基于兴趣行为的分布式虚拟环境缓存管理方法与流程
本发明涉及分布式虚拟环境资源管理领域,尤其是涉及一种基于兴趣行为的分布式虚拟环境缓存管理方法。
背景技术:
随着人们对人机交互沉浸度需求的增加,3D虚拟技术已经广泛地应用到了多数场景的构建中,如虚拟城市、工业仿真、网络游戏等等。由于当前有限网络带宽仍不能满足海量3D数据的多用户实时性传输,人们将P2P技术引入到虚拟场景的传输机制中,以充分利用各个用户节点的传输能力来提高系统的传输效率。
在基于P2P的海量虚拟场景传输策略中,缓存数据更新机制是其中的重要一环。用户在分布式虚拟环境中的行为模式有其独有的特征,由于用户化身在虚拟场景中的漫游方向具有较强随机性,节点的数据加载是非线性的,所以节点邻居关系极为不稳定,这跟网络流媒体的用户行为特征有着明显差异。并且每个节点的缓存空间是有限的,特别是在Web和移动端,缓存中的数据不但要保证节点自身的模型渲染需求还要兼顾其他节点的数据请求,为了最大化地利用有限的缓存资源,需要对系统中的节点缓存进行统一的管理,一个高效的缓存管理机制,将能显著提高资源查找效率和系统服务能力。
目前针对基于P2P网络的分布式虚拟环境的缓存管理策略,较为通用的做法是仿照网络流媒体中的缓存更新方法,如最久未使用算法(LRU)、最少频繁使用算法(LFU)、最多可用丢弃算法等,虽然上述方法能对节点缓存空间进行简单管理,但有着以下不足:
1)数据共享程度低:通用的缓存更新算法并未充分考虑分布式虚拟环境中的场景分布特征和用户行为特征,没有从整体的角度来分析数据更新趋势,造成数据请求成功率差,数据共享程度低。
2)邻居表抖动剧烈:虚拟场景中的化身漫游路径具有很强的随机性,数据的加载呈非线性化,现有的缓存管理算法将会造成节点邻居表的频繁更新,信息交互频繁,数据传输实时性低等问题。
3)节点资源利用率低:对等网络的节点异构性较强,节点的带宽性能和缓存容量有较大差异,当前的缓存管理算法并未充分考虑这些性能指标,没有充分的利用各个节点的资源。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种场景数据共享度高、邻居结构稳定、节点资源利用率高的基于兴趣行为的分布式虚拟环境缓存管理方法。
本发明的目的可以通过以下技术方案来实现:
一种基于兴趣行为的分布式虚拟环境缓存管理方法,包括以下步骤:
根据节点在虚拟场景中的行为轨迹构建兴趣簇,一个节点至少属于一个兴趣簇,所述兴趣簇中各节点同时作为供应节点和固有节点,各节点具有一缓存空间,兴趣簇在漫游过程中所拾取的单元格构成的区域定义为兴趣域;
将节点的缓存空间中的数据划分为五种状态,包括当前视域缓存状态、预下载缓存状态、定位数据缓存状态、副本数据缓存状态和保留数据缓存状态;
根据节点的场景拾取速度、场景数据量构建节点在所述兴趣簇中的直接前驱节点集;
节点请求数据时,首先从所述直接前驱节点集中供应节点请求处于任一缓存状态的数据,在所述直接前驱节点集无法满足数据要求时,通过资源定位文件获得资源对应的固有节点,从所述固有节点请求获取处于定位数据缓存状态的数据,所述资源定位文件周期性传递式更新。
构建所述兴趣簇时,抽取化身的行为轨迹进行聚类分析,动态地将兴趣相似度大于设定阈值的节点加入同一兴趣簇。
所述缓存空间中处于不同状态的数据具有不同的缓存优先级,当缓存空间不足时,缓存优先级小的数据优先剔除,所述缓存优先级的次序为CSCprior>PSCprior>LSCprior>DSCprior>RSCprior,其中,CSCprior、PSCprior、LSCprior、DSCprior、RSCprior依次表示当前视域缓存状态、预下载缓存状态、定位数据缓存状态、副本数据缓存状态和保留数据缓存状态的缓存优先级。
