同时识别双语术语与词对齐的实现方法及实现系统与流程
本发明涉及自然语言处理技术领域,更具体地,涉及一种同时识别双语术语与词对齐的实现方法及实现系统。
背景技术:
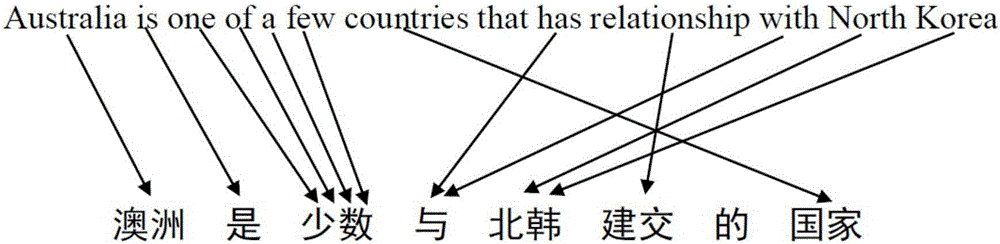
机器翻译是用计算机来实现不同语言之间的转换。被翻译的语言通常称为源语言,翻译成的结果语言称为目标语言。机器翻译就是实现从源语言到目标语言转换的过程。词对齐是统计机器翻译的一项核心任务,它从双语平行语料中发掘互为翻译的语言片断,是翻译知识的主要来源。简而言之,词对齐就是源语言句子中某个词是由目标语言中哪个词翻译而来的。如图1所示,一个词可以被翻译为一个或多个词,甚至不被翻译。在实践中,一部分词对齐错误因未能正确识别和处理术语对应关系而触发,因而进一步影响最终机器翻译译文质量。因此如果能自动识别出平行句对中的术语对应关系,能显著提升词对齐质量,进而增强机器翻译译文质量,尤其是术语的翻译质量。
此外,术语广泛存在于具体的领域语料中,如计算机和医学领域。在微软本地化翻译语料中,平均每100个词就包含15个术语。自动术语识别是指从文本中自动发现领域术语的过程。它是一项具有重要作用的语言技术,在自然语言处理、机器翻译等应用领域具有重要意义。自动术语识别常用的方法包括基于规则方法和基于统计方法。基于规则方法是根据术语构成模式建立一套规则,选择匹配规则的词语作为领域术语。这种方法的最大缺陷是人工编写的规则不可能覆盖所有的语言学现象,领域依赖性很强。基于统计方法主要应用词频、TF-IDF、互信息、信息熵、log-likelihood、假设检验等统计特征,选择特征值符合阈值的词语作为领域术语。基于统计方法不受领域限制,但是对于单词术语和低频术语的识别并不理想,抽取的术语也存在较多噪声。
而当前自动术语识别的性能并没有达到能直接用于词对齐的水平。其主要原因为如下两点:(1)性能更好的基于机器学习技术的术语识别方法需要高质量的人工标数据,但目前极度缺乏足量且高质量的术语标注数据;(2)不断有新的术语产生,标注数据的更新速度严重滞后于实际需求。所以,如果直接将自动术语识别结果作为词对齐的约束,并不能带来性能的提升。因此,研究如何同时提高自动术语识别和词对齐性能,并提高最终的机器翻译译文质量是迫切需要解决的一个难题。
技术实现要素:
为了解决现有技术中的上述问题,即为了解决自动术语识别和词对齐性能,并提高最终的机器翻译译文质量的问题,本发明提供了一种人同时识别双语术语与词对齐的实现方法。
为实现上述目的,本发明提供了如下方案:
一种同时识别双语术语与词对齐的实现方法,所述实现方法包括:
对一对源语言句子和目标语言句子进行分词,获得源语言词组和目标语言词组;
对所述源语言词组和目标语言词组进行词对齐,获得源语言句子到目标句子的对齐初始词;
分别识别所述源语言句子和目标语言句子中的术语,获得初始单语术语;所述初始单语术语包含初始源语言术语和初始目标语言术语;
结合所述对齐初始词、初始单语术语,进行术语对齐,得到初始源语言术语到初始目标语言术语的对齐初始术语;
将所述对齐初始术语作为锚点,通过扩大或者收缩术语边界,获得扩展后的初级双语术语候选列表;
对所述初级双语术语候选列表进行双语术语识别,获得修正的次级双语术语候选列表;
对所述次级双语术语候选列表进行二次双语术语识别和词对齐,获得终极双语术语和终极对齐词。
可选的,所述获得初始单语术语的方法包括:
步骤S31:利用源语言对应的维基百科单语语料训练获得源语言单语术语识别最大熵模型;利用目标语言对应的维基百科单语语料训练获得目标语言单语术语识别最大熵模型;
步骤S32:根据所述源语言句子及所述源语言单语术语识别最大熵模型,获得源语言术语识别中间结果;根据所述目标语言句子及所述目标语言单语术语识别最大熵模型,获得目标语言术语识别中间结果;
步骤S33:将所述源语言术语识别中间结果作为源语言术语识别解码器,解码所述源语言句子得到初始源语言术语;将所述目标语言术语识别中间结果作为目标语言术语识别解码器,解码所述目标语言句子得到初始目标语言术语。
