基于深度学习的博客文本摘要生成方法与流程
本发明涉及一种文本摘要生成方法,具体地涉及一种基于深度学习的博客文本摘要生成方法。
背景技术:
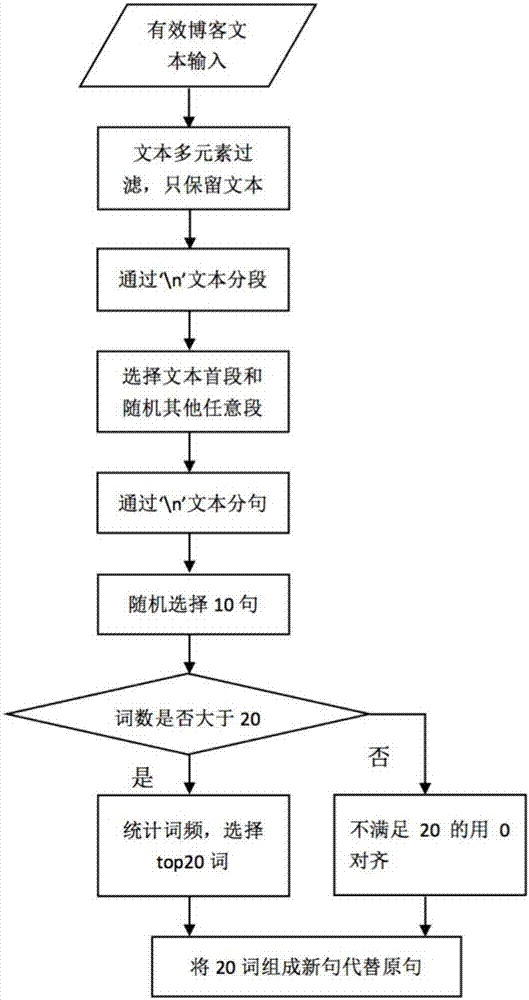
:自然语言处理(naturallanguageprocessing)是当前人工智能特别重要的一部分,它包括文本分类、情感分析、机器翻译、阅读理解等多个子任务,几乎一个子任务就是一个相当重要的专业研究领域,它们之间相互独立又相互联系。深度学习是在近年来提出的一种新型的端到端的学习方式,在普通的处理任务中比如分类也许与普通神经网络的效果相差无几,但是在高维数据的计算以及特征提取的过程中深度学习使用深度网络来拟合,显示了其强大的计算能力。目前深度学习已经运用到了多个领域--图像处理、音频处理、视频处理、自然语言处理,自从2006年由hinton提出以来,它使得众多智能摆脱了繁琐复杂的特征工程过程,比如数据预处理标注等,通过选择不同的模型组合直接由输入数据经过训练便可得到想要的输出形式。将深度学习运用到自然语言处理上的想法由来已久,但是从英文和中文的语言差别性我们可以看到目前深度学习在中文语言上的处理还不尽如意。2014年,”encoder-decoder”深度学习的机器翻译框架被提出,使得深度学习在机器翻译、摘要生成、阅读理解方面有了很大的突破,获得更深层次的文本语义联系。自然语言中文本摘要生成方式主要分成两个方式:第一抽取型,基于规则和统计的文摘要生成,目前已有大量的运用实践证明;第二是抽象型,基于深度学习模型的摘要生成,2014年得到巨大改进,从机械型文本摘要生成跨向理解型文本摘要生成,当前使用encoder-decoder框架,嵌入递归神经网络来实现,在中文方面运用还不明显。随着互联网影响力的扩大,人们使用互联网来相互交流学习愈加频繁,从海量的互联网数据中迅速获取我们所需要的信息,解决信息过载是当前重要的自然语言任务之一,特别是针对于博客一类的数据更是重要,博客往往属于中长型的文本,所表达的信息包含了专业、娱乐、生活等方面,在专业方面的博客往往被大量浏览学习收藏。在信息快速更替的时代,为了方便用户有效率地浏览相应博客,可以快速地获取博客摘要主要内容是必须的。技术实现要素:针对上述存在的技术问题,本发明目的是:提供了一种基于深度学习的博客文本摘要生成方法,基于深度学习框架encoder-decoder(编码器-解码器)自动生成博客的文本摘要,同时可以获取博客更深层次的语义联系。生成的文本摘要可以直观的显示当前博客的主要内容,具有广泛的应用前景。本发明的技术方案是:一种基于深度学习的博客文本摘要生成方法,包括以下步骤:s01:爬取博客数据;s02:对爬取的博客数据进行预处理,选取博客文本数据;s03:将选取的博客文本数据根据中文词向量词典转换成向量矩阵数据;s04:构建深度学习encoder-decoder(编码器-解码器)模型,并对该模型的encoder编码器和decoder解码器分开训练,训练完成后连接使用;s05:重复步骤s01-s03得到生成数据,将生成数据通过训练完成的模型生成预测摘要。优选的,所述步骤s01包括:s11:爬取csdn的多个专家博客,多个主题;s12:选取专家博客网页标签中的摘要部分作为实际摘要,如果该博客没有摘要,则将专家博客的标题以及通过传统文本摘要生成算法选取的权值最大语句联合作为该博客实际摘要,用于在训练时使用。