用于确定值是否在范围内的指令的装置和方法与流程
本申请是国际申请日为2011年12月23日、中国国家阶段申请号为201180075756.7、题为“用于确定值是否在范围内的指令的装置和方法”的发明专利申请的分案申请。
本发明一般涉及计算科学,更具体地涉及确定值是否在范围内的指令的装置和方法。
背景技术:
图1示出了在半导体芯片上用逻辑电路实现的处理核100的高级图。该处理核包括流水线101。该流水线由各自被设计成在完全执行程序代码指令所需的多步骤过程中执行特定步骤的多个级组成。这些级通常至少包括:1)指令取出和解码;2)数据取出;3)执行;4)写回。执行级对由在先前级(例如在上述步骤1))中所取出和解码的指令所标识并在另一先前级(例如在上述步骤2))中被取出的数据执行由在先前级(例如在上述步骤1))中取出和解码的指令所标识的特定操作。被操作的数据通常是从(通用)寄存器存储空间102中取出的。在该操作完成时所创建的新数据通常也被“写回”寄存器存储空间(例如在上述级4))。
与执行级相关联的逻辑电路通常由多个“执行单元”或“功能单元”103_1至103_n构成,这些单元各自被设计成执行其自身的唯一操作子集(例如,第一功能单元执行整数数学操作,第二功能单元执行浮点指令,第三功能单元执行从高速缓存/存储器的加载操作和/或到高速缓存/存储器的存储操作等等)。由所有这些功能单元执行的所有操作的集合与处理核100所支持的“指令集”相对应。
计算机科学领域中广泛认可两种类型的处理器架构:“标量”和“向量”。标量处理器被设计成执行对单个数据集进行操作的指令,而向量处理器被设计成执行对多个数据集进行操作的指令。图2a和2b呈现了展示标量处理器与向量处理器之间的基本差异的比较示例。
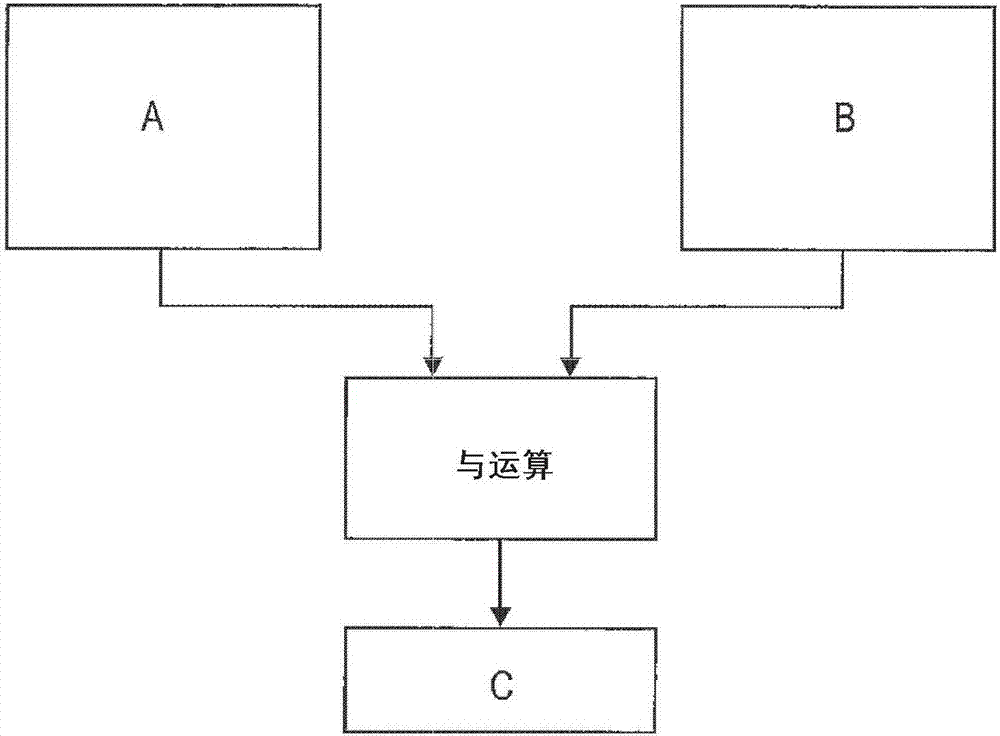
图2a示出标量and(与)指令的示例,其中单个操作数集a和b一起进行“与”运算以产生单个(或“标量”)结果c(即,ab=c)。相反,图2b示出向量and指令的示例,其中两个操作数集a/b和d/e并行地分别一起进行“与”运算以同时产生向量结果c和f(即,a.and.b=c以及d.and.e=f)。根据术语学,“向量”是具有多个“元素”的数据元素。例如,向量v=q,r,s,t,u具有五个不同的元素:q、r、s、t和u。示例性向量v的“尺寸”是5(因为它具有5个元素)。
图1还示出向量寄存器空间104的存在,该向量寄存器空间104不同于通用寄存器空间102。具体而言,通用寄存器空间102标准地用于存储标量值。这样,当各执行单元中的任一个执行标量操作时,它们标准地使用从通用寄存器存储空间102调用的操作数(并将结果写回通用寄存器存储空间102)。相反,当各执行单元中的任一个执行向量操作时,它们标准地使用从向量寄存器空间107调用的操作数(并将结果写回向量寄存器空间107)。可类似地分配存储器的不同区域以存储标量值和向量值。
还应注意,存在位于功能单元103_1到103_n的相应输入处的掩码逻辑104_1到104_n,以及位于功能单元103_1到103_n的输出处的掩码逻辑105_1到105_n。在各种实现中,实际上仅实现这些层中的一个层——不过这并非严格要求。对于采用掩码的任何指令,输入掩码逻辑104_1到104_n和/或输出掩码逻辑105_1到105_n可用于控制哪些元素被该向量指令有效地操作。在此,从掩码寄存器空间106读取掩码向量(例如与从向量寄存器存储空间107读取的输入数据向量一起),并将该掩码向量呈现给掩码逻辑104、105层中的至少一层。
