音乐信息网络中个性化推荐方法与流程
本发明涉及信息检索领域,特别是一种音乐信息网络中个性化推荐方法。
背景技术:
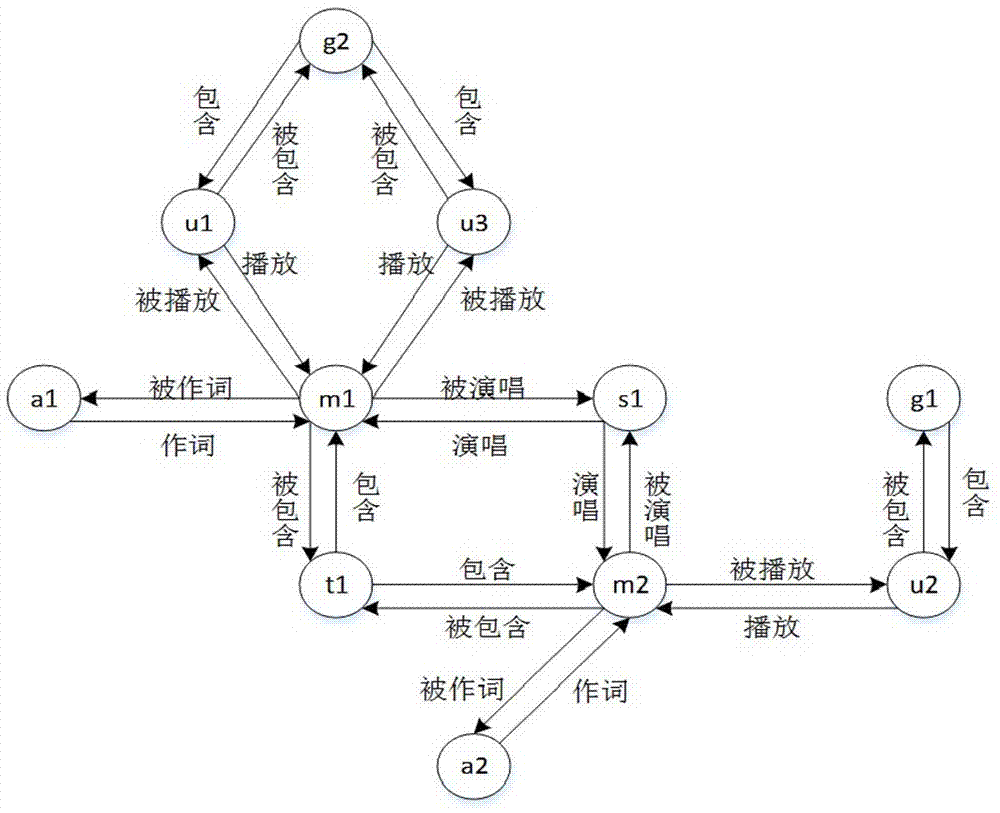
:音乐信息网络实际上是由一个信息子网和社交子网构成,而信息子网通常包含歌曲以及与歌曲相关的类型节点,如歌手、作词者、流派等等,网络中存在的关系有歌曲-歌手之间的被演唱与演唱关系、歌曲-作词者之间的被作词与作词关系、歌曲-流派之间的被包含与包含关系等等,社交子网中包含用户之间的好友关系、歌曲-用户之间的被播放与播放关系、用户-分组之间的被包含与包含关系。目前,音乐信息网络中个性化推荐方法,基本上都是采用基于内容推荐、协同过滤推荐等方法。这些方法只是单纯地利用相似用户喜欢相同歌曲或同一用户喜欢相似歌曲等特性来进行推荐,并没有真正地挖掘用户对歌曲的偏好以及歌曲对用户的影响,不能够很好地体现个性化推荐。技术实现要素:本发明的目的在于提供一种音乐信息网络中个性化推荐方法,以克服现有的音乐信息网络中歌曲个性化推荐方法中存在的问题。为实现上述目的,本发明的技术方案是:一种音乐信息网络中个性化推荐方法,按照如下步骤实现:步骤s1:获取音乐信息网络gm,从所述音乐信息网络gm中提取信息子网g0以及g0的网络模式h0,并根据sg0={(ui,mj)|mj∈g0∧(ui,mj)∈gm}从所述音乐信息网络gm中提取出与所述信息子网g0相关的社交关系sg0,其中,mj为信息子网g0中的歌曲节点,ui为音乐信息网络gm中播放过歌曲mj的用户节点;步骤s2:在所述信息子网g0中计算社交关系影响下的歌曲m、歌手s、作词者a以及流派t的节点群体影响力;步骤s3:在所述音乐信息网络中计算元路径集metapath以及对应的元路径权重wmetapath;步骤s4:指定用户u,在所述音乐信息网络中计算用户u对歌曲的偏好基因;步骤s5:在所述信息子网g0中结合节点群体影响力和用户u对歌曲的偏好基因进行随机游走,得到面向用户u的节点影响力排名,从而得到该用户的歌曲推荐列表。在本发明一实施例中,在所述步骤s4中,用户u对歌曲的偏好基因计算过程如下:根据所述步骤s3得到的元路径权重wmetapath,分别提取出“歌曲-歌手-歌曲”、“歌曲-作词者-歌曲”、“歌曲-流派-歌曲”对应的元路径权重wmetapaths、wmetapatha、wmetapatht;并根据g(s|m)=wmetapaths、g(a|m)=wmetapatha、g(t|m)=wmetapatht和g(s|m)+g(a|m)+g(t|m)=1,计算出用户对歌曲对应的歌手、作词者、流派的偏好基因g(s|m)、g(a|m)、g(t|m)。在本发明一实施例中,在所述步骤s5中,所述用户u的歌曲推荐列表的计算过程如下:步骤s51:根据所述步骤s4得到用户u对歌曲的偏好基因,计算出用户u的信息子网中不同类型关系边的传播因子;步骤s52:根据所述音乐信息网络中用户-用户间边权重以及用户-歌曲间边权重,计算出用户u的信息子网中各种类型边权重;步骤s53:根据步骤s2得到信息子网群体节点影响力、步骤s51得到的传播因子以及步骤s52得到的边权重,在用户u的信息子网中进行随机游走,得到用户u的信息子网节点影响力vec_r;步骤s54:根据所述节点影响力vec_r中抽取出歌曲影响力,并进行影响力排序,得到歌曲的影响力排序vec_m,再从vec_m中选择前k首歌曲作为用户u的歌曲推荐列表vec_mu。在本发明一实施例中,在所述步骤s51中,所述用户u的信息子网中不同型关系边的传播因子计算过程如下:根据所述步骤s4得到用户u对歌曲的偏好基因和所述信息子网的网络模式,将歌曲和歌手关系边的传播因子λms,歌曲和作词者关系边的传播因子λma,歌曲和流派关系边的传播因子λmt分别初始化为用户对歌曲对应的歌手、作词者、流派的偏好基因g(s|m)、g(a|m)、g(t|m),即λms=g(s|m)、λma=g(a|m)、λmt=g(t|m)。