本发明属于深度学习与进化算法领域的结合,主要解决深度神经网络的参数优化问题,具体提供一种基于协同进化和反向传播的深度神经网络优化方法,实现深度神经网络参数的优化。
背景技术:
20世纪80年代以来,神经网络(Neural Network,NN)进入了发展的快车道,新的科学理论的重大突破和高性能计算机的飞速发展使NN重焕生机。1982年加利福利亚理工学院的教授Hopfield提出了著名的Hopfield神经网络模型,从而有力地推动了NN的研究。到了八十年代中期,Ackley,Hinton和Sejnowski,在Hopfield NN模型中基于模拟退火思想引入了随机机制,并基于此模型分析了生物计算与传统的AI计算之间的区别,提出了Boltzmann机,为NN优化计算跳出局部极小值提供了一个有效的方法,第一次成功实现了多层神经网络的功能,并明确了NN中的隐单元的概念。第二年,反向传播算法(Back-Propagation algorithm,BP)获得进展,Rumelhart和McClelland提出的并行分布处理理论对反向传播算法的应用产生了重要影响。这两种模型或理论,对神经网络的发展具有非常重要的作用和意义。
近些年来,神经科学研究人员发现,哺乳类动物的大脑皮质,在传递表示信息时,大脑皮质未曾对感官信号数据直接进行特征提取处理,接收到的刺激信号经过一个复杂的层状神经元网络时,呈现的特征会被逐层识别出来,然后每层的特征作为下一层的输入信号,逐层进行处理后再次传递。人脑是根据经过聚集和分解处理后的外部世界感知信息对物体进行识别,这种感知系统的层次结构极大降低了神经系统的数据处理量,同时仍保留了有效的物体结构。而深度学习神经网络系统,也是通过组合低层特征形成更加抽象的高层表示属性类别或特征,最后得到数据的分布式特征表示的一种特殊网络模型-深度神经网络(Deep Neural Network,DNN)。DNN在很多领域都有着应用,例如:语音识别,文本图像分类,天气预测,人脸识别等等。
目前的深度神经网络的优化算法,一种是:基于梯度的反向传播算法,该算法随着网络结果和数据的复杂性的增加,容易陷入局部最优解;另一种是进化算法,由于参数维数的不断增加,传统的进化算法不再适用。
随着数据规模的不断增加,在处理这种大规模,无序的数据集时,人们越来越发现深度神经网络的优势,深度神经网络必将有着更好的前景。
技术实现要素:
本发明的目的是克服上述已有技术的不足,提供一种基于协同进化和反向传播的深度神经网络优化方法,避免了反向传播算法容易陷入局部最优解的缺陷,同时也利用反向传播算法快速有效的优点,提高进化算法的搜索速度,通过一种迭代方式将这两种方法的优点很好的结合到一起来优化深度神经网络的参数。
为此,本发明提供了基于协同进化和反向传播的深度神经网络优化方法,包括如下步骤:
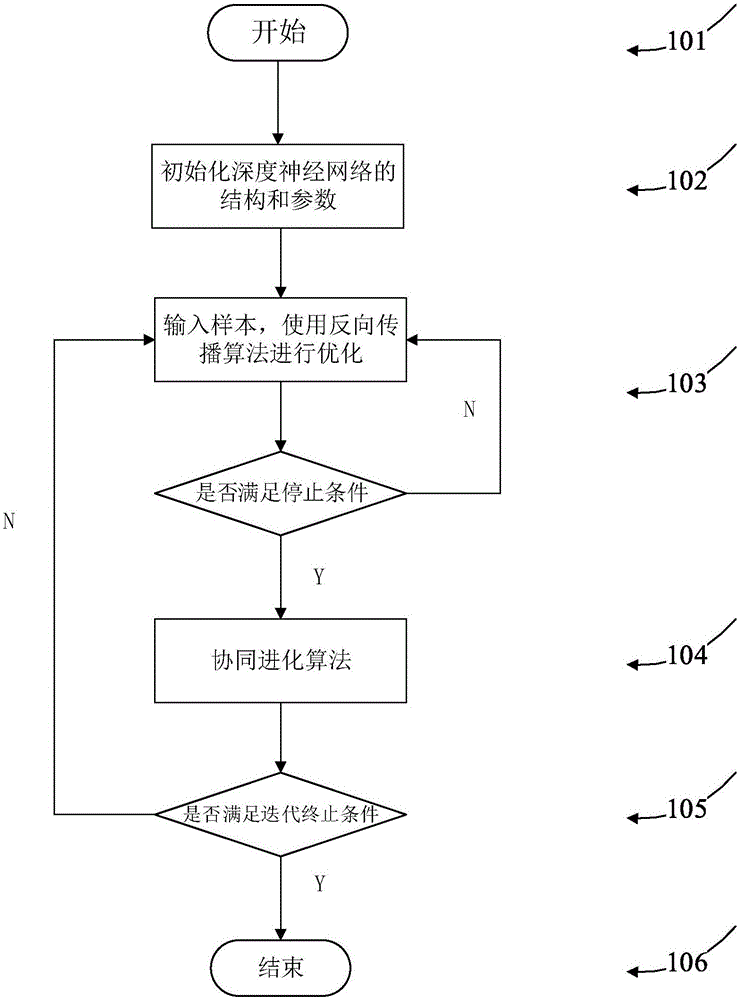
步骤101:开始基于协同进化和反向传播的深度神经网络优化方法;
步骤102:设定一个深度神经网络结构,用Li表示网络的第i层,Ni表示第i层的节点个数,初始化权重W和偏差b,设置学习率η,自定义参数H;
步骤103:向步骤102的深度神经网络输入训练样本,然后使用反向传播算法对深度神经网络进行训练,直到深度神经网络连续两次的迭代误差变化值σ在范围[0,H]内,停止反向传播算法;
步骤104:采用协同进化算法对步骤103中采用反向传播算法训练的权重和偏差进行优化;
步骤105:采用协同进化算法优化完权重和偏差之后,继续使用反向传播算法进行优化,直到深度神经网络连续两次的迭代误差变化值σ在范围[0,H]内,停止反向传播算法,再次使用协同进化算法进行优化,不停的进行迭代,最后直到迭代次数为50次,迭代终止;
步骤106:得到深度神经网络的优化参数,即权重和偏差。
所述的步骤103,包括如下步骤:
步骤301:开始反向传播算法;
步骤302:输入训练样本到深度神经网络,计算训练样本的误差,根据误差的梯度来反向调整深度神经网络每一层的权重:
其中,W是调整前的权重,W′是调整后的权重,E是误差,η是学习率;
步骤303:每次迭代,随机选取Ds个样本,根据步骤302中的权重调整公式来不断更新权重;
步骤304:计算连续两次迭代的误差变化σ,当0≤σ≤H时,停止反向传播算法的迭代过程;
步骤305:结束反向传播算法。
所述的步骤104,包括如下步骤:
步骤401:开始使用协同进化算法对深度神经网络进行优化;
步骤402:在反向传播算法得到的权重基础上,使用协同进化算法进行优化,将深度神经网络按层按节点划分为子问题;
步骤403:计算划分后的每个子问题的成熟度M,并将这些成熟度按照从小到大的顺序进行排序,选取成熟度排在前30%的子问题使用差分进化算法进行优化;
步骤404:采用差分进化算法优化完成之后,选取最优的解去替换步骤402的权重中相应位置的参数,直到所有被选取的子问题被优化完成;
步骤405:结束协同进化算法。
所述的步骤105,包括如下步骤:
步骤501:再次开始反向传播算法;
步骤502:如果连续两次的迭代误差值σ在范围[0,H]内,停止反向传播算法,开始进行协同进化;
步骤503:按照步骤402将深度神经网络按层按节点划分为子问题,再按照步骤403进行子问题的选取,然后使用差分进化算法对这些子问题进行优化,选取最优的解来替换步骤502的权重中对应的参数;
步骤504:再次开始反向传播算法,然后不断的重复步骤502和步骤503,最后直到迭代次数为50次,迭代终止;
步骤505:结束基于协同进化和反向传播的深度神经网络优化方法。
所述的步骤103和步骤304中的误差变化σ:
σ=|E(t)(x)-E(t-1)(x)|
其中,E(t)(x)和E(t-1)(x)分别是第t次和第t-1次迭代的误差。
所述步骤403中的成熟度M的定义:
其中,Mi是第i个子问题的成熟度,N是样本的数量,表示第j个样本在第i个子问题上的输出,函数g(x)的定义如下:
其中,α是一个自适应参数,可以被设置成0.3或0.4。
本发明的有益效果:1、本发明是针对反向传播算法在训练参数的过程中容易陷入局部最优解的缺点,并且由于网络的参数维数太大,单独使用传统的进化算法根本没有办法对其进行优化,因此提出了一种结合协同进化和反向传播算法的方法来优化网络,使得能够更好的优化深度神经网络的参数。
2、本发明将进化算法的优点应用到深度神经网络的训练中,针对大规模的参数,使用协同进化进行优化,同时结合反向传播算法,并且设计一种选择策略,来提高协同进化的优化速度,使得整个网络能够更高效的被训练完成;
3、仿真结果表明,本发明采用的基于协同进化和反向传播的深度神经网络优化方法,优化性能好,提高了网络的分类正确率。
以下将结合附图对本发明做进一步详细说明。
附图说明
图1是基于协同进化和反向传播的深度神经网络优化方法的主流程图;
图2是反向传播算法(BP)的流程图;
图3协同进化的流程图;
图4是手写数字识别数据集的一些样例,每个小的数字图片大小为28*28;
图5是在神经网络的结构:784-300-100-10时,反向传播算法(BP)和本申请的方法(BP-CCDE)的比较,只进行一次协同进化,在迭代次数iter=4时,开始进行协同进化,纵坐标表示average error,横坐标表示迭代次数;
图6是在神经网络的结构:784-300-100-10时,反向传播算法(BP)和本申请的方法(BP-CCDE)的比较,进行了两次协同进化,在迭代次数iter=4和iter=19时,分别开始进行协同进化,纵坐标表示average error,横坐标表示迭代次数。