在执行向量程序代码的过程中,每一向量指令无需要求全数据字。例如,一些指令的输入向量可能仅仅是8个元素,其他指令的输入向量可能是16个元素,其他指令的输入向量可能是32个元素,等等。因此,掩码层104/105用于标识完整向量数据字中的应用于特定指令的一组元素,以在多个指令之间实现不同的向量尺寸。通常,对于每一向量指令,掩码寄存器空间106中所保持的特定掩码模式被该指令调出,从掩码寄存器空间中被取出并且被提供给掩码层104/105中的任一者或两者,以“启用”针对该特定向量操作的正确元素集合。
图3a和3b涉及用于将所产生的候选值保持在范围s内的已知方法。软件需要产生在有限范围内的值(诸如0至255、或1至1000、或-3.1415至3.1415)是常见的。候选值(例如算法产生的值)落在该范围以外也是常见的。根据一种方法,如在图3a中观察到的,在301产生新的候选值,并在302条件测试检测以查明该新的候选值是否超出范围。一旦检测到超出范围的值,后续程序流就将该超出范围的值“拉回范围之中”。简而言之,在303针对该超出范围的值产生在该范围以内的新的“替换”值。
根据一种方法,通过将该超出范围的值的“超出量(excess)”与该范围的低端相加来计算该新的替换值。即,根据c’=(((c–a)%s)+a)从原始超出范围的候选c计算新的候选值c’,其中s是该范围的尺寸,a是该范围的起始,并且%是求模函数。求模函数%对c与该范围的起始相距多远(c-a)作除法,并给出该除法操作的余数作为结果。例如,如果该范围是从0到256且c=300,则(c–a)%s=(300–0)%256=44。因此,新的替换值将被计算为44+a=44+0=44。
然而,求模函数实现起来代价很高,并且通常是比较慢的操作。
因此,已经采取了替代的手段。如在图3b中观察到,一个特定的方法简化了新的替换候选的计算,在下一个产生的候选是前一值的一定小增量的情况下避免了使用求模函数。例如,考虑一算法,该算法通过将前一值加4(例如c=254+4=258)来产生新的候选值。在增加量小于范围尺寸s的情况下,更简单的方法是首先在311、312计算新的候选值(通过将前一值增加少量)及其替换值(在新的候选值太大的情况下)。然后在313执行条件测试。如果该测试指示新的候选值在该范围内,则在314接受预先计算的新候选值。如果该测试指示新的候选值在该范围以外,则在315接受预先计算的替换候选。在该方法的特定版本中,将预先计算的替换值计算为c’=c–s。这基本上使超出范围的值的超出量“绕回”在该范围的起始附近。例如,如果c=258且s=254,则c’=4。显然,步骤311、312、313、314/315消耗了多个指令的执行。
附图说明
本发明是通过示例说明的,而不仅局限于各个附图的图示,在附图中,类似的参考标号表示类似的元件,其中:
图1示出指令执行流水线;
图2a和2b将标量处理与向量处理进行比较;
图3a和3b涉及在确定值是否在范围内时遇到的传统低效率;
图4示出由用于确定指令是否在范围内的指令执行的方法;
图5示出支持图4的指令的执行单元的逻辑设计;
图6a例示了示例性avx指令格式;
图6b示出来自图6a的哪些字段构成完整操作码字段和基础操作字段;
图6c示出来自图6a的哪些字段构成寄存器索引字段;
