基于移动通信信令大数据挖掘职住位置标签的系统及方法与流程
本发明涉及基于大数据挖掘位置标签的技术领域,更具体地说涉及基于移动通信信令大数据挖掘职住位置标签的系统及方法。
背景技术:
随着用户终端、业务应用及市场环境的不断发展,更多精确营销、业务发展和企业应用需要获知用户的工作及居住位置区域信息(职住位置),作为普及渗透率已高达70%的移动手机终端,其自身具有的随时携带性和网络终端定期/非定期交互特征,使得移动通信信令交互数据和用户行为数据成为分析用户职住位置标签的首选,并且因为移动通信信令数据中的位置信息是以无线小区(ci)标记的,而目前网络条件下的无线小区的平均覆盖半径在350米到700之间,所以可以在合理保护用户隐私的前提下,对用户的职住位置标签的评估分析和挖掘探查起到有效的支撑。
现有对移动用户的职住位置标签的分析方法主要是采用在用户手机终端app内嵌定期上报agps位置的代码,然后由手机或者无线上网卡连到无线网络,使得服务器端能够获取用户的位置信息以达到对位置信息的收集,然后采用topn统计分析方法获得职住位置标签,并通过电话调查以及营业厅在进行业务办理时所采集到的身份证信息对由topn统计分析方法获得结果进行验证。
但目前省级运营商移动用户规模已达千万量级、无线基站小区数量也达到了数十万个,如此庞大的用户数量和深度覆盖水平,采用上述方式进行用户的职住位置标签的分析,显然在时效性、经济成本方面都是无法满足要求的。
并且基于移动通信信令大数据进行用户的职住位置标签的挖掘分析时,需要引入时间序列和业务行为类型数据对用户行为与移动位置轨迹进行建模分析,使得数据具有较大的维度,而topn统计分析方法对大维度数据的分析无法达到较理想的效果。
聚类分析(clusteranalysis)方法能够支持对海量数据的多元统计分析,也常被用于用户的位置轨迹点出入规律的数据挖掘,但对于基于移动通信信令大数据进行职住位置的挖掘,由于缺乏先验知识和可供参考的预知模式,所以仅是一位用户在一个统计周期(两周或者一个月)内采集到的数据即可高达数千甚至上万个,从而形成了高维数据集合,众所周知,受“维度效应”的影响,许多在低维度数据空间表现良好的聚类方法在运用到高维数据集合中往往无法达到理想的聚类效果。
因此,确有必要就基于移动通信信令大数据进行批量、高效的职住位置标签的挖掘分析进行更深一步的研究。
技术实现要素:
本发明的第一目的在于提供一种基于移动通信信令大数据挖掘职住位置标签的系统,具有降低数据集合的维度,提高用户的职住位置标签的挖掘发现能力和计算效率的优点。
本发明的上述目的是通过以下技术方案得以实现的:一种基于移动通信信令大数据挖掘职住位置标签的系统,包括
用户个体活动序列建立单元,用于基于cs域移动用户信令数据和ps域移动用户信令及业务xdr详单日志中的用户行为和网络事件记录,按照“事件活动位置—事件起始时间—事件持续时长”模型建立用户个体活动序列;
网格生成单元,用于将移动用户信令和行为xdr日志中记录的小区位置信息按照经纬度信息划分成均匀的网格单元;
网格聚类分析计算单元,用于将xdr记录中的lac/ci信息按照经纬度信息映射到对应的所述网格单元中,并调用网格聚类分析算法计算得到在指定时段内的占用密集网格簇;
