一种面向流式数据的实时摘要生成方法与流程
本发明涉及数据流识别领域,是一种面向流式数据的实时摘要生成方法。
背景技术:
随着网络流量不断增加,识别流量中的数据对于数据防泄漏(Data Leakage Protection,DLP)、安全防御等需求越来越重要。例如从网络流量中识别木马、病毒、色情视频和内部文件等,如果能够在传输过程中进行识别,可以在早期进行审计和处置。
要识别流量中的数据,一般方法是对网络中的数据生成摘要。但是网络流量中存在大量复杂的应用协议处理情况,如在线视频播放、网盘文件下载等,这种数据存在大量乱序以及不完整捕获的情况。
当前对数据生成摘要的方法,例如MD5、SHA算法等,由于在数据发生改变的时候会产生雪崩效应,因此无法应用于识别相似文件的场景。
传统的模糊哈希算法采用分片哈希的思想,用一个弱哈希函数(rolling hash,rh)计算一定长度的连续字节的哈希值(计算长度称为分片计算窗口,以下用window表示),当弱哈希值满足分片条件时,就在这个位置对数据进行分片。
分片条件决定了平均分片数量,计算方法如公式1,2所示,bmin取3,n为数据长度,S取64
rh%binit=binit-1 公式2
之后再使用一个强哈希函数(mapping hash或strong hash)对每个分片计算一个哈希值,这样文件局部发生变化只会影响一两个分片的哈希值,而不会导致整个文件的哈希值完全发生改变。实践上,可以利用其模糊哈希值的编辑距离,度量文件的相似度。
传统的模糊哈希算法(Identifying almost identical files using context triggered piecewise hashing,2006)适用于离线数据的处理,但是对于正在传输的流式数据,由于其存在数据缺损、乱序和重叠的情况,不能进行应用。
技术实现要素:
鉴于此,本发明提出了一种面向流式数据的实时摘要生成方法,是一种可以处理缺损、乱序、重叠的流式数据的摘要生成方法,即在数据缺损、乱序、重叠的情况下仍然能够实时生成摘要,该方法适用于从网络流量中检测文件,可应用于病毒检测、入侵检测、数据防泄露、网络内容审查、数字取证、数字版权保护等领域。
由于本发明的方法是面向流式数据的,因此发明人将本发明中涉及到的算法简称为流式模糊哈希(Stream Fuzzy Hash,简称SFH)算法,对应地,该算法处理的文件对象中的一个数据分片则称为流式模糊哈希计算上下文(以下简称计算上下文)。
为了实现上述目的,本发明采用以下技术方案:
一种面向流式数据的实时摘要生成方法,包括:
1)更新流式输入的每个数据块左邻的计算上下文,如果数据块没有左邻,则将其作为初始化的计算上下文,将更新后的计算上下文保存到区间索引;
2)在区间索引中查找已输入数据的计算上下文,对相邻的计算上下文进行合并;
3)遍历区间索引,将其中的摘要值进行拼接并输出。
进一步地,步骤1)中所述区间索引是指可以对数据偏移量进行查找的数据结构,可以用任意常见查找结构实现,比如区间树、链表、数组、堆、红黑树等。
进一步地,步骤1)中更新流式输入的每个数据块左邻的计算上下文的步骤包括:
1-1)保留数据块的前w-1个字节到缓冲区中,其中w为弱哈希函数的滑动窗口值(可设置为1字节以上),所述数据块的起始位置记为s;
1-2)计算数据块每一个字节的弱哈希值和强哈希值;
1-3)当步骤1-2)计算得到的弱哈希值满足分片条件,则找到重置点(reset point),
i.如果是上下文中的第一个重置点,则s至重置点之间的部分称为左截断数据,计算它的强哈希值,记为部分强哈希值pshv;
