数据处理方法及装置、分类器训练方法及系统与流程
本发明涉及计算机技术领域,特别涉及一种数据处理方法及装置、分类器训练方法及系统。
背景技术:
当今互联网上每天都会产生大量的信息,且每天都在以惊人的速度膨胀。诸如社交网络、新闻评论、BBS、博客、聊天室、聚合新闻(RSS)等每时每刻都会产生大量的数据,鉴于此,基于自然语言理解领域,通过分类算法实现大量数据的分类,对于信息监管拥有广泛而深远的意义。但是人工对其加以分析和处理的速度已经远远不能满足要求,因而人们已经开始着手研究用统计和学习的方法来对大量的信息进行自动处理和分类。
在传统的机器学习中,通过各种各样的手段获取包括文本、语音、视频和图片在内的各种数据,假设所有的样本独立并服从一个确定的概率分布,并基于这样的假设,训练一个分类器,根据已知样本预测未出现在训练集中的样本,从而通过这种方法来实现数据的自动分类。
传统的机器学习一般分为监督学习(supervised learning)和无监督学习(unsupervised learning)。监督学习是指,对于一批样本,不仅知道其中每一个样本数据本身,还知道其对应的类别标签。通过设计一个分类器,对这批样本进行分类,进而能根据该划分预测新样本的类别标签。而无监督学习是指,训练集中的样本数据都没有类别标签,通过分类算法把数据分成若干类,也称之为聚类。
然而在很多应用的所要分析的海量数据中,只有一部分有类别标签,另外一部分却没有类别标签,这自然使得半监督学习近年来成为研究的热点。半监督学习即是指利用已标注类别标签和未标注类别标签的数据来设计分类器,半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。
常规半监督算法的基本思路是:
①首先用有标签的数据样本训练分类器;
②用训练得到的分类器分类没有标签的数据样本;
③将得到的置信度高的数据样本加入到训练集,同时从无标签数据集中删除该部分样本;
④重新训练分类器,整个过程重复进行直至收敛。
但是,现有的这种半监督算法仍然存在着如下缺点:
1)分类器训练过程中如果一个错误分类的样本被加入了原来的训练集,那么在其后的训练过程中,它所犯的错误只会越来越深,还会诱使其它样本犯错;2).当有标签数据集和无标签数据集所服从分布差别比较大时,使用有标签数据集上训练的模型去预测无标签数据同样会出现效果很差的现象。
技术实现要素:
本发明实施例的目的是提供一种数据处理方法及装置、分类器训练方法及系统,以解决由于引入无标签数据训练分类器可能导致分类器性能降低的问题。
本发明实施例提出一种数据处理方法,用于通过对分类器的训练来对有标签数据和无标签数据进行处理,包括:
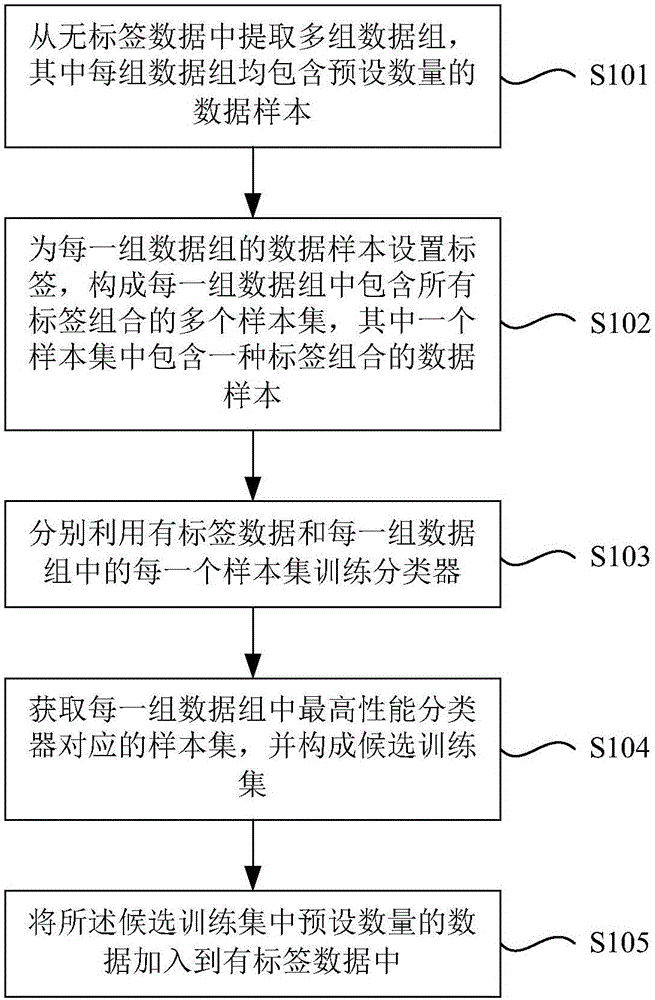
从无标签数据中提取多组数据组,其中每组数据组均包含预设数量的数据样本;
为每一组数据组的数据样本设置标签,构成每一组数据组中包含所有标签组合的多个样本集,其中一个样本集中包含一种标签组合的数据样本;
分别利用有标签数据和每一组数据组中的每一个样本集训练所述分类器;
获取每一组数据组中最高性能分类器对应的样本集,并构成候选训练集;
将所述候选训练集中预设数量的数据加入到有标签数据中。
本发明还提出一种分类器训练方法,包括:
反复通过数据处理方法从无标签数据中获取数据样本加入有标签数据中;
每一次数据样本加入有标签数据后,通过加入数据样本的有标签数据对分类器进行训练。
本发明还提出一种数据处理装置,用于通过对分类器的训练来对有标签数据和无标签数据进行处理,包括:
数据组提取单元,用于从无标签数据中提取多组数据组,其中每组数据组均包含预设数量的数据样本;
标签设置单元,用于为每一组数据组的数据样本设置标签,构成每一组数据组中包含所有标签组合的多个样本集,其中一个样本集中包含一种标签组合的数据样本;
训练单元,用于分别利用有标签数据和每一组数据组中的每一个样本集训练所述分类器;
候选样本获取单元,用于获取每一组数据组中最高性能分类器对应的样本集,并构成候选训练集;
