语音文件的LRC时间轴文件自动生成方法及相关设备与流程
本发明涉及多媒体技术领域,尤其涉及一种语音文件的LRC时间轴文件自动生成方法及相关设备。
背景技术:
目前对于学习终端或者家教终端中的英语听说或者有声教材模块使用的数据均是教材同步课文的语音和对应的文字数据,也即常用的MP3+LRC的形式。对同步于语音文件的文本数据,目前的制作方法中,需要完全人工进行拆分、文字识别、对文本数据进行语音录制、制作时间轴文件、人工校对等等,制作方式步骤多,制作效率比较低、耗时长、制作成本代价高。
技术实现要素:
本发明实施例公开了一种语音文件的LRC时间轴文件自动生成方法及相关设备,大大提高了制作LRC时间轴文件的效率。
本发明实施例第一方面公开一种语音文件的LRC时间轴文件自动生成方法,包括:
当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件;
按照所述语音文件的语句间隔将所述语音文件分成多个语音区间,并记录每个语音区间的开始时间;
依据语音识别技术识别所述语音文件,生成与所述语音文件对应的文本文件,其中,所述文本文件记录与所述语音区间对应的开始时间;
将所述文本文件与所述录音稿文件进行对比,并生成LRC时间轴文件。
作为一种可选的实施方式,在本发明实施例第一方面中,所述方法中将文本文件与所述录音稿文件进行对比,并生成LRC时间轴文件的步骤包括:
判断是否已经读取完所述录音稿文件的文本或者已经读取完文本文件的文本,如果没有读取完,则按预设的单位长度依次读取所述录音稿文件的文本,并将读取的文本与所述文本文件的语音区间对应的文本进行对比,若相似度小于预设的阀值,则读取文本文件的下一个单位长度文本并与录音稿文件进行对比,直到相似度达到预设的阀值;再将所述语音区间对应的文本的开始时间与读取的录音稿文件写入LRC时间轴文件;如果读取完所述录音稿文件的文本或者读取完文本文件的文本,生成整个语音文件对应的LRC时间轴文件。
作为一种可选的实施方式,在本发明实施例第一方面中,所述按照语音文件的语句间隔将所述语音文件分成多个语音区间,并记录每个语音区间的开始时间的步骤之后,所述方法还包括:
依据语种识别技术识别出各语音区间音频发音的语言种类;
再根据识别的语言种类调用对应的语音识别接口进行语音识别,生成与所述语音文件对应的文本文件。
作为一种可选的实施方式,在本发明实施例第一方面中,所述获取未经处理的语音文件及相应的录音稿文件的步骤之后,所述方法还包括:
按预设的降噪值和音频分贝值对所述语音文件进行预处理,从而提升语音识别成文本的精度。
作为一种可选的实施方式,在本发明实施例第一方面中,所述生成LRC时间轴文件的步骤之后,所述方法还包括:
将所述语音文件与所述LRC时间轴文件加密打包生成用户设备使用的数据。
本发明实施例第二方面公开一种语音文件的LRC时间轴文件自动生成装置,包括:
获取模块,用于当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件;
语音区间切分模块,用于按照所述语音文件的语句间隔将所述语音文件分成多个语音区间,并记录每个语音区间的开始时间;
语音识别模块,用于依据语音识别技术识别所述语音文件,生成与所述语音文件对应的文本文件,其中,所述文本文件记录与所述语音区间对应的开始时间;
LRC时间轴文件生成模块,用于将所述文本文件与所述录音稿文件进行对比,并生成LRC时间轴文件。
作为一种可选的实施方式,在本发明实施例第二方面中:
所述LRC时间轴文件生成模块包括:
判断单元,用于判断是否已经读取完所述录音稿文件的文本或者已经读取完文本文件的文本;
