一种基于煤岩学和遗传算法的煤场分堆方法与流程
本发明属于煤场分堆
技术领域:
。具体涉及一种基于煤岩学和遗传算法的煤场分堆方法。
背景技术:
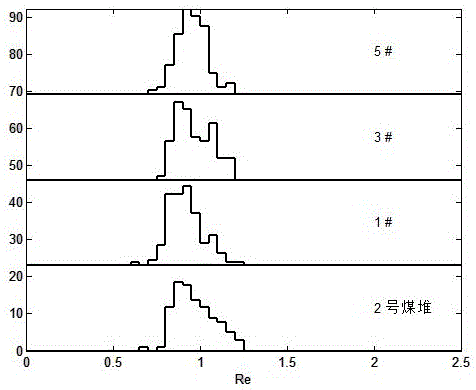
:焦化企业受场地限制,大多采用挥发分、粘结指数、胶质层厚度等煤分类指标指导堆放,将这些指标相同或相近的来煤堆放在一起。但上述指标对来煤分堆堆放后,常出现配煤与焦炭质量不稳定的情况,原因在于这些指标无法鉴别来煤的单混性,少数来煤堆放不合理即可导致配煤质量混乱。在堆放过程中造成的混杂会使以单煤形式堆放的煤堆形成混煤,使建立在单煤基础上的配煤炼焦理论难以适应,同时,也会造成对优质炼焦煤资源的浪费。而利用煤的镜质组随机反射率分布比例指标首先可以很好地鉴别单煤和混煤,其次,在比较来煤的镜质组随机反射率分布比例的相似程度的基础上,可以指导煤场来煤的合理堆放。近年来,随着焦化企业对煤的岩相分析仪器的引进,使得焦化企业对来煤的镜质组随机反射率分布比例的测定变得更加快速与便捷。同时,对煤的镜质组随机反射率分布图的应用研究也越来越普遍,如燕瑞华等的研究(燕瑞华,高志军,耿印权等.镜质组反射率分布图在配煤炼焦中的应用[J].燃料与化工,2001,32(5):227-230.),提出了利用煤的镜质组反射率分布图鉴别混煤、指导煤场分堆和优化配煤结构,并取得了很好的效益;又如姚伯元等的研究(姚伯元,吴亚东.用煤反射率分布图指导煤场来煤的合理堆放[J].燃料与化工,2008,39(3):9-14.),通过定义来煤离异值、来煤分布范围容纳度Fi(%)和来煤反射率分布图重叠度Ci(%)指标,来综合的指导煤场来煤的合理堆放。现有的分堆方法虽有很多优点,但在焦化企业实际生产中还存在以下不足:一是没有考虑煤场分堆的简易性和时效性;二是没有考虑当来煤的煤种复杂且数量多时,人工匹配的复杂度。技术实现要素:本发明旨在克服现有技术的缺陷,目的是提供一种简单高效和快速优化的基于煤岩学和遗传算法的煤场分堆方法。为实现上述目的,本发明采用的技术方案的步骤是:步骤1、测定煤场中各煤堆的镜质组随机反射率分布比例和测定来煤的镜质组随机反射率分布比例。步骤2、建立煤场分堆适应度数学模型Fitness;Fitness=[f1,f2,...,fi,...,fM](1)式(1)中:M表示煤场中的煤堆个数;i表示自然数,i=1,2,3,…,M;fi表示第i号煤堆的来煤和第i号煤堆的镜质组随机反射率分布比例的重合度,fi=100n=0Σj=150(min(Rei,j,xi-1,j,xi-2,j,...,xi-k,j,...,xi-n,j))n>0---(2)]]>式(2)中:i表示自然数,i=1,2,3,…,M;M表示煤场中的煤堆个数;n表示第i号煤堆的来煤种数;Rei,j表示第i号煤堆的镜质组随机反射率分布比例在第j点的数值;j表示自然数,j=1,2,3,…,50;k表示自然数,k=1,2,3,…,n;xi-k,j表示第i号煤堆的第k种来煤的镜质组随机反射率分布比例在第j点的数值;min表示取最小值。步骤3、采用遗传算法和煤场分堆适应度数学模型Fitness寻求最优煤场分堆方案,具体步骤是:步骤3.1、设来煤种数为D;采用整数编码,在[1,M]区间内构建初代种群个体,得到初代种群;初代种群个体的形式为:αt=[b1,b2,...,bD](3)式(3)中,t表示初代种群个体的序号,t为自然数,t=1,2,3,…,P;P表示初代种群个体总数;b表示初代种群个体的基因位点,b∈N∩b∈[1,M];D表示来煤种数。步骤3.2、采用遗传算法中的单点交叉方法对初代种群个体进行交叉操作,交叉概率Pc=0.6;采用变异概率的方式对初代种群个体进行变异操作,变异概率Pm=0.2,形成遗传种群个体,得到遗传种群。步骤3.3、将初代种群和遗传种群合并为总种群;采用煤场分堆适应度数学模型Fitness计算总种群个体的适应度。