标签数据优化单元,用于将所述候选训练集中预设数量的数据加入到有标签数据中。
本发明还提出一种分类器训练系统,包括数据处理装置以及训练装置,其反复通过所述数据处理装置从无标签数据中获取数据样本加入有标签数据中,并在每一次数据样本加入有标签数据后,训练装置通过加入数据样本的有标签数据对分类器进行训练。
相对于现有技术,本发明的有益效果是:
本发明实施例的数据处理方法及装置、分类器训练方法及系统,充分考虑无标签数据的分布,将无标签数据和有标签数据放到一起学习,使得分类器有更好的泛化能力。
本实施例的数据处理方法,利用大量无标签数据样本,采取启发式遍历组合标签思想,保证引入无标签样本后一定能够使得分类器性能变得更优。
附图说明
图1为本发明实施例的一种数据处理方法的流程图;
图2为本发明实施例的另一种数据处理方法的流程图;
图3为本发明实施例的一种数据处理装置的结构图;
图4为本发明实施例的另一种数据处理装置的结构图;
图5为本发明实施例的一种分类器训练系统的结构图;
图6为本发明实施例的一种数据处理方法及装置、分类器训练方法及系统的应用环境示意图。
具体实施方式
有关本发明的前述及其他技术内容、特点及功效,在以下配合参考图式的较佳实施例详细说明中将可清楚的呈现。通过具体实施方式的说明,当可对本发明为达成预定目的所采取的技术手段及功效得以更加深入且具体的了解,然而所附图式仅是提供参考与说明之用,并非用来对本发明加以限制。
本发明实施例涉及一种数据处理方法及装置、分类器训练方法及系统,其应用于服务器,请参阅图6,其为上述的异常数据检测方法及装置、数据预处理方法及系统的运行环境示意图。一种服务器1200,该服务器1200包括有一个或一个以上计算机可读存储介质的存储器120、输入单元130、显示单元140、一个或者一个以上处理核心的处理器180、以及电源190等部件。本领域技术人员可以理解,图6中示出的服务器结构并不构成对终端的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。其中:
存储器120可用于存储软件程序以及模块,处理器180通过运行存储在存储器120的软件程序以及模块,从而执行各种功能应用以及数据处理。存储器120可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据服务器1200的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器120可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。相应地,存储器120还可以包括存储器控制器,以提供处理器180和输入单元130对存储器120的访问。
输入单元130可用于接收输入的数字或字符信息,以及产生与用户设置以及功能控制有关的键盘、鼠标、操作杆、光学或者轨迹球信号输入。具体地,输入单元130可包括触敏表面131以及其他输入设备132。触敏表面131,也称为触摸显示屏或者触控板,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触敏表面131上或在触敏表面131附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触敏表面131可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器180,并能接收处理器180发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触敏表面131。除了触敏表面131,输入单元130还可以包括其他输入设备132。具体地,其他输入设备132可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