在本发明一实施例中,在所述步骤s2中,还包括如下步骤:步骤s22:根据社交关系,计算在社交关系影响下的信息子网中各种类型边权重;步骤s221:歌曲-流派之间的被包含关系边的权重按照如下方式计算:其中,表示歌曲m所属于的流派个数,表示播放歌曲m的用户人数,p(t)表示流派t包含的歌曲列表;步骤s222:流派-歌曲之间的包含关系边的权重按照如下方式计算:其中,表示流派t包含的歌曲数;步骤s223:歌曲-歌手之间的被演唱关系边的权重按照如下方式计算:其中,表示歌曲m的歌手个数,表示播放歌曲m的用户人数,p(s)表示歌手s演唱的歌曲列表;步骤s224:歌手-歌曲之间的演唱关系边的权重按照如下方式计算:其中,表示歌手s演唱的歌曲数;步骤s225:歌曲-作词者之间的被作词关系边的权重按照如下方式计算:其中,表示歌曲m的作词者个数,表示播放歌曲m的用户人数,p(a)表示作词者a作词的歌曲列表;步骤s226:作词者-歌曲之间的作词关系边的权重按照如下方式计算:其中,表示作词者a作词的歌曲数;在步骤s52中,还包括如下步骤:步骤s521:根据所述音乐信息网络中用户之间的好友关系以及用户-歌曲间链接,计算基于用户相似性填充后的所有歌曲评分scoreu;步骤s522:根据所述步骤s521得到基于用户相似性填充后的所有歌曲评分scoreu,将所述步骤s22中初始化为歌曲的评分scoreu,m;步骤s523:重复所述步骤s221至所述步骤s226,得到用户u的信息子网中歌曲-作词者之间边权重wma、作词者-歌曲之间边权重wam、歌曲-歌手之间边权重wms、歌手-歌曲之间边权重wsm、歌曲-流派之间边权重wmt、流派-歌曲之间边权重wtm。在本发明一实施例中,在所述步骤s521中,还包括如下步骤:步骤s5211:根据所述用户-歌曲间边权重umw;若用户u对歌曲m的边权重umwum不为0,则用户u对歌曲m的评分为scoreum=umwum;否则转步骤s5212;步骤s5212:根据所述用户-歌曲间边权重umw,计算出点播过歌曲的用户集mu以及对应的边权重muw;步骤s5213:利用hetesim算法计算出基于元路径“用户-歌曲-歌手-歌曲-用户”、“用户-歌曲-作词者-歌曲-用户”“用户-歌曲-流派-歌曲-用户”下的用户u与每一个用户v∈mu之间的相似性,得到用户相似性行向量usersimu,并对usersimu进行min-max标准化;步骤s5214:若usersimu的最大值大于用户相似性阈值simthre,则根据以下式计算出用户u对歌曲m的评分scoreum:其中,un={r|r∈mu∧usersimur≥simthre},usersimuv为用户u与用户v的相似性,umwvm为用户v对歌曲m的边权重;否则,根据以下式计算出用户u对歌曲m的评分:scoreum=usersimuv*umwvm其中,v={v∈mu∧usersimuv=max(usersimu)},usersimuv为用户u与用户v的相似性,umwvm为用户v对歌曲m的边权重。在本发明一实施例中,在所述步骤s2中,还包括如下步骤:步骤s23:结合所述信息子网中各种类型关系边的传播因子与各种类型边权重在所述信息子网中进行随机游走,计算社交关系影响下的歌曲、歌手、作词者和流派等群体影响力;步骤s231:将所述信息子网中歌曲-歌曲之间边权重wmm、歌手-歌手之间边权重wss、作词者-作词者之间边权重waa、流派-流派之间边权重wtt、歌手-作词者之间边权重wsa、作词者-歌手之间边权重was、歌手-流派之间边权重wst、流派-歌手之间边权重wts、作词者-流