改进k‑means算法的噪声数据去除方法及实施系统与流程
本发明涉及一种噪声去除领域,尤其是涉及一种改进k-means算法的噪声数据去除方法及实施系统。
背景技术:
噪声数据可能是数据集中的错误数据,可能是测量变量时产生的随机误差或偏差,也可能是不相关的数据或者无意义的数据。噪声数据的出现通常是由收集数据的仪器出错、数据传输中的错误、技术上的限制或者数据输入错误等原因造成的。比如在传感器网络采集的过程中由于传感器故障或者人为原因会导致采集到的数据在某一段时间出现较大波动,而这种波动对后续的挖掘任务来说是无意义的,且使得数据不在规定的数据域内,从而会影响后面的挖掘效果和结果,因此需要被消除。常用的消除噪声数据的方法有:分箱法、回归法、聚类法。
分箱法指通过参考周围实例的值来平滑需要处理的数据值,分箱的主要目的是去噪,将连续数据离散化,增加粒度。现有的分箱方法有等深分箱法和等宽分箱法,“箱的深度”表示不同的箱里有相同个数的数据,“箱的宽度”表示每个箱值的取值区间。具体方法有按箱平均值平滑法(即把箱中的所有值平均,然后使用箱的平均值替代箱中所有数据)、按箱中值平滑法(即对箱中的值求中值,然后使用箱的中值替代箱中所有数据)以及按箱边界平滑法(即把箱中的最大和最小值被视为箱边界,箱中的每一个值用最近的箱边界值替换)。由于分箱方法考虑相邻的值,因此是一种局部平滑方法,该算法简单容易实现,但使用该方法时,原数据损失很大,不能有效保留原数据的特征。
回归法是指可以用一个函数如回归函数拟合数据来光滑数据。线性回归涉及找出拟合两个属性或变量的“最佳”线,使得一个属性可以用来预测另一个。多元线性回归是线性回归的扩展,其中涉及的属性多于两个,并且数据拟合到一个多维曲面,该方法清除噪声数据精确有效,但推广能力不足,且由于需要拟合出最佳的曲线或曲面,故耗时也较大。
聚类法是通过发现数据中的族找出数据中的离群点,然后将它们删除,以此达到去除噪声数据的目的,数据集中落在簇集之外的空气温度数据即为噪声数据。
k-means算法是比较经典的基于距离的聚类算法,它把k作为参数输入,随机选取k个中心点,最终将n个对象划分为k个簇,在这k个簇中同一簇中的成员具有较高的相似度,不同簇中的成员具有较高的相异度。k-means聚类算法中的聚类中心是通过计算一个簇中所有数据对象属性的均值来确定的,因此,k-means算法通常用来处理数值型的属性。
k-means算法在很多实际应用中都是一种很有效的聚类方法。但是普通的k-means算法有一个很大的缺点,即它的聚类结果随着随机选择的初始聚类中心的变化会有很大的变化,因此不能保证总能得到比较好的聚类结果,且最终的聚类结果的精确度依赖于初始聚类中心的选择。因此,初始中心点的选择对最终的聚类结果有很大的影响,选择适当的初始中心点可以加快聚类算法的收敛速度,而且还会改善聚类结果的质量。
技术实现要素:
本发明提供了一种改进k-means算法的噪声数据去除方法及实施系统,该方法与该系统的结合在去除金针菇栽培过程空气温度数据中的噪声数据时,具有精确度高、稳定性好、可靠性高、实时性强等优点。
一种改进k-means算法的噪声数据去除方法,具体包括:
(1)采集空气温度数据,利用最远优先策略选出k个聚类中心作为当前聚类中心,k为自然数;
(2)根据当前聚类中心对所有的空气温度数据进行聚类,将每个空气温度数据聚到离它最近的聚类中心表示的聚类簇中;
(3)计算当前每个聚类簇的均值作为新的聚类中心;
(4)判断新的聚类中心与上一次的聚类中心是否相同,若是,执行步骤(5),若否,将新的聚类中心作为当前聚类中心,循环步骤(2)~步骤(4);
(5)计算所有新的聚类中心中任意两个聚类中心之间的距离;
(6)判断任意两个聚类中心之间的距离是否大于设定的环境阈值,若是,执行步骤(7),若否,执行步骤(8);
(7)将任意两个聚类中心之间的距离大于设定的环境阈值的那部分簇筛选出来,然后将空气温度数据的数量较少且空气温度数据的均值偏离正常值较远的那一簇删除;
(8)输出不存在噪声数据。
在步骤(1)中,最远优先策略的基本思想:
首先从整个数据集合中随机的选出一个空气温度数据作为第一个聚类中心,然后从剩下的数据中选离第一个中心最远的空气温度数据作为第二个中心,然后再从剩下的数据中选择离前两个中心点所组成的集合最远的空气温度数据作为第三个中心点,以此类推,直到选择的中心数达到所要求的簇数为止。最远优先策略就是使簇间的距离尽可能的远,这正符合聚类定义的要求。
利用最远优先策略选出k个聚类中心的步骤为:
(1-1)对于所有的空气温度数据,随机选择一个空气温度数据作为第一个聚类中心;
(1-2)计算所有不是聚类中心的空气温度数据到聚类中心集合的最小距离;
(1-3)将当前最小距离数组中最大的值所对应的空气温度数据标记为聚类中心;
(1-4)判断聚类中心的个数是否小于k,若是,执行步骤(1-2)~步骤(1-4),若否,输出k个聚类中心。
在步骤(1-2)中,计算所有不是聚类中心的空气温度数据到聚类中心集合的最小距离的公式为:
D(x,Y)=min{d(x,y)|y∈Y}
其中,Y为聚类中心的集合,d(x,y)为标准化的欧式距离公式;
在步骤(4)中,新的聚类中心与上一次的聚类中心相同,则认为得到的新的聚类结果与上一次的聚类结果一样,聚类过程结束;新的聚类中心与上一次的聚类中心不相同,则认为得到的新的聚类结果与上一次的聚类结果不同,需要继续进行寻优聚类,直到聚类结果不变为止。
在步骤(6)中,所述的环境阈值根据实际需要自行设置,是对实际的空气温度数据的波动程度的评估,所述的正常值指的是空气温度的理论值。
在步骤(6)中,若任意两个聚类中心之间的距离小于设定的环境阈值,则认为不存在噪声数据,环境阈值是根据空气温度数据的特征决定的。
改进k-means算法的噪声数据去除方法在初始聚类中心的选择上引入了最远优先策略,同时又引入了环境阈值来判断数据中是否含有噪声,使得去噪数据精确度高,稳定性好。
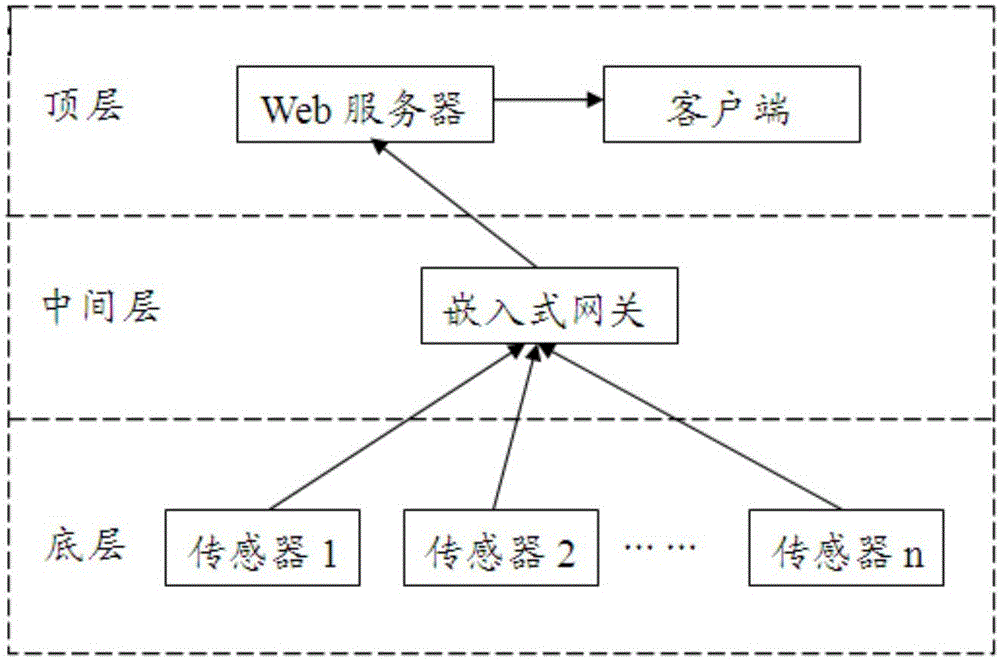
改进k-means算法的噪声数据去除方法的实施系统,包括置于底层的多组无线传感器、置于中间层的嵌入式网关以及置于顶层的B/S结构;无线传感器将采集的信号发送到嵌入式网关,嵌入式网关响应服务器的请求并将接收到的信号发送给B/S结构,B/S结构对接受的信号进行处理,完成噪声数据的去除。
所述的无线传感器内置了ZigBee无线发射模块,将采集到的信号通过相应的协议发送到中间层的嵌入式网关。
所述的嵌入式网关负责接收无线传感器上传的数据,同时响应服务器的请求,并将数据发送给服务器。
所述的B/S结构包括Web服务器与客户端,Web服务器接收嵌入式网关上传的数据,并对数据解析和存储,同时响应客户端的请求,对用户的请求做出反馈,是一个智慧农业生产平台部分。
在B/S结构中,传感器上传的数据按其类型分类,分别存入不同的数据表,当进行去噪操作时,用户通过选择日期来对相应日期的数据进行去噪操作,并以折线图的形式展示去噪前后的环境数据变化情况,当用于综合应用时,可将分类模块隐藏,设置为定时操作,如在每天的零点,对前一天的所有数据进行一次去噪操作,以方便后续的数据挖掘等操作。
所述的Web服务器采用Nginx+uWSGI组合服务器,部署在服务器上的Web应用采用Django框架,该框架是python语言编写的一个Web应用框架,采用了MVC的设计模式,非常适合快速开发。
本发明改进k-means算法的噪声数据去除方法及实施系统,将去除方法与实施系统相结合,具有以下优点:
(1)本发明在传统聚类方法的基础上,引入了环境阈值,同时加入了最远优先策略,可以更快速、更准确地识别出环境数据中的噪声数据。
(2)本发明提供一种精确度高、稳定性好、可靠性高、能够远程实时性的去噪系统,实现对采集到的环境参数进行在线去噪,为后续的数据挖掘等操作提供有效的数据。
附图说明
图1为实施改进k-means算法的噪声数据去除方法的系统结构示意图图;
图2为改进k-means算法的噪声数据去除方法的流程图;
图3为最远优先策略选出k个聚类中心的方法流程图;
图4为实施例1中含有噪声数据的空气温度数据图;