可选的,所述得到初始源语言术语到初始目标语言术语的对齐初始术语的方法包括:
步骤S41:根据所述初始单语术语确定对应的术语特征值;
步骤S42:根据术语特征值及所述术语对齐最大熵模型计算得到任意源语言术语至任意目标语言术语的初始术语对齐分值;
步骤S43:根据所述初始术语对齐分值对初始术语对齐序列进行排序,获得初始术语对齐。
可选的,所述术语特征值包括:
A、源语言术语至目标语言术语的短语翻译概率;
B、源语言术语至目标语言术语的词汇化翻译概率;
C、目标语言术语至源语言术语的短语翻译概率;
D、目标语言术语至源语言术语的词汇化翻译概率。
可选的,所述得到初始源语言术语到初始目标语言术语的对齐初始术语的方法还包括:
如果识别出的源语言句子和目标语言句子中均没有术语,则将所述对齐的源语言词组中,有最大概率被识别为术语的词添加到初始源语言术语中;将所述对齐的目标语言词组中,有最大概率被识别为术语的词添加到初始目标语言术语中。
可选的,所述获得扩展后的初级双语术语候选列表的方法包括:
步骤S51:以所述对齐初始术语对的源语言术语和目标语言术语为基准,建立一个滑动窗,并建立一系列扩展后的单语术语候选项;
步骤S52:通过组合所述扩展后的单语术语候选项,获得双语术语翻译对的候选项;
步骤S53:对所有所述翻译术语翻译对的候选项进行排序,根据规则删除不符合条件的双语术语候选项,获得初级双语术语候选列表。
可选的,所述获得修正的次级双语术语候选列表的方法包括:
步骤S61:使用柱搜索算法,根据所述初级双语术语候选列表获得每次保留的K个最好的候选,获得最优的术语对齐序列;
步骤S62:从所述最优的术语对齐序列和所述对齐初始词中,根据规则删除不符合条件的对齐序列,获得修正的次级双语术语候选列表。
可选的,所述获得终极双语术语和终极对齐词的方法包括:
步骤S71:构建一个空的词对齐候选列表;
步骤S72:从所述次级双语术语候选列表中各种双语术语候选逐一选取,并以选取的双语术语候选为约束,利用基于隐马尔可夫的词对齐方法,生成K个最优的词对齐候选并添加到所述词对齐候选列表;
步骤S73:利用柱搜索算法,结合所述次级双语术语候选列表,对所述词对齐候选列表对齐综合排序,获得K个最好的双语术语候选和词对齐候选,分别为终极双语术语和终极对齐词。
根据本发明的实施例,本发明公开了以下技术效果:
本发明同时识别双语术语与词对齐的实现方法通过分词、词对齐、术语对齐处理,可得到双语术语的对齐初始术语,同时识别双语术语与词对齐能够突破单独进行双语术语识别或者词对齐的局限性,从而大幅提高双语术语与词对齐性能;通过修正初级双语术语候选列表进行双语术语识别得到次级双语术语候选列表,可进一步提高术语识别和词对齐性能,并提高最终的机器翻译译文质量。
为了解决现有技术中的上述问题,即为了解决自动术语识别和词对齐性能,并提高最终的机器翻译译文质量的问题,本发明提供了一种人同时识别双语术语与词对齐的实现系统。
为实现上述目的,本发明提供了如下方案:
一种同时识别双语术语与词对齐的实现系统,所述识别装置包括:
分词模块,用于对一对源语言句子和目标语言句子进行分词,获得源语言词组和目标语言词组;
词对齐模块,用于对所述源语言词组和目标语言词组进行词对齐,获得源语言句子到目标句子的对齐初始词;
识别模块,用于分别识别所述源语言句子和目标语言句子中的术语,获得初始单语术语;所述初始单语术语包含初始源语言术语和初始目标语言术语;
术语对齐模块,用于结合所述对齐初始词、初始单语术语,进行术语对齐,得到初始源语言术语到初始目标语言术语的对齐初始术语;
初级列表确定模块,用于将所述对齐初始术语作为锚点,通过扩大或者收缩术语边界,获得扩展后的初级双语术语候选列表;
次级列表确定模块,用于对所述初级双语术语候选列表进行双语术语识别,获得修正的次级双语术语候选列表;