派之间边权重wat、流派-作词者之间边权重wta均设置为0,即wmm,wss,waa,wtt,wsa,was,wst,wts,wat,wta都设置为对应大小的零矩阵;将歌曲-歌曲之间传播因子λmm、歌手-歌手之间传播因子λss、作词者-作词者之间传播因子λaa、流派-流派之间传播因子λtt、歌手-作词者之间传播因子λsa、作词者-歌手之间传播因子λas、歌手-流派之间传播因子λst、流派-歌手之间传播因子λts、作词者-流派之间传播因子λat、流派-作词者之间传播因子λta均设置为0,即λmm=λss=λaa=λtt=λsa=λas=λst=λts=λat=λta=0;步骤s232:在所述信息子网中,节点之间进行随机游走的转移概率矩阵tpm按如下方式计算:步骤s233:设定两个长度为n的向量vec_c与vec_r;vec_r中的值为所述信息子网中每个节点的影响力值,vec_c初始为并通过如下方式计算vec_r:其中,ε为全图随机跳转概率,n取值为所述信息子网中节点总个数;步骤s234:通过以下两个公式计算vec_c以及vec_r:vec_c=vec_r,且当||vec_r-vec_c||≥ξ时,则继续以上两个公式的计算,否则得到vec_r,ξ为预设误差阈值;步骤s235:分别对vec_r中类型节点歌曲、歌手、作词者以及流派值进行排序,得到歌曲、歌手、作词者以及流派的群体影响力vec_cg;在所述步骤s53中,将所述步骤s233中节点影响力vec_c初始化为vec_m,将所述步骤s231中传播因子和边权重分别设置为所述步骤s51得到的传播因子和所述步骤s52得到的边权重,并重复所述步骤s231至所述步骤s234,得到信息子网中节点影响力vec_r。相较于现有技术,本发明具有以下有益效果:本发明提出了一种音乐信息网络中个性化推荐方法,该方法不仅有效地利用与歌曲相关的信息子网中不同类型的对象和关系等全面的结构信息和丰富的语义信息,同时考虑到社交群体对信息子网节点影响力的影响,并且能够根据用户对歌曲的偏好基因实现个性化推荐。这种在信息子网中借助社交群体与偏好信息为用户提供个性化推荐的方法更合理。附图说明图1为本发明提出的一种音乐信息网络中的个性化推荐方法。图2为本发明一实施例中音乐信息网络。图3为本发明一实施例中音乐信息网络中的信息子网的网络模式。图4为本发明-实施例中音乐信息网络具体例子。图5为本发明-实施例中社交关系影响下的信息子网例子。图6为本发明-实施例中一个用户的信息子网例子。具体实施方式下面结合附图,对本发明的技术方案进行具体说明。下面通过具体实施例对本发明做进一步的说明,但是需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。如图1所示,为本发明所提出的音乐信息网络中的个性化推荐方法的的流程图,该方法包括如下步骤:步骤s1:获取音乐信息网络,从音乐信息网络中提取信息子网以及信息子网的网络模式,并从音乐信息网络中提取出与所述信息子网相关的用户-歌曲之间的播放关系,即社交关系;进一步的,在本实施例中,在音乐信息网络中,去除用户之间的社交关系以及用户与歌曲之间的播放关系与被播放关系等社交信息后,得到只与歌曲相关的没有社交关系影响下的信息子网g0,在这个信息子网g0的网络模式中,有四种类型节点,分别为歌曲、歌手、流派、作词者,网络中存在的关系有:歌手-歌曲之间的演唱与被演唱关系、作词者-歌曲之间的作词与被作词关系、流派-歌曲之间的包含与被包含关系;再从音乐信息网络中提取与信息子网相关的社交关系sg0,在sg0中,有两种类型节点,分别是歌曲、用户,网络中存在的关系有:用户-歌曲之间的播放与被播放关系。