优选的,所述步骤s02具体包括以下步骤:s21:滤除博客数据中的视频元素、图片元素、数学计算公式元素,只保留博客数据的文本部分;s22:将博客文本数据分段,提取分段文本数据的第一段,随机选择其余文本数据的任意一段,组成初始文本数据;s23:对初始文本数据进行分句,设定每一分句的词数a;s24:如果每一分句的词数超过a,根据词频大小选择词频最高的a个词,按照原先的顺序连接起来;如果词数少于a,使用0向量填充,对初始文本数据句对齐。优选的,所述步骤s03中,在中文词向量词典中没有查询到的词使用近似词替换。优选的,所述步骤s04具体包括:s41:训练模型encoder编码器中的卷积神经网络,将向量矩阵数据转换成句向量,将训练数据与卷积神经网络中的卷积核相互运算,运算公式如下:其中,fij表示第i个神经网络的第j个元素,k表示该卷积神经网络的卷积核,wj:j+c-1表示网络输入选取第j到j+c-1行,b表示偏置量;从当前每个神经网络中选取最大值将所有的最大值连接组成句向量,sik表示第i个神经网络在k这个卷积核的作用经过最大池化最终的值;s42:训练模型encoder编码器中的递归神经网络,将生成的句向量转换成文本向量,计算公式如下:其中,表示t时刻递归神经网络的输入,表示t时刻递归神经网络的隐藏层的输出状态,wih表示输入层和隐藏层的权值矩阵i*h,wh′h表示上一时刻隐藏层与当前时刻隐藏层的权值矩阵h‘*h,表示递归神经网络中t时刻隐藏层第h个神经元的中间值,tanh表示隐藏层激活函数是双曲正切函数,whk表示递归神经网络中隐藏层和输出层的权值矩阵,表示递归神经网络中t时刻输出层第k个神经元的中间值,ex表示输出层激活函数是softmax的指数函数形式,表示最终输出层的输出;将最后序列生成的传递给解码器;s43:训练模型decoder解码器中的长短期记忆网络lstm,将编码器中递归神经网络生成的隐藏状态作为输入,在lstm中结合上一时刻隐藏层的状态和当前时刻的输入决定当前时刻隐藏层的状态ht,通过输出层得到预测摘要,计算公式如下:ft=σ(wf·[ht-1,xt]+bf)it=σ(wi·[ht-1,xt]+bi)c′t=tanh(wc·[ht-1,xt]+bc)ct=ft*ct-1+it*c′tot=σ(wo·[ht-1,xt]+bo)ht=ot*tanh(ct)其中,ct表示t时刻当前lstm中的状态,c′t表示t时刻lstm中神经元新的状态候选值,ft表示t时刻lstm中忘记门层的输出,it表示t时刻lstm中输入门层的输出,ot表示t时刻输出层的输出,ht表示t时刻当前网络隐藏层状态,xt表示t时刻网络的输入,即摘要训练数据的向量,bf表示忘记门层的偏置值,bi表示输入门层的偏置值,bc表示神经元新旧状态之间的偏置值,bo表示输出层的偏置值,σ表示激活函数sigmoid,wf表示忘记门层与输入层的权值矩阵,wi表示输入门层与输入层的权值矩阵,wc表示神经元新旧状态的权值矩阵,wo表示输出层的权值矩阵,tanh表示激活函数双曲正切函数;公式3-1到公式3-6表示在lstm中结合上一时刻隐藏层的状态和当前时刻的输入决定当前时刻隐藏层的状态,得到ht之后,会通过同递归神经网络相似的输出层softmax得到预测摘要,softmax的输出层是300维大小同词向量。优选的,对训练完成的模型进行评估,具体包括:步骤一、采用rouge指标,通过比较预测摘要和实际摘要的重合程度进行评估;步骤二、使用博客数据进行训练,使用duc-200数据集用于模型测评;步骤三、将该模型与当前已存在的其他摘要生成模型对比。与现有技术相比,本发明的优点是:(1)利用深度学习技术生成文本摘要,可以直观有效的了解博客文本的主要内容,同时此技术可以扩展向其他类型文本的摘要生成或者文本总结领域,在中英文语料均可,具有广泛的应用前景。