图7a-7b是示出根据本发明的实施例的通用向量友好指令格式及其指令模板的框图;
图8是示出根据本发明的实施例的示例性专用向量友好指令格式的框图;
图9是根据本发明的一个实施例的寄存器架构的框图;
图10a是示出根据本发明的实施例的示例性有序流水线以及示例性寄存器重命名的无序发布/执行流水线两者的框图;
图10b是示出根据本发明的各实施例的要包括在处理器中的有序架构核的示例性实施例和示例性的寄存器重命名的无序发布/执行架构核的框图;
图11a-b示出了更具体的示例性有序核架构的框图,该核将是芯片中的若干逻辑块之一(包括相同类型和/或不同类型的其他核);
图12是根据本发明的实施例的可具有超过一个的核、可具有集成的存储器控制器、并且可具有集成图形的处理器的框图;
图13是根据本发明的实施例的示例性系统的框图;
图14是根据本发明的实施例的第一更具体的示例性系统的框图;
图15是根据本发明的实施例的第二更具体的示例性系统的框图;
图16是根据本发明的实施例的soc的框图;
图17是根据本发明的实施例的对比使用软件指令变换器将源指令集中的二进制指令变换成目标指令集中的二进制指令的框图。
具体实施方式
描述
图4涉及利用特殊指令的改进方法,如果c在范围s以内,则该特殊指令返回c,或如果c不在范围s以内,则该指令返回c-s。因此,该指令有效地接受c和s作为输入值,并提供结果,该结果是图3b的步骤312、313和314/315的流程最终提供的结果。然而,注意,不需要通过将前一值增加小增量(虽然可以这样)来确定新的候选c。
如图4的流程中观察到的,将候选值c和范围s提供给该指令作为输入操作数401。然后该指令计算c-s402,并在结果r中返回:a)c,如果c在范围s以内(404);或b)“绕回值”,等于c-s,如果c超出了范围s(405)。在实施例中,实现该指令以使得假定该范围的起始(a)为零。在另一实施例中,c不能等于或超过2s。
在403根据c-s计算的符号来确定c是否在范围s以外。即,如果c-s为负,则c在范围s以内并且r=c。相反,如果c-s为正,则c在范围s以外并且r=c-s。取决于该实现,重新将s视为类似于表中的条目的数量,s可以是表示范围的尺寸或范围的最大值的值。
作为应用该新指令的示例,参考图4的插图450,如果范围s被视为表451中的条目的数量,并且c对应于指向该表中的条目之一的索引,则在范围s以内的输入候选值c对应于该表中的有效条目。超出范围s的c值在技术上对应于该表中不存在的条目。经改进的指令本质上通过使超过量“绕回”在该范围的起始附近并将指向的任何条目给出为结果来处理该情况。例如,如果s具有0至256的范围且c=259,则给出的结果是c–s=259–256=3。因此,使超过量3绕回在该范围的起始附近,并且在绕回之后将被指向的条目给出作为答案。
在多种递归或循环中,以这种方式处理超出范围v可实际上产生用于接下来的递归或循环的适当值。
在又一实施例中,该指令还产生位掩码。在此,该位掩码对应于第二结果,该第二结果在结果中针对r的每个单元设置一位。换言之,在位掩码结果中设置了r个位。例如,如果底层硬件支持512位操作数并且s是512,则结果r将是0与512之间的任何值。因此,针对r的每个可能的值预留位位置。因此,例如,如果r=75,则在位掩码中将75个位设置为1,同时余下位将被设置为0(相反的逻辑方案也是可能的)。如果难以设计写入两个结果(r和位掩码)的指令,则可通过接着发生的指令来创建位掩码。即,第二指令可接收r作为其输入操作数,并创建上述位掩码作为其结果。