进一步的,在本实施例中,从豆瓣音乐网站中获取音乐网络数据信息,提取网络实体,包括歌曲(m),歌手(s),作词者(a),流派(t),用户(u),分组(g),这些数据中存在关系有:歌曲-歌手之间的被演唱与演唱关系、歌曲-作词者之间的被作词与作词关系、歌曲-流派之间的被包含与包含关系、用户-歌曲之间的播放与被播放关系、分组-用户之间的包含与被包含关系,从而生成音乐信息网络,音乐信息网络例子如图2所示。进一步的,在本实施例中,音乐信息网络中信息子网的网络模式中有节点歌曲(m),歌手(s),作词者(a),流派(t),边代表节点之间的关系,分别为歌曲-歌手之间的被演唱与演唱关系、歌曲-作词者之间的被作词与作词关系、歌曲-流派之间的被包含与包含关系,信息子网的网络模式如图3所示。而与信息子网相关的社交关系sg0是指用户-歌曲之间的播放与被播放关系。进一步的,在本实施例中,音乐信息网络的具体例子如图4所示,社交关系影响下的信息子网例子如图5所示。步骤s2:在信息子网中计算社交关系影响下的歌曲、歌手、作词者和流派等节点群体影响力vec_cg;步骤s21:根据信息子网的网络模式,计算信息子网中不同类型关系边的平均边介数,并根据平均边介数计算随机游走过程中不同类型关系边的传播因子;步骤s211:计算信息子网g0中被演唱关系边、被作词关系以边及被包含关系边的边介数,并计算出这三种类型边的平均边介数的比值ems:ema:emt=9.5332:7.5288:8.7495;步骤s212:根据λms:λma:λmt=ems:ema:emt和λms+λma+λmt=1计算出这三种类型边的传播因子λms=0.3693,λma=0.2917,λmt=0.3390,且演唱关系边、作词关系边以及包含关系边的传播因子均为1,即λsm=1,λam=1,λtm=1。步骤s22:根据社交关系,计算在社交关系影响下的信息子网中各种类型边权重;步骤s221:歌曲-流派之间的被包含关系边的权重按照如下方式计算:其中,表示歌曲m所属于的流派个数,表示播放歌曲m的用户人数,p(t)表示流派t包含的歌曲列表;步骤s222:流派-歌曲之间的包含关系边的权重按照如下方式计算:其中,表示流派t包含的歌曲数;步骤s223:歌曲-歌手之间的被演唱关系边的权重按照如下方式计算:其中,表示歌曲m的歌手个数,表示播放歌曲m的用户人数,p(s)表示歌手s演唱的歌曲列表;步骤s224:歌手-歌曲之间的演唱关系边的权重按照如下方式计算:其中,表示歌手s演唱的歌曲数;步骤s225:歌曲-作词者之间的被作词关系边的权重按照如下方式计算:其中,表示歌曲m的作词者个数,表示播放歌曲m的用户人数,p(a)表示作词者a作词的歌曲列表;步骤s226:作词者-歌曲之间的作词关系边的权重按照如下方式计算:其中,表示作词者a作词的歌曲数。步骤s23:结合传播因子与各种类型边权重在信息子网中进行随机游走,计算社交关系影响下的歌曲、歌手、作词者和流派等群体影响力;步骤s231:将信息子网中歌曲-歌曲之间边权重wmm、歌手-歌手之间边权重wss、作词者-作词者之间边权重waa、流派-流派之间边权重wtt、歌手-作词者之间边权重wsa、作词者-歌手之间边权重was、歌手-流派之间边权重wst、流派-歌手之间边权重wts、作词者-流派之间边权重wat、流派-作词者之间边权重wta均设置为0,即wmm,wss,waa,wtt,wsa,was,wst,wts,wat,wta都设置为对应大小的零矩阵;将歌曲-歌曲之间传播因子λmm、歌手-歌手之间传播因子λss、作词者-作词者之间传播因子λaa、流派-流派之间传播因子λtt、歌手-作词者之间传播因子λsa、作词者-歌手之间传播因子λas、歌手-流派之间传播因子λst、流派-歌手之间传播因子λts、作词者-流派之间传播因子λat、流派-作词者之间传播因子λta均设置为0,即λmm=λss=λaa=λtt=λsa=λas=λst