本发明属于数据挖掘领域,特别涉及一种海量文本中企业行为或事件的抽取方法。
背景技术:
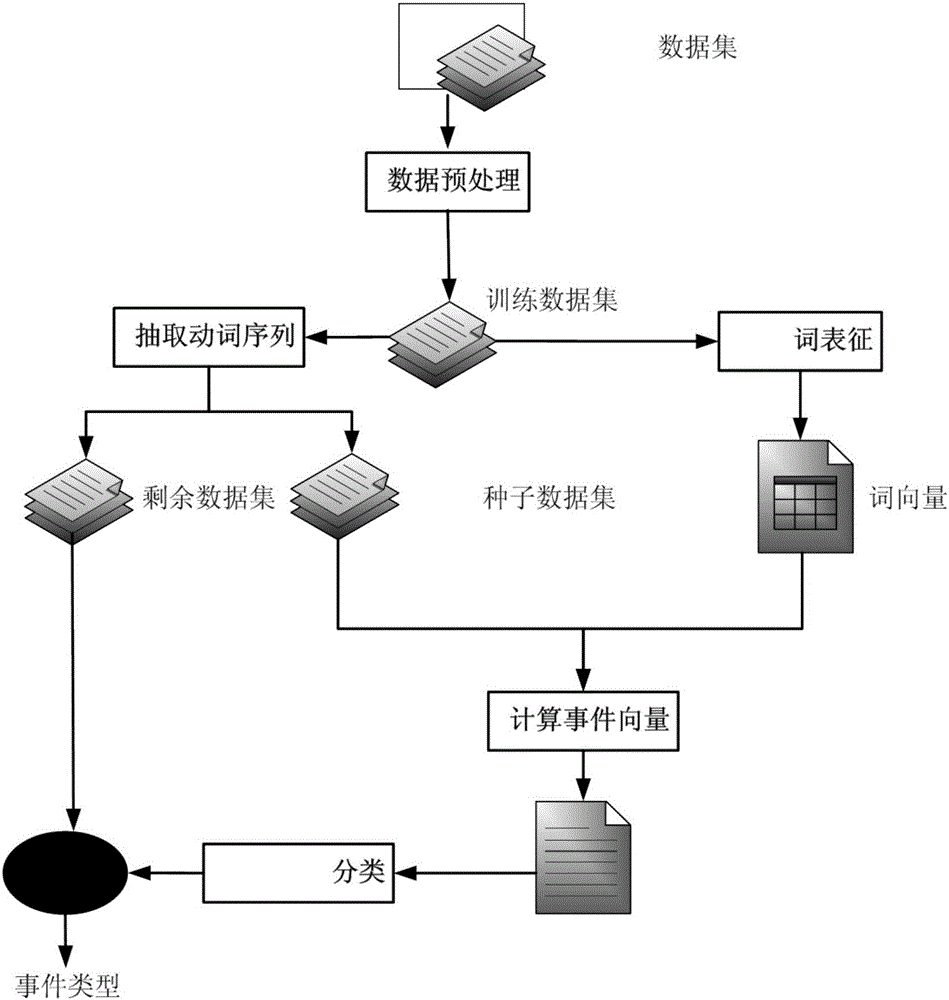
:随着信息技术和计算机科学的飞速发展,社交媒体(又称社会化媒体)展示出巨大的潜力,以微博为例,普通用户可以在平台上进行关注、点赞、分享、转发等行为,而许多企业更是充分利用官方微博进行信息发布、营销推广、粉丝互动等,从海量数据中挖掘商业信息,从而制定出更好的商业策略,同时企业的官方微博也包含了企业的相关行为信息,这些行为信息同样具有潜在的商业价值和应用研究价值,因此从海量数据中提取企业行为信息并将这些应用到商业领域是一件非常有意义的研究主题。最近几年,越来越多的企业利用社交媒体平台发布、获取信息,以及沟通、合作、建立关系,同时也有很多学者研究企业微博,然而,大多数学者关注于企业微博的商业价值、企业微博的营销推广对用户的影响、以及影响企业营销的因素;仅仅少数的学者通过数据挖掘提取企业行为,但是选择分类方法效果并不理想。由于微博提供了丰富的、及时的企业微博信息,这也可用于研究企业微博信息与企业当前情况的影响关系,同时,这些组织的企业行为信息可以用于商业战略制定、粉丝关系维系以及预测企业未来方向等,比如,趋势预测、内容推荐等。然而,在虚拟的社交媒体中确定企业事件,提取企业行为,仍然存在一些挑战,主要包括以下两个问题,第一,数据存在噪音、且形式种类多样;第二,许多信息掺杂多个主题,分类器难以确定标签。技术实现要素:【要解决的技术问题】本发明的目的是提供一种海量文本中企业行为或事件的抽取方法,以有效的从海量数据中提取企业的行为标签。【技术方案】本发明是通过以下技术方案实现的。本发明涉及一种海量文本中企业行为或事件的抽取方法,其包括以下步骤:A、数据预处理从网络中获取目标数据,并将这些数据内容进行预处理形成数据集;B、词表征将预处理形成的数据集中的单词映射到k维的空间向量中,k为预设的维度范围;C、事件向量计算从预处理后的数据集中抽取动词序列,计算所有动词序列的平均词向量,人工标注若干条种子标签,计算同一标签相同事件的平均种子向量;D、事件提取分类通过计算剩余数据集和事件向量的相似度来确定每一条微博数据记录的分类。作为一种优选的实施方式,所述步骤B将预处理后形成的数据集放入word2vec模型中训练得到k维空间向量。作为另一种优选的实施方式,所述步骤C中采用cosine相似度计算法计算剩余数据集和事件向量的相似度。作为另一种优选的实施方式,所述步骤A中的预处理至少包括分词处理和数据清理。作为另一种优选的实施方式,所述分词处理包括通过文本中的句号、问号和感叹号进行文本切分。作为另一种优选的实施方式,所述数据清理包括删除一字词、停用词、以及删除重复的记录。作为另一种优选的实施方式,所述步骤A中的目标数据采用爬虫技术爬取得到。下面将对本发明进行详细说明。企业的官方微博通过社交媒体平台发布相关信息,这些企业的微博记录大部分都包含了企业的事件。由于微博的140字的长度限制(现已取消),本发明假设每一条微博记录最多包含一类事件,即假设企业行为事件有n类,表示为E={e1,e2,…,en}式(1)在上述这些事件中,第i类事件都能被一组向量表示,即表示为ei=(vi1,vi2,…,vim).式(2)在本发明中,目标是提供一个能够自动提取企业事件的模型框架,这些企业事件信息被隐含在企业的官方微博中,即表示为Weibo={weibo1,weibo2,…,weibol},因此,本发明需要解决的问题是,如何确定一篇新的微博文章weiboi属于E中的哪一类行为事件。为了解决上述问题,本发明提供的方法主要包括如下四个部分:数据预处理、词表征训练、事件聚类、事件识别。数据预处理是将微博爬取的数据集进行分词、删除一字词停用词以及数据清理。词表征训练,将词当做特征,用Word2vec把特征训练位高维空间向量。计算事件向量,利用种子数据集和动词词向量进行每一事件类型的向量计算。最后,利用分类器将剩余数据集进行分类。下面分别对上述四个部分进行介绍。