本发明属于数据挖掘技术领域,具体涉及一种带属性社交网络重叠社区划分方法,可用于用户画像、个性化推荐和自动好友分类。
背景技术:
社区结构是复杂网络的一个重要属性,它是指网络可以划分成很多社区,社区内的点紧密相连,社区间的点连接稀疏。同一社区内的点往往具有相似的性质,可以提供重要的信息。社区检测就是发现隐藏在网络中的社区结构,其对理解网络的功能,探索隐藏在网络中的信息,追踪网络的行为有重要意义。近年来,随着facebook、twitter、微信、google+等社交网络的飞速发展,针对社交网络的社区发现方法迫切需求。
针对社交网络社区发现问题,已经存在多种不同的优化算法。girvan等人于2002年提出了基于分割边介数的社区检测方法gn,该方法与类似算法相比其运行速度大为改进。newman于2004年提出了极大化网络模块度q函数的算法fn,至此q成为了评价社区检测的重要指标。上述的这些算法只关注了网络的拓扑结构。然而,与一般网络相比,社交网络拥有更丰富的信息。社交网络中的用户除了拥有丰富的边连接关系之外,还拥有丰富的属性信息,比如:年龄,爱好,高中毕业学校,职业,政治立场等。边连接关系是一种强关系,若有边相连的两个用户,则说明他们属于一个圈子。而属性是一种弱关系,属于同一个圈子的用户往往在某些属性上趋于一致,因此结构和属性信息对于社区发现来说都是有用信息。
近年来,国内外学者提出了一些同时考虑结构和属性信息的社区发现算法。例如zhou等人提出了sa-cluster算法,其将属性信息作为节点对网络进行扩充,构建了随机游走模型来评价节点的紧密度。但是该方法需要事先指定社区个数,而社区的数目在真实的网络中通常是未知的。dang等人提出了算法sac1和sac2,这两种算法均设计了两个函数来评价网络的结构和属性相似度,并通过对两个目标加权求和转化为单目标来优化。然而,该方法需要人工指定目标权重,收敛速度慢。
上述的所有算法都没有考虑社区的重叠关系,而社交网络中的一个人可以属于多个圈子,因而不能更好的实现微信和facebook网络中的自动好友分类。
为此,liu等人于2010年提出了一个基于多目标进化的重叠社区检测算法,其应用了基于排列的编码方式,从而可以获得重叠社区划分,但该方法由于没有考虑节点的属性信息,不适用于带属性社交网络社区划分。
综上,现有技术针对社交网络由于没有同时考虑节点的属性信息和社区之间的重叠关系,因而得到的网络划分不准确。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种基于多目标进化的带属性社交网络社区划分方法,以提高网络划分的准确性。
本发明的技术思路是:针对社交网络的属性信息,对多目标优化算法moea/d进行改进,构建了属性相似度函数sa,应用局部贪婪的思想,设计局部结构和属性相似度最优的解码方式,获得有实际意义的重叠社区;并通过优化两个目标函数eq和sa,获得高度准确的社区划分。
根据上述思路,本发明的技术方案包括如下操作:
(1)设定参数:即设定种群中染色体的个数m为100,最大迭代次数g为1000,种群中染色体的邻居个数tn为20,网络中节点的个数表示为n;
(2)初始化种群:将迭代次数t的初始设置为1,应用基于排列的编码表示,随机生成m个染色体,记为a(p1),a(p2),…,a(pj),…a(pm),其中a(pj)表示种群中第j个染色体,j=1,2……m;
(3)基于局部结构和属性紧密度对种群中的染色体a(pj)进行解码,生成具有重叠的社区划分a(cj);