所述直接前驱节点集中的节点Peerj满足以下双目标函数:
min pr
且所述双目标函数满足约束条件:
式中,pr表示直接前驱节点集中节点个数,dist(Node,Peerpk)表示节点Node和直接前驱节点集中节点Peerpk的欧氏距离,RBW(Peerpk)表示节点Peerpk扣除已有的后继节点占有服务带宽的剩余带宽,UBW表示每个节点应维护的前驱供应节点的域基本上载带宽,且满足:
UBW≥u×ADVol×ALSpeed
其中,u表示节点每移动一个单元格需要加载的新单元格的数量,ADVol表示当前兴趣域内单元格的平均场景数据,ALSpeed表示当前兴趣域内单元格的平均拾取速度。
所述平均拾取速度根据以下公式获得:
式中,m表示当前兴趣域包含的单元格的数量,LSpeed(Celli)表示单元格Celli的拾取速度,Lcell表示单元格边长,S表示以Celli为中心、以r为半径的单元格集合。
所述兴趣簇满足或趋近如下目标:
a)兴趣簇的各节点中处于定位数据缓存状态的数据包含对应兴趣域中所有单元格,即:
式中,n表示兴趣簇中节点个数,表示存在于第p个节点中处于定位数据缓存状态的单元格,p表示节点序号,RCell表示兴趣域所包含的所有单元格;
b)资源定位文件维护有每个定位数据缓存状态数据对应的固有节点,且每个定位数据缓存状态数据拥有稳定的上载供应能力。
所述每个定位数据缓存状态数据拥有稳定的上载供应能力具体为:
针对定位数据缓存状态的单元格Cellj,存储该Cellj的节点node满足以下条件
式中,NBW、NCache分别表示节点node的可用上载带宽和缓存空间,DVol(Cellj)表示单元格数据量,LSpeed(Cellj)表示单元格拾取速度,Cache(Cellj)表示单元格所需缓存空间,表示节点node中处于当前视域缓存状态和预下载缓存状态的数据占用的缓存空间之和。
所述资源定位文件由超级节点进行周期性传递式更新,具体为:
获取兴趣簇中缓存有处于定位数据缓存状态的Cellj的至少一个节点,若所述至少一个节点中的一个节点ni满足
NLSCi=α1×NDisti+β1×NCratei
则指定节点ni作为Cellj的存储节点,更新资源定位文件,将其它节点中缓存的Cellj转化为副本数据缓存状态,其中,NDisti表示节点的视点圆心与Cellj的空间距离归一化量,NCratei表示Cellj在节点缓存空间中所占的比例作为缓存比重指标,α1、β1表示权重,且α1+β1=1,n表示兴趣簇中缓存有处于定位数据缓存状态的Cellj的节点集合;
在某一节点缓存空间不足时,根据该节点中所有处于定位数据缓存状态的单元格的删除优先级进行单元格剔除,更新资源定位文件。
所述根据该节点中所有处于定位数据缓存状态的单元格的删除优先级进行单元格剔除具体为:
计算节点中新转化的定位数据缓存状态单元格和已有的定位数据缓存状态单元格的删除优先级:
CPriori=α2×VRatei+β2×RDegi
式中,CPriori表示单元格Celli的优先级,VRatei表示单元格请求率,RDegi表示单元格重用度,α2、β2表示权重,α2+β2=1;
依次剔除优先级低的单元格,即
式中,NCellLsC表示节点中所有处于定位数据缓存状态的单元格的集合。
在进行处于定位数据缓存状态的单元格剔除时,若在兴趣簇中存在与待剔除单元格相应的处于副本数据缓存状态的数据,则直接剔除所述待剔除单元格,并选择另一存储有所述处于副本数据缓存状态的数据的节点,将所述处于副本数据缓存状态的数据转化为定位数据缓存状态。
与现有技术相比,本发明具有以下有益效果:
(1)本发明从场景分布特征和用户行为特征的角度出发,来研究基于对等网络的分布式虚拟环境的缓存更新问题,能有效的解决当前流行的大规模分布式虚拟环境的传输问题。
(2)本发明量化了上载场景数据单元应具有的供应能力,基于节点的场景拾取速度和场景数据量构建了节点直接前驱邻居集和稳定的Mesh Network,减少了资源查找时间和频繁的数据交互次数。
(3)本发明量化了单元格请求率和模型重用度,基于兴趣节点簇采用了传递式更新策略,构建了场景数据资源定位文件,充分利用了节点的异构性,提高了资源利用率,也解决了由于场景分布不均匀带来的服务器请求率高的问题。
(4)本发明中首先向前驱结点请求,在不能满足数据加载的情况下,则向固有节点请求,且对定位数据缓存的请求具有最高上载优先级,既保证了场景数据的快速查找和数据的稳定传输,又充分利用了各节点的网络资源,避免单个节点的过载。
(5)本发明中,各个节点定位数据缓存状态的数据必须能包含兴趣域中所有单元格,保证被请求过的每个单元格在节点中至少存在一个副本(replication),以减少对超级节点的数据请求。
(6)本发明中,兴趣域中的相邻单元格按照一定的离散序列或者随机分布分散至各个节点中,这样在节点场景拾取的过程中可以并发的从多个供应节点请求数据,以充分利用各个供应节点可能产生的闲时上载带宽,防止出现单个节点满负载而其他节点闲置的现象。
附图说明
图1为本发明的原理示意图;
图2为本发明的五种数据缓存状态示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
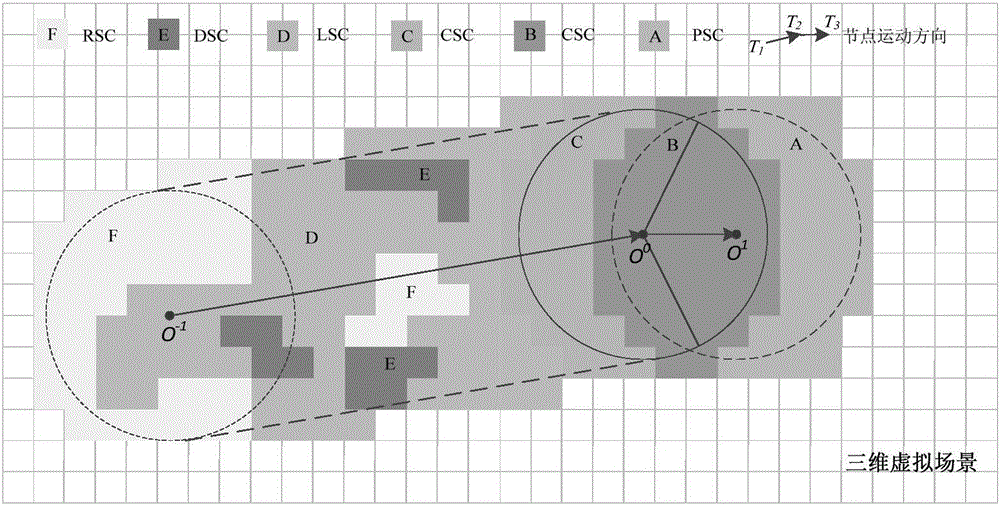
网络中所构建的虚拟世界都是现实世界的模拟和仿真,具有十分明显的设计特征和用户行为特征,例如,虚拟旅游景区具有较为固定的旅游线路,网络游戏具有较为明细的游戏逻辑和行走路线,虚拟场景有热点和非热点区域等等,现在诸多的虚拟场景特征分析和用户行为分析的研究工作也充分证明了这一点。本发明根据分布式虚拟环境独有的特征,构建了基于兴趣行为的传递式缓存更新方法,其主要思想是根据节点的兴趣行为、场景拾取速度、场景数据量构建了节点的直接前驱节点集,以提高节点邻居结构的稳定性和数据传输实时性,然后基于兴趣节点簇提出了节点缓存数据初始化和传递式更新策略。
如图1所示,本发明的技术路线为:首先从数据角度,定义了缓存数据的五种状态,并基于兴趣簇定义了兴趣域的概念,其次对单元格拾取速度和模型数据量进行量化,基于兴趣簇给出了构建稳定直接前驱节点集的算法,然后给出了定位数据缓存状态转化的基本条件和传递式更新算法,基于单元格请求率和数据重用度提出了定位数据缓存状态的数据剔除策略,构建了兴趣簇的定位数据缓存状态结构化存储结构。
本发明基于兴趣行为的分布式虚拟环境缓存管理方法,包括以下步骤:
根据节点在虚拟场景中的行为轨迹构建兴趣簇,一个节点至少属于一个兴趣簇,所述兴趣簇中各节点同时作为供应节点和固有节点,各节点具有一缓存空间,兴趣簇在漫游过程中所拾取的单元格构成的区域定义为兴趣域;
将节点的缓存空间中的数据划分为五种状态,包括当前视域缓存状态、预下载缓存状态、定位数据缓存状态、副本数据缓存状态和保留数据缓存状态;
根据节点的场景拾取速度、场景数据量构建节点在所述兴趣簇中的直接前驱节点集;
节点请求数据时,首先从所述直接前驱节点集中供应节点请求处于任一缓存状态的数据,在所述直接前驱节点集无法满足数据要求时,通过资源定位文件获得资源对应的固有节点,从所述固有节点请求获取处于定位数据缓存状态的数据,所述资源定位文件周期性传递式更新。
1)构建兴趣簇及缓存空间的划分
1.1兴趣簇的构建
