一种多姿态行人检测方法与流程
本发明涉及一种检测方法,尤其是一种多姿态行人检测方法。
背景技术:
行人检测可定义为:判断输入图片是否包含行人,如果有,给出位置信息。它是车辆辅助驾驶、智能视频监控和人体行为分析等应用中的第一步,近年来也应用在航拍图像、受害者营救等新兴领域中。由于背景的复杂性,行人往往在场景中不会单独出现,因此不可避免的会有遮挡以及角度和姿态的不同带来的非刚体的形变等等,使得行人检测成为计算机视觉的研究难点与热点.
题为《基于后验hog特征的多姿态行人检测》的论文。该论文涉及的是一种基于后验hog特征的行人检测方法,先统计全部行人样本的共性信息——梯度特征能量,对个体样本的hog特征进行加权处理,得到表征行人边缘的后验hog特征,然后利用s-isomap特征降维方法和k-means聚类方法对不同姿态和视角的行人做子类划分,并集成各子类分类器的方法。但是该方案模型死板,而行人具有非刚性的特点,难以适应其运动;对于行人躺下,蹲下,弯腰等姿态,没有针对的相应姿态训练,无法检测到此类姿态;而且,在行人下半身被遮挡的情况,难以被检测。
技术实现要素:
为克服现有的技术缺陷,本发明提出一种多姿态行人检测方法,本方法针对多姿态行人的非刚性,提出以行人头肩作为训练正样本,并根据姿态类型分成两类正样本,训练得到两个可形变部件模型针对不同的姿态进行检测。在检测过程中,利用旋转特征图进行检测的方法,适应了多角度多姿态的行人检测。本发明采用以下技术方案予以实现,包括以下步骤:
1)创建样本集:所述样本集包括正样本集及负样本集;
2)对样本集进行dpm特征提取:对所述样本集中的样本进行dpm特征提取得到dpm特征向量;
3)样本训练:把所述第一类正样本和负样本提取得到的dpm特征输入lsvm分类器中得到第一行人检测器,对所述第二类正样本和负样本提取得到的dpm特征输入lsvm分类器中得到第二个行人检测器;
4)行人检测:通过所述第一个行人检测器和第二个行人检测器计算待测图像的分数从而进行行人检测。
进一步地,步骤1)中,所述正样本集中的正样本分为第一类正样本和第二类正样本,第一类正样本主要包括站立、行走、坐着的姿态图片,第二类正样本是人躺着的姿态的图片;所述负样本集中的负样本从现实场景的背景图片进行采样得到。
进一步地,步骤2)中,对所述第一类正样本和负样本提取dpm特征向量的dpm可形变部件模型的部件个数为4个,部件尺寸为6*6像素。
进一步地,所述正样本集中第二类正样本还包括对第二类正样本进行适当的角度旋转后的样本。
进一步地,步骤2)中,对所述第二类正样本和负样本提取dpm特征向量的dpm可形变部件模型的部件个数为5个,部件尺寸为6*6像素。
进一步地,步骤2)中,对所述样本集中的正样本和负样本进行提取后得到的hog特征向量为36维dpm特征向量。
进一步地,步骤3)中,所述降维后得到的dpm特征为13维。
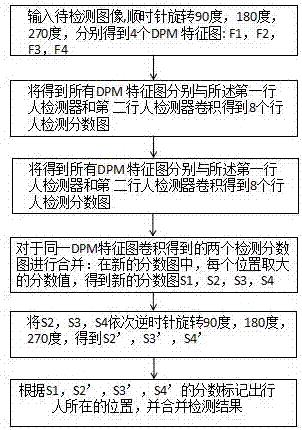
进一步地,步骤5)中,所述行人检测方法步骤包括如下:
41)输入待检测图像,顺时针旋转90度,180度,270度,并分别计算得到4个dpm特征图:f1、f2、f3、f4;
42)将步骤51)中的得到所有dpm特征图分别与所述第一行人检测器和第二行人检测器卷积得到8个行人检测分数图;
43)对于同一个dpm特征图卷积得到的两个检测分数图进行合并:在新的分数图中,每个位置取两个检测分数图中对应位置较大的分数值,得到新的分数图s1、s2、s3、s4分别对应f1、f2、f3、f4;
44)将s2、s3、s4依次逆时针旋转90度、180度、270度,得到s2’、s3、s4’;
45)根据s1、s2’、s3’、s4’的分数标记出行人所在的位置,并合并检测结果。
进一步地,步骤4)中,所述分数表达式为β·φ(x),其中β是第一行人检测器或第二行人检测器,它们都是特征向量滤波器,φ(x)是图像及指定的位置和尺度,x是特征向量,计算得到分数越大,表示检测窗口中行人的可能性越大。