(一)数据预处理由于微博数据具有强噪音和模糊性,且数据类型多样等特点,因此,数据预处理是实验过程中非常重要的一个步骤,这里包括了3个预处理步骤:爬取微博数据、分词处理、数据清理。爬取微博数据。对于这个环节,爬取的对象可以是国产手机市场占有率前十的企业的官方微博(华为、小米、魅族、中兴、联想、酷派、OPPO、VIVO、HTC、TCL),除此之外,很多工具都可以用于在开发信息网络下的数据爬取。分词处理。由于中文不像英文,每个词都是自动分开,所以需要对文档进行分词处理,这样可以确定词的词性,也便于后续实验的进行,在分词之后,微博记录集被表示为Weiboi={wi1,wi2,…,wik}式(3)数据清理。由于中文文本中经常包含大量无意义的词,所以非常有必要进行数据清理。数据清理是发生在分词之后,这个过程主要包括删除一字词、停用词、以及删除重复的记录,以便于获得更好是抽取结果。最后wij表示文档weiboi中在数据预处理后第j个位置上的词,而爬取的所有文档形成的数据集则用weibos表示。(二)词表征对于词表征WE,即即表示,将wi单词映射到k维空间向量(维度范围:50—500),近年来很多研究提供了大量的词表征实现方法,尤其是Mikolov发表的CBOW模型(ContinuousBag-of-WordModel)和Skip-gram模型(ContinuousSkip-gramModel)。具体地,可以使用Skip-gram模型,假定训练的词ws=(ws1,ws2,…,wsT),训练目标为最大化概率其中wsi表示ws中第i个词,p(wsj|wsi)表示出现词wsi条件下出现wsj的概率。将所有数据预处理后的原始数据集放入word2vec模型中训练,因为这种方法不仅仅能够捕获词之间的位置关系,还包括词的语义关系。(三)事件向量计算由于行为事件用动词表示,所以在计算事件向量之前,本发明从预处理后的数据集抽取了动词序列,则Weiboi可简化表示为Weiboi={vi1,vi2,…,vik′}式(6)其中vij(j=1,2,...,k′)是weiboi中第j个动词。而被训练的词向量有一个有趣的线性性质,例如,用有效的向量空间向量表示词,计算向量等等,因此本发明通过计算单词的平均词向量来表示一条微博,由于本发明需要计算事件向量,所以本发明选择了所有动词的平均词向量来表示一个微博,计算方法如下:其中Qi表示weiboi中动词的总量。为了表示事件,需要人工标注若干条种子标签,每条数据记录最多包含一种事件类型,在人工标注完成后,获得了两组种子事件数据集,然后计算同一标签相同事件的平均种子向量,表示为其中i表示标签类型,Ri表示i类标签的种子总数,seedij表示i类标签第j条种子微博记录。(四)事件提取分类在计算出每一类事件的向量ei后,将完成分类任务,通过计算剩余数据集和事件向量的相似度来确定每一条微博数据记录的分类,而本发明选择的相似度计算方法可以是cosine相似度计算法,表示为基于cosine相似度计算,用i*事件提取后应该给微博记录打上的标签,给sim(weibok,ei)设定一阈值用u表示,如果sim(weibok,ei)的最大值小于阈值u,这将此条微博记录标为其他类(NULL),表示此微博记录没有包含事件。如果sim(weibok,ei)高于阈值u,将此微博标签为相似度最高的事件的标签。【有益效果】本发明提出的技术方案具有以下有益效果:本发明使用向量表示事件和微博,所以基于事件的相似度,本发明能够有效地计算相似度和分类一条新的微博数据。同时,本发明检测微博事件的精确度、召回率、和F值要远优于现有技术中的方法。附图说明图1为本发明的实施例一提供的海量文本中企业行为或事件的抽取方法的流程图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的具体实施方式进行清楚、完整的描述。实施例一图1为本发明实施例一提供的海量文本中企业行为或事件的抽取方法的流程图。如图1所示,该方法包括数据预处理、词表征、事件向量计算和事件提取分类,下面对各个步骤进行详细说明。