网络社区的挖掘方法及装置与流程
本发明实施例涉及大数据分析技术领域,尤其涉及一种网络社区的挖掘方法及装置。
背景技术:
在移动互联时代,人们的社交行为越来越多的依赖于网络。比如,人们通过网络社区对一个热点事件表达不同的观点,或者通过各种即时通讯软件完成相互之间的联络。可以预见的是,由于人们的很多社交行为通过网络上自发形成的网络社区完成,因此,可以通过对人们网络交互数据的挖掘,得到人们日常的网络交流行为所形成的各种“人际圈子”,也就是网络社区。
如果能够通过对网络数据的分析、挖掘,得到人们进行日常交流的网络社区,无疑将对企业的更多决策提供有效的支持。比如,可以通过上述挖掘得知人们在网络上行程的网络社区的关注话题是什么,进而为企业下一步的营销目标及营销战略提供决策支持。
然而,对于这种在网络上形成的网络社区的挖掘,目前还没有可行的技术方案。
技术实现要素:
针对上述技术问题,本发明实施例提供了一种网络社区的挖掘方法及装置,以实现对网络社区及其组成成员的有效挖掘。
一方面,本发明实施例提供了一种网络社区的挖掘方法,所述方法包括:
获取以弹性分布式数据集合RDD形式存储的原始网络社区,以及所有前次挖掘得到的前次挖掘网络社区;
获取与所述原始网络社区中的成员存在通联关系的初步网络社区成员,并以RDD形式将所有初步网络社区成员存储为初步网络社区;
获取所有一个成员属于所述初步网络社区,另一个成员属于所述初步网络社区,或者所述原始网络社区,或者所述前次挖掘网络社区的目标通联关系,并以RDD形式将所述目标通联关系所涉及的网络社区成员存储为泛化网络社区;
获取所述泛化网络社区与所述原始网络社区及所述前次挖掘网络社区之间的差集,并以RDD形式将所述差集中的成员存储为目标网络社区;
重复上述挖掘操作,直至所述目标网络社区的规模维持稳定,或者目标网络社区达到预定规模,或者所述挖掘操作的次数达到挖掘次数上限。
另一方面,本发明实施例还提供了一种网络社区的挖掘装置,所述装置包括:
原始获取模块,用于获取以弹性分布式数据集合RDD形式存储的原始网络社区,以及所有前次挖掘得到的前次挖掘网络社区;
初步获取模块,用于获取与所述原始网络社区中的成员存在通联关系的初步网络社区成员,并以RDD形式将所有初步网络社区成员存储为初步网络社区;
泛化获取模块,用于获取所有一个成员属于所述初步网络社区,另一个成员属于所述初步网络社区,或者所述原始网络社区,或者所述前次挖掘网络社区的目标通联关系,并以RDD形式将所述目标通联关系所涉及的网络社区成员存储为泛化网络社区;
目标获取模块,用于获取所述泛化网络社区与所述原始网络社区及所述前次挖掘网络社区之间的差集,并以RDD形式将所述差集中的成员存储为目标网络社区;
重复执行模块,用于重复上述挖掘操作,直至所述目标网络社区的规模维持稳定,或者目标网络社区达到预定规模,或者所述挖掘操作的次数达到挖掘次数上限。
本发明实施例提供的网络社区的挖掘方法及装置,通过获取原始网络社区及前次挖掘网络社区,获取成员与原始网络社区中的成员之间存在通联关系的初步网络社区,再将所述初步网络社区进行泛化,获得泛化网络社区,最后对所述泛化网络社区中的成员进行精简,得到目标网络社区,使得目标网络社区中的每个成员都与网络社区中的至少一个成员之间存在两两通联的通联关系,实现了对目标网络社区及其成员的有效挖掘。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1是本发明第一实施例提供的网络社区的挖掘方法的流程图;
