一种改进的文本相似度求解方法与流程
本发明涉及语义网络技术领域,具体涉及一种改进的文本相似度求解方法。
背景技术:
目前主要的文本相似度计算方法有两类,第一类是基于数理统计的方法,例如经典的向量空间模型方法。这类方法计算简单,能在词汇出现的频度和频率层面上反映两个文本的相似程度。但是一个有实际意义的文本,它有自己想表达的中心思想,这是语义层面上的概念,数理统计方法提取出来的中心思想与文本实际表达的中心思想相差甚远。因此,如果想要准确的计算文本之间的相似度,必须从语义层面上进行着手;第二类是基于语义分析的方法,这类方法利用语义词典对文本中的词汇进行语义分析,但没有深入语义间的内在联系,也没有考虑文本中特征词汇中不同词汇对文本的重要程度的差异问题,因此计算的准确率较低。为了满足上述需求,本发明提供了一种改进的文本相似度求解方法。
技术实现要素:
针对于文本中特征词汇中不同词汇对文本的重要程度的差异问题,本发明提供了一种改进的文本相似度求解方法。
为了解决上述问题,本发明是通过以下技术方案实现的:
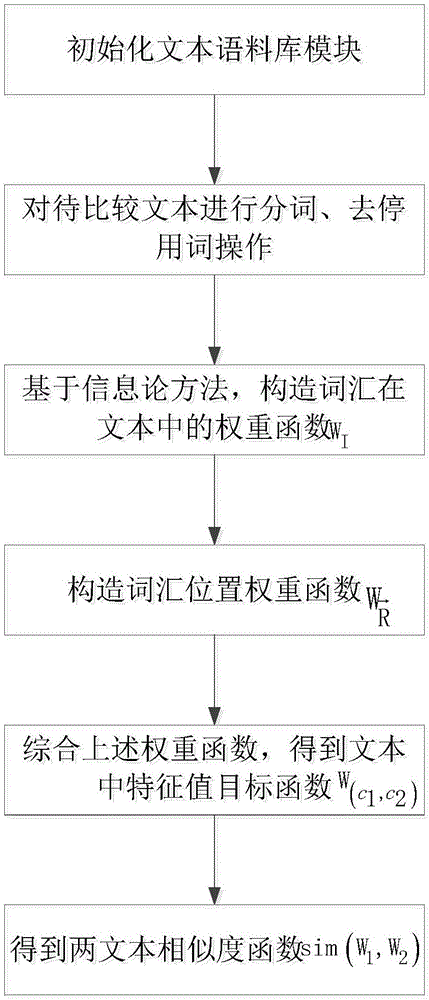
步骤1:初始化文本语料库模块,对待比较文本(W1,W2)的进行预处理。
步骤2:基于信息论方法,计算词汇在文本中权重值WI。
步骤3:根据词汇位置信息,计算词汇在文本中的权重值
步骤4:综合考虑上述两因子,构造提取文本(W1,W2)中的特征值目标函数分别提取文本(W1,W2)中的特征值。
步骤5:求解待比较文本(W1,W2)间的文本相似度sim(W1,W2)。
本发明有益效果是:
1、此方法比传统的文本相似度计算方法得到的结果具有更高的准确性,更符合人工提取的结果。
2、此方法在信息检索、机器翻译、自动问答系统等领域都具有更好的适用性。
3、为后续的文本聚类提供良好的理论基础。
附图说明
图1一种改进的文本相似度求解方法的结构流程图
具体实施方式
为了解决文本中特征词汇中不同词汇对文本的重要程度的差异,结合图1对本发明进行了详细说明,其具体实施步骤如下:
步骤1:初始化文本语料库模块,对待比较文本(W1,W2)的进行预处理,其具体描述过程如下:
利用分词系统和停用表分别对文本(W1,W2)进行分词和去停用词处理。
步骤2:基于信息论方法,计算词汇在文本中权重值WI,其具体计算过程如下:
基于信息论词频的计算公式有:
上式为词汇关于词频在文档中所具有的信息量,p(c1,2)分别为词c1、c2在文本中的概率值。
基于信息论文档频率的计算公式有:
为词汇关于文档频率在文档库中所具有的信息量,为分别含有c1、c2的文档数,N为文档库中文档的总个数。
综上所述,有基于信息论计算词汇权重的函数,如下式:
步骤3:根据词汇位置信息,计算词汇在文本中的权重值其具体计算过程如下:
根据调研资料显示,特征词越在文本靠前位置,越能代表文本的中心思想。通过步骤2得到词汇在文本的权重值,取前20个特征词汇。对这些词汇进行位置权重划分。有位置向量,如下:
词汇位置权重函数为:
上式ai与bj分别为特征词最靠前出现的段落位置和对应段落所在的句子位置。
步骤4:综合考虑上述两因子,构造提取文本(W1,W2)中的特征值目标函数分别提取文本(W1,W2)中的特征值,其具体计算过程如下:
提取文本(W1,W2)中的特征值目标函数为:
上式α、β分别为WI、对特征提取影响的权重系数,α+β=1,一般α>β,即基于信息论得到的词频与文档频率的权重函数对文本(W1,W2)中特征提取的影响更大,其值可以根据实验测试出来。
步骤5:求解待比较文本(W1,W2)间的文本相似度sim(W1,W2),其具体计算过程如下:
根据步骤4计算得出的特征词汇权重值,相关领域专家选取前m位关键词,这里m<20,既分别有文本(W1,W2)对应的特征词向量。
根据欧式距离计算两特征词向量间的距离
最后得到两文本(W1,W2)间的文本相似度sim(W1,W2):
上式ω为平滑因子,可以根据实验得出最佳值。
- 还没有人留言评论。精彩留言会获得点赞!