一旦通过本申请中描述的改进指令或后续指令创建该位掩码,就可将该位掩码存储在向量寄存器空间中,并将其用作后续向量指令的掩码向量。该位掩码可用于提取位流中的随机位置处的可变尺寸的位字段,这些位字段可能脱离包含该位流的固定尺寸的子范围的寄存器的末尾——这是可变长度解码(例如在视频或音频解码中)中的常见操作。例如,在从串行位流中提取可变长度位字段的过程期间,本领域普通技术人员可能具有包含512位的寄存器,其中已经使用了该寄存器的509个位。如果需要10个位,则将需要该寄存器的余下3位加上来自下一512位寄存器的另外7位。在该情况下,产生7位掩码会是有用的。图5示出支持上述指令的执行单元的逻辑设计。第一输入操作数寄存器501接受新的候选值c,并且第二输入操作数寄存器接受范围s。寄存器501、502可以是位于指令执行流水线的数据取出级的输出处或位于执行单元的输入处的通用寄存器存储空间中的寄存器。
在实施例中,c和s被呈现为标量值。差逻辑502计算c+(-s)。差逻辑503产生符号位504,该符号位504指示c+(-s)操作的结果是正还是负。如果是负,则将输入操作数寄存器501中的值呈现为结果寄存器505中的结果,或如果是正,则将c+(-s)的值呈现为结果寄存器505中的结果。可选地,编码逻辑可耦合至结果寄存器以如上所述地创建位掩码。将位掩码存储在位掩码结果寄存器506中。寄存器505可以在通用寄存器空间中或位于执行单元的输出处。寄存器506可以是掩码寄存器空间中或位于执行单元的输出处的寄存器。
在替代实施例中,去掉了假定该范围从零开始的约束,替代地,假定该范围从a值开始,并且通过第三输入操作数寄存器(未在图5中示出)提供a。在该情况下,如果c大于s+a,则提供结果c–(s+a)。否则,提供结果c。
在另一实施例中,该指令被设计成执行图3a的步骤311。在该实现中,该指令接收第一、第二和第三操作数。第一操作数对应于“前一值”,而第二输入操作数对应于增量。第三输入操作数对应于范围。在此,再次采用了三输入操作数寄存器。该指令通过将增量与前一值相加来计算新的候选值。然后过程流程如上针对该指令的更早描述的实现方式所述那样继续。
在另一实现中,实现该指令的逻辑电路包括用于为后续条件分支设置状态标志的附加电路。例如,这可用于作为特殊情况来处理绕回的跳转代码。换言之,在一种实现中,该指令还被设计成在认为候选值超出范围时设置条件标志。因此,该指令可产生(例如,通过清除状态标志)针对被请求的所有位的正确定位的掩码(如果在范围内或无绕回)或仅产生(例如通过设置状态标志)绕回位(其中前一寄存器的余下位隐含地全被占据,并且可能已经具有来自先前迭代的掩码)。
还可构造包含图5的电路的n个实例的阵列的向量版本,使得能够并行地执行该指令的n个操作。写掩码电路可遵循该阵列以根据接收到的写掩码(例如来自另一输入寄存器)来掩码该阵列的结果。
示例性指令格式
本文中所描述的指令的实施例可以不同的格式体现。例如,本文描述的指令可体现为vex、通用向量友好或其它格式。以下讨论vex和通用向量友好格式的细节。另外,在下文中详述示例性系统、架构、以及流水线。指令的实施例可在这些系统、架构、以及流水线上执行,但是不限于详述的系统、架构、以及流水线。
vex指令格式
