基于局部纹理特征的人群密度谱估计方法与流程
本发明涉及视频图像处理技术,特别涉及对大型公共场所人流密度实时检测的技术。
背景技术:
以往的人群密度估计方法大多数都是提取图像的全局特征并对整幅图像的人群密度做估计。然而,这种方法具有两个严重的缺点:1.行人可能只出现在图像的某一部分区域,例如:在包含道路的图片中,行人可能只出现在人行道上;2.在实际应用中,人们更加关心的是特定区域的人群密度,例如:在电影院,入口处的人群密度比坐在等候区域的人群密度更重要。所以,为了更好地适应于各种应用场景,就必须对图像的人群密度谱进行估计。
人群密度谱估计需要综合考虑图像的所有局部和空间信息,通过不同的颜色或者亮度将密度结果展示出来。密度谱就像是一幅热量图,颜色深或亮度大的区域代表高密度区域,颜色浅或亮度低的区域则对应着低密度区域,这样的展示结果让监测人员对监控画面中的人群分布情况一目了然。基于密度谱,我们还可以做更多更深入的智能研究。
传统的密度谱估计方法首先提取大量的图像局部块特征,例如SIFT;再通过k-means等聚类方法对所有图像局部特征进行聚类,由此得到图像的“词袋模型”(Bag of Words)或者“码书”(codebooks);然后提取每个像素点的“词袋模型”特征表达;最后学习得到该特征与像素点人群密度之间的回归模型,由此估计出整幅图像的人群密度谱。这一类方法过于依赖场景,导致训练出的模型往往泛化能力不够,并且需要提取很复杂的特征集,如Bow-Sift等。
目前较好的方法是提取图像的若干块,利用所有图像块的特征与该图像块内行人分布的向量集训练得到一个随机森林。在检测阶段,首先提取图像块的特征,然后利用训练好的随机森林预测该块的行人分布标签,再利用视频前后帧之间的密度先验概率得到每一个图像块的密度,最后每一个像素点的密度由所有包含该点的图像块的密度加权得到。该方法由于提取的特征块数量较多、特征维度较高,且采用随机森林这样的树状结构存储特征,所以在内存和时间上都消耗非常大,导致很难达到实时性要求。
真实监控场景下的人群密度谱估计问题,面向的场景是校园、车站、商场等公共场所,在这些场景中,行人可能会出现在视频图像中的任何位置。现实生活中监控场景复杂多变,密度谱估计算法必须要满足实时性要求,并且需要对场景具有无依赖性,同时还能够直观反映出当前监控场景下的行人分布及拥挤情况。
技术实现要素:
本发明所要解决的技术问题是,提供一种不依赖场景且能满足实时性要求的人群密度谱估计方法。
本发明为解决上述技术问题所采用的技术方案是,基于局部纹理特征的人群密度谱估计方法,包括以下步骤:
1)训练步骤:
1-1)采集视频样本图片,根据单位面积内包含的行人数量对样本设置人群密度分类标签;设置各人群密度分类标签对应的得分;
1-2)提取样本图片的纹理特征,将样本图片的纹理特征与对应的人群密度分类标签输入SVM分类器进行分类器训练。
2)测试步骤:
2-1)利用SIFT关键点检测器提取出候选关键点,再在候选关键点中通过间隔采样选取出关键点;以每个关键点为中心,提取出固定大小的邻域图像块,提取邻域图像块的纹理特征;
2-2)将邻域图像块的纹理特征输入SVM分类器进行分类,得到该图像块的一个人群密度分类标签,并得到该人群密度分类标签对应得分;
2-3)计算邻域图像块内的所有像素点的密度得分,密度得分为邻域图像块的SVM预测得分与距离加权因子的乘积;
像素点的距离加权因子w(i,j)为
其中,p(i,j)代表(i,j)位置的像素点,dist(p(i,j),C)代表该像素点与关键点的欧式距离;
2-4)遍历检测图像中每个像素点所在的所有邻域图像块,将对应的像素点密度得分进行累加得到每个像素点的最终密度得分;
2-5)将每个像素点的最终密度得分归一化到0到255之间,再将最终密度得分对应成灰度值,得到一幅灰度密度谱图;或将最终密度得分对应成RGB三个通道值,得到一幅彩色密度谱图。
本发明采用SIFT关键点检测器可以有效检测出图像中行人所在的区域,使用SVM分类器对每个关键点区域进行分类,有效得到各个关键点区域的人群密度。另外,本发明还提供一种纹理特征的提取方式,通过提取局部纹理模式的灰度共生矩阵特征来表达图像块的行人密度,简单有效。
本发明的有益效果是,具有非常高的实用性和可行性,并且能够满足实时性要求。
附图说明
图1:本发明的人群密度谱估计流程示意图
具体实施方式
本发明需要用到的现有技术包括SIFT关键点检测器、SVM分类器,所采用的特征为局部二值模式LBP、局部三值模式LTP、灰度共生矩阵特征。
根据单位面积内包含的行人数量多少,我们将人群密度分为五种类型:非常低、低、中等,高,非常高。这种分类依据来自于Polus提出的人群可自由活动水平概念,Polus将人群密度分为四种水平:自由人流、受限制人流、密集人流、拥堵人流。
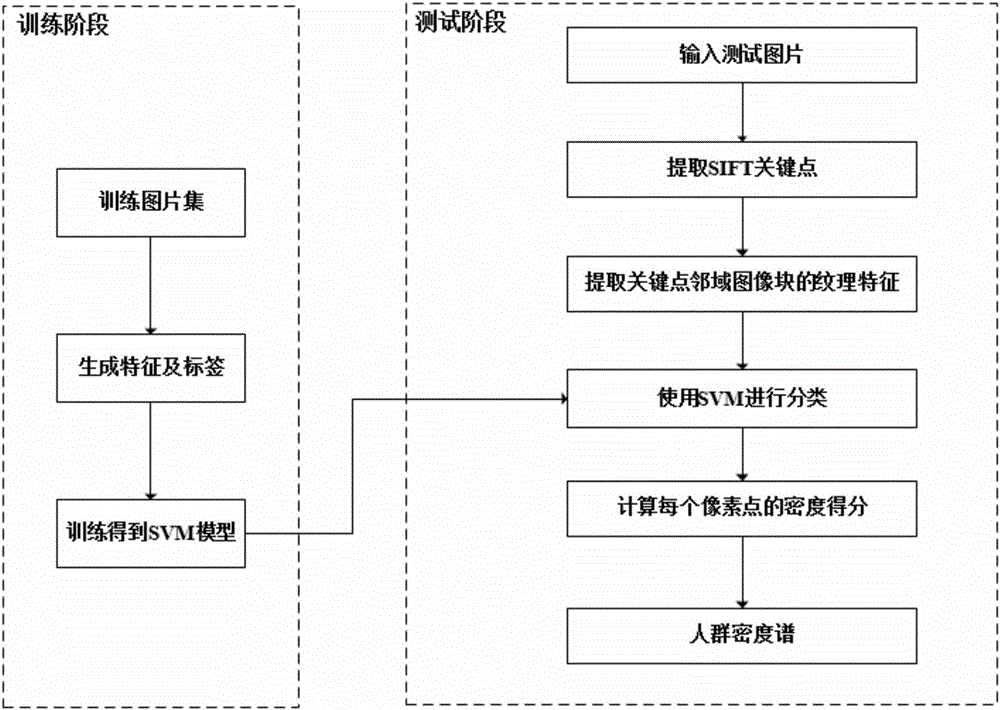
本发明主要工作分为两个阶段:训练阶段和测试阶段,如图1所示。
其中训练阶段可以分为以下三个步骤:
步骤一、对真实监控场景下拍摄好的大量视频样本进行采样,对于五种类型的人群密度,分别提取等量的训练图片。事先利用摄像头在校园教学楼以及图书馆门前广场拍摄得到大量的视频,通过裁剪,挑选出非常低、低、中等、高、非常高密度的图片各600张,每张图片大小都是63×63,将这3000张图片分别标上对应的标签,由此构成训练图片集。
步骤二、提取特征:对训练集中的每一张图片,可以分为以下五步来提取其纹理特征。
1.计算原图像对应的梯度图像;
2.对于原图像中每个像素点,提取其3×3邻域,计算得到对应的局部三值模式LTP三值码(-1,0,1),并分解成正局部二值模式LBP二值码(0,1)以及负LBP二值码(-1,0)。对于正LBP码,通过顺时针的方式计算得到其对应的LBP值;对于负LBP码,通过逆时针的方式计算得到其对应的LBP值,在这个计算过程中,负LBP码中的-1被当作+1处理。经过计算,原图像每一个像素点都得到了正负LBP值,由此便得到了对应的正负两幅LBP图。
