一种基于知识图谱的爬取种子列表更新方法及装置与流程
本发明属于数据采集领域,尤其涉及一种基于知识图谱的爬取种子列表更新方法及装置。
背景技术:
网络爬虫是一种自动提取网页的程序,它协助搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统网络爬虫从一个或若干初始url开始,爬取初始url的网页并获取初始url的网页上链接的url,在爬取网页的过程中,不断从当前网页上获取新的url放入待爬取队列,直到满足系统的一定停止条件。
为满足海量数据爬取的需求,网络爬虫系统一般采用大规模分布式架构。在这种架构中,如何过滤与搜索主题无关的网页成为提高网络爬虫系统爬取方向精确性和爬取效率的关键。传统的分布式网络爬虫系统通常采用简单的网页去重机制。这种机制虽然能避免爬取重复的网页,但没有考虑爬取的网页内容与搜索主题的相关性,因此无法做到精确、高效的网页爬取,从而影响了分布式网络爬虫系统爬取网页的性能以及爬取网页的质量。
技术实现要素:
本发明的目的是提供一种基于知识图谱的爬取种子列表更新方法及装置,通过在网页爬取的过程中,不断计算爬取网页内容与搜索主题的相似度,并过滤掉与搜索主题相似度不高的网页,从而达到提高爬取网页准确度和爬取网页效率的目的。
为了实现上述目的,本发明技术方案如下:
一种基于知识图谱的爬取种子列表更新方法,用于爬虫系统在爬取网页的过程中获取爬取种子,所述基于知识图谱的爬取种子列表更新方法,包括:
从初始的爬取种子列表中选取一个种子,所述初始的爬取种子列表中的种子对应的网页内容与搜索主题的相似度大于设定的相似度阈值;
爬取该种子的网页,从该种子的网页中提取出所有链接的url作为新种子;
爬取新种子的网页,基于知识图谱计算出所述新种子对应的网页内容与搜索主题的相似度;
用所述新种子的相似度与设定的相似度阈值进行比对,如果所述新种子的相似度大于设定的相似度阈值,则将该新种子加入爬取种子列表中,否则直接丢弃该新种子。
本发明的一种实现方式,所述基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,包括:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k;
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn;
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn;
统计新种子对应的网页内容中各实体k1,k2,...,kn出现的次数l1,l2,...,ln,并结合各实体k1,k2,...,kn的权重d1,d2,...,dn,通过如下公式计算出新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,li为实体ki在新种子的网页内容中出现的次数,l为各实体k1,k2,...,kn在新种子对应的网页内容中出现次数的总和,s为新种子对应的网页内容与搜索主题的相似度。
本发明的另一种实现方式,所述基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,包括:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k;
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn;
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn;
查询新种子对应的网页内容中是否存在各实体k1,k2,...,kn,如果存在某个实体ki,则保持该实体的权重di不变,如果不存在某个实体ki,则将该实体的权重di置为0,然后通过如下公式计算出新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,n为知识图谱中查找到的与实体k相关的实体的数量,s为新种子对应的网页内容与搜索主题的相似度。
进一步地,所述基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,还包括:
根据所述新种子的父种子的相似度,对新种子对应的网页内容与搜索主题的相似度进行更新,更新公式为:
更新后新种子的相似度=父种子的相似度*新种子的相似度s/设定的相似度阈值。
进一步地,所述将新种子加入爬取种子列表中,包括:
在将新的种子加入爬取种子列表中时,会按照新种子对应的网页内容与搜索主题的相似度由高到低的顺序,在爬取种子列表中进行排序。
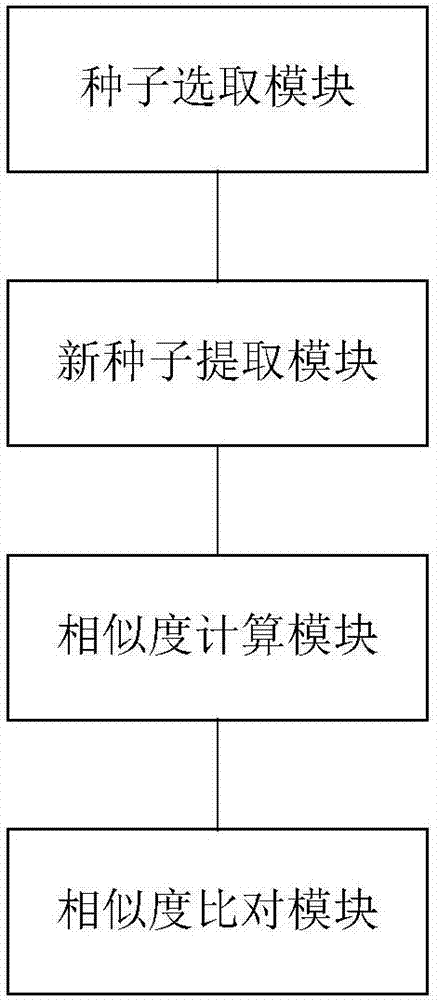
本发明还提出了一种基于知识图谱的爬取种子列表更新装置,用于爬虫系统在爬取网页的过程中获取爬取种子,所述基于知识图谱的爬取种子列表更新装置,包括:
种子选取模块,用于从初始的爬取种子列表中选取一个种子,所述初始的爬取种子列表中的种子对应的网页内容与搜索主题的相似度大于设定的相似度阈值;
新种子提取模块,用于爬取该种子的网页,从该种子的网页中提取出所有链接的url作为新种子;
相似度计算模块,用于爬取新种子的网页,基于知识图谱计算出所述新种子对应的网页内容与搜索主题的相似度;
相似度比对模块,用于用所述新种子的相似度与设定的相似度阈值进行比对,如果所述新种子的相似度大于设定的相似度阈值,则将该新种子加入爬取种子列表中,否则直接丢弃该新种子。
本发明的一种实现方式,所述相似度计算模块基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,执行如下操作:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k;
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn;
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn;
统计新种子对应的网页内容中各实体k1,k2,...,kn出现的次数l1,l2,...,ln,并结合各实体k1,k2,...,kn的权重d1,d2,...,dn,通过如下公式计算出新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,li为实体ki在新种子的网页内容中出现的次数,l为各实体k1,k2,...,kn在新种子对应的网页内容中出现次数的总和,s为新种子对应的网页内容与搜索主题的相似度。
本发明的另一种实现方式,所述相似度计算模块基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,执行如下操作:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k;
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn;
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn;
查询新种子对应的网页内容中是否存在各实体k1,k2,...,kn,如果存在某个实体ki,则保持该实体的权重di不变,如果不存在某个实体ki,则将该实体的权重di置为0,然后通过如下公式计算出新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,n为知识图谱中查找到的与实体k相关的实体的数量,s为新种子对应的网页内容与搜索主题的相似度。
进一步地,所述相似度计算模块基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,还执行如下操作:
根据所述新种子的父种子的相似度,对新种子对应的网页内容与搜索主题的相似度进行更新,更新公式为:
更新后新种子的相似度=父种子的相似度*新种子的相似度s/设定的相似度阈值。
进一步地,所述相似度比对模块将新种子加入爬取种子列表中,执行如下操作:
在将新的种子加入爬取种子列表中时,会按照新种子对应的网页内容与搜索主题的相似度由高到低的顺序,在爬取种子列表中进行排序。
本发明提出了一种基于知识图谱的爬取种子列表更新方法及装置,通过利用已经建立的知识图谱计算所爬取的网页内容与搜索主题的相似度,并通过设定的相似度阈值过滤掉与搜索主题相似度不高的网页,逐步调整网页爬取的方向,提高了爬取网页的准确度以及爬取网页的效率。