(2)通过深度学习模型自动生成摘要,研究了语义更深层的联系,建立了完善的语言模型,生成的多种语言副产品包括句向量、文本向量,可以用于语言情感分析以及文本分类等语言任务中。(3)与基于统计与规则的摘要生成方式相比,更佳端到端,省略了以往自然语言处理中繁琐的流程,比如分词、标注等。(4)使用深度学习机器翻译框架,可使得运用领域扩展至其他,比如阅读理解、故事生成等。附图说明下面结合附图及实施例对本发明作进一步描述:图1为本发明用户使用的整体流程图;图2为本发明文本预选择方法的流程图;图3为本发明博客数据生成词典的流程图;图4为本发明文本到向量转换的流程图;图5为本发明基于深度学习的摘要生成模型训练的流程图。具体实施方式以下结合具体实施例对上述方案做进一步说明。应理解,这些实施例是用于说明本发明而不限于限制本发明的范围。实施例中采用的实施条件可以根据具体厂家的条件做进一步调整,未注明的实施条件通常为常规实验中的条件。实施例:一种基于深度学习的中文博客摘要生成方法,具体步骤包含:步骤一、博客训练数据爬取和整理博客训练数据爬取自csdn网站的人气博客,得到的博客内容多样,但都是专业性较强的文本,同时博客训练数据中也有些数据存在缺陷,比如博客过于短小,博客中没有文本,只包含了视频和图片,对于这种文本我们会丢弃。使用beautifulsoup中的find和get_text得到最终的博客文本并且选取网页标签类别为article_description的文本内容作为博客实际摘要。如果该博客没有摘要,则将专家博客的标题以及通过textrank选取的权值最大语句联合作为该博客实际摘要,在训练时使用。textrank方法是一种基于统计和规则的文本摘要生成算法,用于通过权值大小提取关键字和关键句,目前被封装在多种语言平台包括java、python、c++的类库中,可以直接调用。步骤二、文本预选择及文本到向量转换1)将博客文本训练数据,通过‘\n’标识分段;2)选取博客数据的首段,通过多篇论文得出的结论即一篇文章大多时候会在开头和结尾体现出要表达的主要思想,此外再结合通过random函数随机选取的其他任意一段,作为最终训练的博客文本数据,其中这里处理的是训练数据中博客文本部分,训练数据中的博客摘要部分不需要选择;3)将初步选择的博客文本摘要数据,以‘,’和‘。’为标识分句,使用nltk工具进行分词,并且统计各词词频,词频的统计是在全文中进行的;将每一句的词量控制在20词(词数还可以为其他值)以内,如果超过20词即通过词频大小选择出该剧中词频最高的20个词,按照顺序连接起来,组成句子代替原来的句子;如果该句包含词语少于20,即使用0来代替padding来完成对初步选择的博客文本数据的句对齐;4)从已经完成句对齐的文本当中,随机选择10个句子,来表示成我们最终将放入学习模型的训练数据;5)使用word2vec对收集的博客训练数据生成词向量词典,生成的词向量为300维,训练参数设置如表1;cbowsizewindownegativebinaryiter0300501156)对已经整理好的文均200词的博客摘要数据进行文本到向量的转换,遍历文中各词在生成的词典中进行查找,将查找到的词向量按照原来文本的顺序连接起来,即每篇博客数据的句子用20*300的矩阵表示,最终会有10个这样的矩阵。