一种人民矛盾调解案例搜索和调解策略推荐方法与流程
本发明涉及搜索技术和策略推荐领域,尤其是司法领域人民矛盾调解案例搜索和调解策略推荐方法。
背景技术:
互联网技术急速发展,信息资源爆炸式增长,深刻影响人们的工作和生活方式。如今,互联网逐渐成为获取资源和信息交流的主要场所,用户可以通过互联网搜索得知大量信息,给工作和生活带来极大的便利。然而,随着网络资源的增长,通过搜索引擎获得的结果并不一定是用户期望得到的信息,往往还需要在搜索结果中进行查找筛选,这就降低了用户的搜索效率。并且,现有的基于web的搜索引擎无法针对特定的领域提供搜索服务。因此如何提高用户获取目标搜索结果的效率,提高用户体验度以及形成特定领域的搜索引擎,是目前搜索技术领域具有挑战性的问题。
如今,在提高搜索质量,专业领域及个性化需求的搜索引擎方面开展了大量的工作。专利cn201010559233针对多个搜索引擎得到的搜索结果不同,对来自多个搜索引擎的搜索结果按照索引擎的权重及搜索引擎上的排序位置权重进行基础排序;再根据共现信息等情况来对基础排序进行修正调整,使搜索排序的依据更合理,提高了搜索结果的质量。专利cn201210548858.2在浏览器窗口提供搜索类别列表和搜索引擎列表,用户可以对相同的搜索输入,采用不同的搜索类别和搜索引擎产生对应的搜索结果。考虑到不同的浏览器和类别对搜索结果的影响,但是需要不断变换浏览器和搜索类别组合搜索,以找到符合需求的信息。专利cn201310226576.5根据用户搜索词给出第一搜索结果并接收用户针对第一搜索结果的行为数据。根据视觉特征、用户行为数据和搜索词生成推荐搜索词,能够准确挖掘用户的搜索意图,搜索结果更具针对性,满足用户搜索的个性化需求,改善用户搜索体验。专利cn102567326b公开了一种信息搜索排序装置和方法,包括:确定单元,预测单元,排序单元,结合搜索日志信息、组织架构信息提高搜索结果的准确性。
人民调解搜索服务是针对司法领域的专业性搜索引擎,基于web的搜索引擎模式及服务,不能满足用户的需求,需要定制专业领域搜索服务;调解案例作为案例搜索服务的数据来源,数据量较大,没有明确的填写规范,数据填写多样化,会影响搜索引擎服务质量。如:大多数案例均为短文本数据,传统的tf_idf等算法搜索准确率不高;从大量的案例中找出具有代表性的案例供学习使用时,比较耗费时间和精力;案例中涉及大量的隐私信息,人工脱敏处理工作量大等。
技术实现要素:
为了克服已有人民调解搜索方式的准确率不高、耗费时间较长的不足,本发明提供一种准确率较高、耗费时间较短的人民矛盾调解案例搜索和调解策略推荐方法。
本发明解决其技术问题所采用的技术方案是:
一种人民矛盾调解案例搜索和调解策略推荐方法,包括以下步骤:
步骤1:数据收集、预处理
收集人民调解案例信息,存储在数据库中,需要包含的字段包括:纠纷详情、调解结果、调解详情、调解时间、结束时间、调解人、所属地区、调解机构和评价字段,其中,纠纷详情、调解详情和评价是文本数据,其他字段均为结构化数据。
对收集到的数据进行预处理,确保调解结果、调解详情字段不为空,将重复数据删除;
步骤2:分词及向量表示
创建矛盾调解专业领域词典mediate.txt,将容易分词错误的词,尤其是矛盾调解专业领域词汇,根据调解案例数据将无法正确切分的词,加入矛盾调解专业领域词典mediate.txt;另外汉语中还存在一些无意义的词,将这些无意义、区分度不高的词加入停用词典stopword.txt,分词时直接将停用词去掉不作分析;
根据词典mediate.txt和停用词典stopword.txt将文本字段进行分词,将文本数据表示为向量的形式;
步骤3:tf_cdf特征聚类
由于矛盾调解案例无详细类别信息,采用tf_cdf计算文本单词权重,并进行tf_cdf特征聚类获案例详细类别及类别关键词,同时从聚类结果中获取单词tf_cdf值;
