一种基于二叉树的文本行精确定位方法与流程
本发明属于场景图像文本行定位领域,具体涉及一种基于二叉树的文本行精确定位方法。
背景技术:
场景图像中的文本行定位是一种在自然场景环境中拍摄的图片中对文本行进行定位的技术。该技术针对多语种翻译、基于内容的网络搜索、视觉辅助以及无人驾驶等领域均有广泛的应用。然而在文本行定位过程中,经常会发生文本行的过分割问题,即原本应被检测为单独一个文本行的区域,因为定位方法不够鲁棒或场景图像中非文字噪音与文本行粘连等原因,而被分割成若干不完整的部分,从而造成很多误检,使得后续的文字识别效果较差。另外还有一种情况是为了避免文本行趋向欠分割,通常定位方法也会专门令文本行定位过分割化,这是因为文本行的欠分割很难被纠正,而过分割问题却能够通过后续的合并等操作对文本行定位进行重置和改善。
为了解决文本行过分割的问题,领域内通常采用的方法是为所有文本行的组合方式构建起一个搜索空间,从中选择出一条最优路径作为重置后的文本行定位结果,例如集束搜索(beam search)方法。但这类方法存在以下缺陷:首先没有考虑到文本行合并过程的特点,因此没有构建符合这些特性的数据结构来表示搜索空间。现有的搜索空间通常是利用近乎全排序的方式来对文本行的所有组合方式进行遍历,然后从中选出一条最优路径。若有n个文本行,则时间复杂度高达O(n(n-1)/2)=O(n2);此外这些方法还缺乏高效的剪枝、融合策略。领域内文本行重定位方法通常是在搜索空间的每一层中对所有结点排序,然后设定一个固定阈值t作为搜索空间宽度,接着将每层中结点序号排到宽度值之外的结点全部剪去。这种设定固定阈值的剪枝、和并方法缺乏灵活性和合理性,无法高效在搜索空间中搜寻到最优路径。
技术实现要素:
本发明针对上述问题,提供了一种基于二叉树的文本行精确定位方法,该方法首先为过分割的文本行构建二叉树搜索空间,然后模拟后序遍历访问方式以Olog(n)的复杂度来搜索路径,接着执行剪枝、合并操作来高效的得到解决过分割问题的最优路径,该路径对应着重置、优化后的文本行精确定位结果。
为了达到上述目的,本发明采用如下技术方案:
一种基于二叉树的文本行精确定位方法,包括以下步骤:
步骤A:对于一副输入的文本行区域被过度分割的自然场景图像,为所有这些被过度分割的文本行建立搜索空间;其中,文本行被过度分割是指文本行定位过程中产生过多的行分割线,导致单个文本行过度分割成若干部分;行分割线用于标注文本行的边界位置以同背景区域区分开来;得到用二叉树表示的搜索空间;
步骤B:对于一个用二叉树表示的搜索空间,二叉树的结点用边界位置这个属性来表示该结点指代的文本行区域组合的范围,并在待合并位置处分成左、右两个子结点;所有文本行区域的组合方式都以结点的形式被纳入该搜索空间;然后通过模拟二叉树后序遍历的方式从搜索空间中构建路径,其中每条路径表示一种特定的文本行组合方式;本步骤的目标是从这些路径中搜索出一条最优路径来重置文本行的定位,以解决文本行过分割问题;
步骤C:对于二叉树搜索空间中某条路径上包含的每个结点集,据结点集中父结点及左、右子结点的置信度比较结果可在八种剪枝、合并策略中选择一种合适的情况进行处理,最终得到解决过分割问题的最优路径,该路径对应着重置后的文本行精确定位结果。
所述步骤A的具体步骤如下:
步骤A01:输入文本行被过度分割的自然场景图像g,其中行分割线包含两个属性:位置l(指代行分割线位于输入图像g中第几行),置信度p(指代行分割线的梯度值,置信度越小则行分割线分离开来的两文本区域间的差异也越小,故该行分割线越容易导致过分割问题);将二叉树搜索空间中的结点同g中的文本行区域一一对应,其中结点包含两个属性:边界位置(结点的左边界位置ll和右边界位置lr对应着某一文本行组合的边界分割线,故边界位置定义了该文本行组合的范围),待合并位置(结点的边界位置内部,具有最大置信度pmax的行分割线的位置lm);
步骤A02:在当前文本行范围内构建父结点np,首先在所有行分割线中选出最外围的首尾行分割线l1,lend的位置作为父结点的边界位置ll,lr,由边界位置可确定该父结点所对应的文本行区域组合的范围;然后在此范围内(不包含边界位置)找到置信度最高pmax的行分割线的位置作为待合并位置lm;
步骤A03:构建父结点np的左子结点nl和右子结点nr,用父结点np的待合并位置lm将父结点代表的文本行区域范围分成左部分partl和右部分partr,分别用左子结点nl和右子结点nr来表示;其中左子结点nl的边界位置ll*,lr*由父结点的左边界位置ll及待合并位置lm构成,左子结点nl的待合并位置lm*由左部分partl中置信度最高的行分割线位置获得;右子结点nr的边界位置由父结点的待合并位置lm及右边界位置lr构成,右子结点nr的待合并位置由右部分partr中置信度最高的行分割线位置获得;
步骤A04:将左子结点nl代表的文本行区域范围作为当前文本行范围,返回到步骤A02并递归地构建二叉树搜索空间中的结点,直到构建到某一左子结点只存在边界位置而不含待合并位置时,则令该结点为叶子节点nleaf(不可再分的文本行单位),并返回到该结点的父节点np处;
步骤A05:将右子结点nr代表的文本行区域范围作为当前文本行范围,返回到步骤A02并递归地构建二叉树搜索空间中的结点,直到构建到某一右子结点只存在边界位置而不含待合并位置时,则令该结点为叶子节点nleaf(不可再分的文本行单位),并返回到该结点的父节点np处;
步骤A06:通过上述步骤,自上而下、自左向右递归地构建二叉树搜索空间,直到最右一个文本行单元作为叶子节点被纳入该搜索空间,即建立起覆盖了所有文本行组合方式的二叉树搜索空间。
所述步骤B具体步骤如下:
步骤B01:对二叉树搜索空间进行后序遍历,得到对所有结点的访问顺序序列{n1,n2,...,nt},其中nt是根结点,在后续遍历中被最后访问到;
步骤B02:据二叉树结构特性及后序遍历规则可将{n1,n2,...,nt-1}按照每三个结点划为一组的方式分成组,再加上根结点nt及其子节点构成的一组,得到共组结点集合,在此过程结点排列顺序不变;其中每个集合s都包含一个父结点及其按待合并位置分开的左、右子结点,得到结点集序列
步骤B03:对于每个结点集用分类器对中的父结点、子结点代表的文本行判断其属于完整文本行的置信度(过分割文本行的置信度较低),然后按照置信度进行剪枝或合并操作(具体的剪枝、合并策略在步骤C中详解),使得每个结点集si只保留一个结点,则此时结点集序列S即为在剪枝、合并策略下选择出的最优路径,从而得到重置的文本行精确定位结果,以解决过分割问题。
所述步骤C具体步骤如下:
步骤C01:分类器判别阶段,对结点集si中的父结点及左、右子结点分别用分类器判断该结点所指代的文本行是否属于完整的文本行(即没有被过度分割的文本行),同时给出该文本行非过分割的置信度;每个结点集根据所含三个结点的判别结果从八种情况中选择合适的一种,进行后续处理;
步骤C02:八种分类器判别情况中,有五种情况无需进行结点置信度比较就可直接根据分类器判别结果来执行决策阶段的剪枝或合并操作;剩下三种情况还需要进一步在结点置信度比较阶段,根据父结点、左子结点及右子结点的置信度比较结果,来对结点所指代的文本行区域执行剪枝或合并操作;最终在剪枝、合并策略下处理过的结点集,构成了二叉树搜索空间中的最优路径,对应着重置后的文本行精确定位结果,解决了文本行的过分割问题。
本发明技术方案具备以下技术效果:针对场景图像中文本行过分割的特征,提出构建二叉树搜索空间。其中,将所有不可再分的文本行单元作为叶子结点(分割置信度为0),将覆盖了若干文本行区域的文本行组合作为中间结点(分割置信度渐高),将整个文本行区域作为根结点(分割置信度最高),即把所有过分割的文本行纳入了二叉树体系。构建二叉树的过程是自上而下、自左向右的,而在二叉树搜索空间中搜索路径采用的后后序遍历是自底向上的,即剪枝、合并操作时从分割置信度较小朝往较大的方向进行,这符合在过分割的文本行中应先合并差异(差异度由分割置信度指代)较小的文本行的规律,因此二叉树这种数据结构很适合作为处理过分割文本行的搜索空间。另外根据二叉树结构特性可知该方法的时间复杂度为Olog(n),相比于其它用排序方法构建的搜索空间O(n2)的复杂度要高效得多。最后本方法采用了符合二叉树特性的一整套自适应地剪枝、合并策略,相比于固定阈值的剪枝方案能够加速文本行精确定位过程,并更精准的解决文本行过分割问题。
附图说明
图1是在输入原图中被过度分割的文本行定位。
图2是为定位出的文本行构建二叉树搜索空间。
图3是模拟后序遍历搜索策略在二叉树搜索空间中构建路径。
图4是剪枝、合并策略。
图5是文本行精确定位效果图(解决了文本行过分割问题)。
具体实施方式
下面结合附图详细介绍本发明各步骤中的具体细节。
本发明提出了一种基于二叉树的文本行精确定位方法,具体包括以下步骤:
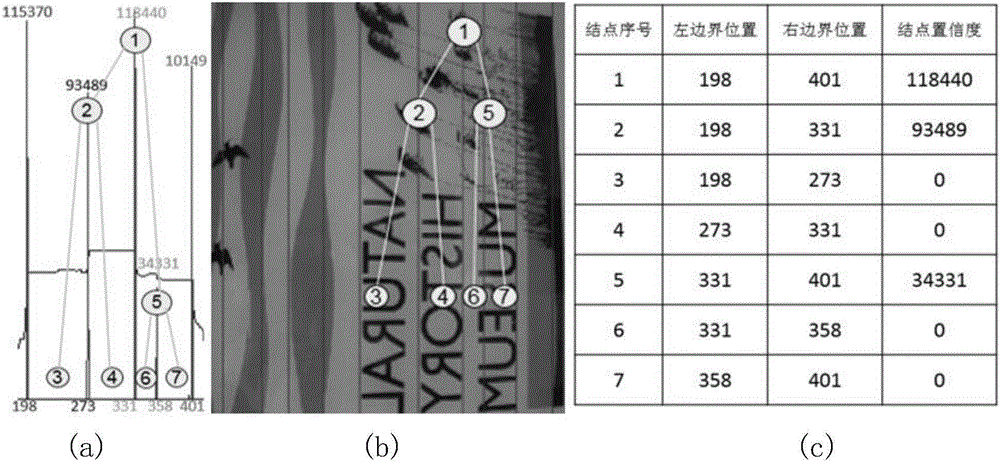
步骤A:输入文本行被过度分割的自然场景图像(如图1所示),其中行分割线的位置及置信度已经给出(如图2(a)所示),要为被过度分割的文本行构建二叉树搜索空间(如图2(b)所示)。二叉树中的结点包含三个属性,分别是结点所指代文本行的左边界位置、右边界位置及置信度。具体实现时用图2(c)所示的表格来存储二叉树搜索空间及结点。其具体实施方式的步骤与权利要求书步骤大体一致,不同之处是增加了构造表格的过程。
步骤A具体步骤如下:
步骤A01:构建一张表来表示二叉树搜索空间,命名为二叉树表。二叉树表中每行代表一个结点,一行包含四个字段(属性),其中结点序号唯一标识一个结点(由序号可看出二叉树中结点的构建过程是自上而下、自左向右),左、右边界位置可确定结点所代表文本行区域的范围,结点置信度在后续的路径搜索步骤中起作用。二叉树表的行数由行分割线的数目num来确定,根据二叉树的结构特性知有num-1个叶子结点及num-2个中间结点,则二叉树表的行数(也就是结点的个数)为N=(2×num-3)行,因此初始化大小为N×4,值均为0的二叉树表来实现二叉树搜索空间。已知结点序号i=1,2,...,N,那么首先从i=1的结点(根结点,也是表中首行)开始构造。