步骤三、基于深度学习的摘要生成模型训练该步骤关键在于模型的构建以及训练,深度学习模型有多层网络,这里使用encoder-decoder(编码器解码器)框架,在编码器中嵌入卷积神经网络cnn和递归神经网络rnn对初始文本进行编码,在解码器中嵌入长短期记忆神经网络lstm对训练数据进行预测。训练模型encoder编码器中的卷积神经网络,将文本选择生成的向量数据转换成句向量,其中的卷积神经网络featuremap大小为300,卷积核为(3,300),池化方式为max-pooling即最大池化方式,相关公式如下:公式1-1表示训练数据与卷积神经网络中的卷积核相互运算,fij表示第i个featuremap的第j个元素,k表示该卷积神经网络的卷积核,这里卷积核的大小是3*300,wj:j+c-1表示网络输入选取第j到j+c-1行,这里的c值为3,b表示偏置量;公式1-2是经过从当前每个featuremap中选取最大值,最终300个最大值连接组成句向量,sik表示第i个featuremap在k这个卷积核的作用经过最大池化最终的值。步骤二、训练模型encoder编码器中的递归神经网络,将生成的300维句向量转换成文本向量,相关公式如下:在上述公式中,表示t时刻递归神经网络的输入,表示t时刻递归神经网络的隐藏层的输出状态,wih表示输入层和隐藏层的权值矩阵i*h,wh′h表示上一时刻隐藏层与当前时刻隐藏层的权值矩阵h‘*h,表示最终输出层的输出,这里是softmax生成的750维向量,最后一个句子输入完成后的表示生成的文本向量共750维;公式2-1表示,输入句向量和上一层隐藏状态在隐藏层中的计算结果;公式2-2表示隐藏层的输出,即隐藏层的状态;公式2-3表示隐藏层到输出层的计算结果;公式2-4表示输出层最终的结果。之后会将最后序列生成的传递给解码器。步骤三、训练模型decoder解码器中的长短期记忆网络lstm,将编码器中递归神经网络生成的隐藏状态作为输入,结合摘要训练数据(在之前转换成向量的形式)放入网络中,生成预测摘要,相关公式如下:ft=σ(wf·[ht-1,xt]+bf)3-1it=σ(wi·[ht-1,xt]+bi)3-2c′t=tanh(wc·[ht-1,xt]+bc)3-3ct=ft*ct-1+it*c′t3-4ot=σ(wo·[ht-1,xt]+bo)3-5ht=ot*tanh(ct)3-6在上述公式中,ct表示当前lstm中的状态,ht表示当前网络隐藏层状态,xt表示网络的输入,即摘要训练数据的向量;公式3-1到公式3-6表示在lstm中结合上一时刻隐藏层的状态和当前时刻的输入决定当前时刻隐藏层的状态,得到ht之后,会通过同递归神经网络相似的输出层softmax得到预测摘要,softmax的输出层是300维大小同词向量。整个网络的训练是分层训练,原始训练数据80%用于训练,20%用于微调。1)进入编码器第一步生成句向量,将传入的文本词向量数据中的每句所有的词向量作为卷积神经网络的输入,经过卷积核(3,300),以及max-pooling的池化方式,最终生成300维的句向量;2)将生成的句向量,一共10句传入递归神经网络中,生成初始参数设置在[-1,1],满足高斯分布,其中递归神经网络第一步的隐藏状态设置为0,最终生成750维的句向量,以及最后一步的隐藏状态;3)将编码器生成的最后一步隐藏状态传入解码器作为长短期记忆神经网络的第一步的隐藏状态输入,第一步输入层的输入数据是文本结束标志<eos>,后面步的输入是训练数据中的摘要数据部分,摘要数据被转换成词向量形式同文本。4)对模型进行评估,这里用到duc-200数据。模型评估指标是rouge,主要是比较实际摘要和预测摘要重合程度,rouge-1表示就单个词的重复程度,rouge-2表示就两个词相连的重复程度。