一种基于游客移动信令数据的景区实时动态客流量统计方法与流程
本发明属于通信技术领域,特别是移动互联网及计算机通信领域,涉及一种基于游客移动信令数据的景区实时动态客流量统计方法。
背景技术:
近年来,以云计算、物联网、移动通信等为代表的新一代信息技术取得了重大突破,开始广泛应用于各行各业。物联网技术突破了互联网的“线上”局限,把虚拟世界与现实世界联成一体;移动通信技术实现了实时数据在系统之间、远程设备之间的无线连接,为无处不在的全程服务提供了条件;云计算解决了互联网发展所带来的巨量数据存储与处理问题。这些技术的普及和应用,为旅游信息化的发展提供了有力支撑,将人类社会带入了一个以“pb”(1024tb)为单位的新阶段,大数据时代应运而生。大数据不仅更新了旅游信息化所需的技术,更从观念和思维上革新了人类的认识,实现思维、商业、管理上的变革。
随着中国经济的发展,人们收入的增长以及对生活品质的追求,旅游业在国内发展得很快,得到了国家的大力支持,旅游业进入爆发性的增长阶段,成为新的支柱产业。旅游已经成为人们生活方式的重要组成部分,但与此同时引发了一些景区管理的安全隐患,景区超流量接待游客已不是罕见现象。2015年跨年夜上海发生的踩踏事件,暴露出了我国在大量游客管理方面能力的匮乏。事后国家旅游局对景区安全管理更加严格,尤其是在景区客流量控制上。因此,无论是从国家还是旅游局层面来讲,景区需要一套针对景区游客的安全监控方案。
传统的景区动态客流量统计方法在实时性方面体现的比较差,统计景区客流量是通过从传统的数据库中分析提取。而传统数据库具有效率不够高、可读性不高、数据时间性不足等缺点,导致分析传统数据库中的海量游客信令数据会造成查询速度特别慢、统计速度特别慢等缺点。所以传统数据库不适合用于存储分析海量数据,不利于应对短时间内因游客剧增导致拥堵、踩踏等引发的安全事故。
flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。kafka可实时记录从数据采集工具flume中收集的数据,并作为消息缓冲组件为上游实时计算框架提供可靠数据支撑。
spark是一个分布式的内存计算框架,其特点是能处理大规模数据,计算速度快。spark需要集成hadoop的分布式文件系统才能运作,它延续了hadoop的mapreduce计算模型,相比之下spark的计算过程保持在内存中,减少了硬盘读写,能够将多个操作进行合并后计算,因此提升了计算速度。spark必须搭在hadoop集群上,它的数据来源是hdfs,本质上是yarn上的一个计算框架,像mapreduce一样。spark核心部分分为rdd。sparksql、sparkstreaming、mllib、graphx、sparkr等核心组件解决了很多的大数据问题,其完美的框架日受欢迎。其相应的生态环境包括zepplin等可视化方面,正日益壮大。spark读写过程不像hadoop溢出写入磁盘,都是基于内存,因此速度很快。另外dag作业调度系统的宽窄依赖让spark速度提高。
本方法采用快速的海量数据处理框架和相应的分析算法实时监控景区内的客流情况,以便景区和当地人民政府能及时采取疏导、分流等措施,从而达到景区安全管理的目的。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于游客移动信令数据的景区实时动态客流量统计方法,该方法针对传统的景区动态客流量统计方法在实时性方面体现的比较差、海量数据不适合存储在传统数据库中进行分析等问题,通过实时监控景区内的客流量,有助于应对短时间内景区游客剧增情况,便于景区和当地政府及时采取疏导、分流等措施,从而达到景区安全管理的目的,同时更大程度地提升游客对景区的体验度。
为达到上述目的,本发明提供如下技术方案:
一种基于游客移动信令数据的景区实时动态客流量统计方法,该方法包括以下步骤:
s1:lte-a空口监测仪实时采集景区内游客的信令数据,并将数据保存至远程文件中,以一分钟的时间粒度保存一个信令数据文件;
