人机交互自适应调整方法及系统与流程
本发明涉及计算机应用领域,尤其涉及一种人机交互自适应调整方法以及系统。
背景技术:
利用深度相机(3d相机)可以获取人体的深度图像,进一步利用深度图像可以识别出人体姿势或动作从而实现人机交互。比如目前比较常见的设备中,将深度相机(比如kinect,astra等)与主机设备(如游戏主机、智能电视等)相连,当人体对象处在深度相机的可测范围内,由深度相机获取含人体的深度图像,将深度图像传输到主机设备中,通过处理器对深度图像进行人体姿势或动作(如手势等)识别后,将识别到的手势与预设的主机指令对应后触发该指令以实现体感交互。
当用户在进行体感交互时,理想的状况是在有足够大的交互空间,该空间需要尽可能的覆盖深度相机的测量区域,比如对于测量范围在1~4m、横向fov为60°的深度相机而言,交互空间要尽可能地覆盖该扇形测量区域。然而实际情形中交互空间常常受限,比如用户客厅范围有限、交互空间中有其他物体阻碍等等,在此情形下,用户的体感难以覆盖整个深度相机测量区域以至于降低用户的体感交互体验。
已有的解决方案中,往往需要用户在进行体感交互前对当前的交互区域进行把握,然后对深度相机进行相应的调整;另外在进行具体的体感应用时,需要一个对用户进行激活的指令,该激活指令要求用户站在深度相机测量区域的中心位置以被更好的识别,通过此类的方法来尽可能提升后续体感交互的用户体验。然而这些方法均不够智能,用户体验较差。
技术实现要素:
本发明的目的是为了解决现有技术中人机交互方案在交互空间受限时,用户的体感难以覆盖整个深度相机测量区域,以至于用户的体感交互体验较差的问题,提出一种人机交互自适应调整方法及系统。
本发明的人机交互自适应调整方法,包括以下步骤:
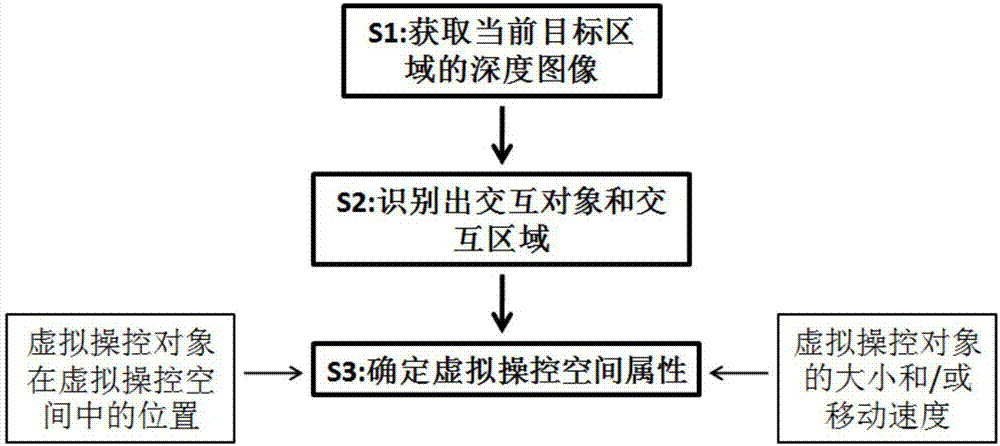
s1:获取当前目标区域的深度图像;
s2:根据所述深度图像识别出交互对象以及交互区域;
s3:根据所述交互对象以及所述交互区域来确定虚拟操控空间属性。
优选地,所述交互区域小于所述目标区域。
优选地,所述步骤s2还包括以下步骤:
s21:利用所述深度图像识别出交互对象;
s22:对所述深度图像进行平面检测;
s23:识别出含有交互对象的平面区域,将该区域作为交互区域。
优选地,所述步骤s3中确定虚拟操控空间属性包括:根据所述交互对象在所述交互区域中的相对位置,确定所述虚拟操控空间中虚拟操控对象的位置。
优选地,所述步骤s3中确定虚拟操控空间属性包括:根据所述交互区域对于所述虚拟操控空间的相对位置及相对大小,确定所述虚拟操控空间中所述虚拟操控对象与所述交互对象的映射关系。
优选地,所述映射关系包括所述虚拟操控对象与所述交互对象的移动速度之间的映射关系;
优选地,所述映射关系包括所述虚拟操控对象与所述交互对象的大小之间的映射关系。
本发明还提出一种人机交互自适应调整系统,包括存储器,用于存放程序;处理器,运行所述程序,以用于控制所述人机交互自适应调整系统执行上述的人机交互自适应调整方法。
优选地,所述系统还包括深度相机和计算设备,所述深度相机用于获取当前目标区域的深度图像;所述计算设备与所述深度相机相连,计算设备中包含所述处理器。
本发明还提出一种包含计算机程序的计算机可读存储介质,所述计算机程序可操作来使计算机执行上述的人机交互自适应调整方法。
与现有技术相比,本发明的有益效果有:
本发明提供了一种人机交互自适应调整方法及系统,利用对深度相机获取的深度图像进一步处理后,识别出交互对象以及与深度相机测量区域不同的交互区域,进一步根据交互对象和交互区域来确定虚拟操控空间属性,对虚拟操控对象在虚拟操控空间中的位置,以及虚拟操控对象的大小和/或移动速度进行适当的调整,以满足用户在交互空间受限的情形下依然可以拥有较好的交互体验。
附图说明
图1是本发明实施例1中人机交互的场景示意图。
图2是本发明实施例1中人机交互自适应调整方法的总流程图。
图3是本发明实施例1中人机交互自适应调整系统的结构示意图。
