一种基于字典的改进分形编码水声图像压缩算法的制作方法
本发明涉及一种基于字典的改进分形编码水声图像压缩算法,属于图像压缩与处理领域。考虑到传统的分形编码方式编码时间长,每次图像进行编码都要在原图像基础上重新生成字典(又称码本),不同的图像具有不同的字典,即使同一幅图像,不同的分割方式也产生不同的字典,针对上述问题本发明采用固定字典的方法进行分形编码,并从字典的生成、扩充及分类三方面来改进分形编码算法。
背景技术:
分形编码在分形几何理论和迭代函数系统(IFS)的基础上发展起来的一种图像压缩方法。它充分利用了图像中普遍存在的局部自相似性,用一组在编码过程中得到的压缩变换参数来表示原图像,使压缩变换的吸引子与原图像充分接近。这个变换反映了图像中局部与局部间的相似性。分形编码具有压缩比高、解码图像与分辨率无关和解码速度快的优点,但也有其不足之处:计算量大,编码速度慢、解码图像质量不佳等。
目前国内外学者对如何提高分形编码的编码速度研究主要有以下几个方向:① 分类匹配② 优化搜索范围③ 采用固定码本这三种手段。分形编码过程中最耗时的环节是对每一个值域块在整个定义域范围内进行最佳匹配块搜索,因此,要减少编码时间,就必须缩小搜索范围,且保证最佳匹配块位于缩小后的范围内,故多数研究者关注的重点是如何构建高效合理的值域块匹配空间。
本发明考虑采用固定字典的方法进行分形编码。采用字典法进行编码最关键的环节是字典的生成、扩充及分类。以往的方法生成的字典不够丰富,存在分类过少或过多的问题,此外字典的尺寸只有一种,只能适用于4×4分割。为此,本发明对字典的生成、扩充和分类方法进行改进,生成了三种不同尺寸的字典,同时增加字典的丰富性及对水声图像的适应性。
技术实现要素:
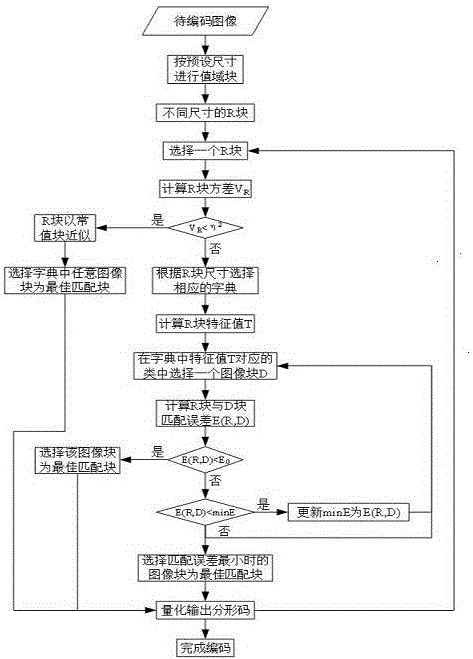
本发明利用分形集的丰富性生成大量形状和纹理不同的图像,对这些图像进行分割生成不同尺寸的图像块,之后对图像块进行扩充、分类不同尺寸的图像块集合作为字典。编码时,原图像只需进行值域块分割,对每分割后的每个R,按字典分类时的规则计算其特征值,然后在该特征值所对应的字典某一类中进行匹配搜索,记录搜索到最佳匹配块在字典中的位置、对比度因子和灰度偏移量作为分形码,字典的生成及编码流程图见说明书附图1所示。解码时,根据分形码找到每一个R块在字典中的最佳匹配块,只需要一次变换即可恢复。
本发明的实现包括如下步骤:
步骤一:字典生成。
为了使各式各样的图像块都能在字典中找到理想的匹配块,字典中的块必须足够的丰富且具有非常广泛的代表性。字典生成的关键问题是如何获得更丰富多样的图像块,本发明字典的生成包括:Julia分形集图像生成,字典生成及扩充。
步骤二:编码。
包含以下具体步骤:
(1)载入生成的字典。
(2)设置R块阈值,匹配误差阈值 。
(3)对图像进行值域块分割。
(4)根据值域块分割尺寸选择相应尺寸的字典作为匹配搜索时的码本。
(5)对于每一个R块,计算其方差
(6)对所有R块执行步骤(5),量化分形码,输出形成编码文件。
步骤三:解码。
与现有技术相比,本发明的有益效果是:由于每个R块仅在字典中所属的类中进行搜索,匹配次数比基本算法大幅减少,具有更快的编码速度,比基本算法平均提高了351倍。此外,字典法解码只需一次迭代,因此具有极快的解码速度,比基本算法提高了12倍。在压缩比方面,本发明的方法比基本算法提高了21%。因此,本发明一种基于字典的改进分形编码水声图像压缩算法,可以极大地提高编解码速度,对于水声图像,可以达到或高于基本算法的解码质量,对于普通灰度图像,采用3×3和4×4分割时,字典法有很好的表现,采用6×6分割时,字典法块效应较明显。
