疾病的快速辅助定位方法与流程
本发明涉及临床诊断系统,具体涉及一种疾病的快速辅助定位方法。
背景技术:
在罕见疾病的临床诊断中,一个常见的问题便是如何根据患者的表型信息快速准确地分析出其罹患的具体的疾病类型。表型诊断就是通过比较患者表型和所有已知疾病记录的表型间的相似程度,跟患者越相似的疾病可能性越大,因此精确地计算记录的疾病表型和患者间的表型间的相似程度是成功诊断的关键。
由于各种外界原因,比如患者间的遗传和环境等个体差异、临床医生的知识结构差异等,临床诊断时患者的表型描述不可能跟疾病的已知表述完全一致,在现实场景中,经常出现以下问题:1)数据不完整(只包括部分表型);2)噪音(跟真实疾病无关的表型,即提供了错误的表型);3)不准确描述(表型描述过于宽泛,不具有区分度)。
技术实现要素:
针对现有技术中的上述不足,本发明提供的疾病的快速辅助定位方法解决了实际场景中表型数据不完备、带有噪音和描述不够准确引起疾病定位不准确的问题。
为了达到上述发明目的,本发明采用的技术方案为:
提供一种疾病的快速辅助定位方法,其包括:
接收患者描述的罹患疾病的所有表型,并采用接收的所有表型构建患者描述表型集;
获取表型注释数据库中具有患者描述的表型的所有疾病;
查找每种疾病所对应的表型,并采用每种疾病所对应的表型分别构建相关疾病表型集;
计算患者描述表型集与每个相关疾病表型集的相似度:
其中,t1为患者描述表型集;t2为相关疾病表型集;sim(t1,t2)为集合t1与集合t2之间的相似度;t1和t2疾病所对应的两种不同的表型;sim(t1,t2)为表型t1和t2之间的相似度;
比较患者描述表型集与所有相关疾病表型集的相似度,相似度值越大,则患者罹患当前相似度对应疾病的概率越大。
本发明的有益效果为:本方案通过独特的算法计算患者表型与所有已知疾病的相似度,能够很好地排除患者描述表型数据不完备、带有噪音和描述不够准确等带来的不确定性;将采用本方案的方法与现有通过相似度定位疾病的resnik、jc和lin方法在同等模拟环境下进行模拟实验,通过数据对比,本方案抗外界干扰因素明显高于现有技术中采用相似度的三种方法。
附图说明
图1为本发明疾病的快速辅助定位方法一个实施例的流程图。
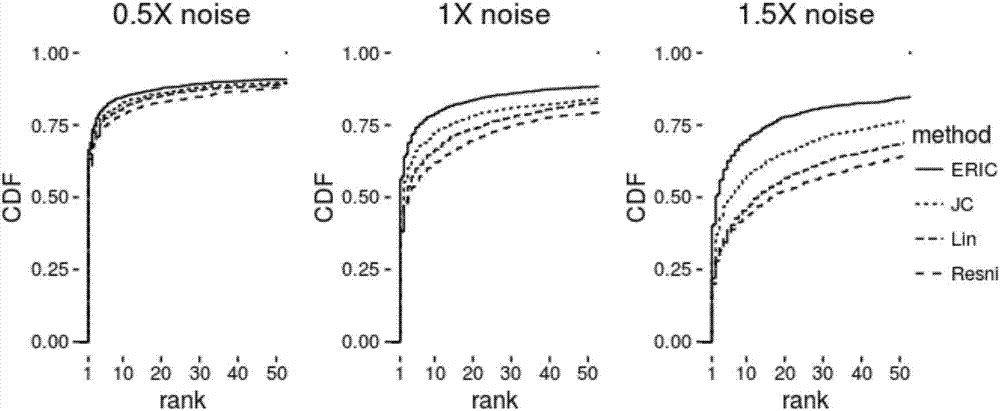
图2为模拟测试时,添加0.5倍,1倍和1.5倍噪音后,本方案与现有技术中的resnik、jc和lin方法抵抗噪音干扰时的效果图。
图3为模拟测试时,先抽取50%表型,然后分别替换其中的30%、50%和90%的表型作为每个表型对应的任意一个祖先表型后,本方案与现有技术中的resnik、jc和lin方法抵抗不精确描述时的效果图。
图4为模拟测试时,先抽样50%的表型,不精确部分表型,在添加不同程度的噪音后,本方案与现有技术中的resnik、jc和lin方法抵抗混合效应时的效果图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
参考图,图1示出了本发明疾病的快速辅助定位方法一个实施例的流程图。如图1所示,该方法100包括步骤101至步骤104。
在步骤101中,接收患者描述的罹患疾病的所有表型;为了便于后面患者罹患疾病的相似度与数据库中疾病的相似度计算,此处将患者描述的所有表型构建成一个集合,即采用接收的所有表型构建患者描述表型集。
在本发明的一个实施例中,表型注释数据库为从人类表型本体官方网站获得的罕见疾病和每种罕见疾病对应的表型构建而成。
由于数据集中的所有疾病及每种疾病的相关表型均来自于全球权威机构,而不是自己从各种数据网址收集整理而来,更助于后面准确定位疾病的准确性和可靠性。
在步骤102中,获取表型注释数据库中具有患者描述的表型的所有疾病,此处的疾病的所有表型中至少包括一种患者描述的表型。
在步骤103中,查找每种疾病所对应的表型,此处为便于后续相似度计算,同理也可以将每种疾病所对应的表型分别构建成一个集合,即采用每种疾病所对应的表型分别构建相关疾病表型集。
