作进一步说明。
现有主流的GPU虚拟化技术,可分为两类。一类技术要求在服务器上外接或内置GPU硬件,但是由于实际环境中的服务器大多数没有GPU(或相当于GPU的硬件),升级扩展服务器必须付出很高的成本,而且能否升级还要受到许多因素的制约;另一类技术是纯软件方法,直接在API层通过软件库模拟GPU的3D处理能力,虽然不用升级硬件,但是效率很低,不能满足实际生产环境的要求。
本发明的任务是提出一种GPU虚拟化技术方案,为虚拟机提供虚拟GPU能力,支持主流3D应用的流畅运行。相对于现有的第一类方案,本发明适应现实情况,不要求服务器外接或内置GPU硬件;与第二类方案单纯在API层实现功能不同,本发明从vGPU运行效率出发,整体上调整了系统虚拟化的体系结构,克服传统软件模拟库效率低下的问题。
本发明整体逻辑框架如图1所示,包括vGPU驱动、vGPU前端以及后端三个部分,分别属于客户机操作系统、客户机虚拟设备以及宿主机操作系统这三个层次,此外整个体系最终需要物理层CPU和内存等硬件资源的支撑,但是不要求具备硬件GPU。上述各部分相互协作,共同实现vGPU功能。
(1)vGPU驱动
vGPU驱动属于客户机操作系统(GUEST OS)的一部分,驱动的框架遵循客户机操作系统要求的驱动模型规范,例如对于Windows需要遵循WDDM/XDDM模型。本发明以vGPU为基础,实现一个完整的驱动,为上层的操心系统及3D应用提供各种3D能力支持。
vGPU驱动承担抽象硬件层(HAL)的接口功能,负责以下三项功能:
a)向应用层报告vGPU的能力。3D应用在实际使用GPU之前,都会首先查询GPU能力,然后决定是否进入相应的硬件协处理流程。因而vGPU驱动必须提供一个支持特性集,说明vGPU能够支持的操作类型和支持的级别。一旦集合中标记了对某项特性的支持,则必须在vGPU的前后端实现中支持此特性。该集合的定制需要根据实际需要,在支持范围和实现代价之间权衡。对于轻量级的3D应用场景,定义基本级集合,仅包含最基础的3D支持特性;对于需要使用专业3D软件的场景,则必须实现包含更多特性的高级特性集合。
b)截获3D请求。驱动层相对于设备层,更接近于应用,因而可以截获高级语义的3D请求。高级语义3D请求相对数量少,而且容易进行合并或优化。驱动最终把处理后的请求转向vGPU前端进行下一步的处理。这样的效果是:简化vGPU设备的接口设计,消除不必要的中间环节,并能显著提高效率。
c)绑定特定的关键信息。这些关键信息主要包括:开发商标识(VendorID),设备类型标识(DeviceID),资源地址信息等。它们必须与vGPU设备的前后端准备设置的特性相一致,以避免冲突。
(2)vGPU前端
vGPU前端,模拟一个可以被客户机操作系统发现的GPU显卡设备,实现三个层次的特性,包括PCI设备特性、VGA设备特性以及GPU设备特性。从实现角度,vGPU前端功能主要由虚拟化软件设施的设备虚拟化模块支持。因此具体特性的实现需要基于现有虚拟化软件设施进行改造,当前最流行的开源虚拟化软件包括KVM和XEN两类,它们的设备虚拟化设施实际都是Qemu,因此vGPU前端的实现主要集中在对Qemu的改造上。
a)PCI设备特性。vGPU作为PCI设备,首先应当在虚拟机启动阶段被客户机操作系统发现。vGPU必须表现为挂载在一级PCI总线的设备,具备独立的开发商型号和设备型号,以区别于现有的其它设备。实现方法是,修改虚拟化设施中的vgaBIOS以及显卡设备模型,使之支持指定的开发商代号ID和设备型号ID,并具备报告I/O资源和Memory资源的能力。vGPU模拟的信息必须与vGPU驱动指定的信息一致,以此确保在虚拟机操作系统的启动和运行阶段,能够按照PCI设备正常发现vGPU和完成验证检查,避免发生冲突。
b)VGA设备特性。GPU显卡的基础功能是传统的VGA显卡功能,一方面vGPU显卡通常仍然需要利用VGA的部分功能完成某些显示相关的工作;另一方面客户机操作系统会在三种情况下运行在VGA这种低级模式,包括启动阶段、显示模式切换阶段以及系统异常阶段。VGA设备特性实现方法是,修改虚拟化设施中的vgaBIOS以及显卡设备模型,按照标准VGA以及VESA的规范,完成寄存器功能和中断调用功能的模拟。现有的虚拟化设施软件通常都已经具备这些特性,仅需要对可能冲突的部分特性进行调整。包括:显存资源地址范围,I/O寄存器地址范围和中断向量表地址范围。
c)GPU设备特性。vGPU前端作为虚拟设备,其职责为衔接上层的vGPU驱动和下层的vGPU后端。同时作为虚拟设备,不需要实现物理GPU全部的复杂功能。GPU设备特性可以基于现有的虚拟化软件设施中的显卡设备模型进行修改,即修改Qemu。具体要求是,增加显存段或显存页表机制,能够任意分配显存资源,满足GPU对RenderTarget(渲染目标平面)、Texture(纹理)操作的要求,支持GPU特性集合的设置与维护。
(3)vGPU后端
vGPU后端由运行在宿主机中虚拟化软件实现,其职责是基于物理层硬件,通过调度并处理vGPU前端提交的3D请求,从而最终完成vGPU功能。
基本思路是,首先对服务器的物理CPU(颗/核)进行分组,然后选择其中一组CPU专用于GPU功能模拟。用于GPU功能模拟的CPU组,专门运行3D流水线程序,不受其它进程的抢占,与各虚拟机并发工作。