vex编码允许指令具有两个以上操作数,并且允许simd向量寄存器比128位长。vex前缀的使用提供了三个操作数(或者更多)句法。例如,先前的两操作数指令执行改写源操作数的操作(诸如a=a+b)。vex前缀的使用使操作数执行非破坏性操作,诸如a=b+c。
图6a示出示例性avx指令格式,包括vex前缀602、实操作码字段630、modr/m字节640、sib字节650、位移字段662以及imm8672。图6b示出来自图6a的哪些字段构成完整操作码字段674和基础操作字段642。图6c示出来自图6a的哪些字段构成寄存器索引字段644。
vex前缀(字节0-2)602以三字节形式进行编码。第一字节是格式字段640(vex字节0,位[7:0]),该格式字段640包含明确的c4字节值(用于区分c4指令格式的唯一值)。第二-第三字节(vex字节1-2)包括提供专用能力的多个位字段。具体地,rex字段605(vex字节1,位[7-5])由vex.r位字段(vex字节1,位[7]–r)、vex.x位字段(vex字节1,位[6]–x)以及vex.b位字段(vex字节1,位[5]–b)组成。这些指令的其他字段对如在本领域中已知的寄存器索引的较低三个位(rrr、xxx以及bbb)进行编码,由此可通过增加vex.r、vex.x以及vex.b来形成rrrr、xxxx以及bbbb。操作码映射字段615(vex字节1,位[4:0]–mmmmm)包括对隐含的前导操作码字节进行编码的内容。w字段664(vex字节2,位[7]–w)由记号vex.w表示,并且提供取决于该指令而不同的功能。vex.vvvv620(vex字节2,位[6:3]-vvvv)的作用可包括如下:1)vex.vvvv编码第一源寄存器操作数且对具有两个或两个以上源操作数的指令有效,第一源寄存器操作数以反转(1补码)形式被指定;2)vex.vvvv编码目的地寄存器操作数,目的地寄存器操作数针对特定向量位移以多个1补码的形式被指定;或者3)vex.vvvv不对任何操作数进行编码,保留该字段,并且应当包含1111b。如果vex.l668尺寸字段(vex字节2,位[2]-l)=0,则它指示128位向量;如果vex.l=1,则它指示256位向量。前缀编码字段625(vex字节2,位[1:0]-pp)提供了用于基础操作字段的附加位。
实操作码字段630(字节3)还被称为操作码字节。操作码的一部分在该字段中指定。
modr/m字段640(字节4)包括mod字段642(位[7-6])、reg字段644(位[5-3])、以及r/m字段646(位[2-0])。reg字段644的作用可包括如下:对目的地寄存器操作数或源寄存器操作数(rrrr中的rrr)进行编码;或者被视为操作码扩展且不用于对任何指令操作数进行编码。r/m字段646的作用可包括如下:对引用存储器地址的指令操作数进行编码;或者对目的地寄存器操作数或源寄存器操作数进行编码。
比例、索引、基址(sib)-比例字段650(字节5)的内容包括用于存储器地址生成的ss652(位[7-6])。先前已经针对寄存器索引xxxx和bbbb参考了sib.xxx654(位[5-3])和sib.bbb656(位[2-0])的内容。
位移字段662和立即数字段(imm8)672包含地址数据。
通用向量友好指令格式
向量友好指令格式是适于向量指令(例如,存在专用于向量操作的特定字段)的指令格式。尽管描述了其中通过向量友好指令格式支持向量和标量运算两者的实施例,但是替换实施例仅使用通过向量友好指令格式的向量运算。