s2:通过flume组件监测远程文件是否有文件更新,若有更新,将文件逐条记录收集;
s3:flume组件将更新的最新文件中的数据逐条发送至kafka数据缓冲组件中进行数据缓冲,直至更新后的最新文件中的数据全部发送完毕,将该数据流打包成批数据作为spark的数据输入流;
s4:在spark分布式的内存计算框架中,通过比较前一分钟和后一分钟游客所在基站的位置来实时统计景区内游客总量;
s5:将每分钟实时统计的客流量结果进行输出并存储,如存储到mysql/oracle数据库中。
进一步,在步骤s1中,所述lte-a空口监测仪采集景区内游客的移动信令数据,包括imsi库、信令发生的时间、所在的基站位置信息,并将移动信令数据以一分钟的时间粒度保存一个信令数据文件。
进一步,该方法还包括以下步骤:s6:将存入到数据库的实时结果输出至应用展示层中,以可视化界面的形式方便用户查看。
本发明的有益效果在于:
1)本发明将景区内游客的海量实时移动信令数据存储在远程文件系统中,为数据预处理和数据分析处理模块提供数据准备,把数据分析后的结果存储到传统的数据库中,从而大大减轻了传统数据库直接存储海量实时数据的压力。
2)本发明基于hadoop平台,在spark分布式内存计算框架中进行海量的数据运算分析,把在传统数据库中进行数据运算的压力转移到高效快速的spark分布式内存计算框架中,从而保证了景区内对游客的实时监控。
3)本发明可用于分析景区内精细化的客流特征,通过重复利用kafka缓冲的批数据处理流,在spark中生成多个rdd变换,每个rdd变换用于一种客流特征的分析,形成各自的业务逻辑。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明中的数据预处理流程图;
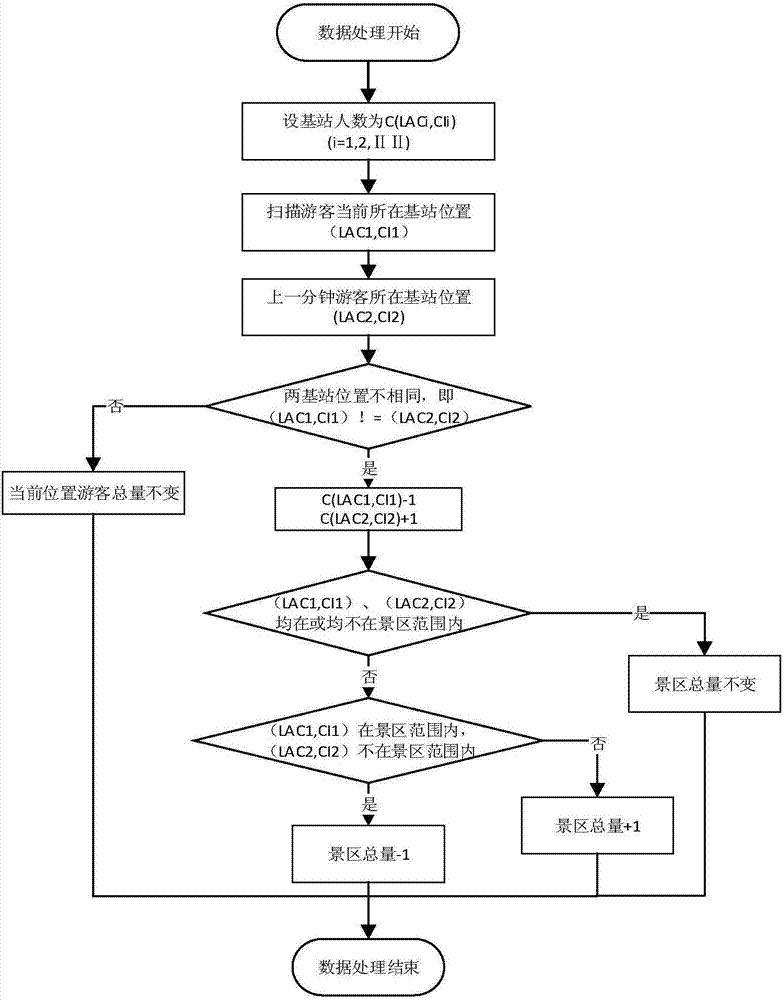
图2为本发明中数据实时计算处理流程图;
图3为本发明中精细化的客流特征分析流程框图;
图4为本发明中数据实时计算处理后数据表的设计。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图1为本发明中的数据预处理流程图,图2为本发明中数据实时计算处理流程图,如图所示,本发明提供了一种基于游客移动信令数据的景区实时动态客流量统计方法,该方法包括如下步骤:
步骤1:lte-a空口监测仪实时采集景区内游客的信令数据imsi号和(lac,ci)(移动终端imsi表示游客在景区的唯一标识,移动终端所在的基站位置(lac,ci)表示游客所在的位置),并将数据保存至远程的文件中,以一分钟的时间粒度保存一个信令数据文件。
步骤2:通过flume组件监测远程文件是否有文件更新,若有更新,将文件逐条记录收集。
步骤3:flume组件将更新的最新文件中的数据逐条发送至kafka数据缓冲组件中进行数据缓冲,直至更新后的最新文件中的数据全部发送完毕,将该数据流打包成批数据作为spark的数据输入流。
步骤4:在spark分布式的内存计算框架中,通过比较前一分钟和后一分钟游客所在基站的位置来实时统计景区内游客总量。当前景区游客总量为各个基站下游客总量之和。当游客从景区内一个基站到另一个基站,景区总量不变;当游客前后一分钟都在该景区内的同一个基站范围内,景区总量不变;当游客从景区外的一个基站到景区内的一个基站,景区总量+1;当游客从景区内的一个基站到景区外的一个基站,景区总量-1。
步骤5:将每分钟实时统计的客流量结果进行输出并存储,如存储到mysql/oracle数据库中。数据库中表的设计结构如图4所示。
步骤6:将存入到数据库的实时结果输出至应用展示层中。
本发明可用于分析景区内精细化的客流特征,通过重复利用kafka缓冲的批数据处理流,在spark中生成多个rdd变换,每个rdd变换用于一种客流特征的分析,形成各自的业务逻辑。如图3所示。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!