用于实现稀疏卷积神经网络加速器的装置和方法与流程
本发明涉及人工神经网络,更具体涉及用于实现稀疏卷积神经网络加速器的装置和方法。
背景技术:
人工神经网络(artificialneuralnetworks,ann)也简称为神经网络(nn),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。近年来神经网络发展很快,被广泛应用于很多领域,包括图像识别、语音识别,自然语言处理,天气预报,基因表达,内容推送等等。
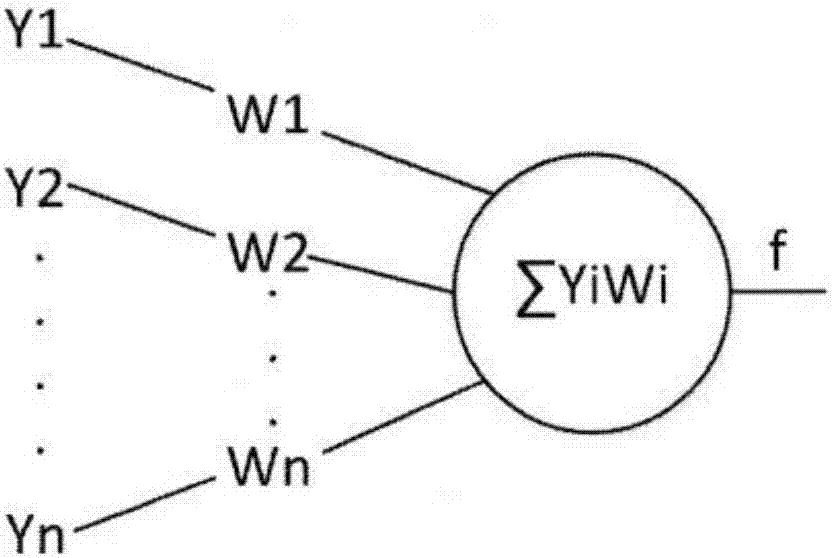
图1图示说明了人工神经网络中的一个神经元的计算原理图。
神经元的积累的刺激是由其他神经元传递过来的刺激量和对应的权重之和,用xj表示在第j个神经元的这种积累,yi表示第i个神经元传递过来的刺激量,wi表示链接第i个神经元刺激的权重,得到公式:
xj=(y1*w1)+(y2*w2)+...+(yi*wi)+...+(yn*wn)
而当xj完成积累后,完成积累的第j个神经元本身对周围的一些神经元传播刺激,将其表示为yj得到如下所示:
yj=f(xj)
第j个神经元根据积累后xj的结果进行处理后,对外传递刺激yj。用f函数映射来表示这种处理,将它称之为激活函数。
卷积神经网络(convolutionalneuralnetworks,cnn)是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。
图2示出了卷积神经网络的处理结构示意图。
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。卷积神经网络通常由卷积层(convolutionlayer)、下采样层(或称为池化层即poolinglayer)以及全连接层(fullconnectionlayer,fc)组成。
卷积层通过线性卷积核与非线性激活函数产生输入数据的特征图,卷积核重复与输入数据的不同区域进行内积,之后通过非线性函数输出,非线性函数通常为rectifier、sigmoid、tanh等。以rectifier为例,卷积层的计算可以表示为:
其中,(i,j)为特征图中的像素索引,xi,j表示输入域以(i,j)为中心,k表示特征图的通道索引。特征图计算过程中虽然卷积核与输入图像的不同区域进行内积,但卷积核不变。
池化层通常为平均池化或极大池化,该层只是计算或找出前一层特征图某一区域的平均值或最大值。
全连接层与传统神经网络相似,输入端的所有元素全都与输出的神经元连接,每个输出元素都是所有输入元素乘以各自权重后再求和得到。
在近几年里,神经网络的规模不断增长,公开的比较先进的神经网络都有数亿个链接,属于计算和访存密集型应用现有技术方案中通常是采用通用处理器(cpu)或者图形处理器(gpu)来实现,随着晶体管电路逐渐接近极限,摩尔定律也将会走到尽头。
在神经网络逐渐变大的情况下,模型压缩就变得极为重要。模型压缩可以将稠密神经网络变成稀疏神经网络,可以有效减少计算量、降低访存量。然而,cpu与gpu无法充分享受到稀疏化后带来的好处,取得的加速极其有限。而传统稀疏矩阵计算架构并不能够完全适应于神经网络的计算。已公开实验表明模型压缩率较低时现有处理器加速比有限。因此专有定制电路可以解决上述问题,可使得处理器在较低压缩率下获得更好的加速比。
就卷积神经网络而言,由于卷积层的卷积核能够共享参数,因此卷积层的参数量相对较少,而且卷积核往往较小(1*1、3*3、5*5等),因此对卷积层的稀疏化效果不明显。池化层的计算量也较少。但全连接层仍然有数量庞大的参数,如果对全连接层进行稀疏化处理将会极大减少计算量。
因此,希望提出一种针对稀疏cnn加速器的实现装置和方法,以达到提高计算性能、降低响应延时的目的。
技术实现要素:
基于以上的讨论,本发明提出了一种专用电路,支持fc层稀疏化cnn网络,采用ping-pang缓存并行化设计,有效平衡i/o带宽和计算效率。