密度聚类分析计算单元,用于调用密度聚类分析算法计算得到所述占用密集网格簇的质心;
职住位置标签生成单元,用于基于所述网格簇的质心生成用户的职住位置标签。
采用上述方案,将cs域移动用户信令数据和ps域移动用户信令及业务xdr详单日志中的用户行为和网络事件的数据记录构建为用户个体活动序列,降低了数据集合的维度,使得采用网格聚类分析算法能够获得较理想的聚类效果,从而实现对用户位置轨迹点出入规律的数据挖掘。
作为优选,所述网格聚类分析计算单元包括
网格筛选子单元,用于在调用网格聚类分析算法之前,根据预设的密度阈值和稀疏密度阈值将网格单元分类为密集网格单元和稀疏网格单元,并删除所述稀疏网格单元。
采用上述方案,通过理论分析和实验证明,删除稀疏网格单元不会影响到网格聚类分析算法的聚类质量,并且删除稀疏网格单元可减少不必要的计算数据,提高网格聚类分析算法的计算速度。
作为优选,所述网格聚类分析计算单元还包括网格聚类结果输出子单元,用于根据计算得到的所述占用密集网格簇,调用topn统计分析方法分别生成在指定时段内的top5用户活动密集区块、用户事件发生频度最高小区以及用户事件持续时长最高小区,并分别写入所述网格聚类结果输出子单元中建有的二级表单中。
采用上述方案,通过采用topn统计分析方法对占用密集网格簇进行分析,可获得一个粗略的区域范围结果。
作为优选,所述密度聚类分析计算单元调用的密度聚类分析算法为dbscan算法。
采用上述方案,dbscan算法是一个比较有代表性的基于密度的聚类算法,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
作为优选,所述密度聚类分析计算单元调用的dbscan算法用于将所述占用密集网格簇中的所有点标记为核心点、边界点或者噪声点,并将任意两个距离小于预设的距离阈值的所述核心点归为同一个簇,以及将与所述核心点的距离小于距离阈值的所述边界点也归为同一个簇。
采用上述方案,在数据量较大时,dbscan算法的时间复杂度是相当高,如此一来就需要进行非常多次的区域查询,通过上述方式,改进dbscan的时间复杂度,以起到降低区域查询次数的作用,提高计算速度。
本发明的第二目的在于提供一种基于移动通信信令大数据挖掘职住位置标签的方法,具有降低数据集合的维度,提高用户的职住位置标签的挖掘发现能力和计算效率的优点。
本发明的上述目的是通过以下技术方案得以实现的:一种基于移动通信信令大数据挖掘职住位置标签的方法,包括下列步骤:
步骤一,基于cs域移动用户信令数据和ps域移动用户信令及业务xdr详单日志中的用户行为和网络事件记录,按照“事件活动位置—事件起始时间—事件持续时长”模型建立用户个体活动序列;
步骤二,将移动用户信令和行为xdr日志中记录的小区位置信息按照经纬度信息划分成均匀的网格单元;
步骤三,将xdr记录中的lac/ci信息按照经纬度信息映射到对应的所述网格单元中,并调用网格聚类分析算法计算得到在指定时段内的占用密集网格簇;
步骤四,调用密度聚类分析算法计算得到所述占用密集网格簇的质心;
步骤五,基于所述网格簇的质心生成用户的职住位置标签。