根据化身兴趣行为来构建兴趣节点簇,在传输初始阶段,根据场景特征设置一系列查询点,抽取节点化身的行为轨迹,并和查询点集进行聚类分析,将兴趣相似度大于设定阈值的节点化为同一兴趣簇,一个节点可能属于多个兴趣簇。
兴趣簇是大致按照节点的漫游轨迹进行划分的,节点在其中的漫游通常具有一定的方向性和前后顺序,那么节点加载场景数据的过程将呈线性化。本发明按照节点化身在虚拟场景中的空间分布,构建一个逻辑mesh network,根据兴趣簇中节点的整体移动方向和节点的空间分布,将节点分为前驱结点和后继结点,由于在虚拟场景中的物理距离较近,前驱结点可以为后继结点提供场景数据。
1.2缓存状态的划分
将节点缓存空间中的数据分为五种状态:
(1)当前视域缓存状态(Current scenes cache,CSC),表示当前AOI内的场景缓存数据。
(2)预下载缓存状态(Prefetching scenes cache,PSC),表示节点将要访问区域的预下载场景缓存数据。
(3)定位数据缓存状态(Location scenes cache,LSC),表示簇超级节点根据节点的计算能力所指定的场景缓存数据和节点自身的偏好缓存数据;此状态的数据被用于构建资源定位文件,并为请求节点提供稳定供应服务。
(4)副本数据缓存状态(Duplicate scenes cache,DSC),表示兴趣簇中某些LSC状态数据的副本数据,DSC状态的数据皆由LSC状态转化而来,在节点计算资源空闲的情况下,可以充当LSC状态数据的角色。
(5)保留数据缓存状态(Reserved scenes cache,RSC),表示节点访问过的且能缓存在本地但处于LSC和DSC状态之外的场景缓存数据。此状态的数据为已缓存在节点本地,但不具有为其他节点提供稳定供应能力的数据,主要存在于缓存空间充足但上载带宽不足的节点中,可以充当供应服务的补充角色。
以上缓存的各种状态表示为STATUS={PSC、CSC、LSC、DSC、RSC}。
缓存数据随着节点的移动在不同状态间进行转换。如图2所示,大致过程如下:(1)节点在场景中漫游,首先需从供应节点得到预取区域和AOI中的场景数据,来满足用户当前视野的渲染需求,这些数据处于PSC和CSC状态;(2)随着节点的移动,需要对AOI中的数据进行更新,原来处于PSC和CSC状态的数据需要进行转换,如果此时该节点具备为其他节点提供稳定上载的供应能力,则根据缓存更新策略将处于PSC和CSC状态的部分数据转换为LSC状态,而拥有该LSC状态数据的其他兴趣簇节点需要将自身缓存中的该数据转化为DSC状态;(3)对于PSC和CSC状态中节点不能提供稳定供应能力的数据,则将其转换为RSC状态。
由于节点的缓存空间是有限的,在缓存不足的情况下需要对一些数据进行剔除。不同状态的数据具有不同的缓存优先级,优先级的次序分别为CSCprior>PSCprior>LSCprior>DSCprior>RSCprior,当缓存空间不足时,从优先级小的状态数据进行剔除。
1.3兴趣域
节点加载和传输数据的主要对象是三维虚拟场景数据,本发明从场景数据的角度出发,在兴趣簇的基础上进一步提出兴趣域的概念来分析虚拟场景的传输问题。兴趣簇的关注对象是节点化身,而兴趣域的关注对象是兴趣簇节点所加载的场景数据。
整个虚拟场景可以分割为均匀的正方形单元格Cell,Cell为节点场景拾取的基本单位,兴趣簇节点的漫游区域将会覆盖若干个Cell,用坐标方位对Cell进行编号,表示为Celli。
定义1兴趣域(Cluster Region),在节点加入和离开某个兴趣簇的一时间段中,各个簇节点在漫游过程中所拾取的场景单元格构成的场景区域集合。表示为:
RCell={Celli|Cell1,Cell2,…,Cellm}