读取单元,用于当判断单元判断出没有读取完所述录音稿文件的文本或者文本文件的文本时,按预设的单位长度依次读取所述录音稿文件的文本;
对比单元,用于将读取单元读取的文本与所述文本文件的语音区间对应的文本进行对比;
时间写入单元,用于当对比单元对比出读取单元读取的文本与所述文本文件的语音区间对应的文本的相似度达到预设的阀值时,将所述语音区间对应的文本的开始时间与读取的录音稿文件写入LRC时间轴文件。
作为一种可选的实施方式,在本发明实施例第二方面中,所述装置还包括:
语种识别模块,用于依据语种识别技术识别出各语音区间音频发音的语言种类。
作为一种可选的实施方式,在本发明实施例第二方面中,所述装置还包括:
预处理模块,用于按预设的降噪值和音频分贝值对所述语音文件进行预处理,从而提升语音识别成文本的精度。
作为一种可选的实施方式,在本发明实施例第二方面中,所述装置还包括:
加密打包模块,用于将所述语音文件与所述LRC时间轴文件加密打包生成用户设备使用的数据。
本发明实施例第三方面公开一种用户设备,包括本发明实施例第二方面公开的所述语音文件的LRC时间轴文件自动生成装置。
与现有技术相比,本发明实施例具备以下有益效果:
本发明实施例中,当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件;然后按照语音文件的语句间隔将语音文件分成多个语音区间,并记录每个语音区间的开始时间;再依据语音识别技术识别语音文件,生成与该语音文件对应的文本文件,其中,文本文件记录了与语音区间对应的文本的开始时间;最后将文本文件与录音稿文件进行对比,并生成LRC时间轴文件。可见,实施本发明实施例,能够智能地生成语音文件的LRC时间轴文件,省去了大量的人工工作,提高了效率,降低了成本。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例公开的一种语音文件的LRC时间轴文件自动生成方法的流程示意图;
图2是本发明实施例公开的另一种语音文件的LRC时间轴文件自动生成方法的流程示意图;
图3是本发明实施例公开的另一种语音文件的LRC时间轴文件自动生成方法的流程示意图;
图4是本发明实施例公开的一种语音文件的LRC时间轴文件自动生成装置的结构示意图;
图5是本发明实施例公开的另一种语音文件的LRC时间轴文件自动生成装置的结构示意图;
图6是本发明实施例公开的一种用户设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明实施例的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
本发明实施例公开了一种语音文件的LRC时间轴文件自动生成方法及相关设备,能够智能地生成语音文件的LRC时间轴文件,省去了大量的人工工作,提高了效率,降低了成本。以下进行结合附图进行详细描述。
实施例一
请参阅图1,图1是本发明实施例公开的一种语音文件的LRC时间轴文件自动生成方法的流程示意图。如图1所示,该语音文件的LRC时间轴文件自动生成方法可以包括以下步骤:
101、当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件。
本发明实施例中,可以一次只处理一个语音文件,即只自动生成一个语音文件的LRC时间轴文件。也可以是批量处理语音文件,即批量地自动生成多个语音文件的LRC时间轴文件。当有语音文件未处理时,则获取未经处理的语音文件及相应的录音稿文件。其中,LRC时间轴文件是音乐同步歌词文件。
102、按照语音文件的语句间隔将语音文件分成多个语音区间,并记录每个语音区间的开始时间。
