基于图的主题描述词预测及排序方法与流程
本发明涉及一种基于图的主题描述词预测及排序方法。
背景技术:
在知识爆炸的今天,为了更好地结合网上资源和图书资源给用户更好的知识服务体验,提供用户更多关于某个主题的关键信息点以帮助用户更好地理解和挖掘知识内容,提出基于图的主题描述词的预测及排序方法。根据现在已有的主题描述词来预测给定主题词的描述词,通过层次不同的描述词序列来提供系统的知识服务。
技术实现要素:
本发明的目的在于提供一种基于图的主题描述词预测及排序方法,从而方便用户更系统地了解知识点。
本发明解决其技术问题采用的技术方案如下:一种基于图的主题描述词预测及排序方法,包括以下步骤:
1)主题描述词的预测问题转化:将主题描述词的预测问题转化为一个二部图的预测问题,主题词与描述词可视作该二部图的两个互不相交的子集,属于不同集合的顶点之间边的关系即为主题词和描述词之间的关系,预测主题词和描述词之间的属于关系即预测存在边的可能性得分;
2)预测问题映射:对步骤1)中得到的预测问题,利用图的张量积将二部图的预测问题转化为顶点标签的传播问题,通过图的乘积运算,在本发明中采用的是张量积的方法,将主题词图和描述词图融合为一个图,图中的每个顶点表示(主题词,描述词),预测问题映射为预测图中不相连顶点之间边的存在问题;
3)基于图的转导推理:构造损失函数以及图的正则化方程,得到学习目标,利用给定的主题词和描述词构造的顶点信息进行预测,得到未知的主题词与描述词之间的关系;
4)问题优化,解决预测过程中的计算瓶颈:由于预测过程是一个矩阵计算的过程,在主题词和描述词较多的情况下,计算复杂度急剧增加,为了提高预测效率,需要对预测过程中的计算进行优化,通过矩阵的奇异值分解以及矩阵的特征值、特征向量,矩阵的秩,降低矩阵运算维度;
5)数据过滤:由于在预测过程中,出现很多冗余的信息,需要对主题词数据和描述词数据进行过滤,通过描述词的词向量对描述词进行层次聚类,将词向量相似度高于或等于0.85的描述词视作一类描述词,在处理过程中不需要重复预测,同时过滤掉聚类后聚簇中只有一个的描述词;
6)描述词排序:选取预测结果中可能性最高的20个描述词,对20个描述词进行二次聚类,将词向量相似度高于或等于0.65的描述词视作一类描述词,构造训练集,利用支持向量机的方法对预测得到的每个描述词进行排序,每个类簇中所有描述词排序的平均值作为该类簇的排序,从而得到关于这个主题的描述词序列。
进一步地,步骤1)中所述的将主题描述词的预测问题转化为一个二部图预测问题,具体为:
主题词与描述词视作该二部图的两个互不相交的子集,两集合中顶点之间边的关系即为所需预测的主题词和描述词之间的关系,对主题词进行分词并训练得到词向量,利用向量空间的余弦相似度计算得到主题词之间边的权重,描述词与描述词在所有主题词中共同出现的次数作为描述词之间边的权重,主题词与描述词是否共同出现过作为主题词与描述词之间的相关度。预测问题转化为预测未知主题词和描述词之间的边权重关系,权重越大,说明该描述词隶属该主题词的可能性越高。
进一步地,所述步骤2)中的预测问题映射,具体为:
利用图的张量积将二部图的预测问题转化为顶点标签的传播问题,通过图(矩阵)的乘积运算,在本发明中采用的是张量积的方法,将主题词图G和描述词图H融合为一个图A,图中的每个顶点表示(主题词,描述词)的二元关系,预测问题映射为预测图中不相连顶点之间边的问题,若图G和图H通过张量积运算得到图A,则:
其中,表示向量的乘法,λ表示矩阵的特征值,μ,υ表示矩阵奇异分解后的奇异向量,i表示G的下标,j表示H的下标;即,若顶点(i,j)~(i’,j’),则在图G中,i~i’且在图H中,j~j’,其中符号~表示顶点之间存在边;
进一步地,所述步骤3)中的图的转导推理过程包括以下内容:
通过步骤2)已经得到了由主题词图G和描述词图H通过张量积得到的图A,通过基于图的转导推理即构造损失函数以及图的正则化方程,得到学习目标,利用给定的主题词和描述词构造的顶点信息进行预测,得到未知的主题词与描述词之间的关系矩阵f,根据问题,我们构造如下所示的学习目标:
其中,l(f)是损失函数,表示f与图A中实际存在的边之间的差值,用来衡量预测结果的好坏,λfTA-1f为学习函数的正则化项,用来衡量图的平滑度;
假设f遵从近似高斯分布,即f~N(0,A),那么学习目标得到增强,可以转化为:
以此可以合并归一化多种图的转导模式,如下所示:
k-step随机行走模式:κ(A)=Ak,
正则化的拉普拉斯算子:κ(A)=I+A+A2+A3+…,、
指数法:
进一步地,所述步骤4)中对预测过程计算的优化,具体为:
由步骤3)中的学习目标,可得其中G为一个m*m的矩阵,H为一个n*n的矩阵,由此可以得到κ(A)是一个mn*mn的矩阵,需要消耗O(m2n2)的时间和空间,难以在内存加载并且做矩阵的计算,因为需要做计算的简化。为了简化说明,令令Fij=score(i,j),即预测得到的顶点i和顶点j之间的边的概率值,则f=vec(F),则
F通过矩阵分解,可以得到秩更小的两个矩阵,与rank(F)·rank(Σ)成正比,其中Σ表示F的特征值矩阵,矩阵的每一个元素而在tensor张量积的转导模型中,可得到以下推导过程:
rank(Σ)=1,而通过以上步骤,预测过程计算得到优化。
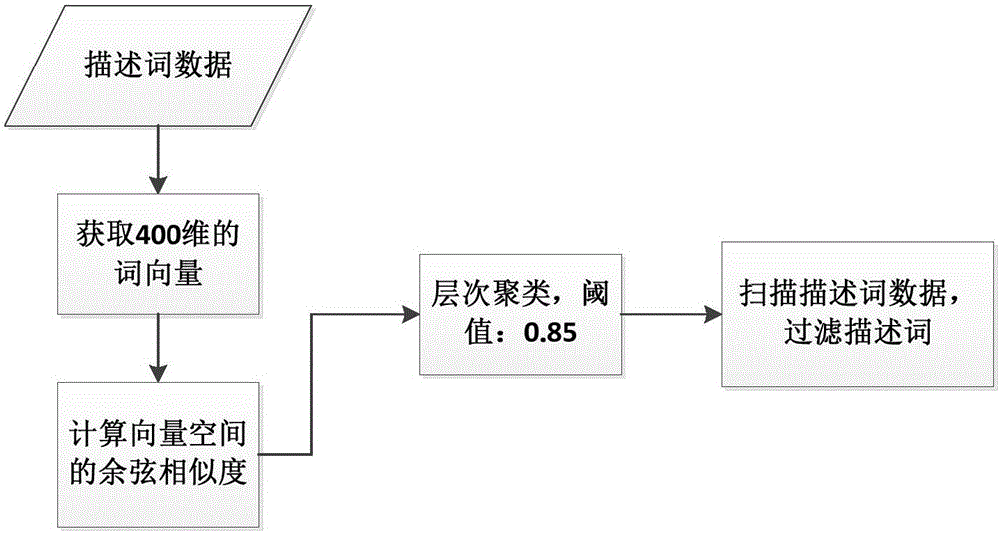
进一步地,所述步骤5)中对预测过程中的主题词和描述词的数据过滤,具体为:
由于在预测过程中,出现很多冗余的信息,需要对主题词数据和描述词数据进行过滤,有很多类似的描述词可能对预测过程造成影响,如:主要分类,种类,分类等。首先,需要获取每个描述词的400维的词向量,用词向量作为描述词的特征值进行计算,用向量空间的余弦相似度来代表两个词向量之间的相似度,通过计算向量空间中两个向量之间的余弦值作为衡量两个描述词之间差异的标准。公式如下所示:
通过描述词的词向量对描述词进行聚类,将词向量相似度高于或等于0.85的描述词视作一类描述词,过滤后,选择一个描述词作为该类簇的描述词代表,对所有的描述词进行过滤,用该类簇的描述词代表替换所有该类簇中的其他描述词,在处理过程中不需要重复预测,同时过滤掉聚类后聚簇中只有一个的描述词。通过数据的过滤,不仅过滤了冗余的描述词信息,而且简化了运算空间和存储空间。
进一步地,所述步骤6)预测得到的描述词进行排序,包括以下子步骤:
6.1)构造实验训练集:实验预测主要针对工程科教图书相关,为了使训练集覆盖范围更广,所以选取了工业、航空、化学、环境、机械、疾病、交通、农业、生物、天文共10个类的序列描述词构造训练集train.dat,训练得到描述词的400维词向量,向量中的每一列数组都是特征,用来提取描述词的原始特征,训练多个及分类器
6.2)通过训练集得到模型文件。
在训练集train.dat上训练一个排序的SVM,用正则化参数c,设置为20.0,训练学习到规则输出到model文件中。
6.3)将预测得到的得分最高的20个描述词进行二次聚类,聚类的阈值为0.65,聚类方法同步骤5)。
6.4)根据基于图方法得到预测的描述词,根据预测的分数,选择分数最高的20个描述词作为候选序列,对候选序列进行排序。类簇中所有描述词的平均得分作为该类簇的排序得分,从而得到最后的关于这个主题的描述词序列。
本发明方法与现有技术相比具有的有益效果:
1.本方法的流程保证可以依靠机器自动学习完成,无需人工干预,减轻用户负担;
2.本方法通过聚类进行数据过滤,减少信息冗余,为读者提供更加准确的主题词信息关键点;
3.本方法通过排序,优化描述词序列,得到层次关系更为清晰明确的描述词序列,符合人学习知识的曲线规律;