图7a-7b是示出根据本发明的实施例的通用向量友好指令格式及其指令模板的框图。图7a是示出根据本发明的实施例的通用向量友好指令格式及其a类指令模板的框图;而图7b是示出根据本发明的实施例的通用向量友好指令格式及其b类指令模板的框图。具体地,针对通用向量友好指令格式700定义a类和b类指令模板,两者包括无存储器访问705的指令模板和存储器访问720的指令模板。在向量友好指令格式的上下文中的术语“通用”指不束缚于任何专用指令集的指令格式。
尽管将描述其中向量友好指令格式支持64字节向量操作数长度(或尺寸)与32位(4字节)或64位(8字节)数据元素宽度(或尺寸)(并且由此,64字节向量由16双字尺寸的元素或者替换地8四字尺寸的元素组成)、64字节向量操作数长度(或尺寸)与16位(2字节)或8位(1字节)数据元素宽度(或尺寸)、32字节向量操作数长度(或尺寸)与32位(4字节)、64位(8字节)、16位(2字节)、或8位(1字节)数据元素宽度(或尺寸)、以及16字节向量操作数长度(或尺寸)与32位(4字节)、64位(8字节)、16位(2字节)、或8位(1字节)数据元素宽度(或尺寸)的本发明的实施例,但是替换实施例可支持更大、更小、和/或不同的向量操作数尺寸(例如,256字节向量操作数)与更大、更小或不同的数据元素宽度(例如,128位(16字节)数据元素宽度)。
图7a中的a类指令模板包括:1)在无存储器访问705的指令模板内,示出无存储器访问的完全舍入(round)控制型操作710的指令模板、以及无存储器访问的数据变换型操作715的指令模板;以及2)在存储器访问720的指令模板内,示出存储器访问的时效性725的指令模板和存储器访问的非时效性730的指令模板。图7b中的b类指令模板包括:1)在无存储器访问705的指令模板内,示出无存储器访问的写掩码控制的部分舍入控制型操作712的指令模板以及无存储器访问的写掩码控制的vsize型操作717的指令模板;以及2)在存储器访问720的指令模板内,示出存储器访问的写掩码控制727的指令模板。
通用向量友好指令格式700包括以下列出的按照在图7a-7b中示出的顺序的如下字段。结合以上图4和5的讨论,在实施例中,参考下文在图7a-b和8中提供的格式细节,可利用非存储器访问指令类型705或存储器访问指令类型720。可在以下描述的寄存器地址字段744中标识输入向量操作数和目的地的地址。在另一个实施例中,在写掩码字段770中指定写掩码。
格式字段740-该字段中的特定值(指令格式标识符值)唯一地标识向量友好指令格式,并且由此标识指令在指令流中以向量友好指令格式出现。由此,该字段对于仅具有通用向量友好指令格式的指令集是不需要的,在这个意义上该字段是任选的。
基础操作字段742-其内容区分不同的基础操作。
寄存器索引字段744-其内容直接或者通过地址生成来指定源或目的地操作数在寄存器中或者在存储器中的位置。这些字段包括足够数量的位以从pxq(例如,32x512、16x128、32x1024、64x1024)个寄存器组选择n个寄存器。尽管在一个实施例中n可高达三个源和一个目的地寄存器,但是替换实施例可支持更多或更少的源和目的地寄存器(例如,可支持高达两个源,其中这些源中的一个源还用作目的地,可支持高达三个源,其中这些源中的一个源还用作目的地,可支持高达两个源和一个目的地)。