获取未经处理的语音文件后,按照语音文件的语句间隔将语音文件分成多个语音区间,例如可以按照语音文件中人的说话间隔来切割语音区间,或者可以按照自然句子的长度来切割语音区间,此处不做限制。将语音文件切割成多个语音区间后,还需要记录每个语音区间的开始时间,例如第一个语音区间的开始时间是00:01秒,第二个语音区间的开始时间是00:10秒。
103、依据语音识别技术识别语音文件,生成与该语音文件对应的文本文件,其中,文本文件记录与该语音区间对应的文本的开始时间。
将语音文件切割成多个语音区间后,再利用语音识别技术对语音文件进行语音识别,并生成与该语音文件对应的文本文件,在该文本文件中,记录与语音区间对应的文本的开始时间,例如在文本文件中,第一个语音区间对应的文本为“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶”,第一个语音区间的开始时间是00:01秒,则记录前述文本的开始时间为00:01秒。又如在文本文件中,第二个语音区间对应的文本为“冬天,漫天的雪花就像飞絮一样飞舞”,第二个语音区间的开始时间是00:10秒,则记录前述文本的开始时间为00:10秒。
104、将文本文件与录音稿文件进行对比,并生成LRC时间轴文件。
生成与语音文件对应的文本文件后,再将该文本文件与录音稿文件进行对比,将文本文件中与录音稿文件中相匹配的文本的开始时间记录到录音稿文件中,这样就完成了语音文件及相应的录音稿文件时间的对应,根据记录有时间轴的录音稿文件来生成LRC时间轴文件。
在图1所描述的方法,当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件;然后按照语音文件的语句间隔将语音文件分成多个语音区间,并记录每个语音区间的开始时间;再依据语音识别技术识别语音文件,生成与该语音文件对应的文本文件,其中,文本文件记录了与语音区间对应的文本的开始时间;最后将文本文件与录音稿文件进行对比,并生成LRC时间轴文件。可见,实施本发明实施例,能够智能地生成语音文件的LRC时间轴文件,省去了大量的人工工作,提高了效率,降低了成本。
实施例二
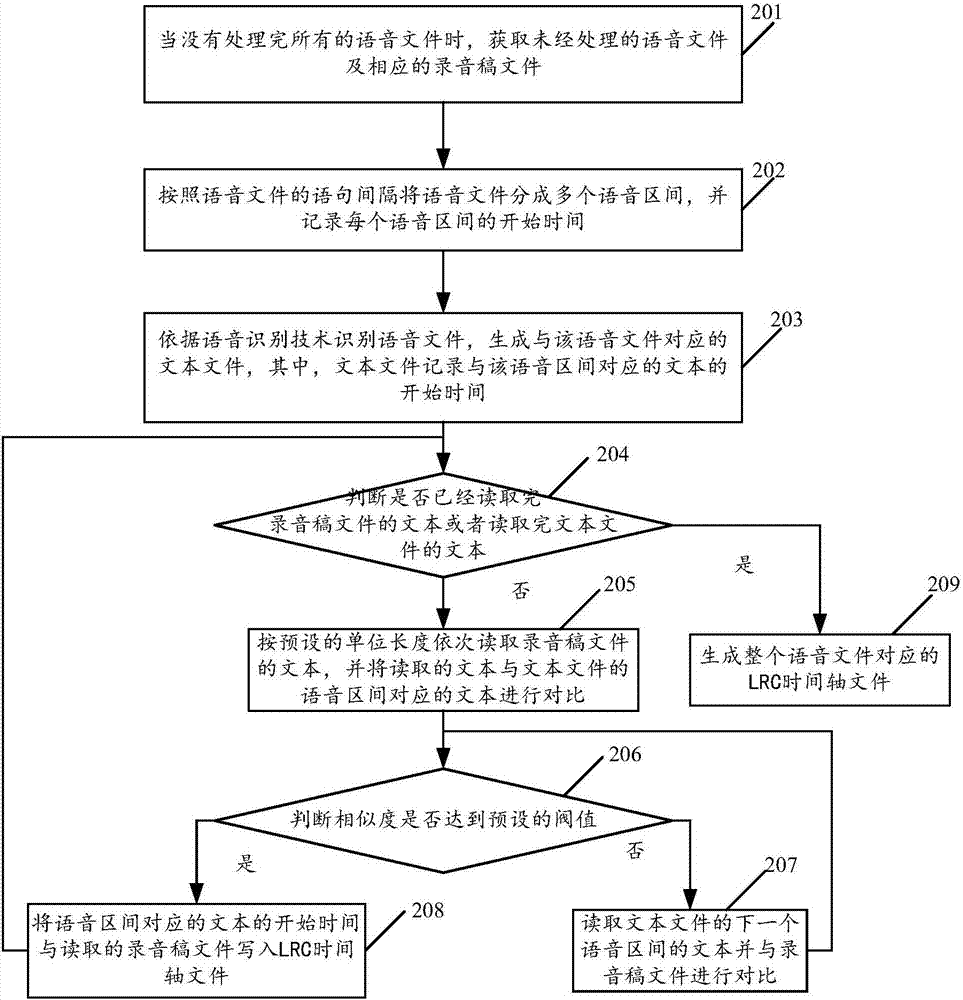
请参阅图2,图2是本发明实施例公开的另一种语音文件的LRC时间轴文件自动生成方法的流程示意图。如图2所示,该语音文件的LRC时间轴文件自动生成方法可以包括以下步骤:
201、当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件。
202、按照语音文件的语句间隔将语音文件分成多个语音区间,并记录每个语音区间的开始时间。
获取未经处理的语音文件后,按照语音文件的语句间隔将语音文件分成多个语音区间,例如可以按照语音文件中人的说话间隔来切割语音区间,或者可以按照自然句子的长度来切割语音区间,此处不做限制。将语音文件切割成多个语音区间后,还需要记录每个语音区间的开始时间,例如第一个语音区间的开始时间是00:01秒,第二个语音区间的开始时间是00:10秒。
203、依据语音识别技术识别语音文件,生成与该语音文件对应的文本文件,其中,文本文件记录与该语音区间对应的文本的开始时间。
将语音文件切割成多个语音区间后,再利用语音识别技术对语音文件进行语音识别,并生成与该语音文件对应的文本文件,在该文本文件中,记录与语音区间对应的文本的开始时间,例如在文本文件中,第一个语音区间对应的文本为“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶”,第一个语音区间的开始时间是第00:01秒,则记录前述文本的开始时间为第00:01秒。又如在文本文件中,第二个语音区间对应的文本为“冬天,漫天的雪花就像飞絮一样飞舞”,第二个语音区间的开始时间是第00:10秒,则记录前述文本的开始时间为第00:10秒。