ii.如果不是第一个,则新划分出一个分片,记为该分片的强哈希值;
iii.更新s为分片结束后的下一字节,回到步骤1-2);
1-4)当当次输入数据中所有数据块计算结束,将最后一个重置点到数据块结束位置之间的数据称为右截断数据,该部分的强哈希值称为强哈希状态,记为shs。
进一步地,步骤1-2)中,使用矩阵乘法运算作为强哈希函数计算强哈希值,优选伽罗华域(Galois Field)的矩阵乘法运算。
进一步地,步骤1-2)中可以使用Rolling Hash算法计算弱哈希值,步骤1-3)中分片条件可以让弱哈希值满足公式(2),也可以是特定末位数、特定数值等其它预设条件。
进一步地,根据上述计算方法,二进制流数据的强哈希值可以表示为以每位或特定位数为单位,映射成n阶矩阵,并将映射后的矩阵按照在数据流中出现的顺序相乘。
进一步地,步骤2)中如果计算上下文的数据区间的左右值连续则判断两个计算上下文相邻(比如[0:100]和[101:102])。
进一步地,步骤2)中,对两个相邻的计算上下文进行合并的方法包括以下步骤:
a)对计算上下文p和其右邻n保存在缓冲区中的w-1个字节,执行更新操作(即上述步骤1-2)至1-4));
b)计算p的强哈希状态值shs和n的部分强哈希值pshv的矩阵乘积;
c)如果p中不包含重置点,则用该矩阵乘积更新p的强哈希状态值shs,否则,用该矩阵乘积更新n的部分强哈希状态值pshv;
e)使用矩阵乘法拼接经步骤c)更新后的p和n的强哈希值。
进一步地,步骤3)中,将摘要值进行拼接的步骤包括:每个分片的强哈希值是一个n阶矩阵,矩阵中的每个元素是一个m bit数值,将这个矩阵的n*n个元素进行拼接,形成一个n*n*m bit的值,再通过截取或映射成为一个或多个字节的字符。
本发明主要从以下两个方面对模糊哈希算法进行改进:
1)流式摘要方法。将乱序的流式数据块,转化为可独立处理的计算上下文,并用区间索引组织起来,实现对乱序数据的实时计算。
2)对内存占用的改进。使用矩阵乘法运算作为强哈希函数,来减少原始文件缓存。因其具有满足结合律但不满足交换律的性质,可以将分片前的数据的计算为矩阵乘积的方式,既减少内存,又降低了哈希冲突率。由于矩阵乘法满足结合律,在window取值为7的实施例中,因此可以只保存前6个字节作为左边界值mbuffer[window size-1],将第7个字节到第一个重置点的强哈希值作为左中间状态值LFS(Left State)保存下来,这和直接缓存原始数据相比,大大减少了内存。
因此,本发明主要具备以下四个优点:
1)能够对流式数据进行实时摘要,将原本只能适用于完整数据的模糊哈希算法,引入多个中间状态和区间数据索引,满足实时计算乱序、重叠的数据块的能力;
2)能够对缺损(即不完整)的数据进行摘要,保留与完整数据的相关性;
3)计算中几乎不需要缓存数据,降低内存占用;
4)只需要对数据进行一次计算就能够生成长度合适的摘要值。
综上,本发明采用存储中间计算结果的方法进行流式数据摘要计算,能够处理数据缺损、乱序和重叠的情况,并且矩阵乘法运算作为强哈希算法减少内存占用,使得本发明能够在内存集约的情况下实时计算流式数据摘要。
附图说明
图1表示本发明流式数据处理结构示意图。
图2表示本发明流式模糊哈希摘要生成示意图。
具体实施方式
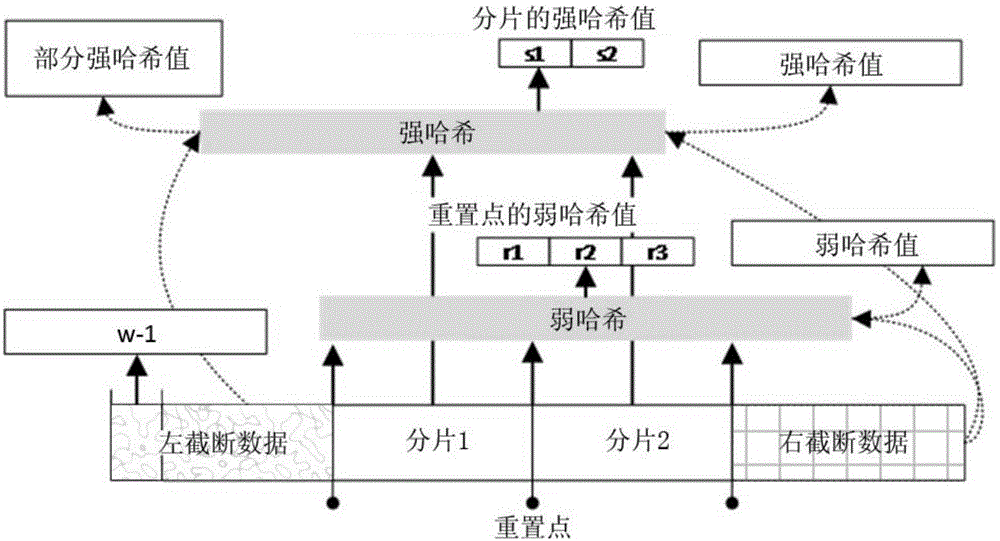
在SFH算法中,一个输入的数据块,如图1所示可能被分割成3个部分:
1)分片,是两个重置点间的数据,可以直接计算出该分片的模糊哈希值;
2)左截断数据,是从数据块起始到第一个重置点之间的数据,不能直接计算出模糊哈希值,需要保留前w-1个字节的数据在缓冲区中,可以计算剩余字节的矩阵乘积(left state);
3)右截断数据,是从数据块中最后一个重置点到数据结束位置之间的数据,它是尚未到完全到达的分片的一部分,不能直接计算出模糊哈希值,可以计算出部分矩阵乘积(mapping hash state);
完整的处理流程主要包含以下几个基本操作(下文中的乘法、乘积均指矩阵乘法):
1)更新操作,输入是一个数据块和其左邻的计算上下文,如果数据块没有左邻(当偏移量为0或乱序时),则是一个刚初始化的计算上下文。
对于一个输入数据块,s为数据块起始位置,具体过程如下:
a)保留前w-1个字节到缓冲区中;
b)对数据块的每一个字节,计算其弱哈希值和强哈希值;
c)当弱哈希值满足分片条件(公式2),则找到重置点。
i.如果是上下文中的第一个重置点,记为部分强哈希值(partial strong hash value,缩写为pshv);
ii.如果不是第一个,则新划分出一个分片,记为该分片的强哈希值(strong hash value of slices);
iii.更新s为分片结束后的下一字节,回到步骤b);
d)当当次输入数据中所有数据块计算结束,将最后一个重置点到数据块结束位置之间的数据称为右截断数据,该部分的强哈希值记为强哈希状态(strong hash state,缩写为shs)。
采用矩阵乘法运算作为强哈希函数计算强哈希值时,二进制流数据流的哈希值可以强哈希值可以表示为以每位或特定位数为单位,映射成n阶矩阵,并将映射后的矩阵按照在数据流中出现的顺序相乘。
所述数据流中重置点的判断条件为,每w个字节计算一个弱哈希值,当得出的弱哈希值满足分片条件后,即为重置点(reset point)。
2)合并操作,对区间索引判断为相邻的两个相邻的计算上下文,p和p的右
邻n进行合并。具体过程如下:
a)对p和n保存在缓冲区中的w-1个字节,执行更新操作;
b)计算p的强哈希状态值shs和n的部分强哈希值pshv的矩阵乘积;
c)如果p中不包含重置点,则用该矩阵乘积更新p的强哈希状态值shs;否则,用该矩阵乘积更新p的部分强哈希状态值pshv;
d)使用矩阵乘法拼接经步骤c)更新后的p和n的强哈希值。
3)生成最终摘要值
当满足计算结束条件时,遍历区间索引,将其中的摘要值进行拼接并输出,如图2所示,其中,Seg1,Seg2…Segn中每一个Seg代表一个计算上下文,[l1,r1],[l2,r2]…[ln,rn]中的每一个代表区间索引里面的一个区间。每个分片的强哈希值是一个n阶矩阵,矩阵中的每个元素是一个m bit数值,将这个矩阵的n*n个元素进行拼接,形成一个n*n*m bit的值,再通过截取或映射成为一个或多个字节的字符,输出形式类似abcd1234[0:30000],方括号内为计算摘要的数据的偏移量信息。
上述步骤中的1)和2)是本发明的核心点,对于每一个Segi,逐字节计算其弱哈希值和强哈希值,将原始数据转化成存储在区间索引中的上下文。
以总大小149GB,包含7998个文件的数据集为例。经测试本发明在乱序输入和顺序输入两种情况下,计算出的摘要结果一致。顺序计算时,花费52min,速度约为47.75MB/s,内存占用峰值1.25kB;乱序计算时,花费57min,速度约为43.8MB/s,内存占用峰值310kB。总体满足实际的应用需求。
- 还没有人留言评论。精彩留言会获得点赞!