模型的训练使用hinton提出的分层训练方式,梯度参数的调整是反向传播方式,训练数据是收集的博客摘要数据,运用80%的数据进行训练,20%的数据进行测试。整个模型构建训练将在谷歌深度学习平台tensorflow上进行,训练将调用gpu,gpu在处理高维数据计算上效果明显,是调用cpu的5到8倍。步骤四、使用摘要生成模型生成预测摘要1)将要预测的数据进行文本预选择及向量的转换;2)将生成的向量数据放入训练好的深度学习摘要生成模型中,生成预测摘要。下面以具体实施案例对本发明进行进一步的详细说明。1)博客训练数据爬取自csdn网站的人气博客,内容包括移动开发、web前端、架构设计、编程语言、互联网、数据库、系统运维、云计算、研发管理9个专业方向,共21600篇博客,命名格式为姓名_索引号。得到的博客内容包括了多种元素,文本、图片链接、计算公式、代码等,由于图片、计算公式、代码元素在文本摘要生成的过程中并没有帮助,因此过滤掉这些元素,只留下文本;2)对博客数据进行预选择,选择首段加上其他任意一段,可以更加有效地生成摘要;将数据限制在每篇博客20*10的词量,是为了方便在模型中运用,深度学习训练复杂,大量的参数调整会耗费时间,将数据尽可能精简、提取文本特征是必要的,同时这样也对变长文本的问题进行了,将变长文本转换成定长文本,可以拥有更多的训练数据;3)通过word2vec生成的词典将文本训练数据转换成向量;4)构建深度学习摘要生成模型,使用数据进行训练,数据中的80%进行训练,20%进行测试。5)使用duc-200评估模型,评估指标是rouge-1、rouge-2、rouge-l,rouge指标和bleu指标都是用来针对机器翻译等系列自然语言处理任务进行评估的,它们的核心都是分析候选译文和参考译文n元组共同出现的程度,这里的1、2表示1元组、2元组,l表示最长子序列共同出现的程度相关公式如下:6)为比较本发明的技术优势,设置对比试验,对比本发明使用的模型和当前已有摘要生成模型的效果。深度学习模型间摘要生成对比实验结果如表2所示在上表中,crl是本发明使用的深度学习模型,ilp、lead、urank、tgraph是已经存在的另外四种摘要生成模型。表2实验结果比较通过上述分析可见,本发明使用的模型在当前已有模型中的总体效果是最优的,虽然urank、tgraph在rouge-1、rouge-2指标上的表现稍好,但是在rouge-l上基本不能表现出来。因此,本模型适合用来实现摘要生成任务,同时对机器翻译、阅读理解等自然语言处理方面的效果也较理想。由此可见,本发明具有实质性技术特点,其应用前景非常广阔。7)将想要进行摘要预测的博客,如果该博客只有图片、视频之类的,判定博客无效无法生成摘要;传入该深度学习摘要生成系统中,系统对其进行文本预选择和向量转换,传入训练的模型中,最终系统将模型预测的摘要返回给用户,效果如表3所示。注:由于博客过长,因此不全部显示,只展示最终结果,原博链接如下:http://blog.csdn.net/yuanmeng001/article/details/58871130上述实例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人是能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所做的等效变换或修饰,都应涵盖在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1