其中i为Cell在兴趣域中的唯一坐标编号,i={1,2,…m},m为兴趣域中Cell的总数。
随着簇节点的不断加入和移动范围的扩大,兴趣域中的单元格将会逐渐增多,当兴趣簇趋于稳定后,其兴趣域也将趋于固定。
对兴趣域中Cell缓存状态进行形式化描述。兴趣域的场景数据分布在各个簇节点中,将分布在各个节点中Cell集合记为其中Node表示存储Cell的节点,Node={1,2,…n},n为node个数,j为该节点存储的Cell坐标编号集,i为兴趣域RCell中Cell坐标编号集,那么
存储在各个节点上的Cell具有各种状态,本发明用符号来描述Cell的状态,其中k为该节点存储的Cell坐标编号集,Status表示Cell在该Node缓存中所处的四种状态。那么
由于DSC状态数据为副本数据,不将其计入上述Status中。
2)缓存管理机制
为了充分提高资源查找的效率,本发明采用两种策略对请求节点提供数据供应服务,一、通过直接前驱节点获取数据供应服务,数据来源为处于任何缓存状态的场景数据,该策略需要基于mesh network来构建每个节点的直接前驱节点集;二、通过资源定位文件直接定位资源固有节点并获取数据,数据来源为只处于LSC状态的场景数据,资源定位文件需要通过传递式缓存更新策略进行周期性更新。
节点请求数据时,首先向前驱节点进行询问,在没有直接前驱节点或者前驱节点不能满足数据加载的情况下,则向资源固有节点进行请求,固有节点的LSC数据具有最高上载服务优先级。该策略充分挖掘了节点的兴趣行为,来建立一个稳定的邻居关系和资源查找体系,保证了场景数据的快速查找和数据的稳定供应,并充分利用了各节点的网络资源,避免单个节点的过载。
通常节点会同时拥有前驱节点和固有节点两种角色,在节点对后继节点提供PSC、CSC和RSC数据的同时,其他节点可能会对处于LSC的数据进行服务请求,由于LSC的数据请求应答具有最高优先级,将会中断PSC、CSC和RSC数据的传输,迫使这些后继结点重新去寻找供应节点,为了让节点之间保持相对稳定的供需关系,减少资源查找时间,应该尽可能的使节点的LSC数据由后继节点而不是其他节点来请求,所以随着节点的移动,需要不断对LSC状态的数据进行更新,保持LSC状态的场景数据在节点之间不断传递,从而让场景数据始终存储在处于该场景区域附近的节点中。
2.1)前驱节点集合的构建
为了进一步提高资源查找效率并尽可能的保证场景数据的无延迟加载,本发明在兴趣簇的基础上根据节点漫游行为特征和场景分布特征,提出了从簇邻居表中选择若干邻居来构建直接前驱节点集合的算法。
化身在漫游过程中,必须要保证整体场景数据的供应能力大于化身在漫游时的Cell数据的拾取速度,这样才能保证化身在漫游过程中不出现场景加载延迟和视觉卡顿现象。而Cell数据量和Cell的拾取速度直接决定了这一过程,因此本发明用这两个变量来计算上载该Cell应该具有的供应能力并以此来构建稳定的前驱节点集。
定义2.单元格平均移动速度(Cell Average Speed),在单位历史时间内,所有节点在Celli中移动速度的平均值,表示为ASpeedi。
定义3.单元格拾取速度(Cell Load Speed),Celli被周围节点AOI拾取的最大加载速度。该速度由AOI半径r、距离Celli为r的单元格的平均移动速度和Cell大小决定。记为LSpeed(Celli),单位为cell/s,表示为
其中Lcell为Cell的边长;S是以Celli为中心,距离为r的Cell集合。
定义4.单元格数据量(Cell Data Volume),Celli中的所有三维模型数据量之和,其中单元格中重用模型的数据量只计算一次,表示为DVol(Celli)。
