一种基于遗传算法嵌套粒子群算法的风电场多型号风力发电机排布优化方法与流程
本发明涉及一种风电场多型号风力发电机排布优化方法,特别涉及一种基于遗传算法嵌套粒子群算法的风电场多型号风力发电机排布优化方法。
背景技术:
风能是一种无污染、可再生的新能源,在能源紧缺和传统能源对环境污染严重的现代社会,风电产业成为大力发展的新能源产业之一。风电场微观选址是风电产业合理规划的必要步骤。建设风电场前的风电场微观选址可以有效提高风能利用效率,提高风机使用寿命,降低风电场运维成本和风力发电成本,从而实现风电产业的合理决策与科学发展。风电场选址包括宏观选址和微观选址,宏观选址旨在选择风电场场址,而微观选址重点在于风机选型和安装位置。对当地风资源的长期记录和分析是风电场选址的大前提,微观选址在宏观选址完成之后,安装测风塔,对场址处风况进行一年以上的检测和记录,结合当地长期气象记录等,综合进行风资源分析和评估。在风资源评估、场址地形地貌综合分析的基础上,选择风机数量和型号,确定风机安装位置,以达到风电场预期年产量最大或预期风力发电度电成本最低,令该风电场在社会、经济和环境指标满足的条件下,达到经济效益最大化。
风电场微观选址优化是一种非线性强耦合问题,需综合考虑当地气象地形、环境指标、土地价格、道路分布和建设可行性等因素,涉及流体、气象、机电等多方面因素,无法使用传统最优化方法得出最优解。因此,目前在世界范围内,该方向的研究成果大多都是使用基于搜索的启发式算法对具体问题进行优化决策计算。优化的主要方法为遗传算法、随机算法、粒子群优化算法等。但是研究对象都是简化后的概念性风电场,大多只选择单一型号的风力发电机,将风电场划分为类似棋盘格的方格,对每个格子进行“0”和“1”编码来代表安装风机与否,无法进行风电场区域二维空间上的连续搜索,同时,单一型号的风机高度一致,风机功率曲线一致,无法充分利用三维空间上分布的风能资源。因此,传统的风机排布优化算法无法更加有效地提高风场产能效率和降低风电场产能成本,需要进行进一步改进和性能提升。
与本专利相关的文献和专利中,文献Castro Mora,J等发表在2007年的Neurocomputing的论文“An evolutive algorithm for wind farm optimal design”中,提出了多型号风机排布优化的问题并给出了一种解决方法,但是优化中并未考虑风机间的尾流影响。专利《一种基于遗传算法的风电场多型号风机优化排布方案》(申请公布号:CN 103793566A)提出了使用遗传算法来解决多型号风力发电机排布的问题,但是在风电场区域的搜索方法是人为划分风机直径倍数的网格,风机排布的位置相对粗糙,不够精准。
技术实现要素:
本发明目的在于克服上述现有研究和技术存在的问题和缺陷,提出一种基于遗传算法嵌套粒子群算法的方电场多型号风力发电机排布优化方法。该方法对风电场区域搜索连续,可提高风机排布位置精度,能充分利用竖直方向上的风资源,更具有实用性,且扩展性高。
本发明的目的通过以下的技术方案实现:一种基于遗传算法嵌套粒子群算法的方电场多型号风力发电机排布优化方法,该方法包括以下步骤:
1)根据风资源评估结果和风电场地形气象特性,对风力发电机进行初始选型,确定若干个备选型号用于选型优化,读入风电场相关地形和气象等参数;
2)在风电场区域横纵坐标范围内随机生成风机的初始位置矩阵,矩阵每行代表一种风机位置排布方案,即一个染色体,行数代表遗传算法染色体数,对矩阵的每一行进行二进制编码;