现有技术方案中稠密cnn网络需要较大io带宽、较多存储和计算资源。为了适应算法需求,模型压缩技术变得越来越流行。模型压缩后的稀疏神经网络存储需要编码,计算需要解码。本发明采用定制电路,流水线设计,能够获得较好的性能功耗比。
本发明的目的在于提供一种稀疏cnn网络加速器的实现装置和方法,以便达到提高计算性能、降低响应延时的目的。
根据本发明的第一方面,提供一种用于实现稀疏卷积神经网络加速器的装置,包括:卷积与池化单元,用于根据卷积参数信息对输入数据进行第一迭代次数的卷积与池化操作,以最终得到稀疏神经网络的输入向量,其中,每个输入数据被分割为多个子块,由卷积与池化单元对多个子块并行进行卷积与池化操作;全连接单元,用于根据全连接层权值矩阵位置信息对输入向量进行第二迭代次数的全连接计算,以最终得到稀疏卷积神经网络的计算结果,其中,每个输入向量被分割为多个子块,由全连接单元对多个子块并行进行全连接操作;控制单元,用于确定并且向所述卷积与池化单元和所述全连接单元分别发送所述卷积参数信息和所述全连接层权值矩阵位置信息,并且对上述单元中的各个迭代层级的输入向量读取与状态机进行控制。
在根据本发明的用于实现稀疏卷积神经网络加速器的装置中,所述卷积与池化单元可以进一步包括:卷积单元,用于进行输入数据与卷积参数的乘法运算;累加树单元,用于累加卷积单元的输出结果,以完成卷积运算;非线性单元,用于对卷积运算结果进行非线性处理;池化单元,用于对非线性处理后的运算结果进行池化操作,以得到下一迭代级的输入数据或最终得到稀疏神经网络的输入向量。
优选地,所述累加树单元除了累加卷积单元的输出结果以外,还根据卷积参数信息而加上偏置。
在根据本发明的用于实现稀疏卷积神经网络加速器的装置中,所述全连接单元可以进一步包括:输入向量缓存单元,用于缓存稀疏神经网络的输入向量;指针信息缓存单元,用于根据全连接层权值矩阵位置信息,缓存压缩后的稀疏神经网络的指针信息;权重信息缓存单元,用于根据压缩后的稀疏神经网络的指针信息,缓存压缩后的稀疏神经网络的权重信息;算术逻辑单元,用于根据压缩后的稀疏神经网络的权重信息与输入向量进行乘累加计算;输出缓存单元,用于缓存算术逻辑单元的中间计算结果以及最终计算结果;激活函数单元,用于对输出缓存单元中的最终计算结果进行激活函数运算,以得到稀疏卷积神经网络的计算结果。
优选地,所述压缩后的稀疏神经网络的权重信息可以包括位置索引值和权重值。所述算术逻辑单元可以被进一步配置为:将权重值与输入向量的对应元素进行乘法运算;根据位置索引值,读取所述输出缓存单元中相应位置的数据,与上述乘法运算的结果相加;根据位置索引值,将相加结果写入到输出缓存单元中相应位置。
根据本发明的第二方面,提供一种用于实现稀疏卷积神经网络加速器的方法,包括:依据控制信息而读取卷积参数信息与输入数据与中间计算数据,并且读取全连接层权值矩阵位置信息;根据卷积参数信息对输入数据进行第一迭代次数的卷积与池化操作,以最终得到稀疏神经网络的输入向量,其中,每个输入数据被分割为多个子块,对多个子块并行进行卷积与池化操作;根据全连接层权值矩阵位置信息对输入向量进行第二迭代次数的全连接计算,以最终得到稀疏卷积神经网络的计算结果,其中,每个输入向量被分割为多个子块,并行进行全连接操作。
在根据本发明的用于实现稀疏卷积神经网络加速器的方法中,所述的根据卷积参数信息对输入数据进行第一迭代次数的卷积与池化操作,以最终得到稀疏神经网络的输入向量的步骤可以进一步包括:进行输入数据与卷积参数的乘法运算;累加乘法运算的输出结果,以完成卷积运算;对卷积运算结果进行非线性处理;对非线性处理后的运算结果进行池化操作,以得到下一迭代级的输入数据或最终得到稀疏神经网络的输入向量。
优选地,所述的累加乘法运算的输出结果,以完成卷积运算的步骤可以进一步包括:根据卷积参数信息而加上偏置。