204、判断是否已经读取完录音稿文件的文本或者已经读取完文本文件的文本。
在步骤203中生成与该语音文件对应的文本文件后,再对语音文件对应的录音稿文件进行处理。具体的,首先需要依次读取录音稿文件的文本。在读取录音稿文件的文本之前,先判断是否已经读取完录音稿文件的文本或者已经读取完文本文件的文本,如果否,则执行步骤205,如果是,则执行步骤209。
205、按预设的单位长度依次读取录音稿文件的文本,并将读取的文本与文本文件的语音区间对应的文本进行对比。
如果步骤204中判断出未读取完录音稿文件的文本或者读取完文本文件的文本,则按照预设的单位长度依次读取录音稿文件的文本,其中,单位长度可以是以句号为长度,也可以是按照行为长度,此处不做限制。读取了录音稿文件的文本后,再将读取的文本与文本文件的语音区间对应的文本进行对比,这里从头开始读取的文本是与语音文件的第一个语音区间开始对应的,有可能读取的一个单位长度的文本对应多个语音区间的文本,但一定是按时间顺序对应的。
206、判断相似度是否达到预设的阀值。
将读取的录音稿文件与语音区间的文本进行对比的时候,判断两者的相似度是否达到预设的阀值,如果是,则执行步骤208,如果否,则执行步骤207。
207、读取文本文件的下一个语音区间的文本并与录音稿文件进行对比。
如果判断出读取的文本与语音区间的文本的相似度没有达到预设的阀值,则读取文本文件的下一个语音区间的文本并与录音稿文件进行对比,例如,读取的录音稿文件第一个单位长度的文本是“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶;冬天,漫天的雪花就像飞絮一样飞舞”,文本文件的第一个语音区间的文本是“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶”,将“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶”与秋天,满树飘落的落叶就像翩翩起舞的蝴蝶;冬天,漫天的雪花就像飞絮一样飞舞”进行对比,相似度没有达到预设的阀值,则再读取文本文件的下一个语音区间的文本:“冬天,漫天的雪花就像飞絮一样飞舞”;再将文本文件的第一个语音区间的文本和第二个语音区间的文本:“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶”以及“冬天,漫天的雪花就像飞絮一样飞舞”与录音稿文件第一个单位长度的文本“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶;冬天,漫天的雪花就像飞絮一样飞舞”进行比较,相似度达到了预设的阀值,再执行步骤208。
208、将语音区间对应的文本的开始时间与读取的录音稿文件写入LRC时间轴文件。
