一种新的本体概念词汇语义相似度求解方法与流程
本发明涉及语义网络技术领域,具体涉及一种新的本体概念词汇语义相似度求解方法。
背景技术:
目前,很多学者在关注本体概念相似度的计算方法,相似度问题在哲学、语义学等多个学科中被深入的研究和分析。传统的基于本体的概念语义相似度计算方法主要分为2种:一种是基于信息论的方法,该方法利用信息论来计算2个概念共享信息程度,具有较高的理论严谨性,但是只能粗略地量化概念间的语义相似度,不能实现概念语义相似度的细致细分;另一种方法是基于距离的方法,该方法以概念之间路径的长短作为衡量语义距离的长短,通过计算两概念间的语义距离来实现概念语义相似度的计算,该方法简单、直观,但忽略了影响语义距离的其他很多因素。针对上述方法的缺陷,概念语义相似度不仅与语义距离有关系,而且还受概念在本体树中层次深度、以及待比较词间词形相似度等综合因子的影响,为了满足上述需求,本发明提出了一种新的本体概念词汇语义相似度求解方法。
技术实现要素:
针对如何更精准获得每一个术语的相似术语问题以及考虑词形、本体概念、本体概念共同祖先深度等影响因子,本发明提供了一种新的本体概念词汇语义相似度求解方法。
为了解决上述问题,本发明是通过以下技术方案实现的:
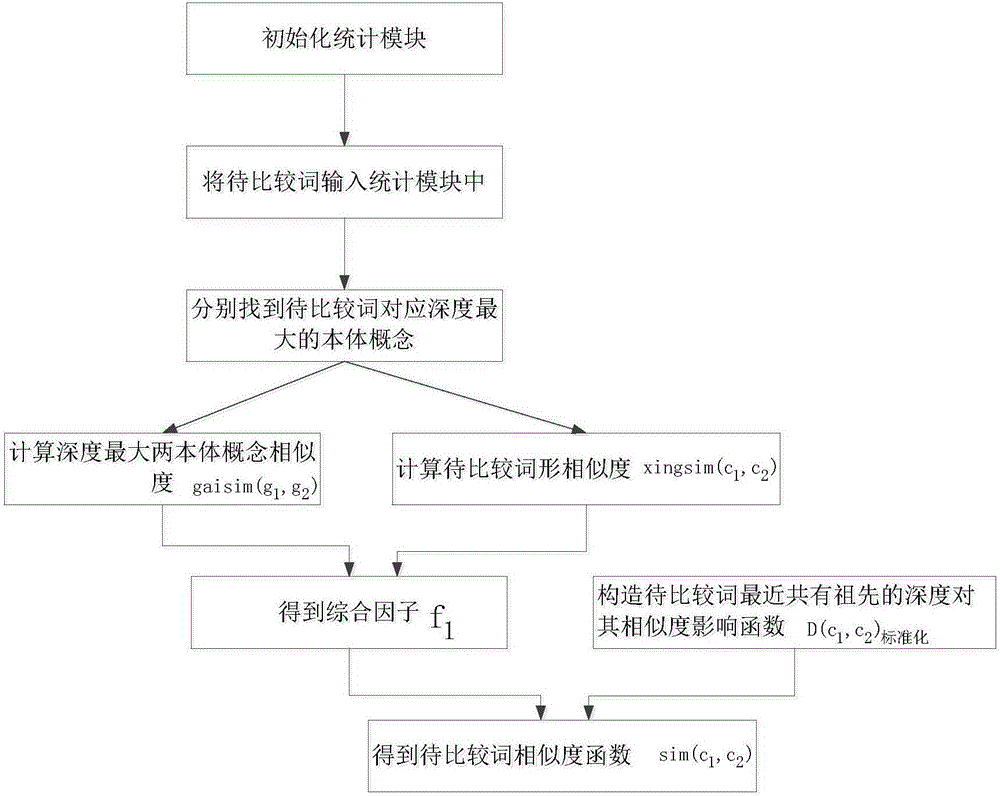
步骤1:初始化统计方法模块。
步骤2:将待比较词(c1,c2)输入初始化统计方法模块中。
步骤3:将待比较词(c1,c2)映射到本体概念模块中。
步骤4:分别选取待比较词(c1,c2)对应深度最大的本体概念g1、g2。
步骤5:计算待比较词(c1,c2)对应深度最大的两本体概念间的相似度gaisim(g1,g2)。
步骤6:待比较词(c1,c2)之间的词形相似度xingsim(c1,c2)。
步骤7:经过上述步骤,计算两待比较词(c1,c2)最近共同祖先的深度D(c1,c2)对两待比较词(c1,c2)相似度的影响,构造影响因子函数D(c1,c2)标准化。
步骤8:综合上述步骤,计算两待比较词(c1,c2)的相似度sim(c1,c2)。
本发明有益效果是:
1、此计算词汇相似度方法在量化概念上更接近专家的经验值。
2、此方法更充分、更综合考虑了待比较词(c1,c2)对应深度最大的本体概念间的距离、深度与密度等因素,大大的提高了语义相似度结果的准确度。
3、更好的提高了本体推理的效果。
4、又考虑了词语本身具有的词形相似度、语义相似度结果的准确度得到了更好提高。
5、各种影响因子的数据处理更规范。
6、更符合实际应用效果。
附图说明
图1为一种新的本体概念词汇语义相似度求解方法结构流程图。
具体实施方式
为解决更精准获得每一个术语的相似术语问题以及考虑词形、本体概念、本体概念共同祖先深度等影响因子,结合图1对本发明进行了详细说明,其具体实施步骤如下:
步骤1:初始化统计方法模块。
步骤2:将待比较词(c1,c2)输入初始化统计方法模块中。
步骤3:将待比较词(c1,c2)映射到本体概念模块中。
步骤4:分别选取待比较词(c1,c2)对应深度最大的本体概念g1、g2,其具体描述如下:
待比较词(c1,c2)与概念之间是一对多的关系,当选取的概念深度越深,则待比较词(c1,c2)则越具体,更方便计算待比较词(c1,c2)的语义相似度。这个深度在统计模块块中很容易找到,例如在《知网》中找到词语对应的本体概念。
步骤5:计算待比较词(c1,c2)对应深度最大的两本体概念间的相似度gaisim(g1,g2),需先求两本体概念间义原项的相似度sim(g1,g2),再计算两本体概念间相对深度deepth(g1,g2),具体计算过程如下:
5.1)两本体概念间义原项的相似度sim(g1,g2)
设c1对应深度最大的本体概念g1中含有n个义原,即g1∈(y1,y2,…,yn),c2对应深度最大的本体概念g2中含有m个义原,即g2∈(y1′,y2′,…,ym′)。
分别两两计算g1与g2中义原的相似度,即sim(yi,yj′),i∈(1,2,…,n)、j∈(1,2,…,m),可以得g1与g2中义原项相似度矩阵J(g1,g2),如下:
根据上述矩阵找出每个行向量中义原平均相似度averageSi,即
最后得到两本体概念间义原项的相似度sim(g1,g2),如下:
5.2)计算两本体概念间相对深度deepth(g1,g2)
deepth(g1,g2)=d1-d2
上式d1为c1对应深度最大的本体概念g1在模块中的深度值,同理d2为c2对应深度最大的本体概念g2在模块中的深度值,这个根据模块可以很容易得出。
对相对深度deepth(g1,g2)进行归一化处理,即得
α为调节因子,由领域专家给定。
5.3)计算待比较词(c1,c2)对应深度最大的两本体概念间的相似度gaisim(g1,g2)
步骤6:待比较词(c1,c2)之间的词形相似度xingsim(c1,c2),需先知词长相似率与词性相似率,其具体计算过程如下:
6.1)词长相似率rateword(c1,c2)
6.2)词性相似率wordsim(c1,c2)
上式n为待比较词(c1,c2)中词性相似个数,len(c1)为词c1的长度,len(c2)为c2的长度。
6.3)待比较词(c1,c2)之间的词形相似度xingsim(c1,c2)
步骤7:经过上述步骤,计算两待比较词(c1,c2)最近共同祖先的深度D(c1,c2对两待比较词(c1,c2)相似度的影响,构造影响因子函数D(c1,c2)标准化:
根据模块,可以找到两待比较词(c1,c2)最近共同祖先的深度D(c1,c2)。这里两待比较词(c1,c2)最近共同祖先深度越靠近底层,代表两待比较词(c1,c2)越相近。
这里可以构造两因子,即:
根据两因子得到深度D(c1,c2)对两待比较词(c1,c2)相似度的影响,有下式:
β为深度深度D(c1,c2)对词语相似度的影响系数,β∈(0,1),其取值可以通过试验得到,这里β越大则表示词语共同祖先的深度对相似度的影响越大,反之影响越小。
步骤8:综合上述步骤,计算两待比较词C∈(c1,c2)的相似度sim(c1,c2),其具体求解过程如下:
上式
所以
一种新的本体概念词汇语义相似度求解方法,其伪代码计算过程:
输入:初始化模块,待比较词C∈(c1,c2)
输出:待比较词C∈(c1,c2)相似度sim(c1,c2)。
- 还没有人留言评论。精彩留言会获得点赞!