步骤4:自动脱敏并进行案例评分自动并生成脱敏典型案例集;
步骤5:生成调解策略提示
以带有类别标签的典型案例作为分析数据,某一个类别按照以下过程生成调解策略:
(5.1)获取带有类别标签的典型案例集,提取调解策略字段;
(5.2)调解策略有一二三等条例标识,按照标识将调解策略断开,形成调解条例;
(5.3)将调解条例进行tf_cdf聚类分析,并提取调解条例的关键词;
(5.4)对调解条例进行类别评分。评分依据包括类别中包含调解条例的条数、具有相同关键字的调解条例在类别中所占的比例;
(5.5)调解条例进行评分,评分依据包括:条例中类别关键词出现的个数和次数和文本的质量;
(5.6)将调解条例类别评分降序排序,提取评分较高的类别,在这些类别中提取分值高的调解条例,作为调解策略提示信息,保存在数据库中;
步骤6:创建索引及计算相关度
全文搜索引擎的核心包括索引创建和相关度计算,将步骤4中的典型案例数据和得到的聚类类别及步骤5中调解策略提示等同步到elasticsearch创建索引;
步骤7:搜索结果及界面展示
用户输入查询内容,获得相似典型案例、案例类别及类标签信息、调解策略推荐,并自动生成相似案例分析报告。
进一步,所述步骤7中,搜索过程如下:
(7.1)相似案例。搜索结果默认按照相关度降序排序输出,用户可手动对检索结果进行过滤和排序,例如显示指定类型和时间段的案例,按照时间升序或者降序排序等;
(7.2)案例类别及类标签,可作为检索的过滤条件,每个案例均显示对应的案例类别和类别关键词;
(7.3)调解策略推荐:根据搜索的得到的相关案例,自动推荐调解策略;
(7.4)检索结果分析:用户在需要时点击分析按钮,获取检索结果分析报告,报告分为:时间分析、空间地域分析、调解机构分析、调解人员分析、调处结果分析和调解用时分析,根据分析结果在结果集上进行二次搜索。
再进一步,所述步骤3中,对矛盾调解中“案件详情”字段进行特征聚类步骤如下所示:
(3.1)初始值确定
人民矛盾调解“案例详情”可聚为k类,共n条矛盾案例,构成语料库d={d1,d2,....,dn},这里语料库是指所有案例中的“案件详情”字段信息的集合,d是组成语料库的单个“案件详情”信息,将语料库中文本进行分词,获得的不重复单词为{t1,t2,....,tn};
(3.2)按照余弦相似度将“案件详情”分配到最近邻聚类
采用余弦相似度作为聚类的度量标准,如公式(1)所示:
其中,
(3.3)更新tf_cdf模型
计算聚类的类内离散度e,如果e小于初始类内离散度的一半e0/2,则更新tf_cdf;如果聚类误差e大于e0/2则跳过步骤(3.3);按照公式(2)计算单词的类别熵:
其中,
本发明采用公式(3)计算某个单词wp的tf_cdf值:
其中,tfp是单词wp在文本i中的词频,dfp单词文档频率是指语料库中包含这个单词的文档数量,分母中h(wp)是单词的熵,ln()是自然对数函数,减小文档频率比重;ε是一个比较小的值,防止h(wp)为0时出现错误,综合考虑词频、文档频率和类别熵,相对于短文本准确性更高
(3.4)更新聚类中心:将每个类中文本向量的均值作为新的聚类中心;
(3.5)重复步骤(3.2)~(3.4),直到聚类中心不再变化,则tf_cdf值不再变化,得到k个类别和tf_cdf模型;
(3.6)类标签提取,聚类完成后,提取每个类别中单词tf_cdf较高的几个词作为类别标签。
所述步骤(3.1)中,初始值确定过程如下:
①初始tf_cdf值确定
给定单词初始tf_cdf的值为单词词频。某个案例i经过分词后,表示为di={w1,w2,...,wj},j=1,2,...,n,n是语料库中进过分词后的不重复单词个数,wj是单词tj在案例i中出现的次数;
②初始聚类中心确定
计算k个距离较远的初始聚类中心:c={c1,c2,...,ck},cj={c1,c2,...,cn},c是k个聚类中心,c是单个聚类中心的向量形式,为表达方便类标签全部用上标表示;