3)在给定的备选风机型号内生成初始型号矩阵并编码,矩阵行数代表粒子群算法粒子数,矩阵的每一行代表一个粒子(一种风机型号选取方案),随机初始化粒子的速度和在搜索域内的位置,作为当前染色体的风机型号选取的初始解;
4)计算当前每个粒子的适应度,即采用当前风机位置和选型方案的度电成本,并求出每个粒子的个体最优适应度和所有粒子的全局最优适应度;
5)根据粒子群算法中设定的粒子速度和位置进化规则,对每个粒子的位置和速度进行进化;
6)判断是否达到粒子群算法设定的最大代数,若达到设定最大代数,停止进行风机型号优化,选取粒子群算法的全局最优适应度,作为当前染色体的适应度,否则返回步骤4);
7)根据每个染色体的适应度,求出遗传算法的全局最优适应度,即风机位置选型的全局最优值;
8)判断是否达到遗传算法的最大迭代次数,若是,则输出遗传算法的全局最优适应度对应的染色体作为风机位置方案,其对应的粒子群算法的全局最优适应度作为选型方案,完成多型号风力发电机排布优化,否则进行步骤9);
9)把所有染色体作为父代染色体群,进行交叉、变异操作,根据染色体的适应度大小计算选择概率,进行选择生成子代染色体群并返回步骤3)。
进一步地,遗传算法和粒子群算法的嵌套为,使用遗传算法选取风机位置,遗传算法的每一代种群生成后,以当前代风机位置作为风机排布位置,使用粒子群算法得出当前代风机位置时选型的最优解,作为当前代风机位置的适应度。
进一步地,个体适应度通过计算度电成本的倒数来体现,度电成本定义为每发一度电的平均成本。适应度最高的个体即为度电成本倒数的最大值,即度电成本最小值的个体,度电成本CoP的计算公式为:
其中:CoE是年发电成本,AEP是风电场年平均发电量,Ci是每台风机的购买年均成本,CO&M是风场的年度运维成本,Cland是风电场土地年平均占用成本,Cother是风电场其他费用的年平均值,Pi是每台风机的年平均发电量,N是风电场风机总台数。
进一步地,所述的粒子群算法选取特定位置方案的风机型号组合,风机的型号特征参数有多种,对任意两台风机,如果任何一个特征参数不同(机场高度、风机额定功率等)在本发明中也认为是不同型号,因此风机型号选择有多种可能性,可根据实际建场时具体情况进行设定。粒子群算法可以保证风机型号选取方案计算的快速。
进一步地,使用遗传算法对风电场区域进行搜索,对可行域的搜索密度由遗传算法中对位置坐标的编码决定,可以进行连续搜索,搜索密度也可以根据实际计算要求进行设定,并不是在风电场区域进行棋盘格划分后再对棋盘格进行选择。
与现有技术相比,本发明具有以下优点:
1、对风电场区域风机位置可行域搜索细致连续。因为对风机位置坐标直接编码,而不是对风电场区域划分棋盘格后对棋盘格进行选择,可在风电场范围内进行连续搜索。能够有效针对实际风电场区域进行风机位置选择和优化。如果为了提高搜索速度,可通过遗传算法编码方式来改变位置搜索密度。
2、算法先进,保证了求解的可行性。遗传算法的使用充分保证了针对非线性强耦合优化问题可求出可行解,粒子群算法的使用既保证了针对多种型号风力发电机参数较多的情况下可快速寻得选型解,又能保证快速两种算法嵌套使用,迭代次数过多的情况下,计算时间不会过长。
3、实用性强。本发明方法充分考虑了实际风场区域的特点和使用多型号风机利用风能的特点,可推广至复杂地形三维风机选址和多型号风机混装的情况;编码方式易于在风电场区域存在道路、维修等限制条件,存在不可建风机子区域的情况下实现。
4、扩展性好,该研究方法和成果可以有效推广拓展至类似的问题求解中,解决相应问题。
附图说明
图1是本发明的风电场多型号风力发电机排布优化方法流程图。
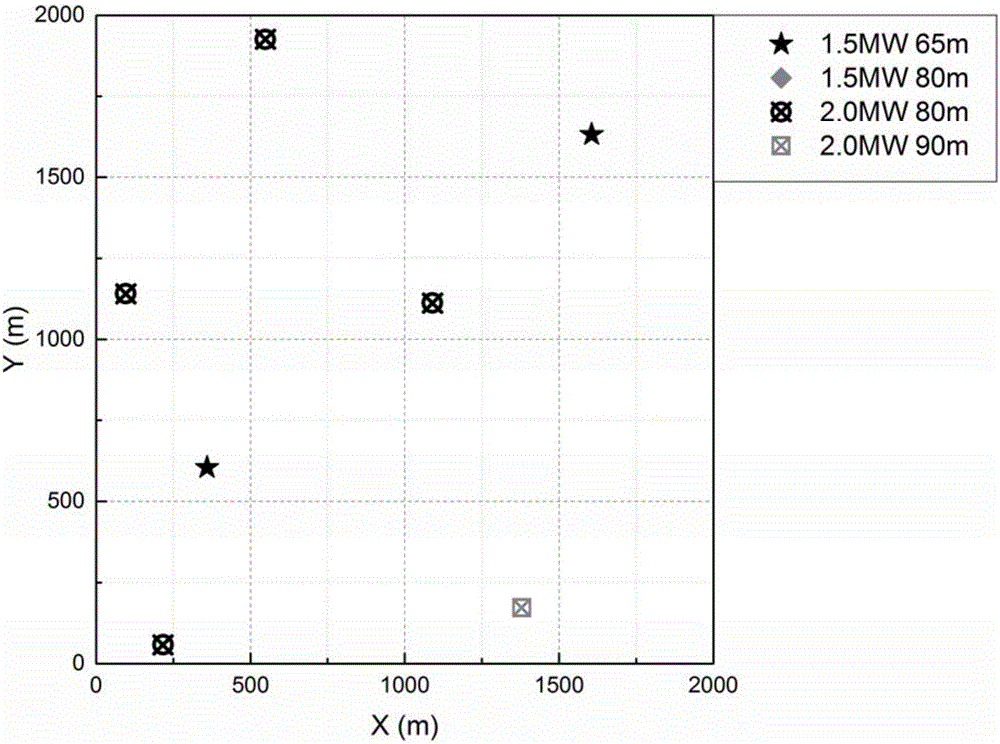