针对兴趣域中的一个Celli,上载该Cell的上载带宽BW(Celli)必须满足如下条件,才能保证请求节点的无延迟加载:
那么针对上载带宽和缓存空间必须同时满足如下条件:
其中,上载带宽的计算基于单元格平均移动速度和单元格拾取速度,而这两个变量基于用户的历史访问记录和虚拟场景设计者的经验值,随着新访问记录的产生,需要对这些数据进行学习,周期性的对这两个变量进行更新,来使上载带宽的运算更加准确。
在Mesh network中,为了使节点可以首先从直接前驱节点的缓存空间获取场景数据,必须维持一个随时满足其数据请求需求并且稳定的供应节点集合。
以下描述构建普通节点的直接前驱节点集的过程。
(1)供应节点上载能力的衡量
节点在移动时拾取的场景数据量决定了数据的请求量,而拾取数据量是由化身在场景中的漫游速度和所加载的Cell数据量决定的。但是各个节点的漫游速度和每个Cell的场景数据量是不同的,并且每个节点请求数据的时间和数据量也无法精确预测。由于兴趣域在整个场景中是一个个的局部范围,并且本发明更注重的是兴趣簇的整体性能,本发明用兴趣域中Cell的平均数据量和节点的平均移动速度,来计算每个节点应维护的供应能力。
设当前兴趣域共包含m个Cell,Cell的平均场景数据为ADVol,记为
Cell的平均拾取速度为ALSpeed,记为
根据每个化身的AOI和场景拾取算法,可以得出化身每移动一个Cell将加载的新Cell数量,设为k个,那么每个节点应维护的前驱供应节点的域基本上载带宽UBW需满足如下条件:
UBW≥k×ADVol×ALSpeed
(2)基于最近距离的节点选择
节点在场景漫游过程中,距离相近的节点必定会加载更多相同的数据,那么在兴趣簇中选择那些能满足数据供应需求并且物理距离较近或者在场景相似度高的区域中漫游的节点作为直接前驱节点集,将会使直接前驱节点集更加稳定。
节点Node的兴趣簇节点集为Cluster={Peeri|Peer1,Peer2,…Peern},i为簇节点编号,i={1,2,…n},n为兴趣簇节点的总数。
首先按照节点之间的欧氏距离由小到大对Cluster中的节点进行排序,记为有序n元组QCluster=<Peerq1,…Peerqj,…Peerqn>,其中Peerqj∈Cluster,qj∈{1,2,…n},元组中元素序列基于以下条件
dist(Node,Peerqj-1)≤dist(Node,Peerqj)
其中dist(Node,Peerqj)代表节点Node和兴趣簇节点集中节点Peerqj的欧氏距离。
(3)直接前驱节点集的构建条件
节点Node从元组QCluster中依次选择节点来构建自身的直接前驱节点集,表示为PrePeer={Peerp1,…Peerpk,…Peerpr},其中pk∈{1,2,…n},pr为前驱节点集的节点个数,那么
PrePeer的节点需满足以下双目标函数:
min pr
且目标函数需满足的约束条件为:
其中
RBW(Peerpk)=PBW(Peerpk)-v×UBW
PBW(Peerpk)表示节点Peerpk固有的可用带宽,v为后继节点的个数(多个节点可以同时拥有同一个直接前驱节点),RBW(Peerpk)表示节点Peerpk扣除已有的后继节点占有服务带宽的剩余带宽。
构建普通节点的直接前驱节点集,通常在节点刚加入兴趣簇时进行判定。由于节点化身在场景漫游中,漫游的方向和运动速度是不同的,使得它们之间的位置拓扑不断的发生变化,所以需要根据Mesh network进行周期性调整。但拓扑的频繁变化也会给直接前驱节点集的判定带来一定的难度和计算消耗,考虑到兴趣簇节点的前驱节点集的整体稳固性,也必须对更新周期进行优化设置。
2.2)LSC缓存结构的构建和更新