③聚类类内离散度计算
计算各个案例与初始案例中心的距离和,确定初始聚类类内离散度e0。
所述步骤(3.3)中,迭代多次执行一次更新tf_cdf值,或者设定一个聚类中心改变值的阈值,超过这个阈值时执行更新。
所述步骤(4)中,自动生成脱敏典型案例集的过程如下:
(4.1)自动脱敏
采用自然语言处理技术自动识别人名和住址信息,将识别出的信息在原文中用某某代替;
(4.2)自动生成典型案例集
通过案例评分,由机器自动生成高质量典型案例集,步骤3将案例划分为不同类别,分别对每个类别进行案例评分,将每个类别中案例评分较高的案例作为本类的典型案例。
所述步骤(4.2)中,案例评分模型创建方法如下:
①分析案例模板,将其划分为案情简介、调解过程、调处结果说明、调解心得模块;
②采用自然语言处理方法分析每个案例组成模块的文本质量,
qt=aql+bqp+cqs(4)
其中,a+b+c=1是各个质量评分所占的比重,ql是文字数值质量,如果未分词的文本长度,大于一定的阈值tl,则ql为1,否则ql按指数衰减;qp是文字重复比例,即文本中出现频次最高的词占文本总词数的比例,qp小于一定的阈值tp时值为1,大于一定阈值时按指数衰减,qs是经过分词后文本长度与分词前文本长度的比例;
③赋予各调解人员一定的评分权重;将调解员经常处理的,并且调解成功率较高的案件的案例调解人员评分权重qh∈[0,1]提高;
④对调解反馈信息进行情感分析,获得调解反馈权重qe;给积极反馈和消极反馈赋予评分权重,积极评分的权重较高;
⑤综合考虑根据以上几个方面,创建案例评分模型q=(αqh+βqe)qt,α是qh在案例评分中占的比重,β是qe所占的案例评分权重,α+β=1,根据案例评分模型,对案例信息进行评分,自动生成带有类别标签的典型案例集。
所述步骤6中,创建索引及计算相关度的过程如下:
(6.1)创建索引
采用es对“纠纷详情”和“调处结果说明”、“调解策略推荐”创建全文索引,其中,“纠纷详情”和“调处结果说明”是原始数据中包含的字段,“调解策略推荐”是步骤5中计算获得的字段;
(6.2)相关度计算
步骤3中聚类获得了类别、类标签、聚类中心及tf_cdf值,本专利采用tf_cdf权重表示文本向量,另外,输入搜索内容query,分词获得pn个单词,同样用tf_cdf向量表示,计算文本相似度。如果单词出现在类标签中,则相应的提高文本相关度。
本发明的技术构思为:构建适用于短文本搜索、准确性高的司法领域案例搜索服务。采用自然语言处理技术和高级机器学习技术,自动实现调解文书质量评分及高质量调解案例库的构建,并在此基础上挖掘相似案例的调解策略,促进人民调解“同案同调”、“公正调解”。本发明通过文本tf_cdf特征聚类获取案例类别和类标签;采用elasticsearch创建分布式容错索引,根据tf_cdf值和聚类标签计算文本相关度,获得相似案例,提高全文搜索及按类别搜索功能准确性。
本发明的有益效果主要表现在:
1)将矛盾调解案例类型细分,不仅能够挖掘案例中隐藏的类别信息,更方便用户按类别查找,提高用户体验。
2)针对案例搜索专业领域特征,进行案例质量评分,自动脱敏生成高质量典型案例集。
3)针对相同类别案例产生调解策略提示,方便用户了解相似案例的处理方式,促进人民调解“同案同调”、“公正调解”。
4)针对矛盾调解案例短文本数据特性,获取tf_cdf模型,综合单词词频和类别文档频率,比常用的tf_idf模型效果更好。
5)采用tf_cdf进行特征聚类,将余弦相似度作为聚类的度量标准。
6)搜索输出默认按照相似度进行排序,采用tf_cdf值、类标签计算文本相似度,提高检索结果准确性。
附图说明
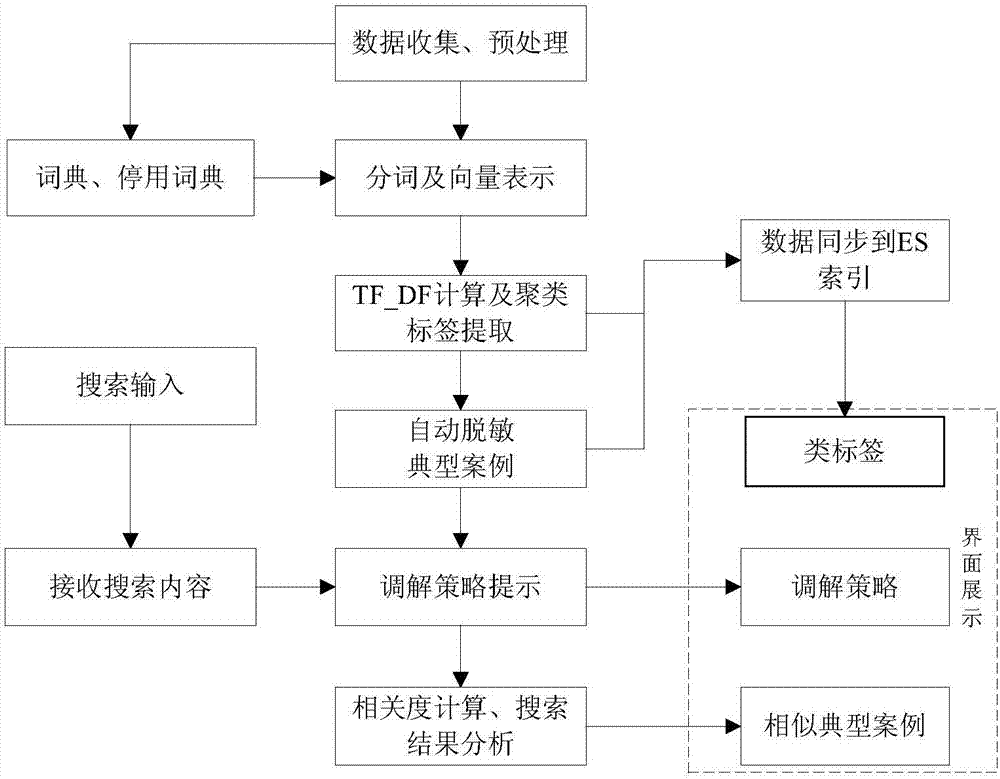
图1是矛盾调解案例搜索引擎流程图。