修饰符(modifier)字段746-其内容将指定存储器访问的以通用向量指令格式出现的指令与不指定存储器访问的以通用向量指令格式出现的指令区分开;即在无存储器访问705的指令模板与存储器访问720的指令模板之间进行区分。存储器访问操作读取和/或写入到存储器层次(在一些情况下,使用寄存器中的值来指定源和/或目的地地址),而非存储器访问操作不这样(例如,源和/或目的地是寄存器)。尽管在一个实施例中,该字段还在三种不同的方式之间选择以执行存储器地址计算,但是替换实施例可支持更多、更少或不同的方式来执行存储器地址计算。
扩充操作字段750-其内容区分除基础操作以外还要执行各种不同操作中的哪一个操作。该字段是针对上下文的。在本发明的一个实施例中,该字段被分成类字段768、α字段752、以及β字段754。扩充操作字段750允许在单一指令而非2、3或4个指令中执行多组共同的操作。
比例字段760-其内容允许用于存储器地址生成(例如,用于使用2比例*索引+基址的地址生成)的索引字段的内容的按比例缩放。
位移字段762a-其内容用作存储器地址生成的一部分(例如,用于使用2比例*索引+基址+位移的地址生成)。
位移因数字段762b(注意,位移字段762a直接在位移因数字段762b上的并置指示使用一个或另一个)-其内容用作地址生成的一部分,它指定通过存储器访问的尺寸(n)按比例缩放的位移因数,其中n是存储器访问中的字节数量(例如,用于使用2倍比例*索引+基址+按比例缩放的位移的地址生成)。忽略冗余的低阶位,并且因此将位移因数字段的内容乘以存储器操作数总尺寸(n)以生成在计算有效地址中使用的最终位移。n的值由处理器硬件在运行时基于完整操作码字段774(稍后在本文中描述)和数据操纵字段754c确定。位移字段762a和位移因数字段762b可以不用于无存储器访问705的指令模板和/或不同的实施例可实现两者中的仅一个或不实现两者中的任一个,在这个意义上位移字段762a和位移因数字段762b是任选的。
数据元素宽度字段764-其内容区分使用多个数据元素宽度中的哪一个(在一些实施例中用于所有指令,在其他实施例中只用于一些指令)。如果支持仅一个数据元素宽度和/或使用操作码的某一方面来支持数据元素宽度,则该字段是不需要的,在这个意义上该字段是任选的。
写掩码字段770-其内容在每一数据元素位置的基础上控制目的地向量操作数中的数据元素位置是否反映基础操作和扩充操作的结果。a类指令模板支持合并-写掩码操作,而b类指令模板支持合并写掩码操作和归零写掩码操作两者。当合并时,向量掩码允许在执行任何操作期间保护目的地中的任何元素集免于更新(由基础操作和扩充操作指定);在另一实施例中,保持其中对应掩码位具有0的目的地的每一元素的旧值。相反,当归零时,向量掩码允许在执行任何操作期间使目的地中的任何元素集归零(由基础操作和扩充操作指定);在一个实施例中,目的地的元素在对应掩码位具有0值时被设为0。该功能的子集是控制执行的操作的向量长度的能力(即,从第一个到最后一个要修改的元素的跨度),然而,被修改的元素不一定要是连续的。由此,写掩码字段770允许部分向量操作,这包括加载、存储、算术、逻辑等。尽管描述了其中写掩码字段770的内容选择了多个写掩码寄存器中的包含要使用的写掩码的一个写掩码寄存器(并且由此写掩码字段770的内容间接地标识了要执行的掩码操作)的本发明的实施例,但是替换实施例相反或另外允许掩码写字段770的内容直接地指定要执行的掩码操作。
