采用流式计算进行爬取数据的实时分析的实现方法与流程
本发明涉及计算机数据分析技术领域,具体涉及一种采用流式计算进行爬取数据的实时分析的实现方法。
背景技术:
Scrapy是一种python开发的快速、高层次的Web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Spiders通过Scrapy引擎从互联网上获取数据源进行数据的爬取操作,这一过程中,Spider根据Scheduler的调度选择向Downloader进行响应或者利用Items字段将获取的数据进行存取。
Scrapy爬取数据的框架结构,如图1所示。大数据流式计算中包括三种框架:Storm、Spark、Samza。
流式计算和批量计算分别适用于不同的大数据应用场景:对于先存储后计算,实时性要求不高,同时,数据的准确性、全面性更为重要的应用场景,批量计算模式更合适;对于无需先存储,可以直接进行数据计算,实时性要求很严格,但数据的精确度要求稍微宽松的应用场景,流式计算具有明显优势。流式计算中,数据往往是最近一个时间窗口内的,因此数据延迟往往较短,实时性较强。
数据的爬取是一个高速执行和并发访问的过程,爬取的结果通常上千万或上亿条记录,对于Scrapy爬虫的经典处理方式是将数据记录进行简单的清洗、提取,然后通过Item存储到Json文件或者Mongodb数据库中,然后从文件或数据库中进行数据的读取和分析,面对近GB或TB级的数据,这种处理难以满足一些实时的数据处理需求。
技术实现要素:
本发明要解决的技术问题是:本发明针对以上问题,提供一种采用流式计算进行爬取数据的实时分析的实现方法。
本发明所采用的技术方案为:
采用流式计算进行爬取数据的实时分析的实现方法,所述方法将Scrapy爬取的数据进行模型化处理,形成数据流Data-Stream,对数据流进行分段操作,分解成一系列短小的批处理作业,然后将分段的数据流传输到数据批处理引擎中,在数据引擎中对数据进行清洗、提取、转化操作,并将得到的数据处理结果保存在内存中。
这一过程由于没有将数据存入DBMS的过程,减少数据存取数据库所带来的IO延迟;同时,将数据处理结果存放内存中,提高数据获取的执行效率,从而实现海量数据的实时分析过程。
DBMS,数据库管理系统,database management system,简称dbms,是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库。用户通过dbms访问数据库中的数据,数据库管理员也通过dbms进行数据库的维护工作。它可使多个应用程序和用户用不同的方法在同时或不同时刻去建立,修改和询问数据库。
所述方法实现步骤如下:
1)利用Scrapy进行数据的爬取操作,在Spider获取数据的过程中将数据通过Pipeline进行整理,形成管道数据流的输出形式;
2)将形成的数据流进行分段操作,分段的数据形成一系列短小的批处理作业,然后将这些批处理作业传入到数据批处理引擎中;
3)在数据引擎中,对分段的数据进行清洗、提取、转化等操作,将精简的数据分析结果存放到内存中,并向上层程序提供这些内存数据提取接口,上层能够进行数据的实时、高速的提取、处理等操作。
所述数据流进行分段的依据是数据分析所需要的数据特征。
所述数据特征包括时间特征、出现频率特征。
本发明的有益效果为:
本发明方法没有将数据存入DBMS的过程,减少了数据存取数据库所带来的IO延迟;同时,将数据处理结果存放内存中,提高数据获取的执行效率,从而实现海量数据的实时分析过程。
附图说明
图1为Scrapy爬取数据的框架结构图;
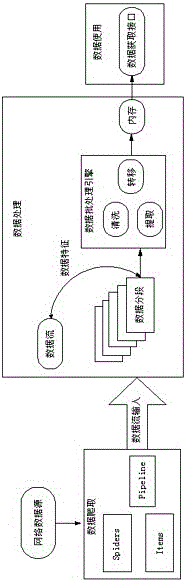
图2为本发明Scrapy爬取数据的示意图。
具体实施方式
下面根据说明书附图,结合具体实施方式对本发明进一步说明:
实施例1
采用流式计算进行爬取数据的实时分析的实现方法,所述方法将Scrapy爬取的数据进行模型化处理,形成数据流Data-Stream,对数据流进行分段操作,分解成一系列短小的批处理作业,然后将分段的数据流传输到数据批处理引擎中,在数据引擎中对数据进行清洗、提取、转化操作,并将得到的数据处理结果保存在内存中。
这一过程由于没有将数据存入DBMS的过程,减少数据存取数据库所带来的IO延迟;同时,将数据处理结果存放内存中,提高数据获取的执行效率,从而实现海量数据的实时分析过程。
DBMS,数据库管理系统,database management system,简称dbms,是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库。用户通过dbms访问数据库中的数据,数据库管理员也通过dbms进行数据库的维护工作。它可使多个应用程序和用户用不同的方法在同时或不同时刻去建立,修改和询问数据库。
实施例2
如图2所示,在实施例1的基础上,本实施例所述方法实现步骤如下:
1)利用Scrapy进行数据的爬取操作,在Spider获取数据的过程中将数据通过Pipeline进行整理,形成管道数据流的输出形式;
2)将形成的数据流进行分段操作,分段的数据形成一系列短小的批处理作业,然后将这些批处理作业传入到数据批处理引擎中;
3)在数据引擎中,对分段的数据进行清洗、提取、转化等操作,将精简的数据分析结果存放到内存中,并向上层程序提供这些内存数据提取接口,上层能够进行数据的实时、高速的提取、处理等操作。
Pipeline,管道,管道(Unix),流水线 (计算机)。
实施例3
在实施例2的基础上,所述数据流进行分段的依据是数据分析所需要的数据特征。
实施例4
在实施例3的基础上,本实施例所述数据特征包括时间特征、出现频率特征。
实施方式仅用于说明本发明,而并非对本发明的限制,有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也属于本发明的范畴,本发明的专利保护范围应由权利要求限定。
- 还没有人留言评论。精彩留言会获得点赞!