图2是部分矛盾调解词典mediate.txt的示意图。
图3是矛盾调解部分停用词典stopword.txt的示意图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图3,一种人民矛盾调解案例搜索和调解策略推荐方法,包括以下步骤:
步骤1:数据收集、预处理
收集人民调解案例信息,存储在数据库中,需要包含的字段包括:纠纷详情、调解结果、调解详情、调解时间、结束时间、调解人、所属地区、调解机构、评价等字段,其中纠纷详情、调解详情和评价是文本数据(非结构化数据),其他字段均为结构化数据。
对收集到的数据进行预处理,确保调解结果、调解详情字段不为空,且调解案由不能过于简单;将重复数据删除。
步骤2:分词及向量表示
文本数据是非结构化数据,计算机无法直接分析处理,需要将文本切分为单词并用结构化数据表示,方便计算机进行后续处理。英语可按照空格分词,汉语没有明确的词语分隔符,分词难度较大,一般分词时会借助辅助词典来提高分词的准确性。
本发明创建矛盾调解专业领域词典mediate.txt,将容易分词错误的词,尤其是矛盾调解专业领域词汇,例如:“xx村委会”会被切分为“xx村/委会”,实际上是“xx/村委会”,根据调解案例数据将“村委会”等无法正确切分的词,加入矛盾调解专业领域词典mediate.txt;另外汉语中还存在一些无意义的词,如“的”、“啊”等,矛盾调解专业领域中还有甲方、乙方等,这些词不仅没有包含信息,还对后续分析造成一定的干扰,将这些无意义、区分度不高的词加入停用词典stopword.txt,分词时直接将停用词去掉不作分析。
根据词典mediate.txt和停用词典stopword.txt将文本字段进行分词,将文本数据表示为向量的形式,方便分析处理。
步骤3:tf_cdf特征聚类
矛盾调解中“案件详情”只有几个大类划分,没有详细的类别区分,所有数据混杂在一起,给分析和搜索等带来不便,并且没有训练数据,要提取类标签只能通过聚类的方式进行。步骤2中已经将“案件详情”进行分词,并用向量表示,但是文本数据维数较大特征不明显,还需要进行特征提取,最后采用机器学习算法进行聚类获得类标签。
本发明采用tf_cdf计算文本单词权重,不仅考虑单词的词频和文档频率,还综合考虑单词类别频率,计算结果比常用的tf_idf特征提取算法更可靠。并且传统的基于信息熵,互信息等的文本特征提取常用于已知文本类别标签,或有一部分训练数据,进行分类或标签提取。本发明中矛盾调解案例无详细类别信息,从聚类结果中获取单词tf_cdf值。
对矛盾调解中“案件详情”字段进行特征聚类步骤如下所示:
(3.1)初始值确定
人民矛盾调解“案例详情”可聚为k类,共n条矛盾案例,构成语料库d={d1,d2,....,dn}。这里语料库是指所有案例中的“案件详情”字段信息的集合,d是组成语料库的单个“案件详情”信息。将语料库中文本进行分词,获得的不重复单词为{t1,t2,....,tn}。
①初始tf_cdf值确定
tf_cdf的值要经过迭代计算,按照计算简单、速度快的原则,给定单词初始tf_cdf的值为单词词频。某个案例i经过分词后,表示为di={w1,w2,...,wj},j=1,2,...,n,n是语料库中进过分词后的不重复单词个数,wj是单词tj在案例i中出现的次数。
②初始聚类中心确定
初始聚类中心的选取对聚类结果影响较大,可按照初始聚类中心尽可能远的原则,计算k个距离较远的初始聚类中心:c={c1,c2,...,ck},cj={c1,c2,...,cn},c是k个聚类中心,c是单个聚类中心的向量形式,为表达方便类标签全部用上标表示。
③类内离散度计算
计算各个案例与初始案例中心的误差和,确定初始聚类类内离散度e0
(3.2)“案件详情”分配到最近邻聚类