采用上述方案,将cs域移动用户信令数据和ps域移动用户信令及业务xdr详单日志中的用户行为和网络事件的数据记录构建为用户个体活动序列,降低了数据集合的维度,使得采用网格聚类分析算法能够获得较理想的聚类效果,从而实现对用户位置轨迹点出入规律的数据挖掘。
作为优选,所述步骤二还包括:在调用网格聚类分析算法之前,根据预设的密度阈值和稀疏密度阈值将网格单元分类为密集网格单元和稀疏网格单元,并删除所述稀疏网格单元。
采用上述方案,通过理论分析和实验证明,删除稀疏网格单元不会影响到网格聚类分析算法的聚类质量,并且删除稀疏网格单元可减少不必要的计算数据,提高网格聚类分析算法的计算速度。
作为优选,所述步骤二还包括:根据计算得到占用密集网格簇后,调用topn统计分析方法分别生成在指定时段内的top5用户活动密集区块、用户事件发生频度最高小区以及用户事件持续时长最高小区,并分别写入建有的二级表单中。
采用上述方案,通过采用topn统计分析方法对占用密集网格簇进行分析,可获得一个粗略的区域范围结果。
作为优选,步骤四所调用的密度聚类分析算法为dbscan算法。
采用上述方案,dbscan算法是一个比较有代表性的基于密度的聚类算法,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
作为优选,所述dbscan算法将所述占用密集网格簇中的所有点标记为核心点、边界点或者噪声点,并将任意两个距离小于预设的距离阈值的所述核心点归为同一个簇,以及将与所述核心点的距离小于距离阈值的所述边界点也归为同一个簇。
采用上述方案,在数据量较大时,dbscan算法的时间复杂度是相当高,如此一来就需要进行非常多次的区域查询,通过上述方式,改进dbscan算法的时间复杂度,以起到降低区域查询次数的作用,提高计算速度。
综上所述,本发明具有以下有益效果:
其一,将cs域移动用户信令数据和ps域移动用户信令及业务xdr详单日志中的用户行为和网络事件的数据记录构建为用户个体活动序列,具有降低数据集合维度的优点,使得采用网格聚类分析算法能够获得较理想的聚类效果;
其二,通过网格聚类分析算法和密度聚类分析算法的结合使用,提升了基于移动通信信令大数据进行用户的职住位置标签的挖掘发现能力和计算效率;
其三,利用密度聚类分析算法在具有噪声的数据中发现识别用户的职住位置标签的核心区域,从而具有提升用户的职住位置标签的识别精度的优点。
附图说明
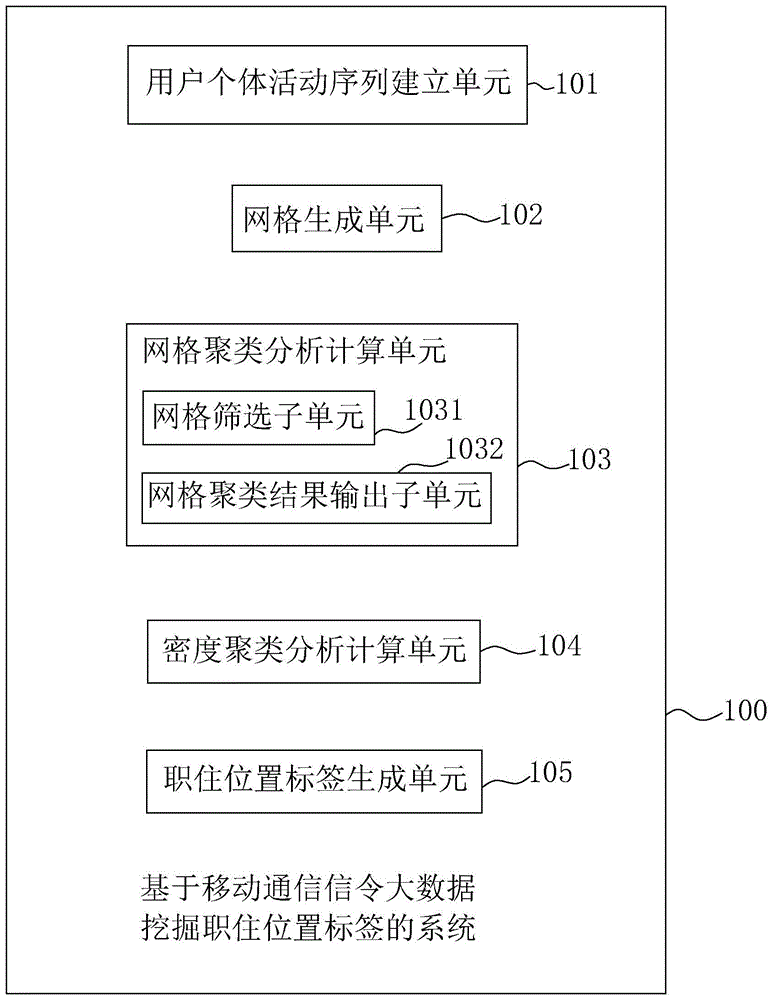
图1是基于移动通信信令大数据挖掘职住位置标签的系统的框图;
图2是基于移动通信信令大数据挖掘职住位置标签的方法的流程图;
图3是用户个体活动序列建模示意图;
图4是调用网格聚类分析算法得到结果图;
图5是调用密度聚类分析算法得到的结果图。
图中,100、基于移动通信信令大数据挖掘职住位置标签的系统;101、用户个体活动序列建立单元;102、网格生成单元;103、网格聚类分析计算单元;104、密度聚类分析计算单元;105、职住位置标签生成单元;1031、网格筛选子单元;1032、网格聚类结果输出子单元。
具体实施方式