显示单元140可用于显示由用户输入的信息或提供给用户的信息以及服务器1200的各种图形用户接口,这些图形用户接口可以由图形、文本、图标、视频和其任意组合来构成。显示单元140可包括显示面板141,可选的,可以采用LCD(Liquid Crystal Display,液晶显示器)、OLED(Organic Light-Emitting Diode,有机发光二极管)等形式来配置显示面板141。进一步的,触敏表面131可覆盖显示面板141,当触敏表面131检测到在其上或附近的触摸操作后,传送给处理器180以确定触摸事件的类型,随后处理器180根据触摸事件的类型在显示面板141上提供相应的视觉输出。虽然在图6中,触敏表面131与显示面板141是作为两个独立的部件来实现输入和输入功能,但是在某些实施例中,可以将触敏表面131与显示面板141集成而实现输入和输出功能。
处理器180是服务器1200的控制中心,利用各种接口和线路连接整个服务器1200的各个部分,通过运行或执行存储在存储器120内的软件程序和/或模块,以及调用存储在存储器120内的数据,执行服务器1200的各种功能和处理数据,从而对服务器1200进行整体监控。可选的,处理器180可包括一个或多个处理核心;优选的,处理器180可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器180中。
服务器1200还包括给各个部件供电的电源190(比如电池),优选的,电源可以通过电源管理系统与处理器180逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。电源190还可以包括一个或一个以上的直流或交流电源、再充电系统、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。
本发明实施例适用于可用建模样本较少,无标签数据较多的情况,例如征信预警系统、情感分析系统等数据的分类,并利用无标签数据来提升分类器的性能。
实施例一
本发明实施例提出一种数据处理方法,请参见图1,本实施例的数据处理方法包括:
S101,从无标签数据中提取多组数据组,其中每组数据组均包含预设数量的数据样本。所述的数据样本可以是各种信息的集合,例如在征信系统中,姓名、身份证号码、家庭住址、工作单位等身份识别信息,贷款发放银行、贷款额、贷款期限、还款方式、实际还款记录等贷款信息,发卡银行、授信额度、还款记录等信用卡信息可以共同构成一条数据样本。所述预设数量可以根据需要来设定,例如每组数据组都可以包含10个数据样本,即可以依次从无标签数据中抽取10个数据样本构成数据组,假设无标签数据有100个数据样本,那么最多可以提取出10组数据组。
S102,为每一组数据组的数据样本设置标签,构成每一组数据组中包含所有标签组合的多个样本集,其中一个样本集中包含一种标签组合的数据样本。为数据样本设置标签时,需要依据有标签数据的标签来设置,比如假设有标签数据的标签分为优质用户和非优质用户两种类别的标签,那么为数据样本设置标签时同样设置优质用户或非优质用户两种标签。其中,标签的类别是根据不同系统的需要来设定的,比如在征信系统中,可以根据用户的信用度分为优质用户和非优质用户两种标签;又比如在情感分析系统中,可以根据舆情信息的语义定义,分为正面和负面两种标签。当然,标签类别的数量并不以两种为限,但为了便于说明,本发明实施例以两种标签为例进行描述。
所述标签组合就是指包含类别的标签的组合。假设标签类别有两种,一个数据组含有10个数据样本,随机对这个数据组中的数据样本打上标签,那么就共有210也就是1024种不同的标签组合,一个样本集就是一种标签组合的数据样本,也就是,这个数据组包含1024个样本集。以一个简单的例子来说明:
假设一个数据组Q中包含两个数据样本{(用户A),(用户B)},其中(用户A)和(用户B)中包括用户A和用户B的信用数据,假设标签类别分为优质用户和非优质用户,那么对这个数据组Q进行标签标注,就形成四个样本集:{(用户A,优质用户),(用户B,优质用户)}、{(用户A,优质用户),(用户B,非优质用户)}、{(用户A,非优质用户),(用户B,优质用户)}、{(用户A,非优质用户),(用户B,非优质用户)}。