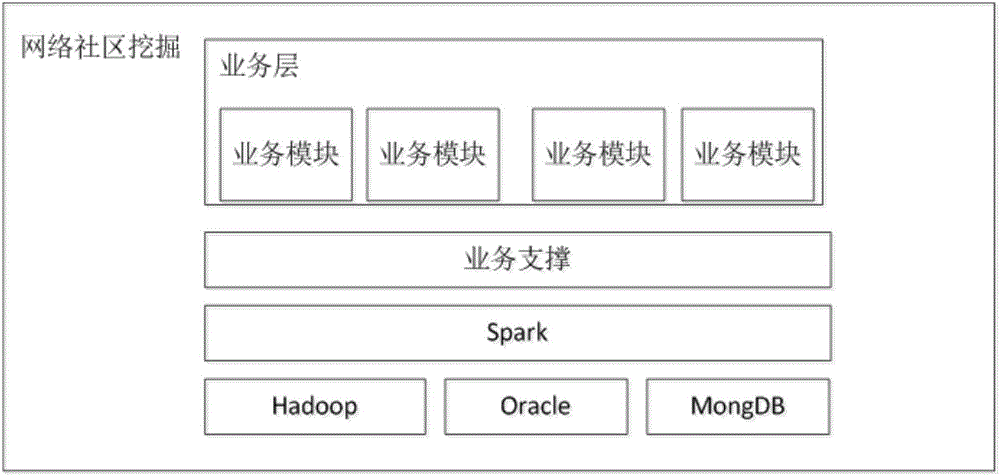
图2是本发明第一实施例提供的应用系统的系统结构框图;
图3是本发明第一实施例提供的网络社区的挖掘方法挖掘得到的网络社区的示意图;
图4是本发明第二实施例提供的网络社区的挖掘方法的流程图;
图5是本发明第三实施例提供的网络社区的挖掘方法的流程图;
图6是本发明第四实施例提供的网络社区的挖掘装置的结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
第一实施例
本实施例提供了网络社区的挖掘方法的一种技术方案。在该技术方案中,网络社区的挖掘方法通常由大数据分析系统执行。优选的,该技术方案提供的网络社区的挖掘方法由Spark系统执行。
参见图1,网络社区的挖掘方法包括:
S11,获取以弹性分布式数据集合(Resilient distributed datasets,RDD)形式存储的原始网络社区,以及所有前次挖掘得到的前次挖掘网络社区。
RDD是Spark提供的最重要的抽象的概念,它是一种有容错机制的特殊集合,可以分布在集群的节点上,以函数式编操作集合的方式,进行各种并行操作。RDD是一个具有容错机制的特殊集合,它提供了一种只读、只能有已存在的RDD变换而来的共享内存,然后将所有数据都加载到内存中,方便进行多次重用。
在本实施例中,由于采用Spark大数据分析系统进行网络社区的挖掘,因此,在挖掘的各个中间步骤中,使用RDD作为网络社区挖掘的最终结果及各种中间结果的存储形式。
可以理解的是,网络社区是由相互之间保持通联关系的网络社区成员组成的。也就是说,网络社区可以是看作是由不同的网络社区成员组成的成员集合。
所谓通联关系,是指成员之间存在着通过网络进行沟通交流的记录。例如,成员甲曾经打电话给成员乙,则认为成员甲与成员乙之间存在由成员甲指向成员乙的通联关系。又例如,成员丙曾经在网络论坛回复成员丁发起的帖子,则认为成员丙与成员丁之间存在由成员丙指向成员丁的通联关系。需要注意的是,上述的通联关系是一种包含指向性的关系。
对网络社区数据的挖掘是以上述通联关系为基础的。因此,在本实施例提供的网络社区的挖掘方法被执行之前,需要预先准备好通联关系数据。优选的,在网络社区的挖掘方法被执行之前,除了通联关系数据,还需要预先准备好成员的身份数据。身份数据中保存成员的标签数据与真实身份数据之间的对应关系。例如,标签数据可以是在挖掘通联关系时使用的成员的IMEI、IMSI,或者网络账号。身份数据是能够唯一标识成员身份的数据,例如,身份数据可以是成员的手机号。上述通联关系数据以及身份数据均预先执行挖掘,并且在网络社区的挖掘方法之前,保存在HDFS(Hadoop distributed file system)中。
图2示出了执行上述挖掘的系统的系统架构。参见图2,在系统底层,部署有Hadoop、Oracle、Mongo DB等数据存储组件。在这些数据存储组件之上,部署有Spark系统。在Spark系统之上,设置有各种业务支撑组件。在这些业务支撑组件之上,部署有执行数据挖掘的业务层。该业务层由不同的业务模块组成,最终完成对于网络社区数据的挖掘。