=λts=λat=λta=0;步骤s232:在信息子网中,节点之间进行随机游走的转移概率矩阵tpm按如下方式计算:步骤s233:设定两个长度为n的向量vec_c与vec_r;vec_r中的值为信息子网中每个节点的影响力值,vec_c初始为并通过如下方式计算vec_r:其中,ε为全图随机跳转概率,n取值为信息子网中节点总个数;在本实施例中,n=15;步骤s234:通过以下两个公式计算vec_c以及vec_r:vec_c=vec_r,且当||vec_r-vec_c||≥ξ时,则继续以上两个公式的计算,否则得到vec_r,ξ为预设误差阈值;步骤s235:分别对vec_r中类型节点歌曲、歌手、作词者以及流派值进行排序,得到歌曲、歌手、作词者以及流派的群体影响力vec_cg,如表1所示。表1步骤s3:在音乐信息网络中计算元路径集metapath以及对应的元路径权重wmetapath;步骤s31:获取一音乐信息网络,在音乐信息网络中通过n步长随机游走得到与用户相关的信息子网g以及信息子网g的网络模式h0;步骤s311:根据用户与歌曲之间的播放关系,得到用户播放的歌曲节点集步骤s312:分别以mx(x=1,...,x)为中心,查找与mx相关的歌手、作词者以及流派的节点集步骤s313:分别以vj(j=1,...,j)为中心,查找与节点vj相关的其他歌曲节点集步骤s314:重复步骤s121至步骤s123,直至找到um中,以每个节点mx为中心的n步长内,且与该节点mx相关的节点集u包括歌曲节点集歌手节点集作词者节点集流派节点集由u构成的子网络即为用户的信息子网g。本实施例中,图4中用户u1对应的信息子网g如图6所示。步骤s32:对信息子网g进行剪枝,并在剪枝后的信息子网g′中计算不同类型边的权重,具体步骤如下;步骤s321:在信息子网g中,保留歌曲-歌手之间的被演唱关系边、歌曲-作词者之间的被作词关系边、歌曲-流派之间的被包含关系边,得到信息子网g′;从信息子网g中歌手-歌曲之间的演唱关系边、作词者-歌曲之间的作词关系边、流派-歌曲之间的包含关系边构成的集合中随机添加一条边至信息子网g′中,直到信息子网g′为强连通图为止,即可得到所述信息子网g通过剪枝枝后的信息子网g′;步骤s322:利用hetesim算法计算信息子网g′中每一对不同类型节点间的相关性,包括:歌曲-歌手之间的被演唱关系相关性、歌曲-作词者之间的被作词关系相关性、歌曲-流派之间的被包含关系相关性、歌手-歌曲之间的演唱关系相关性、作词者-歌曲之间的作词关系相关性以及流派-歌曲之间的包含关系相关性;本实施例中歌曲-歌手之间的被演唱关系边、歌曲-作词者之间的被作词关系边、歌曲-流派之间的被包含关系边的具体相关性计算结果如表2所示,歌手-歌曲之间的演唱关系边、作词者-歌曲之间的作词关系边、流派-歌曲之间的包含关系边的具体相关性计算结果分别与歌曲-歌手之间的被演唱关系边、歌曲-作词者之间的被作词关系边、歌曲-流派之间的被包含关系边的具体相关性相同。表2s1s2s4a1a2t1t2t3m10.5774000.577400.40820.33330.4082m300.50000.707101.0000.5000040820m40.5774000.5774000.57740m50.40820.500000.57740000.7071步骤s323:将步骤s22得到的相关性取倒数,得到所述信息子网g′不同类型边的权重。