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性,更多的是方向上的差异,对绝对的数值不敏感。文本数据经过向量化之后是多维向量,采用余弦相似度作为聚类的度量标准,如公式(1)所示:
其中,
(3.3)更新tf_cdf模型
计算聚类的类内离散度e,如果e小于初始类内离散度的一半e0/2,则更新tf_cdf。如果e大于e0/2则跳过步骤(3)。分类之后,如果一个词在某一类中出现的次数较多,其他类中出现的次数较少,则说明这个词在此类中比较重要,应该相应的加大这个词的权重。如果一个词在各个类中出现的比例基本相同,则说明这个词的区分度相对较低,应该减小这个词的权重。按照公式(2)计算单词在各类中分布的熵:
其中,
对可以分为几个大类的短文本数据,将停用词去掉后,很大一部分出现频率较多的词的含义较为重要,某个单词wp的tf_cdf计算如公式(3)所示:
其中,tfp是文本i中第p个单词在文本i中的词频,dfp单词文档频率是指语料库中包含这个单词的文档数量,分母中h(wp)是单词的熵,ln()是自然对数函数,减小文档频率比重;ε是一个比较小的值,防止h(wp)为0时出现错误,综合考虑词频、文档频率和类别熵,相对于短文本准确性更高
每次迭代都更新tf_cdf值计算量相对较大,可迭代多次执行一次更新tf_cdf值,也可以设定一个聚类中心改变值的阈值,超过这个阈值时执行更新。
(3.4)更新聚类中心
将每个类中文本向量的均值作为新的聚类中心。
(3.5)重复步骤(3.2)~(3.4),直到聚类中心不再变化,则tf_cdf值不再变化,得到k个类和tf_cdf模型。
(3.6)类标签提取,聚类完成后,提取每个类别中单词tf_cdf较高的几个词作为类别标签。
步骤4:自动生成脱敏典型案例集
(4.1)自动脱敏
为保护案例中隐私信息,需要将案例中大量的人名住址等隐私信息进行特殊处理,人工处理耗费大量的时间和精力,本发明进行自动脱敏处理。采用自然语言处理技术自动识别人名和住址信息,将识别出的信息在原文中用某某代替。
(4.2)自动生成典型案例集
调解案例登记没有固定的标准,案例的质量存在较大的差别,调解人员短时间内很难找到可供才考的优秀案例,因此建立高质量的典型案例集有很大意义。但是,人工从大量的案例中抽取供学习参考的典型案例不仅耗费时间,也容易受个人因素影响。本发明通过案例评分,由机器自动生成高质量典型案例集,客观公正节省时间。步骤3将案例划分为不同类别,分别对每个类别进行案例评分,将每个类别中案例评分较高的案例作为本类的典型案例,案例评分模型创建方法如下:
①分析案例模板,将其划分为几个组成模块,例如案情简介、调解过程、调处结果说明、调解心得等模块,每个类别可能有不同划分方法,将其他案例按照对应的组成模块进行划分;
②采用自然语言处理方法分析每个案例组成模块的文本质量,例如:案例组成模块的文字长短,文本的含义,是否由重复词或句子组成等(其他能反应文本质量的指标均包含在本专利范围之内),文字质量高的案例评分较高。
qt=aql+bqp+cqs(4)
其中,a+b+c=1是各个质量评分所占的比重,ql是文字数值质量,如果未分词的文本长度,大于一定的阈值tl,则ql为1,否则ql按指数衰减;qp是文字重复比例,即文本中出现频次最高的词占文本总词数的比例,qp小于一定的阈值tp时值为1,大于一定阈值时按指数衰减,qs是经过分词后文本长度与分词前文本长度的比例,因为文本分词之后会去掉单个字的词和停用词,qs可衡量文本中是否有太多无意义词,qs越大文本质量相对较好。
③案例调解人员有首席调解人员、普通调解人员、兼职人员等,分析调解人员的调解经验,挖掘其擅长领域等,赋予各调解人员一定的评分权重;将调解员经常处理的,并且调解成功率较高的案件的案例调解人员评分权重qh∈[0,1]适当提高。
④对调解反馈信息进行情感分析,获得调解反馈权重qe;给积极反馈和消极反馈赋予评分权重,积极评分的权重较高;