进一步地,对于步骤2)所述降维的具体方法如下:把36维dpm特征向量看做一个4*9的矩阵,令v={u1,...,u9}∪{v1,...,v9},其中ui和vi都是36维向量,其4*9的矩阵表达形式满足下列条件:
然后用36维dpm特征与每个uk和vk进行点积,即计算矩阵表达的某列4个归一化值的和来获得dpm特征向每个uk的投影,计算矩阵表达的某行的9个归一化值的和来获得dpm特征向每个vk的投影,从而得到一个13维的特征向量。
与现有技术比较,本发明提供了一种多姿态行人检测方法,该方法将行人头和肩膀作为训练样本分为多个部件,训练了多个子模型,综合了主模型和子模型的匹配程度,以及利用主模型和子模型的空间位置关系,适应了运动过程中多种姿态行人的非刚性。本方法将姿态分为两类进行训练,且在检测过程中对特征图进行旋转,适应了各种姿态。以行人的头肩作为训练样本,避免了下半身被遮挡无法检测的情况。
附图说明
图1为本发明的方法流程图;
图2为本发明的行人检测流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明实施方式作进一步详细地说明。
1)创建样本集:所述样本集包括正样本集及负样本集,所述正样本集中的正样本分为第一类正样本和第二类正样本,第一类正样本主要包括站立,行走,坐着的姿态图片,第二类正样本是人躺着的姿态的图片。所述负样本集中的负样本是从现实场景的背景图片进行采样得到。对第二类正样本进行适当的角度旋转,加入第二类正样本,仍记做第二类正样本。
2)对样本进dpm特征提取中,对所述样本集中的正样本和负样本进行dpm特征,提取后得到的dpm特征向量为36维dpm特征向量。
然后对dpm特征向量进行降维:降维的具体方法如下:
36维dpm特征向量来自4个不同的归一化9维方向直方图,所以36维dpm特征向量可以看做一个4*9的矩阵。设v={u1,...,u9}∪{v1,...,v9},其中ui和vi都是36维向量,其4*9的矩阵表达形式满足下列条件:
定义一个13维特征,其中的元素是36维dpm特征与每个uk和vk的点积。计算对应方向的4个归一化值的和(即矩阵表达的某列的和)来获得dpm特征向每个uk的投影,计算对应归一化方法的9个方向值的和(即矩阵表达的某行的和)来获得dpm特征向每个vk的投影。
3)样本训练:训练步骤如下:
对第一类正样本和负样本提取dpm特征向量并输入lsvm分类器中得到第一行人检测器,其中dpm可形变部件像素模型的部件个数为4个,部件尺寸为6*6像素。
对第二类正样本和负样本提取dpm特征向量并输入lsvm分类器中得到第二行人检测器,其中dpm可形变部件像素模型的部件个数为5个,部件尺寸为6*6像素。
4)行人检测:由于所有的检测器都是特征向量滤波器,计算分数β·φ(x),其中β是第一行人检测器或第二行人检测器,它们都是特征向量滤波器,φ(x)是图像及指定的位置和尺度,x是特征向量。计算得到分数越大,表示检测窗口中行人的可能性越大。行人检测的基本步骤如下:
41)输入待检测图像,顺时针旋转90度,180度,270度,并分别计算得到4个dpm特征图:f1、f2、f3、f4;
42)将步骤41)中的得到所有dpm特征图分别与第一行人检测器和第二行人检测器卷积得到8个行人检测分数图;
43)对于同一个dpm特征图卷积得到的两个检测分数图进行合并:在新的分数图中,每个位置取两个检测分数图中对应位置较大的分数值,得到新的分数图s1、s2、s3、s4分别对应f1、f2、f3、f4;
44)将s2、s3、s4依次逆时针旋转90度、180度、270度,得到s2’、s3’、s4’;
45)根据s1、s2’、s3’、s4’的分数标记出行人所在的位置,并合并检测结果,从而得出图像上行人的具体位置。
本发明提出的多姿态行人检测方法,能够适应行人非刚性形变的特点,对于不同姿态不同角度的行人进行检测,适用于检测场景下,不同姿态和相机角度的行人。
- 还没有人留言评论。精彩留言会获得点赞!