4.本方法通过通过矩阵分解及降维,通过计算特征值矩阵解决预测过程中的计算瓶颈问题,减少预测过程计算的时间复杂度和空间复杂度,提高了预测的效率;
5.本方法具有良好的可扩展性,丰富主题词及描述词关系图谱时,只需要将新的主题词提交,即可完成描述词的推荐。
附图说明
图1是本发明的总体流程图;
图2是步骤5)的流程图;
图3是步骤6)的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
如图1所示,本发明提供一种基于图的主题描述词的预测及排序方法,包括以下步骤:
1)主题描述词的预测问题转化:将主题描述词的预测问题转化为一个二部图的预测问题,主题词与描述词可视作该二部图的两个互不相交的子集,属于不同集合的顶点之间边的关系即为主题词和描述词之间的关系,预测主题词和描述词之间的属于关系即预测存在边的可能性得分;
2)预测问题映射:对步骤1)中得到的预测问题,利用图的张量积将二部图的预测问题转化为顶点标签的传播问题,通过图的乘积运算,在本发明中采用的是张量积的方法,将主题词图和描述词图融合为一个图,图中的每个顶点表示(主题词,描述词),预测问题映射为预测图中不相连顶点之间边的存在问题;
3)基于图的转导推理:构造损失函数以及图的正则化方程,得到学习目标,利用给定的主题词和描述词构造的顶点信息进行预测,得到未知的主题词与描述词之间的关系;
4)问题优化,解决预测过程中的计算瓶颈:由于预测过程是一个矩阵计算的过程,在主题词和描述词较多的情况下,计算复杂度急剧增加,为了提高预测效率,需要对预测过程中的计算进行优化,通过矩阵的奇异值分解以及矩阵的特征值、特征向量,矩阵的秩,降低矩阵运算维度;
5)数据过滤:由于在预测过程中,出现很多冗余的信息,需要对主题词数据和描述词数据进行过滤,通过描述词的词向量对描述词进行层次聚类,将词向量相似度高于或等于0.85的描述词视作一类描述词,在处理过程中不需要重复预测,同时过滤掉聚类后聚簇中只有一个的描述词;
6)构造训练集,选取预测结果中可能性最高的20个描述词,对20个描述词进行二次聚类,将词向量相似度高于或等于0.65的描述词视作一类描述词,构造训练集,利用支持向量机的方法对预测得到的每个描述词进行排序,每个类簇中所有描述词排序的平均值作为该类簇的排序,从而得到关于这个主题的描述词序列。
进一步地,步骤1)中所述的将主题描述词的预测问题转化为一个二部图预测问题,具体为:
主题词与描述词视作该二部图的两个互不相交的子集,两集合中顶点之间边的关系即为所需预测的主题词和描述词之间的关系,对主题词进行分词并训练得到词向量,利用向量空间的余弦相似度计算得到主题词之间边的权重,描述词与描述词在所有主题词中共同出现的次数作为描述词之间边的权重,主题词与描述词是否共同出现过作为主题词与描述词之间的相关度。预测问题转化为预测未知主题词和描述词之间的边权重关系,权重越大,说明该描述词隶属该主题词的可能性越高;
进一步地,所述步骤2)中的预测问题映射,具体为:
利用图的张量积将二部图的预测问题转化为顶点标签的传播问题,通过图(矩阵)的乘积运算,在本发明中采用的是张量积的方法,将主题词图G和描述词图H融合为一个图A,图中的每个顶点表示(主题词,描述词)的二元关系,预测问题映射为预测图中不相连顶点之间边的问题,张量积用符号。表示,若图G和图H通过张量积运算得到图A,则:
其中,表示向量的乘法,λ表示矩阵的特征值,μ,υ表示矩阵奇异分解后的奇异向量,i表示G的下标,j表示H的下标;即,若顶点(i,j)~(i’,j’),则在图G中,i~i’且在图H中,j~j’,其中符号~表示顶点之间存在边;
进一步地,所述步骤3)中的图的转导推理过程包括以下内容:
通过步骤2)已经得到了由主题词图G和描述词图H通过张量积得到的图A,通过基于图的转导推理即构造损失函数以及图的正则化方程,得到学习目标,利用给定的主题词和描述词构造的顶点信息进行预测,得到未知的主题词与描述词之间的关系矩阵f,根据问题,我们构造如下所示的学习目标:
其中,l(f)是损失函数,表示f与图A中实际存在的边之间的差值,用来衡量预测结果的好坏,λfTA-1f为学习函数的正则化项,用来衡量图的平滑度;
假设f遵从近似高斯分布,即f~N(0,A),那么学习目标得到增强,可以转化为:
以此可以合并归一化多种图的转导模式,如下所示:
k-step随机行走模式:κ(A)=Ak,
正则化的拉普拉斯算子:κ(A)=I+A+A2+A3+…,
指数法:
实验中,我们选用指数法作为增强学习目标;
进一步地,所述步骤4)中对预测过程计算的优化,具体为:
由步骤3)中的学习目标,可得其中G为一个m*m的矩阵,H为一个n*n的矩阵,由此可以得到κ(A)是一个mn*mn的矩阵,需要消耗O(m2n2)的时间和空间,难以在内存加载并且做矩阵的计算,因为需要做计算的简化。为了简化说明,令令Fij=score(i,j),即预测得到的顶点i和顶点j之间的边的概率值,则f=vec(F),则
F通过矩阵分解,可以得到秩更小的两个矩阵,与rank(F)·rank(Σ)成正比,其中Σ表示F的特征值矩阵,矩阵的每一个元素而在tensor张量积的转导模型中,可得到以下推导过程:
rank(Σ)=1,而通过以上步骤,预测过程计算得到优化。
进一步地,所述步骤5)中对预测过程中的主题词和描述词的数据过滤,具体为:
由于在预测过程中,出现很多冗余的信息,需要对主题词数据和描述词数据进行过滤,有很多类似的描述词可能对预测过程造成影响,如:主要分类,种类,分类等。首先,需要获取每个描述词的400维的词向量,用词向量作为描述词的特征值进行计算,用向量空间的余弦相似度来代表两个词向量之间的相似度,通过计算向量空间中两个向量之间的余弦值作为衡量两个描述词之间差异的标准。公式如下所示:
通过描述词的词向量对描述词进行聚类,将词向量相似度高于或等于0.85的描述词视作一类描述词,过滤后,选择一个描述词作为该类簇的描述词代表,对所有的描述词进行过滤,用该类簇的描述词代表替换所有该类簇中的其他描述词,在处理过程中不需要重复预测,同时过滤掉聚类后聚簇中只有一个的描述词。通过数据的过滤,不仅过滤了冗余的描述词信息,而且简化了运算空间和存储空间。
进一步地,所述步骤6)预测得到的描述词进行排序,包括以下子步骤:
6.1)构造实验训练集:实验预测主要针对工程科教图书相关,为了使训练集覆盖范围更广,所以选取了工业、航空、化学、环境、机械、疾病、交通、农业、生物、天文共10个类的序列描述词构造训练集train.dat,训练得到描述词的400维词向量,向量中的每一列数组都是特征,用来提取描述词的原始特征,训练多个及分类器
6.2)通过训练集得到模型文件。
在训练集train.dat上训练一个排序的SVM,用正则化参数c,设置为20.0,训练学习到规则输出到model文件中。
6.3)将预测得到的得分最高的20个描述词进行二次聚类,聚类的阈值为0.65,聚类方法同步骤5)。
6.4)根据基于图方法得到预测的描述词,根据预测的分数,选择分数最高的20个描述词作为候选序列,对候选序列进行排序。
类簇中所有描述词的平均得分作为该类簇的排序得分,从而得到最后的关于这个主题的描述词序列。
实施例
下面结合本发明的方法详细说明本实例实施的具体步骤,如下:
1)选取1852个主题词构造主题词集合,8059个描述词构造描述词集合,令G1=(V,E)是一个无向图,则顶点V可以分割为两个互不相交的子集U,子集V,则U={主题题词},V={描述词},并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in U,j in V),对主题词进行分词并训练得到词向量,利用向量空间的余弦相似度计算得到主题词之间的边,描述词与描述词在所有主题词中共同出现的次数作为描述词之间的边,主题词与描述词是否共同出现过作为主题词与描述词之间的相关度;