(4)构建属性相似度函数sa为:
其中,z表示第z个社区,s(a,b)表示节点a和节点b的余弦相似度,rz代表社区z中节点的个数;
(5)利用拓展模块度函数eq和属性相似度函数sa,利用如下公式分别计算m个社划分适应度函数f:f=λt×|eq-ft|+λa×|sa-fa|,
其中,ft代表当前种群中所有个体的拓展模块度函数eq最优值,fa代表当前种群中所有个体的属性相似度函数sa最优值,ft和fa初始化为无穷小,λt代表结构紧密度权重,λa代表属性相似度权重;
(6)产生新的染色体,生成新的种群:
(6a)初始化j为1,在a(pj)邻居内随机选两个染色体作为父代染色体a(pj1)和并对这两者进行匹配交叉,生成两个新染色体和
(6b)对两个父代新染色体a(pj1)和进行解码,生成两个社区划分a(cj1)和对a(cj1)和利用步骤(4)的公式分别计算其属性相似度,并分别计算其拓展模块度,再利用步骤(5)中的公式分别计算a(cj1)的适应度f1和的适应度f2;
(6c)对两个新染色体和进行解码,生成两个社区划分和对和利用步骤(4)的公式分别计算其属性相似度,并分别计算其拓展模块度,再利用步骤(5)中的公式分别计算的适应度f3和的适应度f4;
(6d)将步骤(6b)与步骤(6c)的结果进行对比:如果f3大于f1,则用替代a(pj1);如果f4大于f2,则用替代否则不做替代;
(6e)对a(pj)染色体实施转换基因位变异,生成一个新染色体
(6f)对a(pj)解码生成社区划分a(cj),利用步骤(4)的公式计算其属性相似度,并计算其拓展模块度,再利用步骤(5)中的公式计算其适应度f6;
(6g)对新染色体解码生成社区划分利用步骤(4)的公式计算其属性相似度,并计算其拓展模块度,再利用步骤(5)中的公式计算的适应度f5;
(6h)将步骤(6f)与步骤(6g)的结果进行对比:如果f5大于f6,则用替代a(pj),否则不做替代;
(6i)判断j是否等于m,若是,执行步骤(7);否则,令j=j+1,返回步骤(6a);
(7)判断t是否等于g,如果是,输出社区的划分结果;否则,令t=t+1,返回步骤(6);
本发明与现有的技术相比具有以下优点:
1.本发明由于设计了评价属性相似度的目标函数sa,可有效处理社交网络中的属性信息。
2.本发明由于采用基于局部结构和属性相似度相结合的解码方式。可获得有实际意义的重叠社区。
3.本发明由于将多目标算法应用于带属性社交网络社区划分中,并通过优化eq和sa两个目标函数,提高了社区划分的准确性。
附图说明
图1是本发明的实现流程图;
图2是本发明对实验数据仿真结果显示图。
具体实施方式
以下结合附图,对本发明的技术方案和效果作进一步详细描述。
参照图1,本发明的实施步骤如下:
步骤1.设定参数。
设定种群中染色体的个数m为100,最大迭代次数g为1000,种群中染色体的邻居个数tn为20,染色体中基因的个数表示为n。
步骤2.初始化种群。
将迭代次数t的初始设置为1,应用基于排列的编码表示,随机生成m个染色体,记为a(p1),a(p2),…,a(pj),…a(pm),其中a(pj)表示种群中第j个染色体,j=1,2……m,例如,如果n=5,a<pj>的排列有多种形式,其中一种排列为<2,3,1,5,4>,另一种排列为<1,3,2,5,4>;同理,如果n=6,a<pj>的一种排列为<2,3,1,5,4,6>,另一种排列为<1,6,3,2,5,4>。