而且,对网络社区的挖掘是一个顺次迭代的过程。也就是说,可以以前次挖掘到的网络社区为基础,进一步的执行下一次的挖掘操作。这就意味着,除了首次执行的挖掘操作以外,其他的挖掘操作都在它之前的挖掘操作。这些之前的挖掘操作的结果是本次挖掘的基础数据。而在第一次挖掘时,它所依赖的基础数据的预先准备的通联关系数据中任意选择的一条通联关系数据。
在执行网络社区的挖掘之前,首先需要获取到原始网络社区以及前次挖掘网络社区。原始网络社区是指本次社区挖掘操作之前一次挖掘操作的结果数据。前次挖掘网络社区是指比前一次挖掘操作更早的挖掘操作的结果数据。需要注意的是,原始网络社区以及前次挖掘网络社区都是以RDD形式存储的数据。
S12,获取与所述原始网络社区中的成员存在通联关系的初步网络社区成员,并以RDD形式将所有初步网络社区成员存储为初步网络社区。
与原始网络社区中的成员之间保持有通联关系的其他成员可能会成为本次挖掘中网络社区的组成成员。这些与原始网络社区中的成员之间存在通联关系的成员被称为初步网络社区成员。而且,需要注意的是,初步网络社区成员与原始网络社区成员之间的通联关系可以是指向原始网络社区成员的通联关系,也可以是指向初步网络社区成员的通联关系。
在获取到原始网络社区及前次挖掘网络社区之后,挖掘上述初步网络社区成员,以便能够完成本次的网络社区的挖掘操作。
S13,获取所有一个成员属于所述初步网络社区,另一个成员属于所述初步网络社区,或者所述原始网络社区,或者所述前次挖掘网络社区的目标通联关系,并以RDD形式将所述目标通联关系所涉及的网络社区成员存储为泛化网络社区。
在获取到初步网络社区之后,对获取到的初步网络社区执行验证。具体的,首先获取符合如下条件的通联关系:通联关系所涉及的一位成员属于初步网络社区,而另一位成员属于初步网络社区,或者原始网络社区,或者前次挖掘网络社区。符合上述条件的通联关系被称为目标网络社区。
目标网络社区所涉及的成员被确认为泛化网络社区的社区成员,因此,将泛化网络社区的数据以RDD形式进行存储。
S14,获取所述泛化网络社区与所述原始网络社区及所述前次挖掘网络社区之间的差集,并以RDD形式将所述差集中的成员存储为目标网络社区。
泛化网络社区中的社区成员数据会存在一些重复。为了去除重复的成员数据,将泛化网络社区的集合数据与原始网络社区及前次挖掘网络社区的数据做差,求得的差集就是目标网络社区的数据。
同样,在求得目标网络社区之后,仍然以RDD形式存储所述目标网络社区的数据。
S15,重复上述挖掘操作,直至所述目标网络社区的规模维持稳定,或者目标网络社区达到预定规模,或者所述挖掘操作的次数达到挖掘次数上限。
可以理解的是,由于预先准备的通联关系的数据的规模有限,执行有限次的网络社区挖掘操作之后,挖掘得到的网络社区的成员数据就会趋于稳定。此时,可以不再重复执行挖掘操作,以得到网络社区数据作为最终的挖掘结果。
另外,在执行挖掘之前,可能对于挖掘的结果或者挖掘的执行过程有着明确的预期。比如,在挖掘之前,预想挖掘得到的网络社区具有一定的规模,当这个规模已经在重复的挖掘操作中得到了实现,则可以停止进一步的挖掘。再比如,在挖掘之前,预想挖掘操作具有一次的循环执行次数上限,当这个次数上限已经达到时,则可以停止进一步的挖掘操作,以当前挖掘到的网络社区作为挖掘的最终结果。
图3示出了挖掘得到的网络社区。参见图3,在网络社区中,不同的社区成员之间有相互之间的通联关系。