图7是在神经网络的结构:784-500-300-10时,反向传播算法(BP)和本申请的方法(BP-CCDE)的比较,只进行一次协同进化,在迭代次数iter=12时,开始进行协同进化,纵坐标表示average error,横坐标表示迭代次数;
图8是在神经网络的结构:784-500-300-10时,反向传播算法(BP)和本申请的方法(BP-CCDE)的比较,进行了两次协同进化,在迭代次数iter=12和iter=24时,分别开始进行协同进化,纵坐标表示average error,横坐标表示迭代次数。
具体实施方式
下面结合附图和实施例对本发明提供的基于协同进化和反向传播的深度神经网络优化方法进行详细的说明。
本发明提出了一种基于协同进化和反向传播的深度神经网络优化方法,包括如下步骤:
步骤101:开始基于协同进化和反向传播的深度神经网络优化方法;
步骤102:设定一个深度神经网络结构,用Li表示网络的第i层,Ni表示第i层的节点个数,初始化权重W和偏差b,设置学习率η,自定义参数H;
步骤103:向步骤102的深度神经网络输入训练样本,然后使用反向传播算法对深度神经网络进行训练,直到深度神经网络连续两次的迭代误差变化值σ在范围[0,H]内,停止反向传播算法;
步骤104:采用协同进化算法对步骤103中采用反向传播算法训练的权重和偏差进行优化;
步骤105:采用协同进化算法优化完权重和偏差之后,继续使用反向传播算法进行优化,直到深度神经网络连续两次的迭代误差变化值σ在范围[0,H]内,停止反向传播算法,再次使用协同进化算法进行优化,不停的进行迭代,最后直到迭代次数为50次,迭代终止;
步骤106:得到深度神经网络的优化参数,即权重和偏差。
所述的步骤103,包括如下步骤:
步骤301:开始反向传播算法;
步骤302:输入训练样本到深度神经网络,计算训练样本的误差,根据误差的梯度来反向调整深度神经网络每一层的权重:
其中,W是调整前的权重,W′是调整后的权重,E是误差,η是学习率;
步骤303:每次迭代,随机选取Ds个样本,根据步骤302中的权重调整公式来不断更新权重;
步骤304:计算连续两次迭代的误差变化σ,当0≤σ≤H时,停止反向传播算法的迭代过程;
步骤305:结束反向传播算法。
所述的步骤104,包括如下步骤:
步骤401:开始使用协同进化算法对深度神经网络进行优化;
步骤402:在反向传播算法得到的权重基础上,使用协同进化算法进行优化,将深度神经网络按层按节点划分为子问题;
步骤403:计算划分后的每个子问题的成熟度M,并将这些成熟度按照从小到大的顺序进行排序,选取成熟度排在前30%的子问题使用差分进化算法进行优化;
步骤404:采用差分进化算法优化完成之后,选取最优的解去替换步骤402的权重中相应位置的参数,直到所有被选取的子问题被优化完成;
步骤405:结束协同进化算法。
所述的步骤105,包括如下步骤:
步骤501:再次开始反向传播算法;
步骤502:如果连续两次的迭代误差值σ在范围[0,H]内,停止反向传播算法,开始进行协同进化;
步骤503:按照步骤402将深度神经网络按层按节点划分为子问题,再按照步骤403进行子问题的选取,然后使用差分进化算法对这些子问题进行优化,选取最优的解来替换步骤502的权重中对应的参数;
步骤504:再次开始反向传播算法,然后不断的重复步骤502和步骤503,最后直到迭代次数为50次,迭代终止;
步骤505:结束基于协同进化和反向传播的深度神经网络优化方法。
所述的步骤103和步骤304中的误差变化σ:
σ=|E(t)(x)-E(t-1)(x)|
其中,E(t)(x)和E(t-1)(x)分别是第t次和第t-1次迭代的误差。
所述步骤403中的成熟度M的定义:
其中,Mi是第i个子问题的成熟度,N是样本的数量,表示第j个样本在第i个子问题上的输出,函数g(x)的定义如下:
其中,α是一个自适应参数,可以被设置成0.3或0.4。