(1)数据预处理从网络中获取目标数据,并将这些数据内容进行预处理形成数据集,具体地,本实施例爬取的对象是国产手机市场占有率前十的企业的官方微博(华为、小米、魅族、中兴、联想、酷派、OPPO、VIVO、HTC、TCL),一共爬取了88874条微博。其中,通过采用爬虫技术从网络中爬取目标数据,预处理包括分词处理和数据清理,分词处理包括通过文本中的句号、问号和感叹号进行文本切分,数据清理包括删除一字词、停用词、以及删除重复的记录。(2)词表征将预处理形成的数据集中的单词映射到k维的空间向量中,k为预设的维度范围,其取值为50~500。具体地,该步骤将预处理后形成的数据集放入word2vec模型中训练得到k维空间向量。(3)事件向量计算在计算事件向量之前,首先从预处理后的数据集抽取了动词序列,则Weiboi可简化表示为Weiboi={vi1,vi2,…,vik′}其中vij(j=1,2,...,k′)是weiboi中第j个动词。然后计算单词的平均词向量来表示一条微博,由于本发明实施例需要计算事件向量,所以本发明实施例选择了所有动词的平均词向量来表示一个微博,计算方法如下:其中Qi表示weiboi中动词的总量。为了表示事件,需要人工标注若干条种子标签,本实施例通过邀请一名志愿者根据自身的理解人工标注了1000条种子标签,每条数据记录最多包含一种事件类型,在人工标注完成后,获得了两组种子事件数据集,然后计算同一标签相同事件的平均种子向量,表示为其中i表示标签类型,Ri表示i类标签的种子总数,seedij表示i类标签第j条种子微博记录。(4)事件提取分类通过采用cosine相似度计算法计算剩余数据集和事件向量的相似度来确定每一条微博数据记录的分类。具体地,在计算出每一类事件的向量ei后,将完成分类任务,通过计算剩余数据集和事件向量的相似度来确定每一条微博数据记录的分类,而本发明实施例选择的相似度计算方法可以是cosine相似度计算法,表示为基于cosine相似度计算,用i*事件提取后应该给微博记录打上的标签,给sim(weibok,ei)设定一阈值用u表示,如果sim(weibok,ei)的最大值小于阈值u,这将此条微博记录标为其他类(NULL),表示此微博记录没有包含事件。如果sim(weibok,ei)高于阈值u,将此微博标签为相似度最高的事件的标签。验证实验本次实验的数据集来自于微博网站http://weibo.com,数据对象是国内知名手机企业官方微博(企业包括华为、小米、魅族、中兴、联想、酷派、OPPO、Vivo、HTC和TCL),爬取数据记录总共有88874条,数据具体信息如表1所示。表1.微博爬取数据集统计表2.语料库中词相关数据统计邀请一名志愿者随机读取微博数据记录,并根据他对微博内容的理解给其打标签,选择两组已经打好标签的数据集,第一组包含了五类,分别是推广、发售、研发、合作、招募,另一组数据包括四类,分别是推广、销售、研发和合作,每一组种子数据集包括1000条微博记录,每一类型总数一样。采用实施例二中的方法进行抽签,其中采用word2vec训练词表征,在训练过程中,word2vec不需要预置标签,它能将词表征映射到k维的空间向量中。在Python3.5环境中运行word2vec,参数选择如下所示:向量维度Vectordimension=1000;内容的窗口大小size=5;选择模型:Skip-gram。将实施例二中的方法与词袋(BOW),TFIDF(termfrequency–inversedocumentfrequency)+BOW、TFIDF加权以及LDA(LatentDirichletAllocation)进行对比实验。BOW:选择了高频词形成词袋向量,在实验中,选择了前100个高频词。TFIDF+BOW:计算数据集中每个词的TFIDF值,选择其中100个最高的TFIDF值的词去形成词袋向量。.TFIDF_weighted:选择的词方式与TFIDF+BOW一致,但是向量每一维的值等于对应词语在该句中的TFIDF值。