基于attentionCNNs和CCR的文本情感分析方法与流程
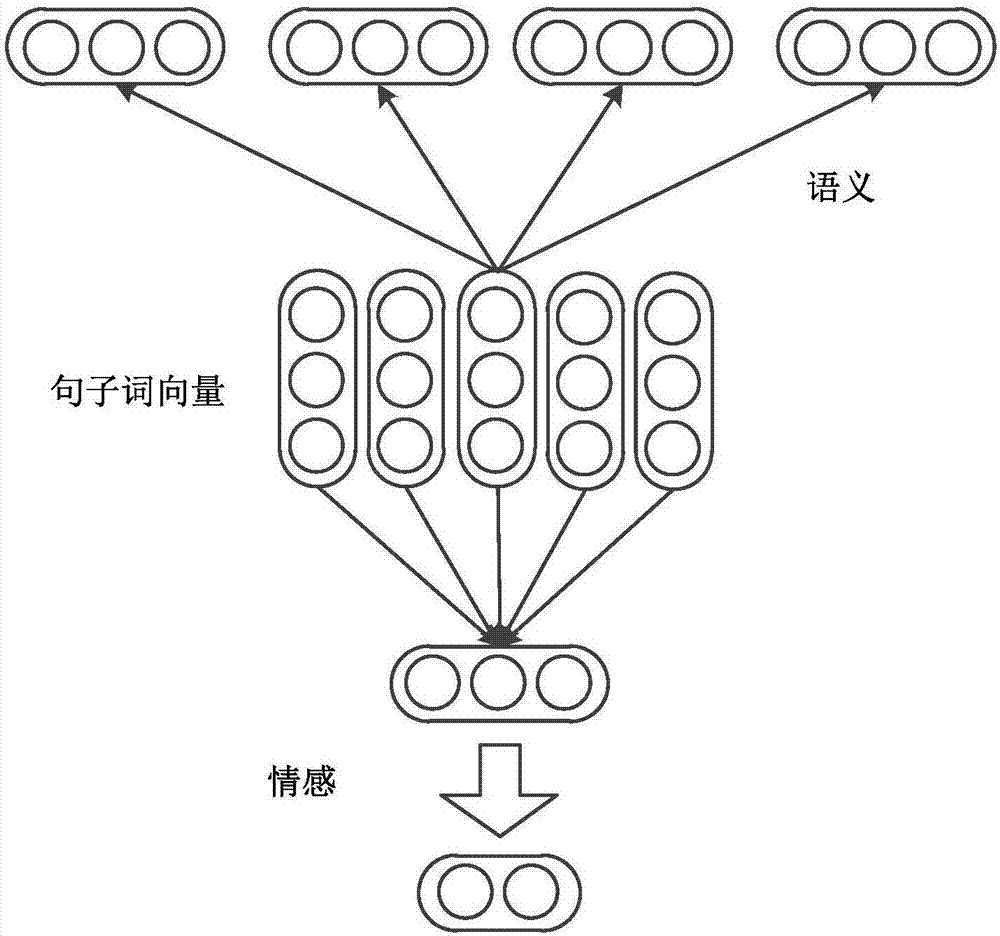
本发明是一种对文本情感进行分析的方法,属于自然语言处理领域。
背景技术:
随着推特(twitter)、脸书(facebook)、微博(weibo)等社交平台和亚马逊(amazon)、淘宝(taobao)等电子商务平台的兴起,网络上评论性文本资源与日俱増。面对来自微博、论坛的大量非结构化的评论文本,迫切需要通过自然语言处理技术对文本中表达的情感倾向进行分析判断。例如,从评论中识别出商品属性的情感信息,可为商家和其他用户提供决策支持;在舆情监控中,政府可及时了解民众对突发事件、社会现象的态度,引导舆论趋势。传统情感分析绝大多数都是采用传统nlp特征与机器学习相结合的方式来构建模型。但传统nlp特征的设计往往需要专家的领域知识,人工成本较高,系统的泛化性和迁移性差。近两年兴起的深度学习方法能较好地弥补上述方法的缺陷,深度学习能够自动学习出描述数据本质的特征表达,从而避免了人工设计特征的缺陷。
目前,深度学习用于情感分析的技术包括词向量,卷积神经网络和循环神经网络等。每个词通过一组词向量表示,并且词向量与词向量之间存在特定关系。句子表示为词向量矩阵后,利用卷积神经网络convolutionalneuralnetwork(cnn)结构提取文本特征。但这种特征只能表示文本的局部信息缺乏全局特征,所提取的特征较为单一,不足以体现文本的情感极性。特征质量直接决定情感分类精度的高低,因此怎样提取出更合适的文本特征是一项非常重要的工作。其次传统词向量的学习是通过训练学习语言模型而得到的产物,词的分布式表达中仅包含了语义和语法信息,缺乏了情感信息,而在情感分析任务中,情感信息起着非常重要的作用。
技术实现要素:
本发明提出一种基于attentioncnns结合注意力的卷积神经网络和ccr多模一致回归的文本情感分析方法,通过分析分词文本的情感极性,解决只提取分析文本的局部特征,从而导致缺乏全局特征,提取的特征单一,不足以体现文本的情感极性的问题。
为达到发明目的采取的具体技术方案为:
基于attentioncnns和ccr的文本情感分析方法:
步骤一、首先将原始文本数据分为训练样本及测试样本。然后对原始文本数据进行分词处理得到分词文本,利用分词文本进行语义词向量和情感词向量训练。利用已有情感词典进行词典词向量构建。
步骤二、利用语义词向量、情感词向量和词典词向量分别表示分词文本,得到三种类型初始输入词向量矩阵。利用长短时记忆网络lstm捕获三种类型初始输入词向量矩阵中每一单词的上下文语义,融入上下文信息后得到三种类型输出词向量矩阵,输出词向量矩阵能够消除单词歧义。
所述三种类型初始输入词向量矩阵包括:初始输入词典词向量矩阵、初始输入语义词向量矩阵和初始输入情感词向量矩阵。所述三种类型输出词向量矩阵包括:输出词典词向量矩阵、输出语义词向量矩阵和输出情感词向量矩阵。