步骤3.4、从总种群中获取Pareto最优个体;判断Pareto最优个体总数是否大于初代种群个体总数,若Pareto最优个体总数大于或等于初代种群个体总数,则采取随机抽取的方式从Pareto最优个体中选择出子代种群个体;若Pareto最优个体总数小于初代种群个体总数,则将Pareto最优个体全部选择到子代种群中,子代种群中其余个体在[1,M]区间内构建。步骤3.5、计算每一个Pareto最优个体的适应度的加和值,选择出适应度的加和值最大的Pareto最优个体为当代最优个体,保存当代最优个体。步骤3.6、清除初代种群中所有的个体,用子代种群中所有的个体填充到初代种群中;判断初代种群迭代次数是否大于最大迭代次数,若初代种群迭代次数大于最大迭代次数则算法终止,计算每一个当代最优个体的适应度的加和值,选择出适应度的加和值最大的当代最优个体为最优煤场分堆方案;若初代种群迭代次数小于或等于最大迭代次数则返回步骤3.2。步骤4、根据最优煤场分堆方案,利用煤场分堆适应度数学模型Fitness计算出最优煤场分堆方案的适应度;若最优煤场分堆方案的适应度中每一个重合度值大于或等于30%,则满足生产需求;若最优煤场分堆方案的适应度中存在有重合度值小于30%,则不满足生产需求,返回步骤3,直至最优煤场分堆方案的适应度中每一个重合度值大于或等于30%。由于采用上述技术方案,本发明与现有技术相比,其显著的有益效果体现在:1,本发明提出了将各煤堆与各煤堆的来煤的镜质组随机反射率分布比例的重合度作为煤场分堆适应度数学模型Fitness,该模型可以高效评价出煤场分堆方案的优劣,从而加快最优煤场分堆方案的选择。2,本发明采用以Pareto理论与遗传算法相结合的方式优化煤场分堆方案,该算法在迭代次数为100~300范围内稳定收敛,从而实现煤场分堆方案的快速优化。3,本发明以来煤的镜质组随机反射率分布比例和煤堆的镜质组随机反射率分布比例作为输入,无需其他评价指标,在遗传算法优化后,即可得到最优煤场分堆方案,从而实现了简单高效。因此,本发明具有简单高效和能够快速优化的特点。附图说明:图1为本发明的1号煤堆和1号煤堆的来煤的镜质组随机反射率分布直方图;图2为本发明的2号煤堆和2号煤堆的来煤的镜质组随机反射率分布直方图;图3为本发明的3号煤堆和3号煤堆的来煤的镜质组随机反射率分布直方图;图4为本发明的4号煤堆和4号煤堆的来煤的镜质组随机反射率分布直方图;图5为本发明的5号煤堆和5号煤堆的来煤的镜质组随机反射率分布直方图。具体实施方式:下面结合附图和具体实施方式对本发明作进一步的描述,并非对其保护范围的限制。实施例1一种基于煤岩学和遗传算法的煤场分堆方法。该方法的具体步骤是:步骤1、本实施例的某煤场的煤堆个数M为5,来煤种数为D为14,测定该煤场中5个煤堆的镜质组随机反射率分布比例和测定14种来煤的镜质组随机反射率分布比例(由于煤的镜质组随机反射率分布比例数据庞杂,故未罗列),所述14种来煤的煤种类别如表1所示。表114种来煤的煤种类别步骤2、建立煤场分堆适应度数学模型Fitness。Fitness=[f1,f2,f3,f4,f5](1)式(1)中,fi表示第i号煤堆的来煤和第i号煤堆的镜质组随机反射率分布比例的重合度,fi=100n=0Σj=150(min(Rei,j,xi-1,j,xi-2,j,...,xi-k,j,...,xi-n,j))n>0---(2)]]>式(2)中,i为自然数,i=1,2,3,4,5;n表示第i号煤堆的来煤种数;j表示自然数,j=1,2,3,…,50;Rei,j表示第i号煤堆的镜质组随机反射率分布比例在第j点的数值;k表示自然数,k=1,2,3,…,n;xi-k,j表示第i号煤堆的第k种来煤的镜质组随机反射率分布比例在第j点的数值;min表示取最小值。步骤3、采用遗传算法和煤场分堆适应度数学模型Fitness寻求最优的煤场分堆方案,具体步骤如下:步骤3.1、来煤种数D为14,设置初代种群个体总数P为50,最大迭代次数为300。采用整数编码,在[1,5]区间内构建初代种群个体,得到初代种群。初代种群个体的形式为:αt=[b1,b2,...,b14](3)式(3)中,t为初代种群个体的序号,t为自然数,t=1,2,3,…,50;b为初代种群个体的基因位点,b∈N∩b∈[1,5]。