2)令主题词图为G,描述词图为H,对图G和图H进行张量积运算:
其中,表示向量的乘法,λ表示矩阵的特征值,μ,υ表示矩阵奇异分解后的奇异向量,i表示G的下标,j表示H的下标;即,若顶点(i,j)~(i’,j’),则在图G中,i~i’且在图H中,j~j’,其中符号~表示顶点之间存在边;将主题词图和描述词图融合成为一个图A,图A中的每个顶点表示(主题词,描述词);
3)通过基于图的转导推理即构造损失函数以及图的正则化方程,得到学习目标,利用给定的主题词和描述词构造的顶点信息进行预测,得到未知的主题词与描述词之间的关系矩阵f,根据问题,我们构造如下所示的学习目标:
其中,l(f)是损失函数,表示f与图A中实际存在的边之间的差值,用来衡量预测结果的好坏,λfTA-1f为学习函数的正则化项,用来衡量图的平滑度;
假设f遵从近似高斯分布,即f~N(0,A),那么学习目标得到增强,可以转化为:
其中,k(A)=I+A+A2+A3+…;
4)对预测过程进行计算的优化:令令Fij=score(i,j),即预测得到的顶点i和顶点j之间的边的概率值,则f=vec(F),则
F通过矩阵分解,可以得到秩更小的两个矩阵,与rank(F)·rank(Σ)成正比,其中Σ表示F的特征值矩阵,矩阵的每一个元素而在tensor张量积的转导模型中,可得到以下推导过程:
rank(Σ)=1,而通过以上步骤,预测过程计算得到优化。
5)对描述词进行过滤,需要获取8059个描述词的400维词向量,用向量空间的余弦相似度来代表两个词向量之间的相似度,通过计算向量空间中两个向量之间的余弦值作为衡量两个描述词之间差异的标准。公式如下所示:
利用描述词的词向量对描述词进行聚类,将词向量相似度高于或等于0.85的描述词视作一类描述词,过滤后,选择一个描述词作为该类簇的描述词代表,对所有的描述词进行过滤,用该类簇的描述词代表替换所有该类簇中的其他描述词,在处理过程中不需要重复预测,同时过滤到出现聚类后聚簇中只有一个的描述词。
6)构造SVMRank的训练集,选取了工业、航空、化学、环境、机械、疾病、交通、农业、生物、天文共10个类的序列描述词构造训练集train.dat,训练得到描述词的400维词向量,向量中的每一列数组都是特征,用来提取描述词的原始特征,每个主题词下的描述词的有序排列作为基准排序,训练多个及分类器;
输入命令行svm_rank_learn‐c 20.0train.dat model.dat得到模型文件model.dat;
训练集部分如下所示:
1qid:1 1:0.725156 2:‐0.724638 3:0.255276 4:0.376281……
2qid:1 1:‐1.8267235 2:‐0.3133405 3:0.85988899994:1.1430175……
3qid:1 1:‐1.633055999 2:‐1.1915725 3:1.663597 4:‐0.564981……
4qid:1 1:‐0.963502499 2:‐1.8096495 3:3.1417305 4:1.3620774999……
5qid:1 1:‐1.6615967 2:‐2.902158 3:1.05021799 4:‐1.476243667……
……
其中400维的向量,每一维都表示一个特征,只展示了前5个特征,qid:1表示一个主题词,1,2,3,4,5表示同属于一个主题的一个描述词序列;
7)添加主题词,对描述词序列进行排列,在实施例中,我们选取半导体、糖尿病作为例子,举例说明,进行预测,预测结果如下:
半导体预测结果:
简介 ‐3.69294317
概述 ‐3.0271586
应用 0.01187611
分类 ‐1.07289428
主要分类 ‐0.90506465
常见种类 ‐0.40280936
工作原理 ‐1.24462377
原理 ‐2.03831893
特点 ‐1.09241109
优点 ‐0.9833932
发展历史 ‐1.10074479
发展 ‐1.11814384
结构 ‐1.72550725
功能 ‐0.80802226
定义 ‐2.74409259
糖尿病预测结果:
治疗 1.41084313
治疗方案 0.83798371
临床表现 ‐0.60407576
症状体征 ‐0.93712148
病因 ‐1.92819514
发病原因 ‐0.66362221
检查 0.37666648
诊断 0.37607291
诊断标准 0.479819
预防 2.40052859
鉴别诊断 1.41187744
概述 ‐3.0271586
疾病概述 ‐1.8904456
简介 ‐3.69294317
预后 2.45333105
预后预防 2.42692976
发病机制 ‐0.38841091
病理生理 ‐0.74266451
病源分类 ‐0.59014071
流行病学 ‐0.63546551
技术 ‐0.14623241
类型 ‐0.98481372
注意事项 0.39251216
故障 1.38315693
方法 0.17992627
8)将预测得到的得分最高的20个描述词进行二次聚类,聚类的阈值为0.65;
9)对候选序列进行排序,在命令行输入命令:
svm_rank_classifytrain.dat modelpredictions
类簇中所有描述词的平均得分作为该类簇的排序得分,从而得到最后的关于这个主题的描述词序列,排序后序列如下:
半导体描述词排序结果:
Cluster 0 ‐3.360050885 简介 概述
Cluster 11 ‐2.74409259 定义
Cluster 8 ‐1.72550725 结构
Cluster 3 ‐1.64147135 工作原理 原理
Cluster 6 ‐1.109444315 发展历史 发展
Cluster 4 ‐1.037902145 特点 优点
Cluster 13 ‐0.98481372 类型
Cluster 9 ‐0.80802226 功能
Cluster 2 ‐0.79358943 分类 主要分类 常见种类
Cluster 12 ‐0.14623241 技术
Cluster 1 0.01187611 应用
Cluster 19 0.17992627 方法
Cluster 15 0.39251216 注意事项
Cluster 16 1.38315693 故障
糖尿病描述词排序结果:
Cluster 9 ‐3.69294317 简介
Cluster 8 ‐2.4588021 概述 疾病概述
Cluster 1 ‐1.033253647 临床表现 症状体征 病因 发病原因
Cluster 12 ‐0.74266451 病理生理
Cluster 15 ‐0.63546551 流行病学
Cluster 14 ‐0.59014071 病源分类
Cluster 11 ‐0.38841091 发病机制
Cluster 3 0.37666648 检查
Cluster 4 0.427945955 诊断 诊断标准
Cluster 0 1.12441342 治疗 治疗方案
Cluster 6 1.41187744 鉴别诊断
Cluster 5 2.40052859 预防
Cluster 10 2.440130405 预后 预后预防
因此,最后半导体的描述词序列为:
糖尿病的描述词序列为:
- 还没有人留言评论。精彩留言会获得点赞!