节点缓存的更新过程就是缓存状态的转化过程,LSC缓存状态的转化对应着资源定位文件中资源分布的更新,而整个兴趣簇节点的LSC缓存结构就能构建出资源定位文件。
兴趣簇在构建和维护过程中,节点的数量和拓扑结构是不断变化的,那么LSC缓存结构也会不断变化,为了形成稳定的LSC缓存结构来实现场景数据的自给,本发明基于以下两个目标对其进行构建和更新:
(1)所有兴趣簇节点的LSC状态缓存数据必须对兴趣域中的场景数据进行全覆盖,以减少对超级节点的依赖,增加普通节点的数据共享程度;并在整体缓存资源有限的情况下,减少副本数据(DSC状态数据)的存在。即满足或趋近如下目标:
其中p为节点序号,n为兴趣簇中节点个数。
(2)根据每个兴趣簇节点的计算能力对LSC状态的缓存数据进行均衡合理的计算资源分配,使得每一个LSC状态缓存数据都拥有着稳定的上载供应能力,并形成场景资源定位文件。
下面介绍节点中LSC状态数据缓存剔除和更新策略。
1)LSC转化的基本条件
将场景数据标识为LSC状态是为了向请求节点提供可靠的并且具有最高上载优先级的专有数据上载服务。因此对于兴趣簇的所有节点,任何节点将兴趣域中的场景数据以LSC状态进行存储,必须具有一定的基本计算能力,而节点的上载带宽能力和缓存能力是满足这些需求的最基本计算能力,本发明以这两个因素来衡量LSC转化条件。
假设Cellj为待转换为LSC状态的单元格数据,如果节点的可用上载带宽可以承载该Cellj的上载传输BW(Cellj),并且缓存空间在能保证PSC和CSC状态数据加载的情况下仍有足够的空闲空间用于储存LSC状态的数据时,那么节点node就具备了将Cellj转化为状态LSC的条件,描述如下:
设节点node的可用上载带宽为NBW,节点的缓存空间为NCache,针对某个如果
那么,节点node拥有基本的计算能力,使得
根据以上条件,当节点需要对自身中PSC和CSC状态的数据进行更新时,在节点自身能满足已缓存某个Cell的供应上载带宽要求(NBW(Peer)≥BW(Cellj))且缓存空间充足的情况下,就将该Cellj的状态转化为LSC状态;如果节点满足不了缓存Cellj的供应上载带宽要求但缓存空间充足,就将该Cellj的状态转化为RSC状态(可在带宽空闲时进行并发传输服务)。
2)簇节点中LSC的传递式更新
在节点的漫游过程中,当有节点从超级节点请求兴趣域已有数据或者从前驱节点请求LSC状态的Cell数据时,就会存在多个节点同时拥有同一个处于LSC状态的Cell数据的情况,而在簇节点没有对兴趣域数据覆盖之前,需要尽可能降低缓存数据的冗余度为新加载的场景数据提供更大的缓存空间,以保证对兴趣域的全覆盖。此时,对缓存数据的更新除了考虑节点自身缓存情况外,还必须从整个兴趣簇的角度出发,来考虑缓存数据的冗余度,并对副本进行优化分布,以最大限的提高资源利用率。
因此需要根据资源定位文件和各个节点的计算能力,来决定将哪些LSC状态数据进行冗余处理。基于提出的缓存目标(1),本发明提出一个衡量标准对重复缓存数据的转化优先级进行量化,并以此来决定哪一个节点以LSC状态缓存某Cell数据,而在其他节点中将其转化为DSC状态。
本发明选用空间场景距离和节点缓存空间作为判断LSC状态转化为DSC的衡量标准。
假设当前有多个节点同时缓存有处于LSC状态的Cellj,符合这样条件的节点设为node={ni|n1,n2,…nq},用表示节点ni的视点圆心与Cellj的欧氏场景距离,代表节点ni的视点圆心。由于在场景空间中,空间距离的数据差值较大,为了衡量的精确度,本发明将其进行归一化处理,表示为NDist,
将Cellj在每个节点缓存空间Cache中所占的比例作为缓存比重指标,表示为NCrate,