图4是本发明实施例1中人机交互自适应调整方法的步骤s2的子流程图。
具体实施方式
下面结合具体实施例并对照附图对本发明做进一步详细说明。需要说明的是,以下的实施例并非是对本发明的限制。
实施例1
图1是根据本发明实施例的用于人机交互的场景示意图。用户17处在含有一些家具如座椅16和沙发18的环境中,面对配备有深度相机12的电视11进行交互,这种人机交互方式也被称为体感交互,即利用人体的姿势或动作,比如利用手势或手部动作来控制电视,或者利用手势来与电视11中的应用进行交互。深度相机12的视场为扇形,凡是在扇形区域中的物体均能被深度相机采集到,在本实施例中将该区域称为目标区域。图1中深度相机12与电视11相连,深度相机12被用来获取目标区域的深度图像。
目前深度相机主要有三种形式:基于双目视觉的深度相机、基于结构光的深度相机以及基于tof(时间飞行法)的深度相机。以下进行简要说明,无论哪种形式都可以被用在实施例中。
基于双目视觉的深度相机是利用双目视觉技术,利用处在不同视角的两个相机对同一空间进行拍照,两个相机拍摄出的图像中相同物体所在像素的差异与该物体所在的深度直接相关,因而通过图像处理技术通过计算像素偏差来获取深度信息。
基于结构光的深度相机通过向目标空间投射编码结构光图案,再通过相机采集目标空间含有结构光图案的图像,然后将该图像进行处理比如与参考结构光图像进行匹配计算等可以直接得到深度信息。
基于tof的深度相机通过向目标空间发射激光脉冲,激光脉冲经目标反射后被接收单元接收后并记录下激光脉冲的来回时间,通过该时间计算出目标的深度信息。
这三种方法中第一种一般采集彩色相机,因而受光照影响大,同时获取深度信息的计算量较大。后两种一般利用红外光,不受光照影响,同时计算量相对较小。在室内环境中,使用结构光或tof深度相机是更佳的选择。
图1中的电视11一般意义上为智能电视或数字电视,也可以是含有显示器、处理器以及诸多接口的计算设备,目前大多数的智能电视运行android操作系统,也可以是windows、linux等操作系统。深度相机拥有usb等接口,用于与计算设备相连,还可以进行供电。图1中深度相机12与电视11连接,将获取到的深度图像传输到电视中,通过存储在电视中的软件对深度图像进行处理,比如图像去噪预处理、骨架提取等,进一步地将处理的结果变成相应的指令来控制电视中的应用程序,比如选中、翻页等。
另外,在本实施例中,计算设备为电视机,在其他实施例中,计算设备也可以为含有显示器、处理器以及诸多接口的电脑、平板、手机、游戏设备等,均属于对本案的简单变形或变换,落入本案的保护范围。
深度相机12的视场在三维空间中可以近似看成是一个锥形(视锥体),为了便于分析,仅分析二维平面的情形。在二维平面上(以水平平面为例),深度相机12的视场为扇形,凡是在扇形区域中的物体均能被深度相机采集到,在本实施例中将该区域称为目标区域20,如图1所示。图1中用户17(交互对象)处在目标区域20中,此外,还有一些其他物体也会出现在目标区域中,比如沙发18、坐椅16等。实际上用户17在交互过程中会受到其他物体的阻碍,如图1中所示,用户的活动区域仅局限在左下角的一小部分,在这里将该部分的区域称为交互区域19,交互区域19明显要小于目标区域20。
若当前电视中运行了一个体感应用程序(比如网球、乒乓球等),用户用身体来控制应用程序中虚拟操控对象13或15的运动。在应用程序,虚拟操控对象13或15也拥有其虚拟操控空间14(图中阴影表示的网球场半场区域),目前通用的做法有两种:
一种方法是:虚拟操控空间14与深度相机的目标区域20是对应关系,即将目标区域20的四个顶点分别与虚拟操控空间14的四个顶点相对应,这种情形下当前用户17处在目标区域20的中间位置,相应的虚拟对象应处在虚拟操控空间的中间位置,如图中虚拟操控对象15所示的位置。然而,在这种设置下,由于图1中的用户17处在交互区域19的右侧,并且用户的活动区域仅局限于该交互区域中,因此,图1中的用户17将仅能实现将虚拟操控对象移动到左侧,无法将其移动到右侧。解决此类问题的方案在背景技术中有描述,即需要用户自己把控来对深度相机进行调整,使得当前用户处在深度相机目标区域的中心,这种解决方案并不智能,用户体验较差。