具体实现方法:
a)物理CPU分组控制。调整宿主机操作系统的CPU及进程调度策略,把服务器的物理CPU分成三组,第一组专供虚拟机使用,即支持vCPU功能和通用的设备模拟功能,该CPU组维持经典的系统虚拟化原理功能;第二组CPU则专门作为vGPU后端,完成GPU功能模拟,这是本发明原理的关键(该CPU组称为BackEnd组)。修改调度策略的主要目的,是防止其它进程或虚拟机被调度到BackEnd组,确保这组CPU的专用性;第三组支持宿主机操作系统的其它进程,例如虚拟机管理、远程管理等工具进程。CPU分组控制示意图见图2。
b)BackEnd组构成专用CPU资源池。根据vGPU前端提交的请求负载情况,组中CPU资源动态分配和伸缩,为前端提供足够能力的服务。BackEnd组中物理CPU的数量不必固定,而可以是一个可以配置的范围,这个范围的主要决定因素是实际业务环境中3D应用本身的轻重程度和平均业务量。
c)3D流水线功能。BackEnd组中CPU所运行的进程,由一组3D处理流水线模块构成。每一个流水线模块,对应完成3D处理的一个阶段;阶段之间通过预定义的输入输出格式进行传递。流水线至少需要支持两个阶段:一个是顶点渲染阶段,负责图元位置信息的处理;另一个是像素渲染阶段,负责图元颜色内容的处理。为适应当前占主流地位的定制流水线机制,对于这两个阶段还有一个特殊要求,必须支持外部渲染器(shader)代码的嵌入。
vGPU驱动、前端以及后端三个层次之间的交互方式,具体描述如下。
a)vGPU驱动与vGPU前端的交互,如图3所示。vGPU前端由Qemu模拟实现,向驱动提供三类形式的交互接口。其中,ROM负责提供vGPU显卡的硬件信息和资源设置;RAM提供显示资源缓冲区;I/O寄存器组提供刷新命令、配置命令等。
b)vGPU前端与后端的交互,如图4所示。vGPU的前端由Qemu模拟实现,从宿主机角度,vGPU前端属于Qemu进程;而vGPU的后端是承载3D流水线功能的一组模块,其运行形式也是宿主机操作系统的进程。因而,前后端的交互通信基于共享内存实现。共享内存提供两种形式的接口,命令队列和资源缓存。命令队列负责传递操作命令,资源缓存负责维护大尺寸的资源。前端Qemu进程通过共享内存接口发出服务请求;后端流水线进程,基于共享内存接口响应请求,提供GPU服务。前端Qemu进程由支持虚拟机的CPU组负责调度运行;后端流水线进程专门由Backend组CPU运行。前后端进程是真正的并发运行模式。
本发明的典型实施场景是,基于Linux宿主机操作系统,以QEMU/KVM作为虚拟化设施,以Windows 7作为客户机操作系统,通过Spice虚拟桌面协议支持3D应用的远程使用。以下以此为背景,说明本发明的最佳实施方式,主要包括以下四步。
(1)修改宿主机操作系统的调度策略
修改Linux操作系统的进程CPU亲和性设置,即进程绑定CPU策略,对物理CPU(颗/核)分为三组使用。
a)第一组用于支持虚拟机。Qemu实质上仅是宿主机操作系统中的一个普通进程,可以利用taskset命令行工具完成虚拟机与CPU绑定。通常,根据运行虚拟机的数量,分配相当数量的CPU(颗或核)与之绑定,即典型情况下一对一。
b)第二组用于支持vGPU,即BACKEND组。根据实际业务环境中,3D应用本身的轻重程度和3D请求业务量,决定组内CPU的数量。
c)第三组用于支持宿主机常规进程。作为虚拟机容器的服务器,其它用途的应用进程很少且负载轻,因此通常只要绑定一颗CPU即可。
(2)扩展虚拟化设施软件支持vGPU后端
实现一个独立进程,承载GPU的计算能力,配合Qemu完成vGPU后端功能。对于该进程有两个要求:
a)支持多线程/多上下文。每个线程对应一个独立的上下文。每个上下文内容包括:作为显存使用的一段内存区域;独立的寄存器组状态;其它内部处理阶段需要维护的必要状态。
b)由若干个功能模块构成3D处理流水线。包括:矩阵变换模块,光照处理模块,裁剪和投影模块,纹理映射模块,像素光栅化模块。模块之间定义输入输出接口,基于内存传递数据流。
(3)修改虚拟化设施软件支持vGPU前端
基于现有Qemu中显卡模型中的QXL实现模型,修改Qemu的vga设备模块和vgaBIOS。对于原有的PCI设备特性、VGA设备特性,除了解决必要冲突之外,基本保持原有功能。对于GPU方面的特性,分别面向上层驱动和下层的vGPU后端,重新构建代码。
面向上层驱动,需要提供两种虚拟设备的接口方式,一是I/O寄存器组,支持vGPU特性的设置/获取,flush等提交指令的执行等;二是内存映射方式,支持驱动通过DMA或共享方式操作renderTarget(渲染目标),texture(纹理)等显存资源。面向下层的vGPU后端,实现基于内存的前后端协同通信方式。
(4)开发vGPU驱动
Windows7操作系统的显示驱动模型为WDDM,需要实现用户态和内核态两级驱动。驱动的实现方法是,以vGPU前端为基础,向操作系统和应用层报告3D方面的支持特性集,并合理的把3D操作请求转给vGPU前端处理。同时,适应Spice协议中QXL加速要求,在驱动层截获系统渲染请求数据和进程渲染请求数据,基于Spice协议转至终端完成实际渲染。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。