如果步骤206中判断出将读取的录音稿文件与语音区间的文本进行对比,相似度达到预设的阀值,则将语音区间对应的文本的开始时间与读取的录音稿文件写入LRC时间轴文件,例如第一个语音区间对应的文本为“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶”,开始时间为第00:01秒;第二个语音区间对应的文本为“冬天,漫天的雪花就像飞絮一样飞舞”,开始时间为第00:10秒;读取的录音稿文件为“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶;冬天,漫天的雪花就像飞絮一样飞舞”,则将读取的录音稿文件“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶;冬天,漫天的雪花就像飞絮一样飞舞”,以及对应的时间,即“秋”对应第00:01秒,“冬”对应第00:10秒写入LRC时间轴文件。步骤208执行完后,继续执行步骤204,直到步骤204中判断出已经读取完录音稿文件或者读取完文本文件的文本。
209、生成整个语音文件对应的LRC时间轴文件。
当步骤204中判断出已经读取完录音稿文件或者读取完文本文件的文本时,说明已经处理完整个语音文件和对应的录音稿文件,则生成整个语音文件对应的LRC时间轴文件。
实施图2所描述的方法通过按预设的单位长度依次读取录音稿文件的文本,并将读取的文本与文本文件的语音区间对应的文本进行对比,再判断两者的相似度是否达到预设的阀值,如果没有达到预设的阀值,则读取文本文件的下一个单位长度文本并与录音稿文件进行对比,直到相似度达到预设的阀值,再将语音区间对应的文本的开始时间与读取的录音稿文件写入LRC时间轴文件,重复执行上述步骤,直至读取完录音稿文件的文本或者读取完文本文件的文本,生成整个语音文件对应的LRC时间轴文件。可见,实施本发明实施例,生成语音文件的LRC时间轴文件的整个过程都是自动完成,没有人工参与,省去了大量的人工工作,提高了效率,降低了成本。
实施例三
请参阅图3,图3是本发明实施例公开的另一种语音文件的LRC时间轴文件自动生成方法的流程示意图。如图3所示,该语音文件的LRC时间轴文件自动生成方法可以包括以下步骤:
301、批量导入语音文件和录音稿文件。
需要批量自动生成语音文件的LRC时间轴文件时,首先批量导入语音文件和录音稿文件。
302、判断是否已经处理完所有的语音文件。
再判断是否已经处理完所有的语音文件,如果是,则执行步骤314,如果否,则执行步骤303。
303、获取未经处理的语音文件及相应的录音稿文件。
304、按预设的降噪值和音频分贝值对语音文件进行预处理。
按预设好的降噪值、音频分贝值,对音频进行预处理,从而提升语音识别成文本的精度。
305、按照语音文件的语句间隔将语音文件分成多个语音区间,并记录每个语音区间的开始时间。
306、依据语种识别技术识别出各语音区间音频发音的语言种类,再根据识别的语言种类调用对应的语音识别接口进行语音识别。
利用语种识别技术识别各语音区间音频发音的语言种类,再根据识别的语言种类调用对应的语音识别接口进行语音识别,能提高语音识别精度。
307、依据语音识别技术识别语音文件,生成与该语音文件对应的文本文件,其中,文本文件记录与该语音区间对应的文本的开始时间。
308、判断是否已经读取完录音稿文件的文本或者已经读取完文本文件的文本。如果否,则执行步骤309,如果是,则执行步骤313。
309、按预设的单位长度依次读取录音稿文件的文本,并将读取的文本与文本文件的语音区间对应的文本进行对比。
310、判断相似度是否达到预设的阀值。如果是,则执行步骤312,如果否,则执行步骤311。
311、读取文本文件的下一个语音区间的文本并与录音稿文件进行对比。执行完毕后返回步骤310。
312、将语音区间对应的文本的开始时间与读取的录音稿文件写入LRC时间轴文件。执行完毕后返回步骤308。
313、生成整个语音文件对应的LRC时间轴文件。
314、将语音文件与LRC时间轴文件加密打包生成用户设备使用的数据。执行完本步骤后返回步骤302。