另一种方法是:无论用户17处在目标区域的何处位置,将虚拟操控对象13或15在虚拟操控空间14中选取一个默认的位置,比如球场边缘的中间位置,即虚拟操控对象15所在的位置。在获取包含用户17的深度图像中,通过识别用户的左右前后移动来控制虚拟控制对象13或15的左右前后移动。同样地,这种方法也会出现如前一种方法类似的问题。
以下将结合本系统的组成说明本发明的人机交互自适应调整方法。
本发明的人机交互自适应调整方法,如图2所示,包括以下步骤:s1:获取当前目标区域的深度图像;s2:识别出交互对象以及交互区域;s3:确定虚拟操控空间属性,其中,步骤s3中的虚拟操控空间属性包括虚拟操控对象在虚拟操控空间中的位置,以及虚拟操控对象的大小和/或移动速度。
本实施例将结合人机交互自适应调整系统的结构组成,来说明本发明的人机交互自适应调整方法。图3所示的是本发明实施例中人机交互自适应调整系统的结构示意图。系统由计算设备以及深度相机组成,其中计算设备包含处理器、存储器2、接口单元2以及显示器,显示器也可以是独立的设备通过接口与计算设备相连。深度相机中包含深度计算单元、存储器1以及接口单元1,深度相机中还包含有图像采集单元,对于结构光深度相机以及tof深度相机,图像采集单元包括光学投影仪以及图像传感器;而对于双目深度相机,图像采集单元包括两个图像传感器。计算设备与深度相机之间通过接口单元连接,该接口单元可以为usb等有线连接,也可以为wifi等无线连接。
深度相机采集到目标区域的图像后,由深度计算单元计算出目标区域的深度图像,根据不同原理的深度相机,其计算方式也有区别,以结构光深度相机为例。
结构光深度相机中结构光投影仪向空间中投影结构光图像,该图像由图像传感器采集后传给深度计算单元,由结构光图像计算深度图像是基于结构光三角法来实现的。以结构光图像为散斑图像为例,预先需要对采集一幅已知深度平面上的结构光图像为参考图像,然后深度计算单元利用当前获取的结构光图像与参考图像,通过图像匹配算法计算各个像素的偏离值δ(变形),最后利用三角法原理可以计算出深度,计算公式如下:
其中,zd指三维空间点距离采集模组的深度值,即待求的深度数据,b是采集相机与结构光投影仪之间的距离,z0为参考图像离采集模组的深度值,f为采集相机中透镜的焦距。其中参考图像、b及f等参数预先要存储在存储器中。这里的存储器一般为flash闪存等非易失性存储器。可以理解的是,若深度相机被集成到计算设备中,该存储器与计算设备中的存储器可以指合二为一。
深度计算单元计算出目标区域的深度图像后,深度图像经由接口单元1传输到计算设备中,深度图像可以被保存在存储器2中,也可以直接经由处理器进行实时的处理,处理的程序(如深度图像预处理、人体识别、骨架提取等)被预先保存在存储器中。处理器将调用这些程序对深度图像进行处理,该处理包括深度图像预处理、人体识别、骨架提取,人体姿势、手势或动作识别等步骤,然后将识别到的姿势、手势或动作与预设的主机指令对应后,最终可以输出控制其他应用程序的指令。
在本实施例中,处理器对深度图像的处理除了可以对深度图像进行人体识别或交互对象识别外,还需要识别出交互区域。这里的交互区域指的是用户可以自由行走且没有阻碍的区域,比如图1中所示的方形,也可以为圆形或者其他形状,形状与具体的应用相关。可以理解的是,这里仅以二维区域进行说明,该发明的方法可以向三维空间区域进行延伸。本发明的人机交互自适应调整方法,步骤s2中根据深度图像识别出交互对象和交互区域,如图4所示,具体还包括以下子步骤:s21:利用深度图像识别出交互对象;s22:对深度图像进行平面检测;s23:识别出含有交互对象的平面区域为交互区域。其中,步骤s22中,对深度图像进行平面检测,具体操作为:首先获得一个能反应空白地面的曲面图,然后在该曲面图中以交互对象所在的地面交点为原点,进行方形扩充直到与曲面图中的边缘重叠为至。