步骤s33:在信息子网g′中计算所有歌曲对之间的最短路径集shortpath和最短路径权重wshortpath;将最短路径集抽象为元路径实例集mshpath,并计算元路径集metapath、元路径实例路径数q和元路径权重wmetapath,具体步骤如下:步骤s331:对于信息子网g′中所有歌曲节点集计算所有歌曲对之间的最短路径集shortpath:利用单源最短路径算法计算歌曲mi到歌曲mj之间的最短路径shortpathij,其中,i,j=1,2,...q,i≠j;步骤s332:计算所有歌曲对之间的最短路径权重wshortpath:对于最短路径集shortpath中的每一条最短路径shortpathij,计算最短路径shortpathij的权重wshortpathij,计算公式为:其中,r为shortpathij的跳数;hetesimr为每一跳对应边er=<vs,vt>的相关性,s=1,...,n;t=1,...,n;步骤s333:根据信息子网g的网络模式h0,将最短路径集shortpath中的每一条最短路径shortpathij抽象为元路径mshpathij,得到所有歌曲对之间的元路径实例集mshpath和元路径实例权重wmshpath,计算为:wmshpath=wshortpath;步骤s334:将元路径实例集mshpath抽象为元路径集对每一条元路径metapathm,获取对应的所有元路径实例计算为:mshpathl′=mshpathij;步骤s335:计算所有的元路径权重wmetapath。进一步的,在本实施例中,在步骤s335中,计算所有的元路径权重wmetapath,具体步骤如下:步骤s3351:对每一条元路径metapathm对应的所有元路径实例计算每一条元路径实例mshpathl对应的元路径实例权重wmshpathl′,计算为;wmshpathl′=wmshpathij;步骤s3352:计算出元路径metapathm的权重wmetapathm,计算公式如下:其中,qm表示元路径metapathm对应的实例路径数。在本实施例中,所有歌曲对之间的最短路径集shortpath计算结果如表3所示,所有歌曲对之间的元路径实例集mshpath的计算结果如表4所示,元路径集metapath、元路径实例路径数目q和元路径权重wmetapath的计算结果如表5所示。表3m1m3m4m5m1[][m1,t1,m3][m1,a1,m4][m1,a1,m5]m3[m3,t1,m1][][m3,t2,m4][m3,s2,m5]m4[m4,a1,m1][m4,t2,m3][][m4,a1,m5]m5[m5,a1,m1][m5,st,m3][m5,a1,m4][]表4m1m3m4m5m1[]'mtm''mam''mam'm3'mtm'[]'mtm''msm'm4'mam''mtm'[]'mam'm5'mam''msm''mam'[]表5元路径名称metapath元路径实体路径数目q元路径权重wmetapath'mtm'40.4735'msm'20.5000'mam'60.5774步骤s4:指定用户u,在音乐信息网络中计算用户u对歌曲的偏好基因;步骤s41:根据元路径集metapath提取出元路径“歌曲-歌手-歌曲”(msm)、“歌曲-作词者-歌曲”(mam)、“歌曲-流派-歌曲”(mtm),根据元路径权重wmetapath分别提取出msm、mam、mtm对应的元路径权重wmetapaths、wmetapatha、wmetapatht;步骤s42:根据g(s|m)=wmetapaths、g(a|m)=wmetapatha、g(t|m)=wmetapatht和g(s|m)+g(a|m)+g(t|m)=1计算出用户u对歌曲对应的歌手、作词者、词派的偏好基因g(s|m)、g(a|m)、g(t|m)。在本实施例中,用户u对歌曲的流派t、歌曲的歌手s以及歌曲的作词者a之间的偏好基因如表6所示,由表6可得,用户id1播放歌曲过程中,有30.530%的可能性选择某种流派包含的歌曲,有32.241%的可能性选择某个歌手演唱的歌曲,有37.229%的可能性选择某个作词者作词的歌曲。