一种改进的中文自动分词算法的制作方法
本发明涉及中文语义网络技术领域,具体涉及一种改进的中文自动分词算法。
背景技术:
自上世纪八十年代初,中文信息处理领域提出中文自动分词课题以来,就一直吸引着来自计算机界、数学界、信息检索界、语言界的,无数的专家和学者。他们经过几十年的不懈努力和艰苦探索,已经取得了一些重要的进展和实用性的成果。可以把这些方法概括的分为三大类。第一,基于词典的中文分词方法,其过程简单、易于理解,但也对多义词、歧义词和嵌套词的切分效果不太理想。第二,基于统计的中文分词方法,该类方法,通过选取合适的数学统计模型,依靠大量的语料来对其进行训练,待模型稳定以后,再利用训练好的模型实现汉字串的自动分词。最后,基于理解的中文分词方法,基于理解的分词方法就是借助于人工智能中的相关技术,将事先已经提取好的关于汉语构词的一些规则和知识加入到推理过程中,利用这些规则和知识结合不同的推理机制,实现最终的中文分词,目前为止基于理解的分词系统还处在试验阶段。
中文自动文词指的是将一个汉字序列按照其出现的上下文中的实际意义,有机的切分成一个个独立的词过程。它是计算机能够自动理解中文语义的基础,是中文信息处理中最重要的预处理技术。在中文里面,计算机不容易明白“她喜欢吃水果”中的“水果”是一个词。只有当自然语言中无意义的汉字串,被正确转化为有意义的词之后,计算机才能正确理解自然语言,进而进行下一步工作。为提高中文自动分词的准确性,本发明提供了一种改进的中文自动分词算法。
技术实现要素:
针对中文自动分词的准确性不高问题,本发明提供了一种改进的中文自动分词算法。
为了解决上述问题,本发明是通过以下技术方案实现的:
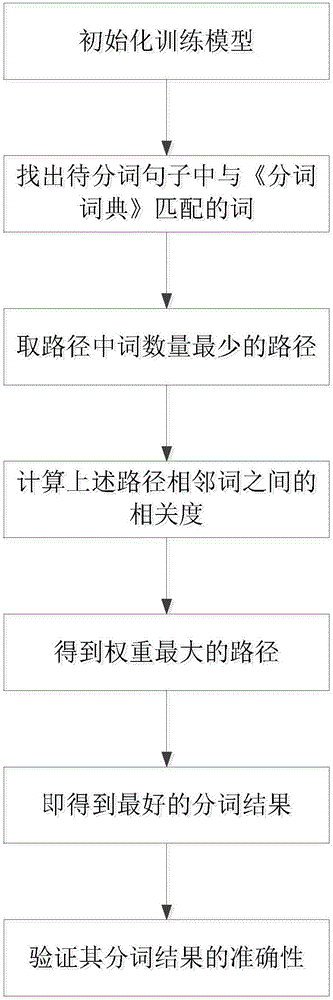
步骤1:初始化训练模型,可以是《分词词典》或相关领域的语料库,或是两者结合模型。
步骤2:根据《分词词典》找到待分词句子中与词典中匹配的词。
步骤3:依据概率统计学,将待分词句子拆分为网状结构,即得n个可能组合的句子结构,把此结构每条顺序节点依次规定为SM1M2M3M4M5E。
步骤4:利用统计学概念理论知识,给上述网状结构每条边赋予一定的权值。
步骤5:找到权值最大的一条路径,即为待分词句子的分词结果。
步骤6:验证此分词结果的准确率和召回率。
本发明的有益效果是:
1、中文预处理的速度较基于分词词典的方法快。
2、此方法较基于分词词典的方法有更好的精度。
3、此方法较基于统计学方法有更好的准确度。
4、此方法实用性更大,更符合经验值。
5、此方法为后续自然语言处理技术提供了极大地应用价值。
附图说明
图1为一种改进的中文自动分词算法结构流程图。
图2为n元语法分词算法图解。
具体实施方式
本发明提出了一种改进的中文自动分词算法。
为了提高中文自动分词的准确性,结合图1-图2对本发明进行了详细说明,其具体实施步骤如下:
步骤1:初始化训练模型,可以是《分词词典》或相关领域的语料库,或是两者结合模型。
步骤2:根据《分词词典》找到待分词句子中与词典中匹配的词,其具体描述如下:
把待分词的汉字串完整的扫描一遍,在系统的词典里进行查找匹配,遇到字典里有的词就标识出来;如果词典中不存在相关匹配,就简单地分割出单字作为词;直到汉字串为空。
步骤3:依据概率统计学,将待分词句子拆分为网状结构,即得n个可能组合的句子结构,把此结构每条顺序节点依次规定为SM1M2M3M4M5E,其结构图如图2所示。
步骤4:利用统计学概念理论知识,给上述网状结构每条边赋予一定的权值,其具体计算过程如下:
步骤4.1)取路径中词的数量最少min()
根据《分词词典》匹配出的字典词与未匹配的单个词,第i条路径包含词的个数为ni。即n条路径词的个数集合为(n1,n2,…,nn)。
得min()=min(n1,n2,…,nn)
步骤4.2)计算相邻两个词(C1,C2)相关度RE(C1,C2)
将两个词(C1,C2)映射到概念模型中,得到相应的概念(g1,g2),即概念(g1,g2)的相关度RE(g1,g2)即为相邻两个词(C1,C2)相关度。
RE(C1,C2)=RE(g1,g2)