315、结束本流程。当步骤302中判断出已经处理完所有的语音文件时,结束本流程。
需要说明的是,步骤314可以在步骤313执行完之后随即执行,也可以在步骤302判断结果为是时先执行步骤314,再执行步骤315。
实施图3所描述的方法中,实现了批量语音文件的处理,相比人工进行批量处理,大大提高了处理效率。并且,通过按预设好的降噪值、音频分贝值,对音频进行预处理,从而提升语音识别成文本的精度。进一步的,通过利用利用语种识别技术识别各语音区间音频发音的语言种类,再根据识别的语言种类调用对应的语音识别接口进行语音识别,提高了语音识别精度。从而提高了生成语音文件的LRC时间轴文件的精确度和效率。
实施例四
请参阅图4,图4是本发明实施例公开的一种语音文件的LRC时间轴文件自动生成装置的结构示意图。如图4所示,该语音文件的LRC时间轴文件自动生成装置可以包括:
获取模块401,用于当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件。
语音区间切分模块402,用于按照获取模块401获取的语音文件的语句间隔将该语音文件分成多个语音区间,并记录每个语音区间的开始时间。其中,可以按照语音文件中人的说话间隔来切割语音区间,或者可以按照自然句子的长度来切割语音区间,此处不做限制。将语音文件切割成多个语音区间后,还需要记录每个语音区间的开始时间,例如第一个语音区间的开始时间是00:01秒,第二个语音区间的开始时间是00:10秒。
语音识别模块403,用于依据语音识别技术识别语音文件,生成与语音文件对应的文本文件,其中,文本文件记录与语音区间对应的开始时间。例如在文本文件中,第一个语音区间对应的文本为“秋天,满树飘落的落叶就像翩翩起舞的蝴蝶”,第一个语音区间的开始时间是00:01秒,则记录前述文本的开始时间为00:01秒。又如在文本文件中,第二个语音区间对应的文本为“冬天,漫天的雪花就像飞絮一样飞舞”,第二个语音区间的开始时间是00:10秒,则记录前述文本的开始时间为00:10秒。
LRC时间轴文件生成模块404,用于将文本文件与录音稿文件进行对比,并生成LRC时间轴文件。
本发明实施例中,当没有处理完所有的语音文件时,获取模块401获取未经处理的语音文件及相应的录音稿文件;然后语音区间切分模块402按照语音文件的语句间隔将语音文件分成多个语音区间,并记录每个语音区间的开始时间;语音识别模块403再依据语音识别技术识别语音文件,生成与该语音文件对应的文本文件,其中,文本文件记录了与语音区间对应的文本的开始时间;最后LRC时间轴文件生成模块404将文本文件与录音稿文件进行对比,并生成LRC时间轴文件。可见,实施本发明实施例,能够智能地生成语音文件的LRC时间轴文件,省去了大量的人工工作,提高了效率,降低了成本。
实施例五
请参阅图5,图5是本发明实施例公开的另一种语音文件的LRC时间轴文件自动生成装置的结构示意图。如图5所示,该语音文件的LRC时间轴文件自动生成装置可以包括:
获取模块501,用于当没有处理完所有的语音文件时,获取未经处理的语音文件及相应的录音稿文件。
预处理模块502,用于按预设的降噪值和音频分贝值对获取模块获取的语音文件进行预处理,从而提升语音识别成文本的精度。
语音区间切分模块503,用于按照获取模块401获取的语音文件的语句间隔将该语音文件分成多个语音区间,并记录每个语音区间的开始时间。
语种识别模块504,用于依据语种识别技术识别出各语音区间音频发音的语言种类。
语音识别模块505,用于依据语音识别技术识别语音文件,生成与语音文件对应的文本文件,其中,文本文件记录与语音区间对应的开始时间。