在根据本发明的用于实现稀疏卷积神经网络加速器的方法中,所述的根据全连接层权值矩阵位置信息对输入向量进行第二迭代次数的全连接计算,以最终得到稀疏卷积神经网络的计算结果的步骤可以进一步包括:缓存稀疏神经网络的输入向量;根据全连接层权值矩阵位置信息,缓存压缩后的稀疏神经网络的指针信息;根据压缩后的稀疏神经网络的指针信息,缓存压缩后的稀疏神经网络的权重信息;根据压缩后的稀疏神经网络的权重信息与输入向量进行乘累加计算;缓存乘累加计算的中间计算结果以及最终计算结果;对乘累加计算的最终计算结果进行激活函数运算,以得到稀疏卷积神经网络的计算结果。
优选地,所述压缩后的稀疏神经网络的权重信息可以包括位置索引值和权重值。所述的根据压缩后的稀疏神经网络的权重信息与输入向量进行乘累加计算的步骤可以进一步包括:将权重值与输入向量的对应元素进行乘法运算;根据位置索引值,读取所缓存的中间计算结果中相应位置的数据,与上述乘法运算的结果相加;根据位置索引值,将相加结果写入到所缓存的中间计算结果中相应位置。
本发明的目的是采用高并发设计,高效处理稀疏神经网络,从而获得更好的计算效率,更低的处理延时。
附图说明
下面参考附图结合实施例说明本发明。在附图中:
图1图示说明了人工神经网络中的一个神经元的计算原理图。
图2示出了卷积神经网络的处理结构示意图。
图3是根据本发明的用于实现稀疏卷积神经网络加速器的装置的示意图。
图4是根据本发明的卷积与池化单元的具体结构示意图。
图5是根据本发明的全连接单元的具体结构示意图。
图6是根据本发明的用于实现稀疏卷积神经网络加速器的方法的流程图。
图7是根据本发明的具体实现例1的计算层结构的示意图。
图8是根据本发明的具体实现例2图示说明稀疏矩阵与向量的乘法操作的示意图。
图9是根据本发明的具体实现例2图示说明pe0对应的权重信息的示意表格。
具体实施方式
下面将结合附图来详细解释本发明的具体实施例。
图3是根据本发明的用于实现稀疏卷积神经网络加速器的装置的示意图。
本发明提供了一种用于实现稀疏卷积神经网络加速器的装置。如图3所示,该装置主要包含三大模块:卷积与池化单元、全连接单元、控制单元。具体地说,卷积与池化单元,也可称为convolution+pooling模块,用于根据卷积参数信息对输入数据进行第一迭代次数的卷积与池化操作,以最终得到稀疏神经网络的输入向量,其中,每个输入数据被分割为多个子块,由卷积与池化单元对多个子块并行进行卷积与池化操作。全连接单元,也可称为fullconnection模块,用于根据全连接层权值矩阵位置信息对输入向量进行第二迭代次数的全连接计算,以最终得到稀疏卷积神经网络的计算结果,其中,每个输入向量被分割为多个子块,由全连接单元对多个子块并行进行全连接操作。控制单元,也可称为controller模块,用于确定并且向所述卷积与池化单元和所述全连接单元分别发送所述卷积参数信息和所述全连接层权值矩阵位置信息,并且对上述单元中的各个迭代层级的输入向量读取与状态机进行控制。
下文中将结合附图4、5,针对各个单元进行进一步的详细描述。
图4是根据本发明的卷积与池化单元的具体结构示意图。
本发明的卷积与池化单元用于cnn中实现卷积层与池化层的计算,该单元可以例化多个实现并行计算,也就是说,每个输入数据被分割为多个子块,由卷积与池化单元对多个子块并行进行卷积与池化操作。
应该注意到,卷积与池化单元对输入数据不仅进行分块化并行处理,而且对输入数据进行若干层级的迭代处理。至于具体的迭代层级数目,本领域技术人员可根据具体应用而指定不同的数目。例如,针对不同类型的处理对象,诸如视频或语音,迭代层级的数目可能需要不同的指定。
如图4中所示,该单元包含但不仅限于如下几个单元(又称为模块):
卷积单元,也可称为convolver模块:实现输入数据与卷积核参数的乘法运算。
累加树单元,也可称为addertree模块:累加卷积单元的输出结果,完成卷积运算,有偏置输入的情况下还加上偏置。