本实施例通过获取以弹性分布式数据集合RDD形式存储的原始网络社区,以及所有前次挖掘得到的前次挖掘网络社区,获取与所述原始网络社区中的成员存在通联关系的初步网络社区成员,并以RDD形式将所有初步网络社区成员存储为初步网络社区,获取目标通联关系,并以RDD形式将所述目标通联关系所涉及的网络社区成员存储为泛化网络社区,获取所述泛化网络社区与所述原始网络社区及所述前次挖掘网络社区之间的差集,并以RDD形式将所述差集中的成员存储为目标网络社区,重复上述挖掘操作,直至相应的停止条件被满足,从而实现了对目标网络社区及其成员的有效挖掘。
第二实施例
本实施例以本发明上述实施例为基础,进一步的提供了网络社区的挖掘方法的另一种技术方案。在该技术方案中,网络社区的挖掘方法还包括:在获取以RDD形式存储的原始网络社区,以及前次挖掘得到的前次挖掘网络社区之前,通过数据挖掘技术,以流式处理框架挖掘成员真实身份数据,以及成员通联关系数据。
参见图4,网络社区的挖掘方法包括:
S41,通过数据挖掘技术,以流式处理框架挖掘成员真实身份数据,以及成员通联关系数据。
在本实施例中,以JStorm流式处理框架完成成员的真实身份数据已经成员之间通联关系数据的挖掘。在采用JStorm框架的过程中进行上述两种数据的挖掘过程中,采用了数据挖掘操作。上述数据挖掘操作具体是指:格式转换、数据提取、数据清洗、数据关联。
可以理解的是,对真实身份数据及通联关系数据的挖掘的数据源主要包括网络日志。网络日志的格式不统一,数据内容也存在大量的重复。因此,需要运用数据挖掘技术对数据进行格式转换、数据清洗等一系列操作。
S42,获取以弹性分布式数据集合RDD形式存储的原始网络社区,以及前次挖掘得到的前次挖掘网络社区。
S43,获取与所述原始网络社区中的成员存在通联关系的初步网络社区成员,并以RDD形式将所有初步网络社区成员存储为初步网络社区。
S44,获取所有一个成员属于所述初步网络社区,另一个成员属于所述初步网络社区,或者所述原始网络社区,或者所述前次挖掘网络社区的目标通联关系,并以RDD形式将所述目标通联关系所涉及的网络社区成员存储为泛化网络社区。
S45,获取所述泛化网络社区与所述原始网络社区及所述前次挖掘网络社区之间的差集,并以RDD形式将所述差集中的成员存储为目标网络社区。
S46,重复上述挖掘操作,直至所述目标网络社区的规模维持稳定,或者目标网络社区达到预定规模,或者所述挖掘操作的次数达到挖掘次数上限。
本实施例通过在获取原始网络社区及前次挖掘网路社区之前,挖掘真实身份数据及成员通联关系数据,实现了对目标网络社区及其成员的有效挖掘。
第三实施例
本实施例以本发明上述实施例为基础,进一步的提供了网络社区的挖掘方法的再一种技术方案。在该技术方案中,网络社区的挖掘方法还包括:在完成所述挖掘操作之后,根据成员之间的通联关系对所述目标网络社区的成员打分,以挖掘所述目标网络社区中的核心成员。
S51,通过数据挖掘技术,以流式处理框架挖掘成员真实身份数据,以及成员通联关系数据。
S52,获取以弹性分布式数据集合RDD形式存储的原始网络社区,以及前次挖掘得到的前次挖掘网络社区。
S53,获取与所述原始网络社区中的成员存在通联关系的初步网络社区成员,并以RDD形式将所有初步网络社区成员存储为初步网络社区。
S54,获取所有一个成员属于所述初步网络社区,另一个成员属于所述初步网络社区,或者所述原始网络社区,或者所述前次挖掘网络社区的目标通联关系,并以RDD形式将所述目标通联关系所涉及的网络社区成员存储为泛化网络社区。