附图说明
图1为本发明基于知识图谱的爬取种子列表更新方法的流程图;
图2为本发明基于知识图谱的爬取种子列表更新装置的结构图。
具体实施方式
下面结合附图和实施例对本发明技术方案做进一步详细说明,以下实施例不构成对本发明的限定。
随着互联网的信息量飞速增长以及人们对搜索引擎的要求越来越高,传统搜索引擎的局限性,如覆盖率低、时效性差、结果不准确、返回不相关的结果太多等缺点逐渐体现,近年来google、百度、搜狗等搜索引擎公司通过构建知识图谱很好地解决了上述问题来,大大提高了搜索的质量。
知识图谱是一种基于图的数据结构,由节点和边组成,每个节点表示现实世界中存在的实体,每条边为实体与实体之间的关系。知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,知识图谱提供了从关系的角度去分析问题的能力。不同于基于关键词搜索的传统搜索引擎,通过知识图谱可以更好地查询复杂的关联信息,从语义层面理解用户的意图,提高搜索质量。
构建知识图谱的一般过程如下:
(1)确定数据来源,例如:wikipedia,freebase等百科类数据;dbpedia和yago等通用语义数据集;musicbrainz和drugbank等特定领域的知识库。
(2)实体对齐(objectalignment),即发现具有不同表述但却代表真实世界中同一对象的那些实体,并将这些实体归并为一个具有全局唯一标识的实体对象添加到知识图谱中,针对多种来源数据一般采用聚类算法实现,其关键在于定义合适的相似度度量。
(3)知识图谱schema构建,建立本体(ontology)。最基本的本体包括概念、概念层次、属性、属性值类型、关系、关系定义域概念集以及关系值域概念集。
(4)解决不一致性问题。优先采用那些可靠性高的数据源抽取得到的事实。
(5)相关实体挖掘。使用主题模型发现虚拟文档集中的主题分布,其中每个主题包含1个或多个实体,这些在同一个主题中的实体互为相关实体。
本实施例根据上述知识图谱的特点,在网络爬虫系统爬取网页的过程中,利用已经构建好的知识图谱计算所爬取的网页内容与搜索主题的相似度,并通过设定的相似度阈值对所爬取的网页进行过滤,能大大提高网络爬虫系统所爬取网页的准确度和爬取的效率。
本实施例一种基于知识图谱的爬取种子列表更新方法,如图1所示,包括:
步骤s1、从初始的爬取种子列表中选取一个种子,所述初始的爬取种子列表中的种子对应的网页内容与搜索主题的相似度大于设定的相似度阈值。
本实施例爬虫系统针对每个不同的搜索主题,通过手工设定有多个种子,爬虫系统在开始进行网页爬取时,首先根据用户输入的搜索主题,将手工设定的多个种子加入爬取种子列表中,作为初始的爬取种子列表。
由于手工设定的种子是通过人工精心选取的与搜索主题高度相似的种子url,因此所有手工设定的种子对应的网页内容与搜索主题的相似度都远大于设定的相似度阈值。或者对初始的爬取种子列表中的种子,爬取其对应的网页,基于知识图谱计算出该种子对应的网页内容与搜索主题的相似度,将相似度大于设定的相似度阈值的种子保留,去除相似度小于等于设定的相似度阈值的种子,最终形成初始的爬取种子列表。
然后,爬虫系统从爬取种子列表中取出一个种子,通过互联网爬取该种子的网页。
步骤s2、爬取该种子的网页,从该种子的网页中提取出所有链接的url作为新种子。
本实施例爬虫系统爬取种子的网页后,分析该种子对应的网页内容,从该种子的网页中提取出所有链接的url作为新种子。
例如,从种子a对应的网页内容中提取出链接的url分别为:
http://dajia.qq.com/blog/371783083688920
http://view.news.qq.com/original/intouchtoday/n3709.html
http://view.news.qq.com/original/intouchtoday/n3704.html
则将上述3个链接的url作为新种子,种子a是这些新种子的父种子。
步骤s3、爬取新种子的网页,基于知识图谱计算出所述新种子对应的网页内容与搜索主题的相似度。
本实施例在获取新种子后,爬取每个新种子的网页,根据知识图谱对新种子对应的网页内容进行分析,计算出新种子对应的网页内容与搜索主题的相似度,具体计算方法如下:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k。