步骤3.基于局部结构和属性紧密度对种群中的染色体a(pj)进行解码,生成具有重叠的社区划分a(cj)。
(3a)令社区集合为c,并初始为空,cz表示第z个社区,z=1,2,……|c|,|c|表示c中社区的个数;
(3b)初始化i为1,在染色体a(pj)中选取第i个基因;
(3c)依次遍历1到|c|个社区,将第i个基因放入cz中;
(3d)利用如下公式分别计算基因i加入cz社区前的局部结构紧密度ql1和基因i加入cz社区后的局部结构紧密度ql2:
其中,kincz和koutcz分别表示cz社区内部的所有点的内度和外度;
(3e)利用如下公式分别计算基因i加入cz社区前的局部属性紧密度sl1和基因i加入cz社区后的局部属性紧密度sl2:
其中,s(a,b)表示节点a与节点b之间的属性相似度,rcz代表社区z中节点的个数;
(3f)比较基因i加入cz社区前后ql和sl的值,用p表示(0,1)之间的随机数:若不满足(p<0.5且sl2>sl1)或(p<0.8且ql2>ql1)或(ql2>ql1且sl2>sl1),则在社区cz中移出基因i,否则,不移出;
(3g)判断基因i是否被加入社区,若不是,则构建新社区cz+1,并将i加入cz+1,否则,不构建;
(3h)判断节点i是否等于基因的个数n,若是,解码结束,否则,返回步骤(3b)。
步骤4.构建属性相似度函数sa为:
其中,z表示第z个社区,s(a,b)表示节点a和节点b的余弦相似度,rz代表第z个社区中节点的个数。
步骤5.构建适应度函数。
构建适应度函数,首先需要计算模块度函数eq和属性相似度函数sa,其中拓展模块度函数eq的计算公式如下:
式中,m表示网络中边的个数,z表示第z个社区,ov表示节点v所属社区的个数,ow表示节点w所属于社区的个数,kv表示节点v的度,kw表示节点w的度,avw表示节点v和节点w的边连接关系,当节点v和节点w之间存在边连接时,则avw的取值为1,否则,其值为0;
利用拓展模块度函数eq和属性相似度函数sa,得到计算m个社区划分适应度函数f:
f=λt×|eq-ft|+λa×|sa-fa|,
其中,ft代表当前种群中所有个体的拓展模块度函数eq最优值,fa代表当前种群中所有个体的属性相似度函数sa最优值,ft和fa初始化为无穷小,λt代表结构紧密度权重,λa代表属性相似度权重。
步骤6.产生新的个体,生成新的种群。
(6a)初始化j为1,在a(pj)邻居内随机选两个染色体作为父代染色体a(pj1)和并对这两者进行匹配交叉,生成两个父代新染色体和
(6b)对两个父代染色体a(pj1)和进行解码,生成第1个社区划分a(cj1)和第2个社区划分即利用步骤(4)的公式对a(cj1)和分别计算其属性相似度,并分别计算其拓展模块度,再利用步骤(5)中的公式分别计算a(cj1)的适应度,即第1适应度f1和的适应度,即第2适应度f2;
(6c)对两个父代新染色体和进行解码,生成第3个社区划分和第4个社区划分对这两个新社区划分和利用步骤(4)的公式分别计算其属性相似度,并分别计算其拓展模块度,再利用步骤(5)中的公式分别计算的适应度,即第3适应度f3和的适应度,即第4适应度f4;
(6d)将步骤(6b)与步骤(6c)的结果进行对比:如果f3大于f1,则用替代a(pj1),否则不做替代;如果f4大于f2,则用替代否则不做替代;
(6e)对a(pj)染色体实施转换基因位变异,生成一个变异后的新染色体