S103,分别利用有标签数据和每一组数据组中的每一个样本集训练分类器。步骤S102已经为样本集打上标签,因此可以依次把样本集加入到有标签数据中来训练分类器。分类器通常属于一个数学模型,其中包含众多参数,通常意义上所述对分类器的训练,即对分类器中参数的调整过程,以使分类器达到更好的分类效果。如果有10组数据组,每组数据组包含1024个样本集,那么要训练分类器10240次。
S104,获取每一组数据组中最高性能分类器对应的样本集,并构成候选训练集。经过步骤S103对分类器的训练,可以对分类器性能进行排序,从而选出每一组数据组对应的最高性能分类器,并获取对应的样本集。分类器的性能可以通过AUC(Area Under Curve)值来考量,AUC值表示分类器ROC(Receiver Operating Characteristic)曲线下方的面积,AUC值越大,表示分类器性能越好。如果有10组数据组,那么可以选出10个最好性能分类器对应的样本集,这10个样本集就构成了候选训练集,候选训练集即是能对分类器的训练产生最好效果的数据样本的集合。
以下对二类比较器的AUC值的计算进行说明:
首先定义:
TN比较器将实际负类预测为负类的样本数;
FN比较器将实际正类预测为负类的样本数;
FP比较器将实际负类预测为正类的样本数;
TP比较器将实际正类预测为正类的样本数;
其中,正类表示关注的类别,比如比较器的目的是找出优质用户,那么优质用户即为正类。
然后计算FRP(False Positive Rate,假正率)值和TPR(True Positive Rate,真正率)值:
FPR=FP/(FP+TN)
TRP=TP/(TP+FN)
接着以FPR为横轴,TPR为纵轴,就得到分类器的ROC曲线,最后计算ROC曲线下方的面积,即AUC值,就能直观地对分类器性能进行评价。
S105,将所述候选训练集中预设数量的数据加入到有标签数据中。这里所述的预设数量也可以根据需要来设定,比如可以将候选训练集中所有样本集中的数据均加入到有标签数据中,也可以线下测试选择候选训练集中最优的一部分样本集的数据样本加入到有标签数据中。选择候选训练集中一部分样本集的数据样本加入到有标签数据中时,还可以按照分类器的性能对候选训练集中的样本集进行排序,并选出需要数量的样本集加入到有标签数据中。
本实施例的数据处理方法,充分考虑无标签数据的分布,实质是将无标签数据和有标签数据放到一起学习,使得分类器有更好的泛化能力(泛化能力[generalization ability]是指机器学习算法对新鲜样本的适应能力)。
本实施例的数据处理方法,利用大量无标签数据样本,采取启发式遍历组合标签思想,保证引入无标签样本后一定能够使得分类器性能变得更优。
实施例二
请参见图2,其为本发明实施例的另一种数据处理方法的流程图,本实施例的数据处理方法包括以下步骤:
S201,将有标签数据按照预设比例划分为用于训练分类器的训练集和用于测试分类器的测试集。所述比例可以按照需要来设定,比如1:8或者1:9等。
S202,对无标签数据进行聚类。当需要处理的无标签样本数非常多时,为了节约计算资源,因而本实施例引入聚类算法,聚类以后每一类中的样本是相似的,那么每一类的数据所打标签是相同的。
S203,从每一类别的无标签数据中提取出一个数据样本,并将每预设数量的数据样本构成一个所述数据组。
S204,提取多组数据组。
S205,为每一组数据组的数据样本设置标签,构成每一组数据组中包含所有标签组合的多个样本集,其中一个样本集中包含一种标签组合的数据样本。
S206,将每一组数据组中的每一个样本集的数据样本分别加入所述训练集,构成多个新的训练集;
S207,通过多个新的训练集分别训练所述分类器。
S208,分别计算经过多个新的训练集训练的分类器的AUC值。
S209,获取每一数据组中最高AUC值对应的样本集,并构成所述候选训练集。
S210,将所述候选训练集中预设数量的数据加入到训练集中。