⑤综合考虑根据以上几个方面,创建案例评分模型q=(αqh+βqe)qt,α是qh在案例评分中占的比重,β是qe所占的案例评分权重,α+β=1。根据案例评分模型,对案例信息进行评分,自动生成带有类别标签的典型案例集。
步骤5:生成调解策略提示
案例的调解策略是用户比较关心的内容,可以作为相似案例的调解依据,实现“同案同调”,促进人民调解服务的公正性。但是,逐个案例查看调解策略费时费力,自动展示相关案例的调解策略,能极大的节省用户时间。本发明自动生成调解策略,以步骤4中带有类别标签的典型案例作为分析数据,某一个类别按照以下步骤生成调解策略:
(5.1)获取步骤4中带有类别标签的典型案例集,提取调解策略字段。
(5.2)调解策略有一二三等条例标识,按照标识将调解策略断开,形成调解条例。
(5.3)将调解条例进行tf_cdf聚类分析,并按照步骤3中提取关键词的方法提取调解条例的关键词。
(5.4)对调解条例进行类别评分。评分依据包括类别中包含调解条例的条数、具有相同关键字的调解条例在类别中所占的比例等。
(5.5)对调解条例进行评分。评分依据包括:条例中关键词出现的频次、文本的质量等;
(5.6)将调解条例类别评分降序排序,提取评分较高的类别,在这些类别中提取分值高的调解条例,作为调解策略提示信息,保存在数据库中。
步骤6:创建索引及计算相关度
全文搜索引擎的核心包括索引创建和相关度计算,将步骤4中的典型案例数据和得到的聚类类别及步骤5中调解策略提示等同步到elasticsearch创建索引。
(6.1)创建索引
elasticsearch基于lucene开发,现在是使用最广的开源搜索引擎之一。本发明采用es对“纠纷详情”和“调处结果说明”、“调解策略推荐”创建全文索引。其中,“纠纷详情”和“调处结果说明”是原始数据中包含的字段,“调解策略推荐”是步骤5中计算获得的字段。
(6.2)相关度计算
相关度计算是计算搜索输入query和索引文本的相关度,并默认按照相关度降序排序输出,相关度计算决定界面的输出,直接影响用户体验,而准确有效的相关度计算方便用户查找。步骤3中聚类获得了类别、类标签、聚类中心及tf_cdf值,本专利采用tf_cdf权重表示文本向量,计算文本相似度。另外,输入搜索内容query,分词获得pn个单词,如果单词出现在类标签中,则相应的提高文本相关度。
步骤7:搜索结果及界面展示
服务器端进行一系列的数据挖掘计算,最终目的是在客户端展示给用户。用户输入查询内容,可获得相似典型案例、案例类别及类标签信息、调解策略推荐,为方便用户从各个角度全面了解相关案例,可以自动生成相似案例分析报告。具体内容如下所示:
(7.1)相似案例。搜索结果默认按照相关度降序排序输出,用户可手动对检索结果进行过滤和排序:显示指定类型和时间段的案例,按照时间排序等。
(7.2)案例类别及类标签。每个案例均显示对应的案例类别和类别标签,也可作为检索的过滤条件。
(7.3)调解策略推荐。根据搜索的得到的相关案例,自动生成调解策略。
(7.4)检索结果分析。案例分析不是默认显示在主界面上,用户可以在需要时点击分析按钮,获取检索结果根系报告,报告分为:时间分析、空间地域分析、调解人员分析、调处结果分析等,可以根据分析结果在结果集上进行二次搜索。
本实施例验证数据是上海市人民调解数据,过程如下:
步骤1:数据收集、预处理
收集人民调解案例信息,存储在数据库中,字段如表一所示。
表1矛盾调解字段信息
将收集到的数据进行预处理,将“mediate_circs”为空和描述简单的字段去掉;将重复纠纷详情重复的数据删除;将案例中涉及人名住房号的隐私信息用“某某”代替。对mediate_circs、mediate_explain、result_recommend字段进行全文检索,其他部分进行准确值检索。
步骤2:分词及向量表示