步骤A02:在当前文本行范围内构建父结点np,首先在所有行分割线中选出最外围的首尾行分割线l1,lnum的位置作为父结点的边界位置ll,lr,由边界位置可确定父结点所对应的文本行区域组合的范围。然后在此范围内(不包含边界位置)找到置信度最高pmax的行分割线的位置作为待合并位置lm。接着在二叉树表中第i行,将ll,lr,pmax分别赋予左子结点位置、右子结点位置及结点置信度字段,即完成了当前结点np的构建。令i=i+1,即准备构造二叉树表的下一行。
步骤A03:构建父结点np的左右子结点nl,nr,用父结点np的待合并位置lm将父结点代表的文本行区域范围分成左右两部分partl,partr,分别用左子结点nl和右子结点nr来表示,其中左子结点nl的边界位置ll*,lr*由父结点的左边界位置ll及待合并位置lm构成,nl的待合并位置lm*由partl中置信度最高p*max的行分割线位置获得,则在二叉树表中第i行将ll*,lr*,p*max分别赋予左子结点位置、右子结点位置及结点置信度字段,即完成了当前结点nl的构建,然后令i=i+1,准备构造二叉树表的下一行。同理,右子结点nr的边界位置ll*,lr*由父结点的待合并位置lm及右边界位置lr构成,nr的待合并位置lm*由partr中置信度最高p*max的行分割线位置获得,则在二叉树表中第i行将ll*,lr*,p*max分别赋予左子结点位置、右子结点位置及结点置信度字段,即完成了当前结点nr的构建,然后令i=i+1,准备构造二叉树表的下一行。
步骤A04:将左子结点nl代表的文本行区域范围作为当前文本行范围,返回到步骤A02并递归地构建二叉树搜索空间中的第i个结点,直到构建到某一左子结点只存在边界位置而不含待合并位置时,则令该结点为叶子节点nleaf(不可再分的文本行单位),接着在二叉树表中第i行将分别赋予左子结点位置和右子结点位置字段,并在结点置信度字段赋予0,然后返回到该结点的父节点np处。
步骤A05:将右子结点nr代表的文本行区域范围作为当前文本行范围,返回到步骤A02并递归地构建二叉树搜索空间中的第i个结点,直到构建到某一右子结点只存在边界位置而不含待合并位置时,则令该结点为叶子节点nleaf(不可再分的文本行单位),接着在二叉树表中第i行将分别赋予左子结点位置和右子结点位置字段,并在结点置信度字段赋予0,并返回到该结点的父节点np处。
步骤A06:通过上述步骤,自上而下、自左向右递归地构建二叉树搜索空间,直到最右一个文本行单元作为叶子节点被纳入该搜索空间(即当i=N时),则建立起覆盖了所有文本行组合方式的二叉树搜索空间。
步骤B:在通过步骤A已经构建好的二叉树搜索空间中模拟后序遍历的访问方式来搜索路径,其中每条路径都是一个结点集,而最优路径是对所有结点集来执行剪枝、融合操作(具体操作见步骤C)后得到的结点集序列。构建路径的具体实现是:将二叉树搜索空间中的每个结点的置信度字段设置为脏位(如图3(a)所示),然后结合图3(b)的搜索策略来近似模拟后序遍历,最终构建出图3(c)所示的路径表,表中每行的结点集都代表一条路径。
步骤B具体步骤如下:
步骤B01:利用脏位(即二叉树表中一行的结点置信度字段)和搜索策略来模拟后序遍历,从而自底向上地构建二叉树搜索空间中的路径。在二叉树表中,找脏位中具有非负最小值的结点作为父节点np,然后搜索np的左、右子结点。搜索策略如图3(b)所示,其具体操作是在所有脏位为0的结点中寻找左边界位置与np的左边界位置相同的作为左子结点nl,右边界位置与np的右边界位置相同的作为右子结点nr,接着在图3(c)的路径表中将np,nl,nr分别赋予左子结点、右子结点及父结点字段。
其中,找脏位中具有非负最小值的结点作为父节点np是因为脏位值非负的结点是中间结点,而只有中间结点才能成为候选父结点。然后在候选父结点中选脏位值最小的结点,是因为脏位值(也就是结点置信度值)越小,说明该候选父结点的左、右子结点所代表的文本行被分割开来的可能性越低,则应当越早的接受合并处理。
在所有脏位为0的结点中寻找np的左、右子结点,是因为脏位为0的结点是叶子结点,然后根据边界位置相同的条件来在叶子结点中搜索np的子结点。
路径表存储的是在二叉树搜索空间中搜索得到的输出结果,路径表中每行代表一组结点集(即一条路径),包含左子结点、右子结点及父节点三个字段。路径表的行数与二叉树内中间结点的个数相同,有num-2个(在步骤A01中已知,num是行分割线的个数)。因此路径表是(num-2)×3的二维表。
步骤B02:搜索出步骤B01中所述的一组结点集(路径)后,应当改变脏位(即二叉树表中的结点置信度字段)的数值,以进行下一组结点集的搜索。其具体操作是:将np所在脏位设为0,也就是使np由中间结点变为叶子结点,然后将nl,nr的脏位设为-1,相当于把这两个叶子结点剪去,在后续的搜索过程中不予考虑。经过上述的脏位设置,np改为叶子结点参与后续的路径构建,执行自底向上的搜索过程。
步骤B03:在脏位被重置后,重复从B01到B03的步骤,直到二叉树表中的脏位值除根结点(即序号为1的结点)外均为-1,则得到路径表中num-2个结点集,即为在二叉树搜索空间中搜寻得到的所有路径。
步骤C:对于二叉树搜索空间中某条路径上包含的每个结点集,据结点集中父结点及左、右子结点的置信度比较结果(父结点及左、右子结点所代表的文本行如图4(a)所示),可在八种剪枝、合并策略中选择一种合适的情况进行处理(分类器判别、置信度比较及决策阶段如图4(b)所示),最终得到解决过分割问题的最优路径,该路径对应着重置后的文本行精确定位结果。
步骤C具体步骤如下:
步骤C01:分类器判别阶段,对结点集s中的父结点及左、右子结点分别用分类器判断该结点所指代的文本行是否属于完整的文本行(即没有被过度分割的文本行),同时给出该文本行非过分割的置信度;每个结点集根据所含三个结点的判别结果从八种情况中选择合适的一种,进行后续处理;
步骤C02:八种分类器判别情况中,有五种情况无需进行结点置信度比较就可直接根据分类器判别结果来执行决策阶段的剪枝或合并操作;剩下三种情况还需要进一步在结点置信度比较阶段,根据父结点、左子结点及右子结点的置信度比较结果,来对结点所指代的文本行区域执行剪枝或合并操作;最终在剪枝、合并策略下处理过的结点集,构成了二叉树搜索空间中的最优路径,对应着重置后的文本行精确定位结果,解决了文本行的过分割问题,如图5所示。
- 还没有人留言评论。精彩留言会获得点赞!