步骤三、利用卷积神经网络cnn并结合不同滤波长度的卷积核提取三种类型输出词向量矩阵的局部特征。
步骤四、利用三种不同的注意力机制,即长短时记忆网络注意力机制、注意力采样以及注意力向量分别提取输出语义词向量矩阵和输出情感词向量矩阵的全局特征。
步骤五、对原始文本数据提取人工设计特征。
步骤六、利用所述局部特征、所述全局特征及所述人工设计特征对多模一致回归目标函数进行参数训练。
步骤七、求得多模一致回归最佳参数,通过多模一致回归预测方法对初始输入词向量矩阵进行正向,中立或者负向情感极性分析。
具体地,所述语义词向量训练:采用skip-gram模型训练语义词向量。该模型从目标词w的上下文c中选择一个词,将上下文c中的一个词作为模型输入,预测目标词w。首先将原始文本数据进行分词处理得到分词文本,然后将分词文本送入skip-gram模型,通过最大化语义词向量损失函数:
得到语义词向量。其中,z表示分词处理后的文本,w表示目标词,c表示目标词所对应的上下文,wj表示上下文c中的一个词,j表示上下文c中单词个数,p(wj|w)表示通过目标词w预测wj的概率。
所述情感词向量训练:在skip-gram模型基础上加入分类层softmaxlayer,用于训练情感词向量。语义部分损失函数与语义词向量相同,情感部分损失函数为
lsentiment=∑y·log(y_pred)
其中,y-pred=softmax(x)表示预测的情感标签,x表示上述训练得到的语义词向量,y表示真实情感标签。最后将语义词向量损失函数lsemantic和情感部分损失函数lsentimen线性结合得到情感词向量损失函数:
所述词典词向量构建:情感词典包含一个词的情感得分,不同情感词典得分标准不同。本发明将所有情感词典单词得分归一化到[-1,1],得到词典词向量矩阵。矩阵中每一行代表一个词在不同情感词典的情感得分,若一单词未出现在某一情感词典当中,用0代替。
具体地,步骤二的具体过程为:原始文本数据经过分词处理后的分词文本利用上述所得词向量表示,得到三种类型初始输入词向量矩阵d且
具体地,所述步骤三的具体处理过程为:利用滤波长度l的cnn卷积核,对三种类型的输出词向量矩阵
具体地,所述步骤四的具体处理过程为:
a、利用双向长短时记忆网络注意力机制提取输出词向量矩阵
b、注意力采样提取输出词向量矩阵
c、注意力向量提取输出词向量矩阵
具体地,所述人工设计特征包括:形态学特征、词性特征、否定检测、词典得分。所述形态学特征包括大写单词个数、问号出现次数,感叹号出现次数。所述词性特征包括:每种词性词在句中所出现次数。所述否定检测包括:否定词出现次数。所述词典得分包括:句子情感总得分和句子最后一词得分。