LRC时间轴文件生成模块506,用于将文本文件与录音稿文件进行对比,并生成LRC时间轴文件。其中,LRC时间轴文件生成模块506包括:
判断单元5061,用于判断是否已经读取完所述录音稿文件的文本或者已经读取完文本文件的文本。
读取单元5062,用于当判断单元5061判断出没有读取完录音稿文件的文本或者文本文件的文本时,按预设的单位长度依次读取录音稿文件的文本。
对比单元5063,用于将读取单元5062读取的文本与文本文件的语音区间对应的文本进行对比。
时间写入单元5064,用于当对比单元5063对比出读取单元读取的文本与文本文件的语音区间对应的文本的相似度达到预设的阀值时,将语音区间对应的文本的开始时间与读取的录音稿文件写入LRC时间轴文件。
加密打包模块507,用于将语音文件与LRC时间轴文件加密打包生成用户设备使用的数据。其中,用户设备可以是学习机端或者家教机端,此处不做限制。
本发明实施例中,通过预处理模块502按预设好的降噪值、音频分贝值,对音频进行预处理,从而提升语音识别成文本的精度。进一步的,语种识别模块504通过利用利用语种识别技术识别各语音区间音频发音的语言种类,再根据识别的语言种类调用对应的语音识别接口进行语音识别,提高了语音识别精度。并且,LRC时间轴文件生成模块506的整个执行过程完全智能化,因此提高了生成语音文件的LRC时间轴文件的精确度和效率。
实施例六
请参阅图6,图6是本发明实施例公开的一种用户设备的结构示意图。其中,图6所示的用户设备包括图4~图5任意一种语音文件的LRC时间轴文件自动生成装置。实施图6所示的用户设备,获取未经处理的语音文件及相应的录音稿文件;然后按照语音文件的语句间隔将语音文件分成多个语音区间,并记录每个语音区间的开始时间;再依据语音识别技术识别语音文件,生成与该语音文件对应的文本文件,其中,文本文件记录了与语音区间对应的文本的开始时间;最后将文本文件与录音稿文件进行对比,并生成LRC时间轴文件。可见,实施本发明实施例,能够智能地生成语音文件的LRC时间轴文件,省去了大量的人工工作,提高了效率,降低了成本。另外,通过按预设好的降噪值、音频分贝值,对音频进行预处理,从而提升语音识别成文本的精度。进一步的,通过利用利用语种识别技术识别各语音区间音频发音的语言种类,再根据识别的语言种类调用对应的语音识别接口进行语音识别,提高了语音识别精度。从而提高了生成语音文件的LRC时间轴文件的精确度和效率。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质包括只读存储器(Read-Only Memory,ROM)、随机存储器(Random Access Memory,RAM)、可编程只读存储器(Programmable Read-only Memory,PROM)、可擦除可编程只读存储器(Erasable Programmable Read Only Memory,EPROM)、一次可编程只读存储器(One-time Programmable Read-Only Memory,OTPROM)、电子抹除式可复写只读存储器(Electrically-Erasable Programmable Read-Only Memory,EEPROM)、只读光盘(Compact Disc Read-Only Memory,CD-ROM)或其他光盘存储器、磁盘存储器、磁带存储器、或者能够用于携带或存储数据的计算机可读的任何其他介质。
以上对本发明实施例公开的一种语音文件的LRC时间轴文件自动生成方法及相关设备进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!