图5为实施例1中噪声数据去除后的空气温度数据图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
如图1所示,一种改进k-means算法的噪声数据去除方法的实施系统,包括置于底层的30组无线传感器、置于中间层的嵌入式网关以及置于顶层的Web服务器与客户端;无线传感器定时采集数据并将数据按相应的协议打包好,通过内置的zigbee无线发射模块将数据发送到中间层的嵌入式网关,该网关中同样集成了zigbee无线模块,主要用来接收传感器上传的数据,同时响应服务器的请求将数据发送给顶层的Web服务器,Web服务器定时向嵌入式网关请求数据,并将数据存储在数据库中,客户端通过可视化的界面,对服务器中的数据进行查看、编辑等各项操作。
如图2所示,一种基于k-means算法的噪声数据处理算法具体包括:
步骤1,采集空气温度数据,利用最远优先策略选出k个聚类中心作为当前聚类中心。
最远优先策略的基本思想:
首先从整个数据集合中随机的选出一个空气温度数据作为第一个聚类中心,然后从剩下的数据中选离第一个中心最远的空气温度数据作为第二个中心,然后再从剩下的数据中选择离前两个中心点所组成的集合最远的空气温度数据作为第三个中心点,以此类推,直到选择的中心数达到所要求的簇数为止。最远优先策略就是使簇间的距离尽可能的远,这正符合聚类定义的要求。
如图3所示,利用最远优先策略选出k个聚类中心的步骤为:
步骤1-1,对于所有的空气温度数据,随机选择一个空气温度数据作为第一个聚类中心;
步骤1-2,根据以下公式,计算所有不是聚类中心的空气温度数据到聚类中心集合的最小距离:
D(x,Y)=min{d(x,y)|y∈Y}
其中,Y为聚类中心的集合,d(x,y)为标准化的欧式距离公式;
步骤1-3,将当前最小距离数组中最大的值所对应的空气温度数据标记为聚类中心;
步骤1-4,判断聚类中心的个数是否小于k,若是,执行步骤1-2~步骤1-4,若否,输出k个聚类中心。
步骤2,根据当前聚类中心对所有的空气温度数据进行聚类,将每个空气温度数据聚到离它最近的聚类中心表示的聚类簇中。
步骤3,计算当前每个聚类簇的均值作为新的聚类中心。
步骤4,判断新的聚类中心与上一次的聚类中心是否相同,若是,执行步骤5,若否,将新的聚类中心作为当前聚类中心,循环步骤2~步骤4。
步骤5,计算所有新的聚类中心中任意两个聚类中心之间的距离。
步骤6,判断任意两个聚类中心之间的距离是否大于设定的环境阈值,若是,执行步骤7,若否,执行步骤8;
步骤7,将任意两个聚类中心之间的距离大于设定的环境阈值的那部分簇筛选出来,然后将空气温度数据的数量较少且空气温度数据的均值偏离正常值较远的那一簇删除;
步骤8,输出不存在噪声数据。
实施例1
从东北某金针菇工厂中采集回来的金针菇栽培过程中的某日某库房1号节点的空气温度数据总数为1443个,将这1443个空气温度数据画成折线图,分析折线图可得,空气温度值的上下波动不超过1℃,因此将环境阈值设置为1,选取的聚类中心的个数为2个。
从东北某金针菇工厂中采集回来的金针菇栽培过程中的某日某库房2号节点的空气温度数据总数为1444个,图4是采集到的1444个数据的分布图,可以看出当日数据在某一点处有一个极大值,且持续时间很短,初步判断是由传感器故障引起,需要被去除。
采用传统的k-means算法和本发明改进的算法分别处理1444个空气温度数据,结果发现,当传统的k-means算法作用于该空气温度数据时,算法迭代了两次便停止了,且簇内误差平方和达到了77.91,通过聚类分成的两簇所占的数量可以看出,该算法此次并没有把噪声数据正确分离出来。而本发明改进的k-means算法作用于该空气温度数据时,该算法同样是迭代了两次,但簇内误差平方和仅为1.64,较传统的k-means算法来说非常的小,且从聚成的两类所占数量来看,本发明的方法成功地把噪声数据分离了出来,达到了噪声点去除的效果,从图5可以明显地看出,噪声数据已经被成功去除。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!