依据这两个衡量指标对LSC转化标准进行量化,与单元格空间距离较近并拥有较大缓存空间的节点,应作为存储Cellj的最佳节点。记LSC转化度为NLSC,表示为
NLSCi=α×NDisti+β×NCratei
α+β=1,在不同的场景环境中,这两个指标的数值可能会相差较大,需要根据具体的场景特征进行调整。例如,如果单元格的数据量普遍较小,则可将β的值调大,以增大其在量化标准中的比重。
如果节点nj满足那么就指定nj保留Cellj的LSC状态,作为给其他节点提供Cellj的上载服务的固定供应节点。集合node中的其他节点根据超级节点的通知,将Cellj标记为DSC状态,在自身缓存空间不足的情况下,可以对DSC状态的数据进行删除。
(3)LSC缓存数据的剔除
随着节点在场景中漫游范围的加大,将会有越来越多已加载过的场景数据以LSC状态缓存在节点本地,但节点的缓存空间和上载带宽毕竟有限,因此当缓存空间不足时,除了考虑将LSC转化为DSC状态外,还必须考虑LSC状态数据的直接剔除问题。
节点对自身LSC数据的直接剔除,不但要考虑本地LSC数据间的缓存优先级,也必须考虑其他簇节点的缓存情况。这里存在三种可能:(1)节点所存储的LSC数据中有一部分在兴趣簇中有副本存在;(2)节点所存储的全部LSC数据在兴趣簇中都有副本(DSC状态)存在;(3)节点所存储的全部LSC数据在兴趣簇中都没有副本存在。
针对只有部分LSC数据有副本的,为了保证兴趣簇中LSC数据对兴趣域的全覆盖,应该先删除具有副本的LSC数据,并通知超级节点根据空间场景距离和节点缓存空间将其他簇节点中的DSC数据转化为LSC,转化节点的判断如前文所述。在剔除这些具有副本的LSC数据时,副本数量是必须考虑的一个因素。而对于没有副本的LSC数据,只需从数据热度方面来考虑这些LSC数据的剔除权重问题。
下面本发明用数据请求率、数据重用度和副本数量这三个指标对LSC数据剔除权重的判断依据进行阐述,首先有如下定义:
定义5.单元格请求率(Cell Visit Rate),在单位历史时间内,访问Celli的次数与虚拟场景总访问次数的比值。表示为
其中VNumi为Celli的访问次数,i,j={1,2,…camt},camt为整个虚拟场景Cell的数量。
定义6.单元格重用度(Cell Reused Degree),Celli中每个Model在整个兴趣域中重用次数的总和为单元格重用度。表示为
其中RNumj为Modelj在兴趣域中的重用次数,j={1,2,…mamt},mamt为兴趣域中Model的数量。
假设Celli在兴趣簇中处于DSC状态的数量为m,依据单元格请求率和单元格重用度对兴趣域中的Cell进行排序,记Celli的缓存优先级为CPrior,表示为
α+β=1,具体值可以根据具体的场景特征进行调整,如果场景重用度的特征比较明显,则可将其比重调大。
当有新Cell转化为LSC状态并且节点的缓存空间不足以存储所有LSC数据时,节点需要参照兴趣簇的资源定位文件,并根据新转化的LSC状态和已有LSC状态的所有Cell的缓存优先级CPrior,依次剔除优先级低的LSC状态的Cell,即
以空出更多缓存空间来保留优先级高的Cell。
同样的,RSC状态的数据更新,和上述LSC数据更新的方法一致,可以在不考虑副本数量的情况下,采用上述方法对RSC数据进行剔除权重的判定。
节点自身缓存状态的任何转化,都要周期性的通知给超级节点,超级节点根据节点反馈的属性描述信息,针对兴趣簇中的全部节点和兴趣域数据,会对LSC状态数据进行权重衡量和宏观调控,然后对相关节点发出更新指令,并最终完成资源定位文件的更新。
本实施例中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!