具体地,所述步骤六的具体处理过程为:首先定义p和q为两种长度相同的离散概率分布,d(p||q)定义为kl散度之和:d(p||q)=dkl(p||q)+dkl(q||p)。将语义词向量局部特征xl1、词典词向量局部特征xl2、全局特征xg1及人工特征xt首尾相连聚合成特征x1=[xt;xg1;xl1;xl2]t。同样将情感词向量局部特征xl3、词典词向量局部特征xl2、全局特征xg3及人工特征xt首尾相连聚合成特征x2=[xt;xg3;xl3;xl2]t。将特征x1和特征x2首尾相连聚合成特征xc。最后,最小化多模一致回归目标函数求得多模一致回归的参数。
其中,
具体地,所述步骤七的具体处理过程为:特征
其中j=1,2,3分别代表正向,中立和负向三种情感类别。
由于卷积神经网络提取的特征仅表现文本的局部,本发明在skip-gram模型上增加了分类层(softmaxlayer)用于训练情感词向量,通过搜集大量的情感词典,构成了一个更全面的词典向量,将注意力机制提取文本全局特征与局部特征进行ccr机制融合结合,达到提高分类精度的目的。该方法能够同时捕捉语义及情感信息,提高情感分析的精确度,丰富文本提取的特征。
附图说明
图1为本发明的系统流程图;
图2为情感词向量模型图;
图3为lstmattention结构图;
图4为一元注意力向量结构图;
图5为二元注意力向量结构图;
图6为本发明系统模型图。
具体实施方式
本发明的方法包括以下步骤:1、利用原始文本数据训练语义词向量和情感词向量并利用搜集的情感词典进行词典词向量构建;2、利用长短时记忆网络lstm捕获单词的上下文语义用于歧义消除;3、利用卷积神经网络(结合不同滤波长度的卷积核提取文本的局部特征;4、再利用三种不同的注意力机制分别提取全局特征;5、对原始文本数据进行人工特征提取;6、利用局部特征,全局特征以及人工特征对多模一致回归目标函数进行训练;7、利用多模一致回归预测方法进行情感极性预测。本发明相对于采用单一词向量或仅提取文本局部特征等方法,能够进一步提高情感分类精度。
如图1和图6所示,基于attentioncnns和ccr的文本情感分析方法具体过程为:
步骤一、首先将原始文本数据分为训练样本及测试样本。然后对原始文本数据进行分词处理得到分词文本,利用分词文本进行语义词向量和情感词向量训练。利用已有情感词典进行词典词向量构建。
所述语义词向量训练:采用skip-gram模型训练语义词向量。该模型从目标词w的上下文c中选择一个词,将上下文c中的一个词作为模型输入,预测目标词w。首先将原始文本数据进行分词处理得到分词文本,然后将分词文本送入skip-gram模型,通过最大化语义词向量损失函数:
得到语义词向量。其中,z表示分词处理后的文本,w表示目标词,c表示目标词所对应的上下文,wj表示上下文c中的一个词,j表示上下文c中单词个数,p(wj|w)表示通过目标词w预测wj的概率。
如图2所示,所述情感词向量训练:在skip-gram模型基础上加入分类层softmaxlayer,用于训练情感词向量。语义部分损失函数与语义词向量相同,情感部分损失函数为
lsentiment=∑y·log(y_pred)
其中,y-pred=softmax(x)表示预测的情感标签,x表示上述训练得到的语义词向量,y表示真实情感标签。最后将语义词向量损失函数lsemantic和情感部分损失函数lsentimen线性结合得到情感词向量损失函数:
所述词典词向量构建:情感词典包含一个词的情感得分,不同情感词典得分标准不同,本发明将所有情感词典单词得分归一化到[-1,1],得到词典词向量矩阵。矩阵中每一行代表一个词在不同情感词典的情感得分,若一单词未出现在某一情感词典当中,用0代替。
步骤二、利用语义词向量、情感词向量和词典词向量分别表示分词文本,得到三种类型初始输入词向量矩阵。利用长短时记忆网络lstm捕获三种类型初始输入词向量矩阵中每一单词的上下文语义,融入上下文信息后得到三种类型输出词向量矩阵,输出词向量矩阵能够消除单词歧义。三种类型初始输入词向量矩阵包括:初始输入词典词向量矩阵、初始输入语义词向量矩阵和初始输入情感词向量矩阵。所述三种类型输出词向量矩阵包括:输出词典词向量矩阵、输出语义词向量矩阵和输出情感词向量矩阵。
如图3所示,具体过程为:原始文本数据经过分词处理后的分词文本利用上述所得词向量表示,得到三种类型初始输入词向量矩阵d且
步骤三、利用卷积神经网络cnn并结合不同滤波长度的卷积核提取三种类型输出词向量矩阵的局部特征。具体处理过程为:利用滤波长度l的cnn卷积核,对三种类型的输出词向量矩阵
步骤四、利用三种不同的注意力机制,即长短时记忆网络注意力机制、注意力采样以及注意力向量分别提取输出语义词向量矩阵和输出情感词向量矩阵的全局特征。具体处理过程为:
a、利用双向长短时记忆网络注意力机制提取输出词向量矩阵
b、注意力采样提取输出词向量矩阵
c、注意力向量提取输出词向量矩阵
步骤五、对原始文本数据提取人工设计特征xt。所述人工设计特征包括:形态学特征、词性特征、否定检测、词典得分。所述形态学特征包括大写单词个数、问号出现次数,感叹号出现次数。所述词性特征包括:每种词性词在句中所出现次数。所述否定检测包括:否定词出现次数。所述词典得分包括:句子情感总得分和句子最后一词得分。
步骤六、利用所述局部特征、所述全局特征及所述人工设计特征对多模一致回归目标函数进行参数训练。具体处理过程为:首先定义p和q为两种长度相同的离散概率分布,d(p||q)定义为kl散度之和:d(p||q)=dkl(p||q)+dkl(q||p)。将语义词向量局部特征xl1,词典词向量局部特征xl2,全局特征xg1及人工特征xt首尾相连聚合成特征x1=[xt;xg1;xl1;xl2]t。同样将情感词向量局部特征xl3,词典词向量局部特征xl2,全局特征xg3及人工特征xt首尾相连聚合成特征x2=[xt;xg3;xl3;xl2]t。最后将特征x1和特征x2首尾相连聚合成特征xc。最后,最小化多模一致回归目标函数求得多模一致回归的参数。
其中,
步骤七、求得多模一致回归最佳参数,通过多模一致回归预测方法对初始输入词向量矩阵进行正向,中立或者负向情感极性分析。具体处理过程为:特征
其中j=1,2,3分别代表正向,中立和负向三种情感类。
- 还没有人留言评论。精彩留言会获得点赞!