非线性单元,也可称为nonlinear模块:实现非线性激活函数,根据需要可以为rectifier、sigmoid、tanh等函数。
池化单元,也可称为pooling模块,用于对非线性处理后的运算结果进行池化操作,以得到下一迭代级的输入数据或最终得到稀疏神经网络的输入向量。这里的池化操作,根据需要可以为最大池化或平均池化。
图5是根据本发明的全连接单元的具体结构示意图。
本发明的全连接单元用于实现稀疏化全连接层的计算。与卷积与池化单元相类似,应该注意到,全连接单元对输入向量不仅进行分块化并行处理,而且对输入向量进行若干层级的迭代处理。至于具体的迭代层级数目,本领域技术人员可根据具体应用而指定不同的数目。例如,针对不同类型的处理对象,诸如视频或语音,迭代层级的数目可能需要不同的指定。此外,全连接单元的迭代层级的数目可以与卷积与池化层的迭代层级的数目相同或不同,这完全取决于具体的应用与本领域技术人员对计算结果的不同控制需求。
如图5所示,该单元包含但不仅限于如下几个单元(又称为子模块):
输入向量缓存单元,也可称为actqueue模块:用于存储稀疏神经网络的输入向量。多计算单元(pe,processelement)可共享输入向量。该模块包含先进先出缓存(fifo),每个计算单元pe对应一个fifo,相同输入元素下能有效平衡多个计算单元间计算量的差异。fifo深度的设置可以取经验值,过深会浪费资源,过小又不能有效平衡不同pe间的计算差异。
指针信息缓存单元,也可称为ptrread模块:用于根据全连接层权值矩阵位置信息,缓存压缩后的稀疏神经网络的指针信息。如稀疏矩阵采用列存储(ccs)的存储格式,ptrread模块存储列指针向量,向量中的pj+1-pj值表示第j列中非零元素的个数。设计中有两个缓存,采用ping-pang设计。
权重信息缓存单元,也可称为spmatread模块:用于根据压缩后的稀疏神经网络的指针信息,缓存压缩后的稀疏神经网络的权重信息。这里所述的权重信息包括位置索引值和权重值等。通过ptrread模块输出的pj+1和pj值可获得该模块对应的权重值。该模块缓存也是采用ping-pang设计。
算术逻辑单元,即alu模块:用于根据压缩后的稀疏神经网络的权重信息与输入向量进行乘累加计算。具体地说,根据spmatread模块送来的位置索引以及权重值,主要做三步计算:第一步,读取神经元的输入向量和权重进行对应乘法计算;第二步,根据索引值读取下一单元(actbuffer模块,或输出缓存单元)中对应位置历史累加结果,再与第一步结果进行加法运算;第三步,根据位置索引值,将相加结果再写入到输出缓存单元中相应位置。为了提高并发度,本模块采用多个乘法和加法树来完成一列中的非零元素的乘累加运算。
输出缓存单元,也称为actbuffer模块:用于缓存算术逻辑单元的矩阵运算的中间计算结果以及最终计算结果。为提高下一级的计算效率,存储也采用ping-pang设计,流水线操作。
激活函数单元,也称为function模块:用于对输出缓存单元中的最终计算结果进行激活函数运算。常见的激活函数诸如sigmoid/tanh/rectifier等。当加法树模块完成了各组权重与向量的叠加运算后,经该函数后可获得稀疏卷积神经网络的计算结果。
本发明的控制单元负责全局控制,卷积与池化层的数据输入选择额,卷积参数与输入数据的读取,全连接层中稀疏矩阵与输入向量的读取,计算过程中的状态机控制等。
根据以上参考描述,并参考图3至图5的图示说明,本发明还提供一种用于实现稀疏cnn网络加速器的方法,具体步骤包括:
步骤1:初始化依据全局控制信息读取cnn卷积层的参数与输入数据,读取全连接层权值矩阵的位置信息。
步骤2:convolver模块进行输入数据与参数的乘法操作,多个convolver模块轲同时计算实现并行化。
步骤3:addertree模块将前一步骤的结果相加并在有偏置(bias)的情况下与偏置求和。
步骤4:nonlinear模块对前一步结果进行非线性处理。
步骤5;pooling模块对前一步结果进行池化处理。