例如,初代种群第1号个体α1的基因如表2所示,初代种群第1号个体α1代表的分堆方案为:1号煤堆的来煤为3#、9#和14#,2号煤堆的来煤为2#、4#、6#和10#,3号煤堆的来煤为5#、12#和13#,4号煤堆的来煤为7#和11#,5号煤堆的来煤为1#和8#。表2初代种群第1号个体α1的基因步骤3.2、采用遗传算法中的单点交叉方法对初代种群个体进行交叉操作,交叉概率Pc=0.6;采用变异概率的方式对初代种群个体进行变异操作,变异概率Pm=0.2,形成遗传种群个体,得到遗传种群。步骤3.3、将初代种群和遗传种群合并为总种群;采用煤场分堆适应度数学模型Fitness计算总种群个体的适应度。例如,总种群第1号个体β1的基因如表3所示。表3总种群第1号个体β1的基因采用煤场分堆适应度数学模型Fitness计算出总种群第1号个体β1的适应度为:[6.6%,75.1%,1%,0%,0%]。步骤3.4、从总种群中获取Pareto最优个体;判断Pareto最优个体总数是否大于初代种群个体总数,若Pareto最优个体总数大于或等于初代种群个体总数,则采取随机抽取的方式从Pareto最优个体中选择出子代种群个体;若Pareto最优个体总数小于初代种群个体总数,则将Pareto最优个体全部选择到子代种群中,子代种群中其余个体在[1,5]区间内构建。例如:总种群第2号个体β2的基因和总种群第3号个体β3的基因如表4所示。表4总种群第2号个体β2的基因和总种群第3号个体β3的基因采用煤场分堆适应度数学模型Fitness分别计算出:总种群第2号个体β2的适应度为[0%,0%,2.9%,0%,0%];总种群第3号个体β3的适应度为[7.3%,0%,8.4%,0%,31.4%]。可以看出,总种群第3号个体β3的适应度中各重合度值均对应地大于或等于总种群第2号个体β2的适应度中各重合度值,则总种群第3号个体β3为Pareto最优个体。步骤3.5、计算每一个Pareto最优个体的适应度的加和值,选择出适应度的加和值最大的Pareto最优个体为当代最优个体,保存当代最优个体。步骤3.6、清除初代种群中所有的个体,用子代种群中所有的个体填充到初代种群中;判断初代种群迭代次数是否大于最大迭代次数,若初代种群迭代次数大于最大迭代次数则算法终止,计算每一个当代最优个体的适应度的加和值,选择出适应度的加和值最大的当代最优个体为最优煤场分堆方案;若初代种群迭代次数小于或等于最大迭代次数则返回步骤3.2。本实施例的步骤3以5个煤堆和14种来煤作为遗传算法的优化分堆对象,该算法在迭代次数为100代时,算法稳定收敛。迭代次数为300时,算法终止,输出的最优煤场分堆方案如表5所示。表5最优煤场分堆方案从表5可以看出,最优煤场分堆方案为:1号煤堆的来煤是2#和7#;2号煤堆的来煤是1#、3#和5#;3号煤堆的来煤是9#、10#和11#;4号煤堆的来煤是12#、13#和14#;5号煤堆的来煤是4#、6#和8#。步骤4、根据最优煤场分堆方案,利用煤场分堆适应度数学模型Fitness计算出最优煤场分堆方案的适应度:(1)1号煤堆与2#和7#来煤的镜质组随机反射率分布比例的重合度计算公式为:f1=Σj=150(min(Re1,j,x1-1,j,x1-2,j))---(4)]]>式(4)中,j表示自然数,j=1,2,3,…,50;Re1,j为1号煤堆的镜质组随机反射率分布比例在第j点的数值;x1-1,j为1号煤堆的2#来煤的镜质组随机反射率分布比例在第j点的数值;x1-2,j为1号煤堆的7#来煤的镜质组随机反射率分布比例在第j点的数值;min表示取最小值。1号煤堆与2#和7#来煤的镜质组随机反射率分布比例如表6所示。表61号煤堆与2#和7#来煤的镜质组随机反射率分布比例通过比较,取各列的最小值。因此,1号煤堆与2#和7#来煤的镜质组随机反射率分布比例的重合度f1=1%+15.7%+18%+6.7%=41.4%。将1号煤堆与2#和7#来煤的镜质组随机反射率分布比例进行作图,如图1所示。从图1可以看出,煤种类别为1/3焦煤的2#来煤、煤种类别为气煤的7#来煤和1号煤堆的镜质组随机反射率分布范围重合度较大,满足分堆要求。