文本数据是非结构化数据,不能直接分析,需要将文本切分为单词。制作矛盾调解专业领域词典mediate.txt和停用词典stopword.txt。根据词典和停用词典将“纠纷详情”、“调处结果说明”文本进行分词,将文本数据表示为向量的形式,方便计算机处理。
(2.1)矛盾纠纷案件中“纠纷详情”如下所示:
甲、乙双方系上下楼邻里关系。2009年11月29日,乙方卫生间地漏堵漏水到甲方家,造成甲方家屋顶、墙面、吊橱门受损,甲方要求乙方赔偿损失,双方为赔偿问题产生分岐引起纠纷。
(2.2)词典包括单词、词频和词性(可省略),每行一个词,用空格隔开,部分矛盾调解词典mediate.txt如图2所示。
(2.3)矛盾调解部分停用词典stopword.txt如图3所示,每行一个词。
(2.4)将“纠纷详情”分词并处理
上下楼/邻里关系/卫生间/地漏/漏水/造成/屋顶/墙面/吊橱门/受损/要求/赔偿损失/赔偿问题/产生/分岐/引起纠纷
步骤3:tf_cdf计算及tf_cdf特征聚类
人民矛盾可分为4个大类别,分别为:赔偿纠纷、邻里纠纷、劳动纠纷、合同纠纷;每个大类下面又可分为若干个小类。下面对合同纠纷大类进行小类划分,特征聚类步骤如下所示:
(3.1)初始值确定
将合同纠纷大类聚类为6个小类,共有2122条矛盾数据,文本数据经过分词,去掉一些单词词频小于3的单词,形成n维单词向量。
①初始tf_cdf值确定
给定初始tf_cdf的值为单词词频值,计算简单速度快。某条数据i可表示为di={w1,w2,...,wn},n是数据维数,w是单词词频值。
②初始聚类中心确定
计算k个距离较远的初始聚类中心c={c1,c2,...,ck},cj={c1,c2,...,cn}。
(3.2)按照余弦相似度分配到最近邻聚类
文本数据经过向量化之后是多维向量,采用余弦相似度作为聚类的度量标准,按照公式(1)计算每个案例与各个类中心的距离,获得案例类别。
(3.3)更新tf_cdf
分类之后,如果一个词在某一类中出现的次数较多,其他类中出现的次数较少,则说明这个词在此类中比较重要,应该相应的加大这个词的权重。如果一个词在各个类中出现的频次基本相同,则说明这个词的区分度相对较低,应该减小这个词的权重。按照公式(2)计算单词在各类中分布的熵。单词在各个类中分布越均匀,熵越大,单词的区分度越低。
对于可以分为几个大类的短文本数据,将停用词去掉后,很大一部分出现频率较多的词含义较为重要,本发明按照公式(3)计算单词的tf_cdf值。
每次迭代都更新tf_cdf值计算量相对较大,可迭代多次执行一次tf_cdf更新,也可以设定一个聚类中心改变值的阈值,超过这个阈值时执行更新。
(3.4)更新聚类中心
更新tf_cdf后,将每个类中文本向量的均值作为新的聚类中心。
(3.5)重复步骤(3.2)~(3.4),直到聚类中心不再变化,则单词的熵不再变化即tf_cdf模型不再变化,得到k个聚类和tf_cdf模型。
(3.6)类标签提取
聚类完成后,分别提取每个类别中单词tf_cdf值前5的单词,作为类别标签。合同纠纷聚类完成后的类别和类标签如表2所示。
表2合同类聚类结果
步骤4:自动生成脱敏典型案例集,过程如下:
(4.1)自动脱敏
为保护案例隐私信息,采用自然语言处理技术识别人名和住址信息,进行自动脱敏处理,将识别出的信息在原文中用某某代替。如下所示:。
“施某某与张某某系雇佣关系。2009年9月初,施某某经某某保姆介绍所介绍到张某某家做保姆工作,并约定每月1300元人民币工资,同时吃、住均在张某某家…”;
(4.2)自动生成典型案例集
调解案例登记没有固定的标准,案例的质量存在较大的差别,调解人员短时间内很难找到可供才考的优秀案例,因此建立高质量的典型案例集有很大意义。但是,人工从大量的案例中抽取供学习参考的典型案例不仅耗费时间,也容易受个人因素影响。本发明通过案例评分,由机器自动生成高质量典型案例集,客观公正节省时间。步骤3将案例划分为不同类别,分别对每个类别进行案例评分,将每个类别中案例评分较高的案例作为本类的典型案例,案例评分模型创建方法如下:
①分析案例模板,将其划分为几个组成模块,例如案情简介、调解过程、调处结果说明、调解心得等模块,每个类别可能有不同划分方法,将其他案例按照对应的组成模块进行划分;
②采用自然语言处理方法分析每个案例组成模块的文本质量,例如:案例组成模块的文字长短,文本的含义,是否由重复词或句子组成等(其他能反应文本质量的指标均包含在本专利范围之内)。文本质量高的案例评分较高,qt较高。
③案例调解人员有首席调解人员、普通调解人员、兼职人员等,分析调解人员的调解经验,挖掘其擅长领域等,赋予各调解人员一定的评分权重,获得评分qh。
④对调解结果反馈信息进行情感分析,给积极反馈和消极反馈赋予评分权重,积极评分的权重较高,获得qe;
⑤综合考虑根据以上几个方面,创建案例评分模型。根据案例评分模型,对案例信息进行评分,自动生成带有类别标签的典型案例集。
步骤5:生成调解策略提示
案例的调解策略是用户比较关心的内容,可以作为相似案例的调解依据,实现“同案同调”,促进人民调解服务的公正性。但是,逐个案例查看调解策略费时费力,自动展示相关案例的调解策略,能极大的节省用户时间。本发明自动生成调解策略,以步骤4中带有类别标签的典型案例作为分析数据,某一个类别按照以下步骤生成调解策略:
(5.1)获取步骤4中带有类别标签的典型案例集,提取调解策略字段。
(5.2)调解策略有一二三等条例标识,按照标识将调解策略断开,形成调解条例。
(5.3)将调解条例进行tf_cdf进行聚类分析,并按照步骤3提取调解条例的关键词。
(5.4)对调解条例进行类别评分。评分依据包括类别中包含调解条例的条数、具有相同关键字的调解条例在类别中所占的比例等。
(5.5)对调解条例进行评分。评分依据包括:条例中关键词出现的频次、文本的质量等。
(5.6)将调解条例类别评分降序排序,提取评分较高的类别,在这些类别中提取分值高的调解条例,作为调解策略提示信息,保存在数据库中。
步骤6:创建索引及计算相关度
全文搜索引擎的核心包括索引创建和相关度计算,将步骤4中的典型案例数据和得到的聚类类别及步骤5中调解策略提示等同步到elasticsearch创建索引。
(6.1)创建索引
elasticsearch基于lucene开发,现在是使用最广的开源搜索引擎之一。本发明采用es对“纠纷详情”和“调处结果说明”、“调解策略推荐”创建全文索引。其中,“纠纷详情”和“调处结果说明”是原始数据中包含的字段,“调解策略推荐”是步骤5中计算获得的字段。
(6.2)相关度计算
相关度计算是计算搜索输入query和索引文本的相关度,并按照相关度降序排序输出,相关度计算决定界面的输出,直接影响用户体验,而准确有效的相关度计算方便用户查找。步骤3中聚类获得了类别、类标签、tf_cdf值,本专利计算相关度。
步骤7:搜索结果集界面展示
服务器端进行一系列的数据挖掘计算,最终目的是在客户端展示给用户。用户输入查询内容,可获得相似典型案例、案例类别及类标签信息、调解策略推荐,为方便用户从各个角度全面了解相关案例,可以自动生成相似案例分析报告。具体内容如下所示:
(7.1)相似案例。搜索结果默认按照相关度降序排序输出,用户可手动对检索结果进行过滤和排序:显示指定类型和时间段的案例,按照时间排序等。
(7.2)案例类别及类标签。每个案例均显示对应的案例类别和类别标签,也可作为检索的过滤条件。
(7.3)调解策略推荐。根据搜索的得到的相关案例,自动生成调解策略。
(7.4)检索结果分析。案例分析不是默认显示在主界面上,用户可以在需要时点击分析按钮,获取检索结果根系报告,报告分为:时间分析、空间地域分析、调解人员分析、调处结果分析等,可以根据分析结果在结果集上进行二次搜索。
- 还没有人留言评论。精彩留言会获得点赞!