需要说明的是:反向传播算法(英:Backpropagation algorithm,简称:BP算法)是一种监督学习算法,常被用来训练多层感知机。反向传播算法(BP算法)主要由两个环节(激励传播、权重更新)反复循环迭代,直到网络的对输入的响应达到预定的目标范围为止。差分进化算法是一种新兴的进化计算技术,和其它演化算法一样,DE(差分进化算法的外文缩写)是一种模拟生物进化的随机模型,通过反复迭代,使得那些适应环境的个体被保存了下来。但相比于进化算法,DE保留了基于种群的全局搜索策略,采用实数编码、基于差分的简单变异操作和一对一的竞争生存策略,降低了遗传操作的复杂性。同时,DE特有的记忆能力使其可以动态跟踪当前的搜索情况,以调整其搜索策略,具有较强的全局收敛能力和鲁棒性,且不需要借助问题的特征信息,适于求解一些利用常规的数学规划方法所无法求解的复杂环境中的优化问题。进化算法是一种成熟的具有高鲁棒性和广泛适用性的全局优化方法,具有自组织、自适应、自学习的特性,能够不受问题性质的限制,有效地处理传统优化算法难以解决的复杂问题。
以上三种算法都是现有的成熟的技术,其具体的定义和操作过程在此不作详细的叙述。
本发明的效果可以通过以下仿真实验进一步说明:
1、仿真参数
对于手写数字识别数据集进行分析,可进行定量的结果分析:
①平均误差:所有样本的平均误差,不同算法下的样本误差;
②分类正确率:测试样本的正确分类的个数比上测试样本的总的个数。
2、仿真内容
本发明方法首先对手写数字识别数据集训练,只使用反向传播算法(BP)和本方法(BP-CCDE)进行比较,比较平均误差和分类正确率。
3、仿真实验结果及分析
手写数字识别数据集如图4所示,每个样本的大小为28*28,训练样本一共60000个,测试集10000个,下面对两种不同隐含层节点数的网络进行验证。
1.深度神经网络的结构:784-300-100-10,含有两个隐含层,在同样的结构和初始化的条件下;通过BP和BP-CCDE的平均误差结果如图5所示,其中,实线和虚线分别表示BP和BP-CCDE方法随着BP的迭代次数,平均误差的变化;可见在加入协同进化之后,误差有一个明显的下降,图5中在iter=4时,开始使用协同进化。在图6中,使用了两次协同进化,平均误差都有一个明显的下降,分别是iter=4和iter=19时,可以看出引进协同进化之后,能够使得误差下降明显。使用BP和BP-CCDE方法对手写数字识别在不同的协同进化次数下的分类正确率如表1所示。
表1 BP和BP-CCDE方法对手写数字识别的分类正确率
表1中BP的迭代次数iter=50,K表示协同进化的使用次数;从表1中可以看出,在进行协同进化之后,本发明方法的分类正确率明显高于BP算法。
2.深度神经网络的结构:784-500-300-10,含有两个隐含层,在同样的结构和初始化的条件下;通过BP和BP-CCDE的平均误差结果如图7所示,其中,实线和虚线分别表示BP和BP-CCDE方法随着BP的迭代次数,平均误差的变化,图7中在iter=4时,开始使用协同进化。在图8中,使用了两次协同进化,平均误差都有一个明显的下降,分别是iter=6和iter=23时,使用协同进化。使用BP和BP-CCDE方法对手写数字识别在不同的协同进化次数下的分类正确率如表2所示。
表2 BP和BP-CCDE方法对手写数字识别的分类正确率
表2中BP的迭代次数iter=50,K表示协同进化的使用次数;从表2中可以看出,在不同网络结构下,在进行协同进化之后,本发明方法的分类正确率明显高于BP算法。随着协同进化方法的次数的增加,正确率也在不断增加,可以看出本方法对于深度神经网络的参数优化有着明显的优势。
以上例举仅仅是对本发明的举例说明,并不构成对本发明的保护范围的限制,凡是与本发明相同或相似的设计均属于本发明的保护范围之内。本实施例没有详细叙述的部件和结构属本行业的公知部件和常用结构或常用手段,这里不一一叙述。