具体地,在本实施例中,以方形交互区域为例,如图1所示,在获取的深度图像中首先识别出地面以及用户、除用户之外的障碍物,通过对障碍物与地面坐标的识别可以得到一个能反应空白地面的曲面图,最后在该曲面图中以用户所在的地面交点为原点,进行方形扩充直到与曲面图中的边缘重叠为至,该方法又称为平面检测,就可以得到含有用户的最大方形交互区域。从曲面图中提取交互区域的方法,除了平面检测的方法外,也可以为其他方法,在此不做限定。
在提取到交互对象以及交互区域之后,就可以得到交互对象相对于交互区域的相对位置。若当前人机交互的应用程序为网球,程序中虚拟操控对象的虚拟操控空间应与该交互区域对应,换句话说,即根据得到的交互对象相对于交互区域的相对位置,来确定虚拟操控对象相对于虚拟操控空间的位置。为了满足这一要求,在程序启动时,虚拟操控对象在虚拟操控空间中的初始位置应与交互对象相对于交互区域的初始相对位置一致,比如图1中,用户17相对于交互区域19的位置在右上角,网球应用中虚拟操控对象的初始位置也应处在虚拟操控空间14的右上角位置,如图1中虚拟操控对象13的位置。此外,虚拟操控对象的移动速度与人体的真实移动速度之间的比例映射关系也需要与虚拟操控空间与交互区域的尺寸之间的比例映射关系相一致。
虚拟操控对象的大小也可以根据交互对象相对于交互区域的大小进行调整。在一种实施例中,若交互区域相对较小,交互对象活动区域有限的情形下,交互对象相对于交互区域较大,则虚拟操控对象可以调整到较大,以便于更好的识别出虚拟操控对象的运动。
计算设备中的存储器2用于存储操作系统以及深度图像处理程序和应用程序;处理器通过对深度图像的处理后发出相应的指令,通过该指令进一步控制应用程序。显示器用于应用程序的显示。深度图像处理程序包括深度图像预处理、人体识别、骨架提取,人体姿势、手势或动作识别等,处理器通过对深度图像的处理后,将识别到的姿势、手势或动作与预设的主机指令对应后,最终可以输出控制其他应用程序的指令。
在本实施例中,应用程序为体感应用程序,比如网球、乒乓球等,计算设备中的处理器通过对深度图像的处理后,将识别到交互对象的姿势、手势或动作与预设的主机指令对应后,最终可以输出控制虚拟操控对象的指令,如左右移动、奔跑、挥手等。在其他实施例中,应用程序可以为其他体感应用程序,虚拟操控对象可能仅有部分被呈现在虚拟操控空间中,例如,握有方向盘的伸出的手、握有步枪的伸出的手臂等。在另外一些实施例中,虚拟操控对象可以不是人体模型,而是可显示光标,计算设备中的处理器通过对深度图像的处理后,将识别到交互对象的姿势、手势或动作与预设的主机指令对应后,最终可以输出控制可显示光标的指令,如左右移动、选中、翻页等。
实施例2
在本实施例中,人机交互自适应调整系统的结构组成与实施例1相同,不同的是,本实施例的交互对象为手部,交互区域为以肩部为中心且在人体尽可能静止的情况下手部可以到达的空间三维区域。这种情形下,交互区域的识别相对于平面检测要简单,只需要在空间中设定到一个虚拟的交互区域即可。处理器根据手部在交互区域中的相对位置来确定虚拟操控对象在虚拟操控空间中的位置。
实施例3
本发明的人机交互自适应调整系统,其深度图像的处理也可以由深度相机独立来完成,即计算设备的处理器也可以设置在深度相机中;另外,深度相机也可以被集成到计算设备如电视中,因此,上述实施例1和实施例2为较佳的实施例,并非对深度相机以及计算设备的功能进行限定。
在本实施例中,人机交互自适应调整系统,可以不包含具体的深度相机和计算设备,只包含存储器,用于存放程序;处理器,运行所述程序,以用于控制所述人机交互自适应调整系统执行上述的人机交互自适应调整方法。
实施例4
在本实施例中,人机交互自适应调整系统,也可以不包含具体的深度相机、计算设备、存储器和/或处理器,直接为一种包含计算机程序的计算机可读存储介质,所述计算机程序可操作来使计算机执行上述的人机交互自适应调整方法。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!