终极确定模块,用于对所述次级双语术语候选列表进行二次双语术语识别和词对齐,获得终极双语术语和终极对齐词。
可选的,所述识别模块包括:
模型确定单元,用于利用源语言对应的维基百科单语语料训练获得源语言单语术语识别最大熵模型;利用目标语言对应的维基百科单语语料训练获得目标语言单语术语识别最大熵模型;
计算单元,用于根据所述源语言句子及所述源语言单语术语识别最大熵模型,获得源语言术语识别中间结果;根据所述目标语言句子及所述目标语言单语术语识别最大熵模型,获得目标语言术语识别中间结果;
解码单元,用于将所述源语言术语识别中间结果作为源语言术语识别解码器,解码所述源语言句子得到初始源语言术语;将所述目标语言术语识别中间结果作为目标语言术语识别解码器,解码所述目标语言句子得到初始目标语言术语。
根据本发明的实施例,本发明公开了以下技术效果:
本发明同时识别双语术语与词对齐的实现系统通过设置分词模块、词对齐模块、识别模块,可得到双语术语的对齐初始术语,同时识别双语术语与词对齐能够突破单独进行双语术语识别或者词对齐的局限性,从而大幅提高双语术语与词对齐性能;通过设置初级列表确定模块、次级列表确定单元,修正初级双语术语候选列表进行双语术语识别得到次级双语术语候选列表,可进一步提高术语识别和词对齐性能,并提高最终的机器翻译译文质量。
附图说明
图1是词对齐的一个实例示意图;
图2是本发明同时识别双语术语与词对齐的实现方法的流程图;
图3是本发明同时识别双语术语与词对齐的工作示意图;
图4是本发明同时识别双语术语与词对齐的实现系统的模块结构示意图。
符号说明:
分词模块—1,词对齐模块—2,识别模块—3,术语对齐模块—4,初级列表确定模块—5,次级列表确定模块—6,终极确定模块—7。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
如图2所示,本发明同时识别双语术语与词对齐的实现方法包括:
步骤100:对一对源语言句子和目标语言句子进行分词,获得源语言词组和目标语言词组;
步骤200:对所述源语言词组和目标语言词组进行词对齐,获得源语言句子到目标句子的对齐初始词;
步骤300:分别识别所述源语言句子和目标语言句子中的术语,获得初始单语术语;所述初始单语术语包含初始源语言术语和初始目标语言术语;
步骤400:结合所述对齐初始词、初始单语术语,进行术语对齐,得到初始源语言术语到初始目标语言术语的对齐初始术语;
步骤500:将所述对齐初始术语作为锚点,通过扩大或者收缩术语边界,获得扩展后的初级双语术语候选列表;
步骤600:对所述初级双语术语候选列表进行双语术语识别,获得修正的次级双语术语候选列表;
步骤700:对所述次级双语术语候选列表进行二次双语术语识别和词对齐,获得终极双语术语和终极对齐词。
通过上述步骤得到:
为了更简洁说明本发明的实施过程,现统一给出符号定义:
源语言句子其中J为源语言句子的词数,sj为源语言句子的第j个词;
目标语言句子其中I为目标语言句子的词数,ti为目标语言句子的第i个词。
经过词对齐处理后,对齐初始词其中指源语言句子第j个词与目标语言句子的第i个词对应,i可能有多个不同的值。
修正后的初始词对齐A=a1a2...aJ,修正后的源语言术语识别修正后的目标语言术语识别
修正后的术语对齐Mk=m1m2...MQ′,其中mq′=(TTp′,STq′),表示第q′个源句子术语对应第p′个目标句子术语;
初始源语言术语识别Q为识别出的源语言术语个数;初始目标语言术语识别P为识别出的目标语言术语个数。
最终词对齐最终双语术语对齐
利用上述符号,本发明的核心思想可形式化为如下四阶段联合模型:
由公式(1)可知,本发明将单语术语识别、双语术语对齐和词对齐融合在一起同时执行,在理论上避免了已有方法存在错误逐级传递的缺点。因为已有方法一般是先进行单语术语识别,再进行双语术语对齐,再在双语术语的约束下进行词对齐,上一阶段的错误会直接传递到下一阶段,最后造成词对齐性能明显下降。在公式(1)中,为双语术语对齐模型,为基于双语术语约束的词对齐模型。公式(1)的输入为源语言句子目标语言句子初始源语言单语术语识别和初始目标语言单语术语识别输出为本发明的最终结果,即最终双语术语对齐M*和最终词对齐A*。