表6歌曲属性偏好基因流派t30.530歌手s32.241作词者a37.229步骤s5:在信息子网中结合节点群体影响力和用户u对歌曲的偏好基因进行随机游走,得到面向用户u的节点影响力排名,从而得到该用户的歌曲推荐列表。步骤s51:根据步骤s4得到用户u对歌曲的偏好基因和信息子网的网络模式,将歌曲和歌手关系边的传播因子λms,歌曲和作词者关系边的传播因子λma,歌曲和流派关系边的传播因子λmt分别初始化为用户对歌曲的偏好基因g(s|m)、g(a|m)、g(t|m),即λms=g(s|m)、λma=g(a|m)、λmt=g(t|m);步骤s52:根据音乐信息网络中用户-用户间边权重以及用户-歌曲间边权重,计算出信息子网中各种类型边权重,具体步骤如下;步骤s521:根据音乐信息网络中用户之间的好友关系以及用户-歌曲间链接,计算出基于用户相似性填充后的所有歌曲评分scoreu,具体步骤如下;步骤s5211:根据用户-歌曲间边权重umw,若用户u对歌曲m的边权重umwum不为0,则用户u对歌曲m的评分为scoreum=umwum,否则转步骤s5212;步骤s5212:根据所述用户-歌曲间边权重umw,计算出点播过歌曲的用户集mu以及对应的边权重muw;步骤s5213:利用hetesim算法计算出基于元路径“用户-歌曲-歌手-歌曲-用户”(umsmu)、“用户-歌曲-作词者-歌曲-用户”(umamu)、“用户-歌曲-流派-歌曲-用户”(umtmu)下的用户u与每一个用户v∈mu之间的相似性,得到用户相似性行向量usersimu,并对usersimu进行min-max标准化;步骤s5214:若usersimu的最大值大于用户相似性阈值simthre,则根据以下公式1计算出用户u对歌曲m的评分scoreum,否则根据以下公式2计算出用户u对歌曲m的评分;其中,un={r|r∈mu∧usersimur≥simthre},usersimuv为用户u与用户v的相似性,umwvm为用户v对歌曲m的边权重;scoreum=usersimuv*umwvm公式2其中,v={v∈mu∧usersimuv=max(usersimu)},usersimuv为用户u与用户v的相似性,umwvm为用户v对歌曲m的边权重;步骤s522:根据步骤s521得到基于用户相似性填充后的所有歌曲评分scoreu,将步骤s22中初始化为歌曲的评分scoreu,m;在本实施例中基于用户相似性填充后的所有歌曲评分scoreu如表7所示。表7m1m2m3m4m5m6歌曲评分4.00002.17343.00003.00002.00003.2490步骤s523:重复步骤s221至步骤s226,得到信息子网中歌曲-作词者之间边权重wma、作词者-歌曲之间边权重wam、歌曲-歌手之间边权重wms、歌手-歌曲之间边权重wsm、歌曲-流派之间边权重wmt、流派-歌曲之间边权重wtm;步骤s53:根据步骤s2得到社交关系影响下的节点群体影响力,将步骤s233中节点影响力vec_c初始化为vec_m,并重复步骤s231至步骤s234,得到信息子网中节点影响力vec_r,如表8所示。表8节点名称节点影响力a10.1477m10.1395m60.1123s10.0876m40.0799t20.0698m30.0681m50.0602t30.0496s20.0388t10.0374a20.0352m20.0308s40.0265s30.0167步骤s54:根据节点影响力vec_r中抽取出歌曲影响力,并进行影响力排序,得到歌曲的影响力排序vec_m,再从vec_m中选择前k首歌曲作为用户u的歌曲推荐列表vec_mr,如表9所示。表9歌曲名称m1m6m4以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1