(6f)对a(pj)进行解码,生成第5个社区划分利用步骤(4)的公式计算其属性相似度,并计算其拓展模块度,再利用步骤(5)中的公式计算其适应度,即第5适应度f5;
(6g)对变异后的新染色体进行解码,生成第6个社区划分利用步骤(4)的公式计算其属性相似度,并计算其拓展模块度,再利用步骤(5)中的公式计算的适应度,即第6适应度f6;
(6h)将步骤(6f)与步骤(6g)的结果进行对比:如果f6大于f5,则用替代a(pj),否则不做替代;
(6i)判断j是否等于m,若是,执行步骤(7);否则,令j=j+1,返回步骤(6a)。
步骤7.判断t是否等于g,如果是,输出社区的划分结果;否则,令t=t+1,返回步骤(6)。
本发明的效果可以通过仿真实验进行验证:
1.实验条件
1.1)实验环境:处理器为intel(r)core(tm)i3cpu550@3.2ghz3.19ghz,内存为3.05gb,硬盘为1t,操作系统为microsoftwindows7,编程环境为visiostudio2012。
1.2)实验数据:
美国政治图书网:该网络是亚马逊网站政治图书间的关系图,每本书具有属性政治派系,可取值为:保守,自由,中立。
facebook自我网络数据集:该数据集包含10个自我网络,共有193个圈子和4039个用户。自我网是由一个用户的所有好友组成的网络。其中,这10个自我网络中的用户都拥有多个属性,属性维度是42到576。所有属性已通过独热编码预处理。
上述所有带属性网络的汇总信息见表1。
表1实验数据的统计信息
2.评价指标:
2.1)用社区紧密度t用于评价社区内结构的优劣,其计算公式如下:
其中,m表示网络中边的个数,z表示第z个社区,ov表示节点v所属于社区的个数,ow表示节点w所属于社区的个数,avw表示节点v和节点w的边连接关系,当节点v和节点w之间存在边连接时,则avw的取值为1,否则,其值为0;
2.2)用熵e评价社区内属性的同质性,其计算公式如下:
其中,z表示第z个社区,d表示属性维数,d代表第d个属性,rz表示第z个社区中节点的个数,代表社区z中属性d取值为j的概率。
t越大代表社区内节点连接越紧密,e越小代表社区内节点属性更同质。
3.实验内容和结果分析
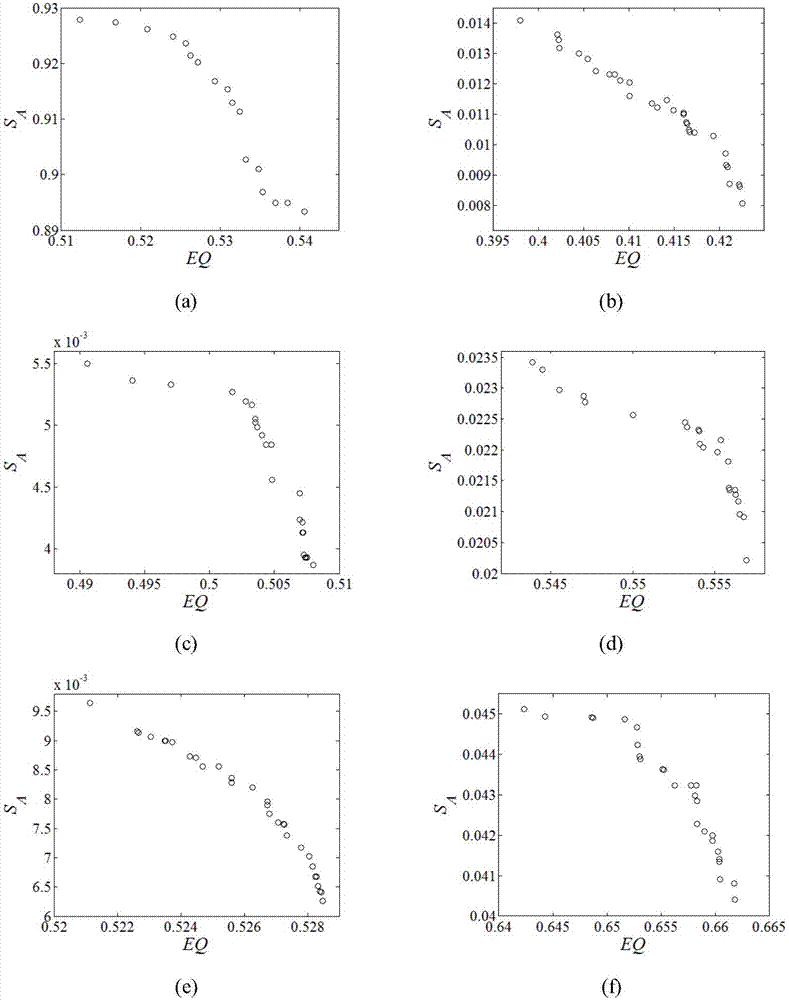
实验1.针对表1中的六个网络,分别用本发明进行社区划分,对每个网络,独立重复运行30次并取平均值,其结果如图2所示。其中,图2(a)表示划分的politicalbooks网络,图2(b)表示划分的ego_0网络,图2(c)表示划分的ego_107网络,图2(d)表示划分的ego_1684网络,图2(e)表示划分的ego_1912网络,图2(f)表示划分的ego_3437网络。
从图2中可以看出,eq在所有网络中的值都大于0.3,表明本发明所得划分具有明显的社区结构。sa在所有网络中的值都达到0.001,表明本发明很好的平衡了网络的拓扑结构和节点的属性信息,提高了社区划分的准确性。
实验2.为了评价本发明所得划分的质量,分别对每个网络计算密度t和熵e,结果见表2。
表2每个网络的密度t和熵e
从表2中可以看出,本发明的在每个网络中密度t的平均值都大于0.6,表明本发明所得划分具有明显的社区结构,而其标准差都小于0.12,表明本发明涉及的方法具有很好的稳定性。所有网络熵e的最小值都小于0.3,而其标准差都小于0.01,表明本发明所得社区划分其内部属性是高度同质且稳定的。