例如,假设源语言句子s,如图3所示:
Header text that appears in the summary.
目标语言句子t:
出现在摘要中的标头文本。
经过分词处理后,并用空格隔开相邻词:
进一步地,在步骤300中,所述获得初始单语术语的方法包括:
步骤310:利用源语言对应的维基百科单语语料训练获得源语言单语术语识别最大熵模型;利用目标语言对应的维基百科单语语料训练获得目标语言单语术语识别最大熵模型。
在本实施例中,所采用的最大熵分类器为斯坦福大学开源的StanfordParser,所述最大熵分类器不能直接使用,需要利用源语言对应的维基百科单语语料训练获得源语言单语术语识别最大熵模型,利用目标语言对应的维基百科单语语料训练获得目标语言单语术语识别最大熵模型。
所述维基百科单语语料,包括英文百科文章存档和中文百科文章存档,得到所述维基百科文档存档后,需要整理后方可用于训练最大熵模型。
整理过程如下:
以英文维基百科中的“computer”条目为例,其中包含句子“Computers are small enough to fit into<mobile devices>,and<mobile computers>can be powered by small<batteries>.Personal computers in their various forms are <icons>of the<Information Age>and are generally considered as"computers".”。其中,“<…>”表示该短语为术语(有人工标记的超链接或者特殊格式(如斜体、加粗等)。按照最大熵模型的要求将所述句子整理成:“Computers/O are/O small/O enough/O to/O fit/O into/O mobile/B devices/I,and/O mobile/B computers/I can/O be/O powered/O by/O small/O batteries/B.Personal/O computers/O in/O their/O various/O forms/O are/O icons/B of/O the/O Information/B Age/I and/O are/O generally/O considered/O as/O"/O computers/O"/O./O”。其中,“O”表示非术语词,“B”表示术语起始词,“I”表示术语中的词。对中文维基百科文档存档作相同处理。
用上述整理之后的句子可训练得到所需的源语言单语术语识别最大熵模型和目标语言单语术语识别最大熵模型,具体训练步骤可参照StanfordParser的操作手册。
步骤320:根据所述源语言句子及所述源语言单语术语识别最大熵模型,获得源语言术语识别中间结果;根据所述目标语言句子及所述目标语言单语术语识别最大熵模型,获得目标语言术语识别中间结果。
在本实施例中,将源语言句子“Header text that appears in the summary.”作为源语言单语术语识别最大熵模型的输入,可得到带标签的源语言术语识别中间结果“Header/B text/O that/O appears/O in/O the/O summary/B./O”。将目标语言句子“出现在摘要中的标头文本。”作为目标语言单语术语识别最大熵模型的输入,可得到带标签的目标语言术语识别中间结果“出现/O在/O摘要/B中/I的/I标头/I文本/I。/O”。
步骤330:将所述源语言术语识别中间结果作为源语言术语识别解码器,解码所述源语言句子得到初始源语言术语;将所述目标语言术语识别中间结果作为目标语言术语识别解码器,解码所述目标语言句子得到初始目标语言术语。