附图说明
图1字典生成及编码流程图。
图2基于字典算法编码具体步骤。
图3 图像块每个像素点的编号。
图4 图像块每个像素点的编号。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述。
本发明包括如下步骤:
步骤一:Julia集图像生成。
Julia集是由法国科学家Gaston Julia 命名的一个复平面上分形点的集合,由映射(、均在复数域且为常数)通过迭代生成。由此映射可产生一个迭代序列:,这一序列可能趋向于无穷或始终在某一范围内并收敛于某一点,使序列不扩散的z值的集合称为Julia集(以下简称J集)。在复平面上,使映射:的吸引边界为有界的复参数的集合称为Mandelbrot集(以下简称M集)。由J集和M集的定义可知,可以在M集内取点作为参数生成J集。
本发明采用Julia分形集,实现用较少的参数生成复杂的图像。采用逃逸时间算法生成Julia集图像,具体包含以下步骤:
(1) 初始化
设定图像的分辨率为,参数,a, b, p, q为设定的参数。逃逸半径,最大迭代次数。建立坐标系:轴为实数轴,轴为虚数轴,和的取值范围分别为:,则图像中的点步长为:;,令中每个点的像素值为0。
(2) 循环
选择点,;,完成以下迭代:
;;;
;;。
(3) 迭代循环控制
计算模:,若,则选择颜色,转到第④步,否则,转到第②步。
(4) 着色
对点着颜色,并且选择下一个像素点,转第②步。
(5) 所有点完成着色,获得J集图像。
为生成不同尺寸的字典,本发明分别设置图像分辨率为、、、,由上一步在M集中所取的每一个点作为参数c,可生成大量形状各异的J集图像。
步骤二:字典的生成及扩充。
本发明对图像采用尺寸不超过的分割,为此,构建3个尺寸分别为、4×4和的字典,记为、和。字典的生成及扩充具体步骤如下:
(1)分割Julia集图像生成不同尺寸的字典
首先将步骤一生成的Julia集图像的灰度值范围经线性变换扩展到0~255。
① 生成字典
a. 将、 J集图像分割为子块;
b. 将 J集图像分割为、、子块;将 J集图像分割为、、、子块,对以上生成的子块,采用像素平均的方法将其尺寸变换为。
② 生成字典
a. 将、 J集图像分割为子块;
b. 将 J集图像分割为、、21×21子块;将 J集图像分割为、12×12、、、42×42子块,对以上生成的子块,采用像素平均的方法将其尺寸变换为。
③ 生成字典
a. 将、 J集图像分割为4×4子块;
b. 将 J集图像分割为、、子块;将 J集图像分割为、、、子块,对以上生成的子块,采用像素平均的方法将其尺寸变换为4×4。
(2)扩充字典。
为使字典包含的块更加丰富多样,本发明采用以下方式对字典进行扩充:
① 素数相乘:将字典中的每个子块乘以不同的素数(选用素数可以避免与某数相乘后的块跟与其它数相乘后的块构成比例关系),然后对256取模,生成新的图像块,最后将新图像块加入到字典中。
② 加入高斯噪声。考虑到水声图像普遍存在噪声,而J集图像分割后的块均为无噪声图像块,为了使字典与水声图像块更好地匹配,本发明通过加入高斯噪声使字典中的块像素变化更具随机性和多样性,以满足水声图像编码需要。