这里考虑了本体间的基本属性关系、路径距离与路径数量、密度与深度等影响因子计算两本体概念(g1,g2)间的相关度。
步骤4.2.1)构造基于基本属性关系对两本体概念(g1,g2)相似度的影响函数RE属性(g1,g2)
两本体概念(g1,g2)相似度与属性相似度成正比,与属性权重也成正比。
路径为g1→J1→…→Jn→g2
假设g1、J1、…、Jn、g2的属性个数各为
每个属性对相应概念的影响权重是不同的,按照权重系数分别对概念属性进行排序,对每个概念属性取前i个属性权重值。
这里
即得下列属性权重矩阵(n+2)×i:
从专业领域本体树中,可以很清楚的知道g1、J1、…、Jn概念中的共有属性,记为(S1′,S2′,…,Sj′),这里j为共有属性的个数,j≤i,且
为概念g1、J1、…、Jn、g2中属性相同,则取出其对应权重值
所以构建的影响函数为:
步骤4.2.2)构造基于路径距离、与路径数量对两本体概念(g1,g2)相似度的影响函数RE路径(g1,g2)
两本体概念(g1,g2)相似度与其路径长度成反比,找到两本体概念(g1,g2)间最长路径,其中经过的概念节点有n个,即(J1→…→Jn)。
即经过路径的长度为L(g1,g2)=n+2
两本体概念(g1,g2)相似度与路径数量成反比,即当路径数量越多,两本体概念(g1,g2)相似度越大,这里根据专业领域本体树可知路径数量为N,如下式。
即
上式r为路径长度与路径个数的权重比值,这个可以根据实验迭代出来。
步骤4.2.3)构造密度与深度对两本体概念(g1,g2)相似度的影响函数RED(g1,g2)
步骤4.2.3.1)两本体概念(g1,g2)深度函数
概念节点的深度是指概念在所处的本体树中的层次深度。在本体树中,每个概念节点都是对上一层节点的一次细化。因此概念节点处于本体树中层次越深,则表示的内容越具体,概念间的相似度越大。反之概念间的相似度越小。
这里深度值从根节点开始,根节点的深度值为1,从概念(g1、g2)与共同父节点构成的树子集中找到同一层中两本体概念(g1、g2)数量最多的,其对应的深度为h。
如果两本体概念(g1、g2)不在同一层,则其平均,即有下式:
与分别为从概念(g1、g2)与共同父节点构成的树子集中两本体概念(g1、g2)数量最多的深度值。
步骤4.2.3.2)两本体概念(g1、g2)密度函数
概率节点密度越大,则其直接子节点数目越多,节点细化的越具体,各直接子节点之间的相似度越大。
从概念(g1、g2)的直接子节点中找到共同直接子节点个数,如上为N。
步骤4.2.3.3)由上述步骤可得:
上式α、β分别为深度与密度的权重系数,α+β=1,α越大表示概念深度对相关度的影响越大,反之影响越小。β越大表示概念密度对相关度的影响越大,反之影响越小。γ为平滑因子,α、β、γ可以通过非线回归迭代估计来确定。
综上所述,有下式
RE(C1,C2)=RE(g1,g2)=ARE属性(g1,g2)+BRE路径(g1,g2)+CRED(g1,g2)
上式A、B、C为相应的影响系数,根据其值大小,影响相关度的程度也不一样,值越大,对相关度影响也越大,A+B+C=1。
步骤5:找到权值最大的一条路径,即为待分词句子的分词结果,其具体计算过程如下:
有n条路径,每条路径长度不一样,假设路径长度集合为(L1,L2,…,Ln)。
假设经过取路径中词的数量最少操作,排除了m条路径,m<n。即剩下(n-m)路径,设其路径长度集合为
则每条路径权重为:
上式分别为第1,2到路径边的权重值,根据步骤4可以一一计算得出,为剩下(n-m)路径中第Si条路径的长度。
权值最大的一条路径:
步骤6:验证此分词结果的准确率和召回率。
准确率:
上式n识为《分词词典》识别待分词句子中字典词的个数,nz为此方法正确分词词的个数。
召回率:
上式n总为待分词句子中词的总个数。
最后综合考虑这两个因子,判定此系统分词结果的正确性。
即d=|zhaorate-rate|≤ε
ε为一个很小的阈值,这个由专家给定。当d满足上述条件,则分词效果比较理想。
- 还没有人留言评论。精彩留言会获得点赞!