术语识别解码器的作用是将最大熵模型的自动标注结果解码为恰当的术语表示,术语识别解码器能自动丢弃不合法的自动标注结果,如“出现/O在/O摘要/B中/I的/O标头/I文本/I。/O”。在本实施例中,将带标签的源语言术语识别中间结果“Header/B text/O that/O appears/O in/O the/O summary/B./O”解码为“<Header>text that appears in the<summary>.”,即初始源语言术语为“header”和“summary”;将带标签的目标语言术语识别中间结果“出现/O在/O摘要/B中/I的/I标头/I文本/I。/O”解码为“出现在<摘要中的标头文本>。”,即术语为“摘要中的标头文本”。即初始单语术语识别结果:“<Header>text that appears in the<summary>.”;“出现在<摘要中的标头文本>。”;
在步骤400中,所述得到初始源语言术语到初始目标语言术语的对齐初始术语的方法包括:
步骤410:根据所述初始单语术语确定对应的术语特征值。
所述初始单语术语包括初始源语言术语和初始目标语言术语。在本实施例所采用的用于术语对齐最大熵模型为斯坦福大学开源的StanfordParser。所述最大熵模型与步骤300中提及的内容相同,在此不再赘述。
步骤420:根据术语特征值及所述术语对齐最大熵模型计算得到任意源语言术语至任意目标语言术语的初始术语对齐分值。
所述术语特征值包括:
A、源语言术语至目标语言术语的短语翻译概率;
B、源语言术语至目标语言术语的词汇化翻译概率;
C、目标语言术语至源语言术语的短语翻译概率;
D、目标语言术语至源语言术语的词汇化翻译概率。
本发明直接对初始术语对齐概率采用最大熵模型进行建模。在最大熵模型中,设计一组特征函数根据公式在最大熵模型框架下得到初始术语对齐分值:
其中,{λf}为对应特征的权重,通过GIS算法训练得到。
所述短语翻译概率h1由正向短语翻译概率和反向短语翻译概率根据下列公式计算得到:
所述词汇化翻译概率h2由正向词汇化翻译概率和反向词汇化翻译概率根据下列公式计算得到:
所述正向短语翻译概率、反向短语翻译概率、正向词汇化翻译概率和反向词汇化翻译概率均由GIZA++工具得到,训练语料为从中英维基百科抽取出中双语术语对。
所述共现概率h3根据下列公式从当前平行语料计算得到:
其中,count(*,*)为共现次数。
步骤430:根据所述初始术语对齐分值对初始术语对齐序列进行排序,获得初始术语对齐。
对齐初始术语其中表示第q个源句子术语对应第p个目标句子术语。
所有可能的术语对齐为源语言术语与目标语言术语组成的笛卡尔积因此需要对中的每种对齐按照步骤420进行打分,然后降序排列。本发明采用了维特比算法来加速排序过程。
在本实施例中,得到的初始术语对齐结果:[summary]::[摘要中的标头文本]};{[header]::[摘要中的标头文本],[summary]::[出现]};{[header]::[摘要中的标头文本],[summary]::[摘要中的标头文本]};{[header]::[出现],[summary]::[出现]}。
此外,为避免因术语识别错误而造成的对齐缺失,本发明对初始单语术语识别进行自动补全,具体规则为:如果识别出的源语言句子和目标语言句子中均没有术语,则将所述对齐的源语言词组中,有最大概率被识别为术语的词添加到初始源语言术语中;将所述对齐的目标语言词组中,有最大概率被识别为术语的词添加到初始目标语言术语中。
在本实施例中,补全后的初始目标语言术语{“出现”,“摘要中的标头文本”}。
在步骤500中,所述获得扩展后的初级双语术语候选列表的方法包括:
步骤510:以所述对齐初始术语对的源语言术语和目标语言术语为基准,建立一个滑动窗,并建立一系列扩展后的单语术语候选项。