3.计算梯度图像的每个像素点对应的LBP值,由此得到梯度LBP图;
4.计算正LBP图、负LBP图和梯度LBP图的灰度共生矩阵;
5.对正LBP图、负LBP图和梯度LBP图的灰度共生矩阵分别计算其能量、对比度、一致性和熵,将各灰度共生矩阵对应的能量、对比度、一致性和熵进行串联得到特征向量(能量,对比度,一致性,熵);最后将正LBP图、负LBP图和梯度LBP图的灰度共生矩阵的特征向量进行串联构成了图像特征(正LBP特征向量,负LBP特征向量,梯度LBP特征向量)。其中,计算能量、对比度、一致性、熵的方法均为现有,不在此赘述。
步骤三、训练支持向量机SVM分类器:将步骤二中得到的3000个特征向量以及对应的标签用来训练SVM分类器。
测试阶段分为以下五个步骤:
步骤一、提取关键点:首先,使用尺度不变特征变换SIFT关键点检测器检测到若干候选关键点;由于边界关键点所在区域往往没有包含任何行人,因此去掉以后对实际效果并没有多大影响,故去除一些边界上的关键点;最后对于关键点较多的情况,我们选择间隔采样的方式,只保留部分关键点。对于关键点是否属于较多的情况的判断可通过与阈值比较的方式进行。
步骤二、提取关键点邻域的纹理特征:首先,对于每个关键点,提取其大小为63×63的邻域图像块,采用与训练阶段相同的方式,计算得到该邻域图像块的纹理特征。
步骤三、使用SVM模型进行分类:对于每个关键点邻域图像块,利用训练阶段训练好的SVM分类模型,对这些邻域图像块进行分类,对应5个密度类别:非常低、低、中等、高、非常高分别对应打分:1,2,3,4,5。
步骤四、计算每个像素点的密度得分:
对于每个关键点邻域图像块内的所有像素点计算密度得分,密度得分等于邻域图像块的SVM预测得分与距离加权因子的乘积,距离加权w(i,j):
其中,w(i,j)代表该像素点的加权因子,p(i,j)代表(i,j)位置的像素点,dist(p(i,j),C)代表该像素点与关键点的欧式距离。
遍历每个像素点所在的所有邻域图像块,将对应的像素点密度得分进行累加得到每个像素点的最终密度得分;
步骤五、将每个像素点的最终密度得分归一化到0到255之间,将得分对应成灰度值,得到一幅灰度密度谱图;或将最终密度得分对应成RGB三个通道值,得到一幅彩色密度谱图。
通过以上步骤便可以完成对一幅输入图像或视频帧的行人密度谱计算。之后,可以对得到的人群密度谱进行应用。例如,设定密度阈值,当某区域的人群密度超过该阈值时,则可以给系统发出警告信息,以提示监控人员该区域可能存在人群过于拥挤情况;同时分析密度谱的变化情况,当某区域人群密度快速增大,则表示该区域可能存在人群突然聚集现象;通过人群密度谱积分图,还可以得到任意区域的人数近似估计。
- 还没有人留言评论。精彩留言会获得点赞!