其中步骤2、3、4、5流水进行以提高效率。
步骤6:根据卷积层的迭代层级数目重复进行步骤2、3、4、5。在此期间,controller模块控制将上一次卷积和池化的结果连接至卷积层的输入端,直到所有层都计算完成。
步骤7:根据步骤1的权值矩阵位置信息读取稀疏神经网络的位置索引、权重值。
步骤8:根据全局控制信息,把输入向量广播给多个计算单元pe。
步骤9:计算单元把spmatread模块送来的权重值跟actqueue模块送来的输入向量对应元素做乘法计算。
步骤10,计算模块根据步骤7的位置索引值读取输出缓存actbuffer模块中相应位置的数据,然后跟步骤9的乘法结果做加法计算。
步骤11:根据步骤7的索引值把步骤10的加法结果写入输出缓存actbuffer模块中。
步骤12:控制模块读取步骤11中输出的结果经激活函数模块后得到cnnfc层的计算结果。
步骤7-12也可以根据指定的迭代层级数目而重复进行,从而得到最终的稀疏cnn的计算结果。
可以将上述的步骤1-12概括为一个方法流程图。
图6是根据本发明的用于实现稀疏卷积神经网络加速器的方法的流程图。
图6所示的方法流程图s600开始于步骤s601。在此步骤,依据控制信息而读取卷积参数信息与输入数据与中间计算数据,并且读取全连接层权值矩阵位置信息。这一步骤对应于根据本发明的装置中的控制单元的操作。
接下来,在步骤s603,根据卷积参数信息对输入数据进行第一迭代次数的卷积与池化操作,以最终得到稀疏神经网络的输入向量,其中,每个输入数据被分割为多个子块,对多个子块并行进行卷积与池化操作。这一步骤对应于根据本发明的装置中的卷积与池化单元的操作。
更具体地说,步骤s603的操作进一步包括:
1、进行输入数据与卷积参数的乘法运算,对应于卷积单元的操作;
2、累加乘法运算的输出结果,以完成卷积运算,对应于累加树单元的操作;这里,如果卷积参数信息指出偏置的存在,再还需要加上偏置;
3、对卷积运算结果进行非线性处理,对应于非线性单元的操作;
4、对非线性处理后的运算结果进行池化操作,以得下一迭代级的输入数据或最终得到稀疏神经网络的输入向量,对应于池化单元的操作。
接下来,在步骤s605,根据全连接层权值矩阵位置信息对输入向量进行第二迭代次数的全连接计算,以最终得到稀疏卷积神经网络的计算结果,其中,每个输入向量被分割为多个子块,并行进行全连接操作。这一步骤对应于根据本发明的装置中的全连接单元的操作。
更具体地说,步骤s605的操作进一步包括:
1、缓存稀疏神经网络的输入向量,对应于输入向量缓存单元的操作;
2、根据全连接层权值矩阵位置信息,缓存压缩后的稀疏神经网络的指针信息,对应于指针信息缓存单元的操作;
3、根据压缩后的稀疏神经网络的指针信息,缓存压缩后的稀疏神经网络的权重信息,对应于权重信息缓存单元的操作;
4、根据压缩后的稀疏神经网络的权重信息与输入向量进行乘累加计算,对应于算术逻辑单元的操作;
5、缓存乘累加计算的中间计算结果以及最终计算结果,对应于输出缓存单元的操作;
6、对乘累加计算的最终计算结果进行激活函数运算,以得到稀疏卷积神经网络的计算结果,对应于激活函数单元的操作。
在步骤s605中,所述压缩后的稀疏神经网络的权重信息包括位置索引值和权重值。因此,其中的子步骤4进一步包括:
4.1、将权重值与输入向量的对应元素进行乘法运算,
4.2、根据位置索引值,读取所缓存的中间计算结果中相应位置的数据,与上述乘法运算的结果相加,
4.3、根据位置索引值,将相加结果写入到所缓存的中间计算结果中相应位置。
在执行完步骤s605之后,就得到了稀疏卷积神经网络的计算结果。由此,方法流程图s600结束。