以下结合附图对本发明作进一步详细说明。
本具体实施例仅仅是对本发明的解释,其并不是对本发明的限制,本领域技术人员在阅读完本说明书后可以根据需要对本实施例做出没有创造性贡献的修改,但只要在本发明的权利要求范围内都受到专利法的保护。
一种基于移动通信信令大数据挖掘职住位置标签的系统100,参照图1,包括用户个体活动序列建立单元101、网格生成单元102、网格聚类分析计算单元103、密度聚类分析计算单元104和职住位置标签生成单元105。其中,网格聚类分析计算单元103包括网格筛选子单元1031和网格聚类结果输出子单元1032。
参照图2,基于移动通信信令大数据挖掘职住位置标签的系统100的作业流程如下:
步骤一,基于cs域移动用户信令数据和ps域移动用户信令及业务xdr详单日志中的用户行为和网络事件记录,按照“事件活动位置—事件起始时间—事件持续时长”模型建立用户个体活动序列。
其中事件活动位置代表该移动用户事件发生时所处无线小区位置,事件起始时间表征移动终端/用户个体出现在该无线小区位置的开始时刻,事件持续时长代表该事件持续的时间,也代表该用户在某活动地点的持续停留时间。一个时段内同一用户在同一无线小区的多次事件行为表征了该用户出现在该无线小区所覆盖地理区域的频度或无线小区占用密度。
参照图3,为用户个体活动序列建模示意图。
步骤二,将移动用户信令和行为xdr日志中记录的小区位置信息按照经纬度信息划分成均匀的网格单元。
步骤三,将xdr记录中的lac/ci信息按照经纬度信息映射到对应的网格单元中,并调用网格聚类分析算法计算得到在指定时段内的占用密集网格簇。
其中,在调用网格聚类分析算法前,根据预设的密度阈值和稀疏密度阈值将网格单元分类为密集网格单元和稀疏网格单元,并删除稀疏网格单元。
簇作为一个区域,该区域中的点的密度大于与之相邻的区域。在网格数据结构中,由于每个网格单元都有相同的体积,因此网格单元中数据点的密度即是落到单元中的点的个数,据此可以得到稠密网格单元的密度。设在某一时刻t一个网格单元的密度为density,定义density=单元内的数据点数/数据空间中总的数据点数,预设密度阈值为ε,可由用户输入,当density>ε时,该网格单元即判定为一个密集网格单元。
相对于稠密网格单元来说,大多数的网格单元包含非常少甚至空的数据,这一类网格单元被称为稀疏网格单元。预设稀疏密度阈值为θ,可由用户输入,当density<θ时,该网格单元即被判定为一个稀疏单元。大量的稀疏网格单元的存在会极大的降低聚类的速度,因此需要在聚类之前对稀疏网格单元进行处理,本实施例中对稀疏网格单元采取的处理方式为删除稀疏网格单元,理论分析和实验证明删除稀疏网格单元不会影响到聚类的质量。
基于用户个体活动序列的网格聚类分析算法的实现流程如下:
1)在指定时段内根据xdr记录中lac/ci信息计算各网格的占用次数,发现和输出占用次数高于等于周边临接网格的占用峰值网格;
2)创建一个队列,队列字段包括网格坐标、时段、占用次数、小区场景字段。以上一步骤中发现的占用次数排序最高的n个非邻接占用峰值网格(占用密集网格)作为队头网格,分配区域id,并以其为中心扩展,扫描周边所有网格,并计算周边该时段内发生过占用的网格是否与其相邻或相接,则将该网格加入该密集区域形成占用密集网格簇,直至不再有这样的网格被发现(判断标准即与另外一个簇的边界是否间隔一个网格以上)。