在步骤104中,计算患者描述表型集与每个相关疾病表型集的相似度:
其中,t1为患者描述表型集;t2为相关疾病表型集;sim(t1,t2)为集合t1与集合t2之间的相似度;t1和t2疾病所对应的两种不同的表型;sim(t1,t2)为表型t1和t2之间的相似度;
在本发明的一个实施例中,表型t1和t2之间的相似度sim(t1,t2)的具体算法为:
sim(t1,t2)=2ic(tmica)-min(ic(t1),ic(t2))
其中,tmica为表型t1和t2的最大信息量共同祖先节点;ic(tmica)为两个表型t1和t2共同的祖先tmica的信息量;ic(t1)和ic(t2)分别为表型t1和t2的信息量;min(ic(t1),ic(t2)表示取ic(t1)和ic(t2)两者中最小值。
实施时,优选表型的信息量的具体算法为:
ic(t)=log(n/nt)
其中,n为从表型注释数据库获取的所有疾病的数量;t为疾病所对应的表型;nt为具有表型t的疾病数量;ic代表每个表型的信息量。
在步骤105中,比较患者描述表型集与所有相关疾病表型集的相似度,相似度值越大,则患者罹患当前相似度对应疾病的概率越大。
在本发明的一个实施例中,该疾病的快速辅助定位方法还包括对患者描述表型集与所有相关疾病表型集的相似度按照疾病的维度进行排序,并输出排序结果。
通过输出的排序结果,用户可以动态地增减或修改描述的表型,以达到罹患疾病的精确定位。
下面选取dddg2p(developmentdisordergenotype–phenotypedatabase数据库(https://decipher.sanger.ac.uk)对现有技术中resnik、jc和lin与本方案的方法(下面用eric表示)进行模拟测试。
其中,dddg2p(developmentdisordergenotype–phenotypedatabase数据库包含了大约25000个疾病和表型间的对应关系,包括1300种发育相关的疾病和大约4000个人类表型本体(hpo)表型术语。
噪音对比测试
由于个体遗传和环境等差异,临床患者还可能表现出跟真实疾病记录无关或者不一致的表型(噪音),我们采用如下步骤生成带噪音的患者描述表型集。
首先,每种疾病我们随机抽取50%的表型,每种疾病抽样10次,添加0.5倍,1倍和1.5倍的噪音,计算带噪音抽样表型跟每个疾病所有表型的相关疾病表型集的相似性,如果目标疾病(真实表型数据来源的疾病)的排名越靠前则说明抗噪音能力越好。
通过模拟测试输出的图像(参考图2)可以发现抵抗噪音能力依次为:eric>jc>lin>resnik,可见本方案提供的方法(eric)比其它方法更能抵抗噪音的影响。
参见表1,在1.5倍噪音时,排名前5的疾病,eric依次能比jc、lin和resnik多13.8%,23.3%和25.7%。
表11.5倍噪音时真实疾病排名
不精确描述测试
临床上患者描述疾病的表型可能比较宽泛,不精确,因此我们还需要模拟不精确描述的影响。同样先抽取50%表型,然后分别替换其中的30%、50%和90%的表型作为每个表型对应的任意一个祖先表型。
通过模拟测试输出的图像(参考图3)可以发现eric和resnik抵御不精确描述的能力比较一致,且都优于jc和lin方法。
参见表2,在90%的不精确描述时,排名前5的疾病eric和resnik比jc和lin多大约8%。
表290%不精确描述时的真实疾病排名
混合效应测试
真实的临床使用时,会同时受到噪音和不精确描述的影响。为了评估这种混合效应的影响,我们抽样50%的表型,然后分别替换其中50%的表型作为每个表型对应的任意一个祖先表型,之后再添加1倍的噪音进行模拟测试。
通过模拟测试分别计算相似度后,我们发现eric仍然是表现最好的,测试数据参考图4和表3。
表31倍和50%不精确描述时真实疾病排名
综上所述,本方案通过独特的计算方式计算的相似度确定为某种疾病的方式与现有的resnik、jc和lin相比,具有更好的抗噪声性能,更能容忍不精确表型描述带来的干扰。
- 还没有人留言评论。精彩留言会获得点赞!