本实施例的数据处理方法,充分考虑无标签数据的分布,实质是将无标签数据和有标签数据放到一起学习,使得分类器有更好的泛化能力。
本实施例的数据处理方法,利用大量无标签数据样本,采取启发式遍历组合标签思想,保证引入无标签样本后一定能够使得分类器性能变得更优。
本实施例的数据处理方法,针对无标签数据量过多的情况,提出聚类和半监督结合使用的算法,大大地降低了分类器训练的时间复杂度。
实施例三
本实施例提出一种分类器训练方法,首先反复通过数据处理方法从无标签数据中获取数据样本加入有标签数据中,然后在每一次数据样本加入有标签数据后,通过加入数据样本的有标签数据对分类器进行训练。其中,所述的数据处理方法与实施例一或实施例二相同,在此不再赘述。
本实施例的分类器训练方法,利用大量无标签数据样本,采取启发式遍历组合标签思想,保证引入无标签样本后能够使得分类器性能变得更优。与传统的半监督模型不同,本实施例的分类器训练方法不考虑具体打标签的准确性,只考虑能否利用无标签样本的分布来改善分类器的性能,并且保证不会出现引入无标签数据反而导致分类器性能变坏的情况,能够很好利用无标签数据提升模型分类效果。因而,本实施例的分类器训练方法特别适用于存在大量无标签样本,且有标签样本数量不足的系统,例如在社交征信预警模型中应用本实施例的分类器训练方法,可以充分利用征信预警模型建设过程中大量未被利用的无标签数据来提升分类器性能,使得银行对信贷用户的风控能力进一步提升。
实施例四
本实施例提出一种数据处理装置,用于通过对分类器的训练来对有标签数据和无标签数据进行处理,请参见图3,本实施例的数据处理装置包括:数据组提取单元31、标签设置单元32、训练单元33、候选样本获取单元34以及标签数据优化单元35。
数据组提取单元31用于从无标签数据中提取多组数据组,其中每组数据组均包含预设数量的数据样本。所述的数据样本可以是各种信息的集合。所述预设数量可以根据需要来设定。例如每组数据组都可以包含10个数据样本,即可以依次从无标签数据中抽取10个数据样本构成数据组,假设无标签数据有100个数据样本,那么最多可以提取出10组数据组。
标签设置单元32用于为每一组数据组的数据样本设置标签,构成每一组数据组中包含所有标签组合的多个样本集,其中一个样本集中包含一种标签组合的数据样本。假设标签类别有两种,一个数据组含有10个数据样本,随机对这个数据组中的数据样本打上标签,那么就共有210也就是1024种不同的标签组合,一个样本集就是一种标签组合的数据样本,也就是,这个数据组包含1024个样本集。
训练单元33用于分别利用有标签数据和每一组数据组中的每一个样本集训练所述分类器。标签设置单元32已经为样本集打上标签,因此可以依次把样本集加入到有标签数据中来训练分类器。如果有10组数据组,每组数据组包含1024个样本集,那么要训练分类器10240次。
候选样本获取单元34用于获取每一组数据组中最高性能分类器对应的样本集,并构成候选训练集。经过训练单元33对分类器的训练,可以对每一组数据组中的数据训练出分类器性能进行排序,从而选出每一组数据组对应的最高性能分类器,并获取对应的样本集。分类器的性能可以通过AUC值来考量,AUC值越大,表示分类器性能越好。如果有10组数据组,那么可以选出10个最好性能分类器对应的样本集,这个10个样本集就构成了候选训练集,候选训练集即是能对分类器的训练产生最好效果的数据样本的集合。
标签数据优化单元35用于将所述候选训练集中预设数量的数据加入到有标签数据中。这里所述的预设数量也可以根据需要来设定,比如可以将候选训练集中所有样本集中的数据均加入到有标签数据中,也可以线下测试选择候选训练集中最优的一部分样本集的数据样本加入到有标签数据中。选择候选训练集中一部分样本集的数据样本加入到有标签数据中时,还可以按照分类器的性能对候选训练集中的样本集进行排序,并选出需要数量的样本集加入到有标签数据中。
本实施例的数据处理方法,充分考虑无标签数据的分布,实质是将无标签数据和有标签数据放到一起学习,使得分类器有更好的泛化能力(泛化能力[generalization ability]是指机器学习算法对新鲜样本的适应能力)。