S55,获取所述泛化网络社区与所述原始网络社区及所述前次挖掘网络社区之间的差集,并以RDD形式将所述差集中的成员存储为目标网络社区。
S56,重复上述挖掘操作,直至所述目标网络社区的规模维持稳定,或者目标网络社区达到预定规模,或者所述挖掘操作的次数达到挖掘次数上限。
S57,根据成员之间的通联关系对所述目标网络社区的成员打分,以挖掘所述目标网络社区中的核心成员。
具体的,根据通联关系的具体属性为成员们打分。例如,成员之间出现一次电话通话,为参加通话的成员各自计50分。成员之间出现一次短消息沟通,为短消息的所有发送成员及接收成员计20分。成员之间出现一次通过互联网的沟通,为沟通各方计1分。当然,具体的积分办法可以根据情况进行调整。完成上述计分操作后,得分最高的网络社区成员就是核心成员。
本实施例在完成网络社区的挖掘之后,为社区成员打分,实现了对网络社区中核心成员的挖掘。
第四实施例
本实施例提供了网络社区的挖掘装置的一种技术方案。参见图6,网络社区的挖掘装置包括:原始获取模块62、初步获取模块63、泛化获取模块64、目标获取模块65,以及重复执行模块66。
所述原始获取模块62用于获取以弹性分布式数据集合RDD形式存储的原始网络社区,以及前次挖掘得到的前次挖掘网络社区。
所述初步获取模块63用于获取与所述原始网络社区中的成员存在通联关系的初步网络社区成员,并以RDD形式将所有初步网络社区成员存储为初步网络社区。
所述泛化获取模块64用于获取所有一个成员属于所述初步网络社区,另一个成员属于所述初步网络社区,或者所述原始网络社区,或者所述前次挖掘网络社区的目标通联关系,并以RDD形式将所述目标通联关系所涉及的网络社区成员存储为泛化网络社区。
所述目标获取模块65用于获取所述泛化网络社区与所述原始网络社区及所述前次挖掘网络社区之间的差集,并以RDD形式将所述差集中的成员存储为目标网络社区。
所述重复执行模块66用于重复上述挖掘操作,直至所述目标网络社区的规模维持稳定,或者目标网络社区达到预定规模,或者所述挖掘操作的次数达到挖掘次数上限。
优选的,所述通联关系表示:一个成员与另一个成员之间存在关联。
优选的,所述关联包括:所述一个成员与所述另一个成员之间存在通讯联系。
优选的,网络社区的挖掘装置还包括:原始数据挖掘模块61。
所述原始数据挖掘模块61用于在获取以RDD形式存储的原始网络社区,以及前次挖掘得到的前次挖掘网络社区之前,通过数据挖掘技术,以流式处理框架挖掘成员真实身份数据,以及成员通联关系数据。
优选的,网络社区的挖掘装置还包括:核心成员挖掘模块67。
所述核心成员挖掘模块67用于在完成所述挖掘操作之后,根据成员之间的通联关系对所述目标网络社区的成员打分,以挖掘所述目标网络社区中的核心成员。
本领域普通技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个计算装置上,或者分布在多个计算装置所组成的网络上,可选地,他们可以用计算机装置可执行的程序代码来实现,从而可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件的结合。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!