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn。
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn。
统计新种子对应的网页内容中各实体k1,k2,...,kn出现的次数l1,l2,...,ln,并结合各实体k1,k2,...,kn的权重d1,d2,...,dn,计算出新种子对应的网页内容与搜索主题的相似度。
优选地,本实施例通过如下公式计算新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,li为实体ki在新种子对应的网页内容中出现的次数,l为各实体k1,k2,...,kn在新种子对应的网页内容中出现次数的总和,s为新种子对应的网页内容与搜索主题的相似度。
下面通过举例对上述计算方法进行说明:
例如,搜索主题为“新媒体”;从知识图谱中查找到的实体k为“新媒体”,从知识图谱中搜索出来新媒体的相关实体分别为:k1=“微信”、k2=“阅读”、k3=“微博”,并且“微信”的权重d1为10%,“阅读”的权重d2为5%,“微博”的权重d3为10%。
新种子对应的网页内容为“公共阅读氛围的缺失,本质上是一种文化与价值观的缺失。目前,在文化传播领域,劣币驱逐良币的现象依然广泛存在。浅阅读占据了阅读者相当多的时间,需要花时间和精力的深阅读越来越少。很多人把自己的阅读主阵地转移到了微信公众号等新媒体平台,对这转变本身不必有价值褒贬,但是,恰恰是新媒体传播了大量低水平的阅读内容。如何提升新媒体阅读的层次,将有价值的、深度的内容新媒体化,恐怕是提高公共阅读层次的一大挑战。”
从该网页内容中统计出“微信”出现了1次,“阅读”出现了8次,则计算出新种子对应的网页内容与搜索主题的相似度为:s=(10%*1+5%*8)/(1+8)=5.56%。
需要说明的是,本实施例还可以通过如下方法计算新种子对应的网页内容与搜索主题的相似度:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k。
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn。
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn。
查询新种子对应的网页内容中是否存在各实体k1,k2,...,kn,如果存在某个实体ki,则保持该实体的权重di不变,如果不存在某个实体ki,则将该实体的权重di置为0,然后通过如下公式计算出新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,n为知识图谱中查找到的与实体k相关的实体的数量,s为新种子对应的网页内容与搜索主题的相似度(新种子的相似度)。
需要说明的是,本实施例在计算出新种子对应的网页内容与搜索主题的相似度之后,还可以根据该新种子的父种子的网页内容与搜索主题的相似度(父种子的相似度),对该新种子对应的网页内容与搜索主题的相似度进行更新,将更新后的新种子的相似度作为最终新种子的相似度,以进一步优化爬虫系统在爬取网页时的方向选择。具体的更新方法为:
更新后新种子的相似度=父种子的相似度*新种子的相似度s/设定的相似度阈值。
容易理解的是,初始的爬取种子列表中的种子由手工设定,其网页内容与搜索主题的相关度已知,后续加入爬取种子列表中的新种子的网页内容与搜索主题的相关度,在将该新种子加入爬取种子列表已经计算出来了,因此本实施例在对新种子的相似度进行更新时,其父种子的相似度都是已知的。
通过上述方法,本实施例计算出新种子对应的网页内容与搜索主题的相似度。
步骤s4、用所述新种子的相似度与设定的相似度阈值进行比对,如果所述新种子的相似度大于设定的相似度阈值,则将该新种子加入爬取种子列表中,否则直接丢弃该新种子。
本实施例在计算出新种子对应的网页内容与搜索主题的相似度之后,用计算出的新种子对应的网页内容与搜索主题的相似度与设定的相似度阈值进行比对,如果新种子的相似度大于设定的相似度阈值,则将新种子加入爬取种子列表中,并将该新种子输出到候选的搜索结果列表中,由搜索引擎进行后续的处理。