3)判断队列长度是否为1,如为1,则转去处理下一个网格,循环上述步骤;否则做如下处理:
a)取出队头网格坐标和区域id,检查所有邻接网格是否发生占用。
b)更改相邻已检查过的网格状态为“已处理”。
c)若邻接网格存在占用情况,则将其纳入该密集网格簇,该网格坐标、占用次数写入队列。
d)循环重复直至该网格簇的相邻和相接网格均无占用情况发生,不再有这样的网格被发现(判断标准即与另外一个簇的边界是否间隔一个网格以上)。
4)在循环的每一遍中各队列只处理其队头网格,即:找到与队头网格邻接的未发现的占用密集网格置入队尾,将被发现的网格按其区域id对其网格编号建立一个新数组,若某次循环发现各队列均为空,算法处理结束。
5)如某队头网格发现一个与其邻接的网格已被某队列发现过,且该网格的区域id与本队头网格的区域id不同,则表明两个分属不同区域的密集网格簇相遇贯通,被发现网格的区域id及该区域id下所有网格均被重新标记为新的区域id,即两个簇区贯通融合。
6)寻找发现剩余网格中占用次数大于预设门限1/2的网格,形成新的占用峰值网格,创建新队列,进行下一个簇的查找,并重复上述步骤。
7)遍历所有网格,直至该时段内所有发生过占用的网格均标记为已处理,或剩余网格的占用次数小于预设门限,予以丢弃。
参照图4,为网格聚类分析算法得到的结果图。
根据计算得到占用密集网格簇后,调用topn统计分析方法分别生成在指定时段内的top5用户活动密集区块、用户事件发生频度最高小区以及用户事件持续时长最高小区,并分别写入网格聚类结果输出子单元1032中建有的二级表单中。
步骤四,调用密度聚类分析算法计算得到占用密集网格簇的质心;本实施例中调用的密度聚类分析算法为dbscan算法,dbscan是一种基于密度的聚类算法,它有一个核心点的概念:如果一个点,在与它在预设的距离阈值的范围内有不少于minpts个点,则该点就是核心点。核心点和与它相距距离在距离阈值范围内的邻居形成一个簇。在一个簇内如果出现多个点都是核心点,则将以这些核心点为中心的簇合并。
使用dbscan算法将上述各网格密集簇中所有点标记为核心点、边界点或噪声点,对任意两个距离小于预设的距离阈值的核心点归为同一个簇。任何与核心点的距离小于预设的距离阈值的边界点也与核心点归为同一个簇。
参照图5,为密度聚类分析算法计算得到的结果图。
步骤五,基于网格簇的质心生成用户的职住位置标签。
本实施例可以解决较高频度、大范围、海量用户职住位置标签的挖掘与识别,基于网格分割和用户行为特征对用户高密度出现的区域划分,并利用密度聚类算法在具有噪声的数据中发现识别任意形状的特征位置网格簇,同时体现出以下特点:
1)不需要对用户个体活动序列的数据的分布做任何假设,分析得到的结果与数据记录处理的顺序无关,客观度较好;
2)不需要分析人员预先指定聚类分析子空间,可以自动发现存在聚类可能的子空间;
3)对干扰噪声数据存在非敏感性,降低了数据etl的复杂度。
- 还没有人留言评论。精彩留言会获得点赞!