本实施例的数据处理方法,利用大量无标签数据样本,采取启发式遍历组合标签思想,保证引入无标签样本后一定能够使得分类器性能变得更优。
实施例五
请参见图4,其为本发明实施例的另一种数据处理装置的结构图。与实施例四相比,本实施例的数据处理装置除了包括:数据组提取单元31、标签设置单元32、训练单元33、候选样本获取单元34及标签数据优化单元35,还包括:标签数据划分单元36和聚类单元37。
聚类单元37用于对无标签数据进行聚类。当需要处理的无标签样本数非常多时,为了节约计算资源,因而本实施例引入聚类算法,聚类以后每一类中的样本是相似的,那么每一类的数据所打标签是相同的。这样,数据组提取单元31就可以从每一类别的无标签数据中提取出一个数据样本,并将每预设数量的数据样本构成一个所述数据组。
标签数据划分单元36用于将所述有标签数据按照预设比例划分为用于训练分类器的训练集和用于测试分类器的测试集。
其中,所述训练单元33又进一步包括:训练集设置模块331和分类器训练模块332。训练集设置模块331用于将每一组数据组中的每一个样本集的数据样本分别加入所述训练集,构成多个新的训练集。分类器训练模块332用于通过多个新的训练集分别训练所述分类器。
所述候选样本获取单元34又进一步包括:性能值计算模块341和样本集采集模块342。性能值计算模块341用于分别计算经过多个新的训练集训练的分类器的AUC值。样本集采集模块342用于获取每一数据组中最高AUC值对应的样本集,并构成所述候选训练集。
本实施例的数据处理方法,充分考虑无标签数据的分布,实质是将无标签数据和有标签数据放到一起学习,使得分类器有更好的泛化能力。
本实施例的数据处理方法,利用大量无标签数据样本,采取启发式遍历组合标签思想,保证引入无标签样本后一定能够使得分类器性能变得更优。
本实施例的数据处理方法,针对无标签数据量过多的情况,提出聚类和半监督结合使用的算法,大大地降低了分类器训练的时间复杂度。
实施例六
本实施例提出一种分类器训练系统,请参见图5,其包括数据处理装置51以及训练装置52。其首先反复通过数据处理装置51从无标签数据中获取数据样本加入有标签数据中,然后在每一次数据样本加入有标签数据后,训练装置52通过加入数据样本的有标签数据对分类器进行训练。其中,所述的数据处理装置51与实施例四或实施例五相同,在此不再赘述。
本实施例的分类器训练系统,利用大量无标签数据样本,采取启发式遍历组合标签思想,保证引入无标签样本后能够使得分类器性能变得更优。与传统的半监督模型不同,本实施例的分类器训练方法不考虑具体打标签的准确性,只考虑能否利用无标签样本的分布来改善分类器的性能,并且保证不会出现引入无标签数据反而导致分类器性能变坏的情况,能够很好利用无标签数据提升模型分类效果。因而,本实施例的分类器训练系统特别适用于存在大量无标签样本,且有标签样本数量不足的系统,例如在社交征信预警模型中应用本实施例的分类器训练方法,可以充分利用征信预警模型建设过程中大量未被利用的无标签数据来提升分类器性能,使得银行对信贷用户的风控能力进一步提升。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本发明实施例可以通过硬件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,本发明实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或网络设备等)执行本发明实施例各个实施场景所述的方法。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本申请技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本申请技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!