需要说明的是,本实施例在将新种子加入爬取种子列表中时,会按照该新种子对应的网页内容与搜索主题的相似度由高到低的顺序,在爬取种子列表中进行排序,使爬虫系统优先爬取网页内容与搜索主题的相似度高的新种子,以进一步提高爬取网页的准确度和爬取网页的效率。
如果计算出的新种子对应的网页内容与搜索主题的相似度小于设定的相似度阈值,则直接丢弃该新种子。
本实施例通过对爬取种子列表中的种子爬取其对应的网页,并将新种子加入到爬取种子列表,不断更新爬取种子列表,并通过遍历爬取种子列表中所有种子实现网页爬取,从而实现在爬虫系统爬取网页过程中,逐步调整网页爬取的方向,提高爬取网页的准确度以及爬取网页的效率。
如图2所示,本实施例还提出了一种基于知识图谱的爬取种子列表更新装置,用于爬虫系统在爬取网页的过程中获取爬取种子,所述基于知识图谱的爬取种子列表更新装置,包括:
种子选取模块,用于从初始的爬取种子列表中选取一个种子,所述初始的爬取种子列表中的种子对应的网页内容与搜索主题的相似度大于设定的相似度阈值;
新种子提取模块,用于爬取该种子的网页,从该种子的网页中提取出所有链接的url作为新种子;
相似度计算模块,用于爬取新种子的网页,基于知识图谱计算出所述新种子对应的网页内容与搜索主题的相似度;
相似度比对模块,用于用所述新种子的相似度与设定的相似度阈值进行比对,如果所述新种子的相似度大于设定的相似度阈值,则将该新种子加入爬取种子列表中,否则直接丢弃该新种子。
与上述方法对应地,本发明的一种实施例,相似度计算模块基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,执行如下操作:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k;
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn;
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn;
统计新种子对应的网页内容中各实体k1,k2,...,kn出现的次数l1,l2,...,ln,并结合各实体k1,k2,...,kn的权重d1,d2,...,dn,通过如下公式计算出新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,li为实体ki在新种子的网页内容中出现的次数,l为各实体k1,k2,...,kn在新种子对应的网页内容中出现次数的总和,s为新种子对应的网页内容与搜索主题的相似度。
本发明的另一实施例,相似度计算模块基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,执行如下操作:
将搜索主题输入到知识图谱中,查找到知识图谱中该搜索主题对应的实体k;
利用知识图谱中的搜索工具,在知识图谱中查找到与实体k相关的n个实体k1,k2,...,kn;
从知识图谱中获取实体k1,k2,...,kn到实体k的距离d1,d2,...,dn,即获取实体k1,k2,...,kn的权重d1,d2,...,dn;
查询新种子对应的网页内容中是否存在各实体k1,k2,...,kn,如果存在某个实体ki,则保持该实体的权重di不变,如果不存在某个实体ki,则将该实体的权重di置为0,然后通过如下公式计算出新种子对应的网页内容与搜索主题的相似度:
其中,di为实体ki的权重,n为知识图谱中查找到的与实体k相关的实体的数量,s为新种子对应的网页内容与搜索主题的相似度。
本实施例相似度计算模块基于知识图谱计算出新种子对应的网页内容与搜索主题的相似度,还执行如下操作:
根据所述新种子的父种子的相似度,对新种子对应的网页内容与搜索主题的相似度进行更新,更新公式为:
更新后新种子的相似度=父种子的相似度*新种子的相似度s/设定的相似度阈值。
本实施例相似度比对模块将新种子加入爬取种子列表中,执行如下操作:
在将新的种子加入爬取种子列表中时,会按照新种子对应的网页内容与搜索主题的相似度由高到低的顺序,在爬取种子列表中进行排序。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!