③ 进行等距变换。为降低匹配误差,参照基本分形编码过程,对生成的字典进行8种等距变换,扩充字典容量。
(3)剔除字典中的冗余。
① 除去字典中的常值块(所有点像素值相同的块)。此类块在分形编码匹配时只能与常值R块匹配,而常值R块则可以与任意块匹配(只需将对比度因子设置为0),故此类块不需要留在字典中。
② 除去字典中具有线性相关关系的块。由分形编码匹配过程可知,具有线性相关关系的块,匹配效果是一样的,只存在匹配参数上的差异,因此只需保留一个即可。
步骤三:字典的分类。
在字典的分类原则上考虑两个因素:
①分类数目的多少。针对小尺寸字典划分较少的分类,将大尺寸字典划分较多的分类。
②每一类中包含块的个数。子块数的设定满足:使用字典编码后,压缩率和峰值信噪比
应接近或高于同尺寸下基本分形编码的这两个参数。
基于以上原因,本发明对三种不同尺寸的字典,分别采取如下的分类策略:
(1)字典分类
① 按图像块每个像素点进行编号,见说明书附图3。
② 按式计算每一个块的特征值。
(5-1)
式中,;为图中编号为的点的像素值;为该块的像素均值。
③ 根据特征值设置不同的类。按照第②步运算规则,图像块的特征值不重复共计511个(不存在全0的二值块),每一个特征值对应字典中的一类。
④ 对于字典中的每个块,根据其特征值,按下列规则决定是否将其放入到其所对应的类(记该类为)中:
a. 若为空集,则直接放入,否则,转到b。
b. 计算该块与中已存在的块的PSNR(峰值信噪比),若结果均小于某预设阈值(本文设置),且中块的数量未达到N,则放入,否则舍弃。
进行此步的筛选,可以避免字典中包含的块相似性过高,增加每一类中块与块之间的差异性,有利于提高编码时的匹配精度。
⑤ 对字典中所有块进行第④步操作,完成字典分类。
(2)字典分类
① 按双线性差值方法将字典中图像块的尺寸由4×4缩小为3×3。
② 按字典分类方法进行分类。
(3)字典分类
①按双线性差值方法将字典中图像块的尺寸由缩小为,对图像块每个像素点进行编号,见说明书附图4。
② 按下式计算每一个块的特征值。
(5-2)
式中,;;为说明书附图4中编号为的点的像素值;为该块的像素均值。
③ 按照第②步运算规则,图像块的特征值不重复共计8192个,每一个特征值对应字典中的一类。
④对字典中的每个块按照字典分类中的第④、⑤步操作,完成筛选和分类。
步骤四:编码。
(1)载入照步骤一、二和三生成的字典。
(2)设置R块阈值,匹配误差阈值。
(3)对图像进行值域块分割。
(4)根据值域块分割尺寸选择相应尺寸的字典作为匹配搜索时的码本。
(5)对于每一个R块,计算其方差,按如下步骤进行搜索匹配,获得分形码(分形码包括最佳匹配块在字典中的位置以及对比度因子和灰度偏移量):
① 若,则视该R块为平滑块,可选字典中的任意块为最佳匹配块,因此无需搜索即可直接输出分形码。
②若则根据R块尺寸按式或计算该R块的特征值,在字典中选择其所对应的类,在中进行搜索匹配,完成编码。
(6)对所有R块执行步骤(5),量化分形码,输出形成编码文件。
步骤五:解码。
(1)载入按上述步骤生成的字典。
(2)由编码文件读出R块、每一个R块对应的最佳匹配块在字典中的位置、对比度因子、灰度偏移量等信息。
(3)定义一个与原图像同样大小的图像X,用来保存解码图像。
(4)对于X中的每一个R块,根据其分形码在字典中找到其最佳匹配块D,然后由恢复。
(5)所有R块恢复之后,拼贴组成解码图像。
- 还没有人留言评论。精彩留言会获得点赞!