所述滑动窗可以逐词向内缩减(1~4个词)或者向外扩展(1~4个词)。在本实施例中,扩展后的源语言单语术语为([header]→{[header text],[header text that],[header text that appears],[header text that appears in]};[summary]→{[summary],[the summary],[in the summary],[appears in the summary],[that appears in the summary]});扩展后的目标语言单语术语为([出现]→{[出现在]},[摘要中的标头文本]→{[在摘要中的标头文本],[摘要中的标头文本。],[摘要中的标头],[摘要中的],[摘要],[中的标头文本],[的标头文本],[标头文本],[文本]})。
步骤520:通过组合所述扩展后的单语术语候选项,获得双语术语翻译对的候选项。
根据所述步骤510对扩展后的源语言单语术语和目标语言术语进行对齐,得到扩展后的术语对齐结果。对齐时,需要根据步骤510的单语扩展的距离计算新的扩展后的单语术语识别概率。在本实施例中,假设源语言术语或者目标语言术语为为单语术语中第i个词,则单语句子为其中,dL和dR分别表示从左和从右扩展的距离,负值表示向里收缩,正值表示向外扩展。利用所述符号,单语术语识别概率计算公式为:
其中,P(*)表示初始单语术语识别概率,βf(1≤f≤4)为对应项权重。在本实施例中均取值为0.25。
步骤530:对所有所述翻译术语翻译对的候选项进行排序,根据规则删除不符合条件的双语术语候选项,获得初级双语术语候选列表。
在本发明中,根据规则删除不符合条件的双语术语候选项指删除任意两个有重叠部分的单语术语对应的双语术语候选项。在本实施例中,将删除得分较小的双语术语候选项,保留得分较大的双语术语候选项。
在步骤600中,所述获得修正的次级双语术语候选列表的方法包括:
步骤610:使用柱搜索算法,根据所述初级双语术语候选列表获得每次保留的K个最好的候选,获得最优的术语对齐序列。
搜索时,需要实时计算扩展后的初级双语术语对齐概率,即伸缩双语术语对齐概率其计算公式为:
其中,P(Lk|STq,TTp)为双语术语对按词对齐Lk的翻译概率,为双语术语伸缩模型。在本发明中,双语术语伸缩模型得分为源语言、目标语言的单语术语识别概率之积,计算公式为:
其中和分别为单语术语识别概率。
步骤620:从所述最优的术语对齐序列和所述对齐初始词中,根据规则删除不符合条件的对齐序列,获得修正的次级双语术语候选列表。
在本实施例中,得到的修正后的次级双语术语候选列表为({[header text]::[标头文本],[summary]::[摘要中]};{[header text]::[的标头文本],[summary]::[摘要]};…一共132(11×12)术语对)。
所述根据规则删除不符合条件的对齐序列与上述步骤530中提及的内容类似,在此不再详述。
在步骤700中,所述获得终极双语术语和终极对齐词的方法包括:
步骤710:构建一个空的词对齐候选列表。
步骤720:从所述次级双语术语候选列表中各种双语术语候选逐一选取,并以选取的双语术语候选为约束,利用基于隐马尔可夫的词对齐方法,生成K个最优的词对齐候选并添加到所述词对齐候选列表。
本实施例中,融合双语术语对齐后,隐马尔可夫词对齐模型为如下公式:
其中,I为目标句子长度,P(sj|t(aj))表示词的翻译概率,p(aj,Mk|aj-1,I)为融合双语术语对齐的词对位概率。
在隐马尔可夫词对齐模型中,词对位概率为P(aj|a(j-1),I)。令con flict(j,Mk)表示源语语言第j个词与目标语言第aj个词对应是否与双语术语对齐Mk是否冲突。如果冲突,则为true,否则为false。则融合双语术语对齐的词对位概率可推导为:
步骤730:利用柱搜索算法,结合所述次级双语术语候选列表,对所述词对齐候选列表对齐综合排序,获得K个最好的双语术语候选和词对齐候选,分别为终极双语术语和终极对齐词。
对所述词对齐候选列表对齐综合排序,公式(1)中的双语术语对齐模型可推导为:
本实施例中,结合公式(1)-(11),修正后的术语对重排序后得到({[header text]::[标头文本],[summary]::[摘要]};{[header text]::[的标头文本],[summary]::[摘要]};…);最终词对齐“NULL{6}出现{4}在{5}摘要{7}中{3}的{}标头{1}文本{2}。{8}”;最终术语对齐({[header text]::[标头文本],[summary]::[摘要]})。
通过上述技术方案可知,本发明的方法和装置具有如下的积极效果:
(1)由于在平行句对中,双语术语普通是边界统一的,即双语术语是成对出现的,因而,双语术语的词对齐有利于单语术语边界的确定,同时,双语术语的对齐也有利于词对齐的确定。因此,同时识别双语术语与词对齐能够突破单独进行双语术语识别或者词对齐的局限性,从而大幅提高双语术语与词对齐性能;
(2)本发明能够有效利用双语术语识别和词对齐知识,有效提高双语术语与词对齐性能,并提高最终的机器翻译译文质量,尤其是术语翻译质量。通过英中软件本地化翻译实验,结果表明,相对于单独识别双语术语和词对齐,本发明在单语术语识别F值提高在9个百分点以上,在双语术语对齐F值的提高在8个百分点以上,在词对齐F值的提高多于4个百分点;在术语翻译方面,正确率提高3.66个百分点;整体翻译质量方面,BLEU值提升0.38个百分点。效果提升较为明显。
其中,F值一个统计学概念,F值=2×(准确率×召回率)/(准确率+召回率);BLEU是一个双语评测替代指标。
此外,本发明还提供一种同时识别双语术语与词对齐的实现系统。如图4所示,本发明同时识别双语术语与词对齐的实现系统包括分词模块1、词对齐模块2、识别模块3、术语对齐模块4,初级列表确定模块5,次级列表确定模块6及终极确定模块7。
其中,所述分词模块1用于对一对源语言句子和目标语言句子进行分词,获得源语言词组和目标语言词组;所述词对齐模块2用于对所述源语言词组和目标语言词组进行词对齐,获得源语言句子到目标句子的对齐初始词;所述识别模块3用于分别识别所述源语言句子和目标语言句子中的术语,获得初始单语术语;所述初始单语术语包含初始源语言术语和初始目标语言术语;所述术语对齐模块4用于结合所述对齐初始词、初始单语术语,进行术语对齐,得到初始源语言术语到初始目标语言术语的对齐初始术语;所述初级列表确定模块5用于将所述对齐初始术语作为锚点,通过扩大或者收缩术语边界,获得扩展后的初级双语术语候选列表;所述次级列表确定模块6用于对所述初级双语术语候选列表进行双语术语识别,获得修正的次级双语术语候选列表;所述终极确定模块7用于对所述次级双语术语候选列表进行二次双语术语识别和词对齐,获得终极双语术语和终极对齐词。
优选地,所述识别模块3包括模型确定单元、计算单元、解码单元。
其中,所述模型确定单元利用源语言对应的维基百科单语语料训练获得源语言单语术语识别最大熵模型;利用目标语言对应的维基百科单语语料训练获得目标语言单语术语识别最大熵模型;所述计算单元根据所述源语言句子及所述源语言单语术语识别最大熵模型,获得源语言术语识别中间结果;根据所述目标语言句子及所述目标语言单语术语识别最大熵模型,获得目标语言术语识别中间结果;所述解码单元将所述源语言术语识别中间结果作为源语言术语识别解码器,解码所述源语言句子得到初始源语言术语;将所述目标语言术语识别中间结果作为目标语言术语识别解码器,解码所述目标语言句子得到初始目标语言术语。
相对于现有技术,本发明同时识别双语术语与词对齐的实现系统与上述同时识别双语术语与词对齐的实现方法的有益效果相同,在此不再赘述。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!