图2是由本发明的优化方法应用于实施例的计算结果。
具体实施方式
以下结合附图对本发明的实施作如下详述:
实施例
本实施例对某风电场的7台风力进行发电机建场前的风机排布选型优化。备选风机为两种出厂型号A(额定功率为1.5MW)和B(额定功率为2MW),每种出厂型号的风机安装高度有两种(1.5MW有65米和80米两种高度,2MW有80米和90米两种高度),即风机型号有4种。风电场区域为横坐标[0,2000](米),纵坐标为[0,2000](米)范围。本实施实例中不考虑复杂地形。优化目标为风电场度电成本。实施步骤具体如下:
1)根据风资源评估结果和风电场地形气象特性,对风力发电机进行初始选型,确定若干个备选型号用于选型优化,读入风电场相关地形和气象等参数;
2)在风电场区域横纵坐标范围内随机生成风机的初始位置矩阵,矩阵每行代表一种风机位置排布方案,即一个染色体,行数代表遗传算法染色体数,对矩阵的每一行进行二进制编码;
3)在给定的备选风机型号内生成初始型号矩阵并编码,矩阵行数代表粒子群算法粒子数,矩阵的每一行代表一个粒子(一种风机型号选取方案),随机初始化粒子的速度和在搜索域内的位置,作为当前染色体的风机型号选取的初始解;
4)计算当前每个粒子的适应度,即采用当前风机位置和选型方案的度电成本,并求出每个粒子的个体最优适应度和所有粒子的全局最优适应度;
5)根据粒子群算法中设定的粒子速度和位置进化规则,对每个粒子的位置和速度进行进化;
6)判断是否达到粒子群算法设定的最大代数,若达到设定最大代数,停止进行风机型号优化,选取粒子群算法的全局最优适应度,作为当前染色体的适应度,否则返回步骤4);
7)根据每个染色体的适应度,求出遗传算法的全局最优适应度,即风机位置选型的全局最优值;
8)判断是否达到遗传算法的最大迭代次数,若是,则输出遗传算法的全局最优适应度对应的染色体作为风机位置方案,其对应的粒子群算法的全局最优适应度作为选型方案,完成多型号风力发电机排布优化,否则进行步骤9);
9)把所有染色体作为父代染色体群,进行交叉、变异操作,根据染色体的适应度大小计算选择概率,进行选择生成子代染色体群并返回步骤3)。
计算当前代风机型号选取方案最优解的适应度值,计算当前代位置的个体适应度值,个体适应度计算公式为:
其中:CoE是年发电成本,AEP是风电场年平均发电量,Ci是每台风机的购买年均成本,CO&M是风场的年度运维成本,Cland是风电场土地年平均占用成本,Cother是风电场其他费用的年平均值,Pi是每台风机的年平均发电量,N是风电场风机总台数,在本实施例中为7;
本发明基于遗传算法嵌套粒子群算法的风电场多型号风力发电机排布优化方法主要包括初始化(包括编码)、计算当代个体适应度、子代生成(交叉变异)等环节组成。在遗传算法的每一代适应度计算中,嵌套对风机型号的优化算法过程,风机型号的优化算法为粒子群算法。图1为基于遗传算法嵌套粒子群算法的风电场多型号风力发电机排布优化方法具体流程。整个实施例是按照图1中所示的流程,进行多型号风力发电机排布优化计算。图2是使用本发明的基于遗传算法嵌套粒子群算法的风电场多型号风力发电机排布优化方法进行排布的结果。假设风机使用寿命为20年,度电成本计算结果为0.3406元/千瓦时,风机在尾流影响下的发电效率为0.9948。使用基于遗传算法嵌套粒子群算法的风电场多型号风力发电机排布优化方法计算结果显示,风机排布位置充分利用了风力发电厂区域,有效提高了风能利用率,适用于风电场微观选址。
- 还没有人留言评论。精彩留言会获得点赞!