非专利文献songhanetal.,eie:efficientinferenceengineoncompresseddeepneuralnetwork,isca2016:243-254中提出了一种加速器硬件实现eie,旨在利用cnn的信息冗余度比较高的特点,使得压缩后得到的神经网络参数可以完全分配到sram上,从而极大地减少了dram的访问次数,由此可以取得很好的性能和性能功耗比。与没有压缩的神经网络加速器dadiannao相比,eie的吞吐率提高了2.9倍,性能能耗比提高了19倍,而面积只有dadiannao的1/3。在此,将该非专利文献的内容通过援引全部加入到本申请的说明书中。
本发明提议的稀疏cnn加速器的实现装置和方法与eie论文的区别在于:eie设计中有一个计算单元,一个周期仅能实现一个乘加计算,而一个计算核前后模块却需要较多的存储和逻辑单元。无论是专用集成电路(asic)还是可编程芯片都会带来资源的相对不均衡。实现过程中并发度越高,需要的片上存储以及逻辑资源相对越多,芯片中需要的计算资源dsp与上述两者越不均衡。本发明计算单元采用高并发设计,在增加了dsp资源的同时,没有使得其他的逻辑电路相应的增加,达到了平衡计算、片上存储、逻辑资源之间的关系等目的。
下面结合图7至图9来看本发明的两个具体实现例。
具体实现例1:
图7是根据本发明的具体实现例1的计算层结构的示意图。
如图7所示,以alexnet为例,该网络除输入输出外,包含八层,五个卷积层与三个全连接层。第一层为卷积+池化,第二层为卷积+池化,第三层为卷积,第四层为卷积,第五层为卷积+池化,第六层为全连接,第七层为全连接,第八层为全连接。
该cnn结构可用本发明的专用电路实现,第1-5层由convolution+pooling模块(卷积与池化单元)按顺序分时实现,由controller模块(控制单元)控制convolution+pooling模块的数据输入,参数配置以及内部电路连接,例如当不需要池化时,可由controller模块控制数据流直接跳过pooling模块。该网络的第6-8层由本发明的fullconnection模块按顺序分时实现,由controller模块控制fullconnection模块的数据输入、参数配置以及内部电路连接等。
具体实现例2:
图8是根据本发明的具体实现例2图示说明稀疏矩阵与向量的乘法操作的示意图。
对于fc层的稀疏矩阵与向量的乘法操作,以4个计算单元(processelement,pe)计算一个矩阵向量乘,采用列存储(ccs)为例进行详细说明。
如图8所示,第1、5行元素由pe0完成,第2、6行元素由pe1完成,第3、7行元素由pe2完成,第4、8行元素由pe3完成,计算结果分别对应输出向量的第1、5个元素,第2、6个元素,第3、7个元素,第4、8个元素。输入向量会广播给4个计算单元。
图9是根据本发明的具体实现例2图示说明pe0对应的权重信息的示意表格。
如图9所示,该表格示出了pe0对应的权重信息。
以下介绍在pe0的各个模块中的作用。
ptrread模块0(指针):存储1、5行非零元素的列位置信息,其中p(j+1)-p(j)为第j列中非零元素的个数。
spmatread模块0:存储1、5行非零元素的权重值和相对行索引。
actqueue模块:存储输入向量x,该模块把输入向量广播给4个计算单元pe0、pe1、pe2、pe3,为了平衡计算单元间元素稀疏度的差异,每个计算单元的入口都添加先进先出缓存(fifo)来提高计算效率。
controller模块:控制系统状态机的跳转,实现计算控制,使得各模块间信号同步,从而实现权值与对应输入向量的元素做乘,对应行值做累加。
alu模块:完成权值矩阵奇数行元素与输入向量x对应元素的乘累加。
actbuffer模块:存放中间计算结果以及最终y的第1、5个元素。
与上类似,另一个计算单元pe1,计算y的2、6个元素,其他pe以此类推。
上面已经描述了本发明的各种实施例和实施情形。但是,本发明的精神和范围不限于此。本领域技术人员将能够根据本发明的教导而做出更多的应用,而这些应用都在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!