LDA:将所有的种子数据集放入到LDA模型中运行,每组实验数据都得到10个主题,然后以最高的比例作为其类相关的主题,比例计算如下所示当一篇新的文档被投入到LDA模型中,根据种子训练的模型计算该文档的话题分布,然后将该微博分类到概率最大的话题下。由于本发明实施例分别计算了两组事件向量,使用微博中所有动词平均向量去表示一条微博记录,然后计算每个事件向量与剩余每一条数据集的cosine相似度,取其中的最大值,以最大值的事件标注这一条数据集的事件,如果cosine最大值也低于0.2,即此条数据集不包含事件行为,被标为其他类。邀请先前的志愿者随机标注了2组微博数据,每组数据均为300条,作为每一组的基准数据集,并将精确度(precision)、召回率(recall)、F值(F_value)作为分类器的评价指标,计算方法如下表。四种可能的分类计算结果如下(表3),具体地,按照以下方式计算精确度(9)、召回率(10)和F值(11):表3.第i种方法对应第j种事件的预测结果在实验中,如果其中的微博数据的相似度没有超过阈值,将给这条微博标为空类,其他类意味着,这条微博数据不包含事件,在本发明中,阈值被设为0.2,分类结果如下表所示。表4.第一组六类标签的精确度类别Word2VecBag_of_WordsTFIDFTFIDF_WeightedLDA(10)发售0.7441860.250.2083330.1384620.089552合作0.6595740.3103450.3333330.2857140推广0.4235290.20.2105260.2413790研发0.5362320.2894740.2352940.280招募0.7037040.0588240.1923080.250空类00.1666670.1491230.1588790.058824表5.第一组六类标签的召回率表4和表5展示第一组数据结构,从两张表中可以看出,对于精确度和召回率,本发明方法在前五类标签都明显优于其他四种方法,尤其是发售和招募的精度都超过70%,即使是推广类精度仅有42.35%也远超于其他四种方法,而对于召回率,前五类召回率都超过50%,招募类甚至达到了70.37%。在第一组实验中,对于前五类标签的精确度和召回率本发明方法明显优于其他四种方法。表6和表7是第二组实验结果,尽管第二组实验结果的总体效果不如第一组结果,但是本发明提供的方法在前四类标签仍然明显优于其他四种方法,除了推广类标签,其他三类标签的精确度都超过50%,而对于召回率,除了合作类,其他三类标签页都超过50%,最高的甚至达到了66.67%表6.第二组五类标签的精确度类别Word2VecBag_of_WordsTFIDFTFIDF_WeightedLDA(10)合作0.5862070.2121210.30.250.240741推广0.4631580.3285710.4242420.3709680.25销售0.6034480.1750.2352940.3333330研发0.5454550.3225810.224490.2352940.363636空类00.1052630.0961540.1274510.064039表7.第二组五类标签的召回率类别Word2VecBag_of_WordsTFIDFTFIDF_WeightedLDA(10)合作0.4788730.0985920.1267610.0985920.183099推广0.6666670.3484850.4242420.3484850.015152销售0.5072460.1014490.1739130.2753620研发0.6486490.270270.1486490.1621620.054054空类00.50.50.650.65综合来看,本发明方法的平均结果在五类分类方法中效果最优,指标为精确度(precision)、召回率(recall)、和F值(F_value)。根据来自于微博数据的实验结果,本发明方法远优于其他四类方法。综上,由于本发明使用向量表示事件和微博,所以基于事件的相似度,本发明能够有效地计算相似度和分类一条新的微博数据。同时,本发明检测微博事件的精确度、召回率、和F值要远优于其他方法。当前第1页1 2 3