(2)2号煤堆与1#、3#和5#来煤的镜质组随机反射率分布比例的重合度计算公式为:f2=Σj=150(min(Re2,j,x2-1,j,x2-2,j,x2-3,j))---(5)]]>式(5)中,j表示自然数,j=1,2,3,…,50;Re2,j为2号煤堆的镜质组随机反射率分布比例在第j点的数值;x2-1,j为2号煤堆的1#来煤的镜质组随机反射率分布比例在第j点的数值;x2-2,j为2号煤堆的3#来煤的镜质组随机反射率分布比例在第j点的数值;x2-3,j为2号煤堆的5#来煤的镜质组随机反射率分布比例在第j点的数值;min为取最小值。与计算1号煤堆与2#和7#来煤的镜质组随机反射率分布比例的重合度的方法相同,2号煤堆与1#、3#和5#来煤的镜质组随机反射率分布比例的重合度f2为68.4%。将2号煤堆与1#、3#和5#来煤的镜质组随机反射率分布比例进行作图,如图2所示。从图2可以看出,煤种类别为肥煤的1#来煤、煤种类别为肥煤的3#来煤、煤种类别为1/3焦煤的5#来煤和2号煤堆的镜质组随机反射率分布范围基本重合,满足分堆要求。(3)与计算1号煤堆与2#和7#来煤的镜质组随机反射率分布比例的重合度的方法相同,3号煤堆与9#、10#和11#来煤的镜质组随机反射率分布比例的重合度f3为59.9%。将3号煤堆与9#、10#和11#来煤的镜质组随机反射率分布比例进行作图,如图3所示。从图3可以看出,煤种类别为焦煤的9#来煤、煤种类别为焦煤的10#来煤、煤种类别为焦煤的11#来煤和3号煤堆的镜质组随机反射率分布范围基本重合,满足分堆要求。(4)与计算1号煤堆与2#和7#来煤的镜质组随机反射率分布比例的重合度的方法相同,4号煤堆与12#、13#和14#来煤的镜质组随机反射率分布比例的重合度f4为41.9%。将4号煤堆与12#、13#和14#来煤的镜质组随机反射率分布比例进行作图,如图4所示。从图4可以看出,煤种类别为瘦煤的12#来煤、煤种类别为瘦煤的13#来煤、煤种类别为瘦煤的14#来煤和4号煤堆的镜质组随机反射率分布范围基本重合,满足分堆要求。(5)与计算1号煤堆与2#和7#来煤的镜质组随机反射率分布比例的重合度的方法相同,5号煤堆与4#、6#和8#来煤的镜质组随机反射率分布比例的重合度f5为57.3%。将4号煤堆与4#、6#和8#来煤的镜质组随机反射率分布比例进行作图,如图5所示。从图5可以看出,煤种类别为1/3焦煤的4#来煤、煤种类别为1/3焦煤的6#来煤、煤种类别为1/3焦煤的8#来煤和5号煤堆的镜质组随机反射率分布范围基本重合,满足分堆要求。可以看出,本实施例最优煤场分堆方案的适应度中的各重合度值均大于30%,故满足生产需求。值得说明的是:由于各煤堆与该煤堆的来煤的镜质组随机反射率分布比例的重合度计算方法相同,本具体实施方式将不赘述其他实施例中各煤堆与所述煤堆对应的来煤的镜质组随机反射率分布比例的重合度的计算。与实施例1相同,若其他实施例的最优分堆方案的适应度中每一个重合度值大于或等于30%,则满足生产需求;若其他实施例的最优分堆方案的适应度中存在有重合度值小于30%时,则不满足生产需求,返回步骤3,直至最优分堆方案的适应度中每一个重合度值大于或等于30%。本具体实施方式与现有技术相比,其显著的有益效果体现在:1,本发明提出了将各煤堆与各煤堆的来煤的镜质组随机反射率分布比例的重合度作为煤场分堆适应度数学模型Fitness,该模型可以高效评价出煤场分堆方案的优劣,从而加快最优煤场分堆方案的选择。2,本发明采用以Pareto理论与遗传算法相结合的方式优化煤场分堆方案,该算法在迭代次数为100~300范围内稳定收敛,从而实现煤场分堆方案的快速优化。3,本发明以来煤的镜质组随机反射率分布比例和煤堆的镜质组随机反射率分布比例作为输入,无需其他评价指标,在遗传算法优化后,即可得到最优煤场分堆方案,从而实现了方法简单高效。因此,本发明具有简单高效和能够快速优化的特点。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1