立即数字段772-其内容允许对立即数的指定。该字段在实现不支持立即数的通用向量友好格式中不存在且在不使用立即数的指令中不存在,在这个意义上该字段是任选的。
类字段768-其内容在不同类的指令之间进行区分。参考图7a-b,该字段的内容在a类和b类指令之间进行选择。在图7a-b中,圆角方形用于指示专用值存在于字段中(例如,在图7a-b中分别用于类字段768的a类768a和b类768b)。
a类指令模板
在a类非存储器访问705的指令模板的情况下,α字段752被解释为其内容区分要执行不同扩充操作类型中的哪一种(例如,针对无存储器访问的舍入型操作710和无存储器访问的数据变换型操作715的指令模板分别指定舍入752a.1和数据变换752a.2)的rs字段752a,而β字段754区分要执行指定类型的操作中的哪一种。在无存储器访问705指令模板中,比例字段760、位移字段762a以及位移比例字段762b不存在。
无存储器访问的指令模板-完全舍入控制型操作
在无存储器访问的完全舍入控制型操作710的指令模板中,β字段754被解释为其内容提供静态舍入的舍入控制字段754a。尽管在本发明的所述实施例中舍入控制字段754a包括抑制所有浮点异常(sae)字段756和舍入操作控制字段758,但是替换实施例可支持、可将这些概念两者都编码成相同的字段或者只有这些概念/字段中的一个或另一个(例如,可仅有舍入操作控制字段758)。
sae字段756-其内容区分是否停用异常事件报告;当sae字段756的内容指示启用抑制时,给定指令不报告任何种类的浮点异常标志且不唤起任何浮点异常处理程序。
舍入操作控制字段758-其内容区分执行一组舍入操作中的哪一个(例如,向上舍入、向下舍入、向零舍入、以及就近舍入)。由此,舍入操作控制字段758允许在每一指令的基础上改变舍入模式。在其中处理器包括用于指定舍入模式的控制寄存器的本发明的一个实施例中,舍入操作控制字段750的内容优先于该寄存器值。
无存储器访问的指令模板-数据变换型操作
在无存储器访问的数据变换型操作715的指令模板中,β字段754被解释为数据变换字段754b,其内容区分要执行多个数据变换中的哪一个(例如,无数据变换、混合、广播)。
在a类存储器访问720的指令模板的情况下,α字段752被解释为驱逐提示字段752b,其内容区分要使用驱逐提示中的哪一个(在图7a中,对于存储器访问时效性725的指令模板和存储器访问非时效性730的指令模板分别指定时效性的752b.1和非时效性的752b.2),而β字段754被解释为数据操纵字段754c,其内容区分要执行多个数据操纵操作(也称为基元(primitive))中的哪一个(例如,无操纵、广播、源的向上转换、以及目的地的向下转换)。存储器访问720的指令模板包括比例字段760、以及任选的位移字段762a或位移比例字段762b。
向量存储器指令使用转换支持来执行来自存储器的向量加载并将向量存储到存储器。如同寻常的向量指令,向量存储器指令以数据元素式的方式与存储器来回传输数据,其中实际传输的元素由选为写掩码的向量掩码的内容规定。
存储器访问的指令模板-时效性的
时效性的数据是可能足够快地重新使用以从高速缓存受益的数据。然而,这是提示,且不同的处理器可以不同的方式实现它,包括完全忽略该提示。
存储器访问的指令模板-非时效性的
非时效性的数据是不可能足够快地重新使用以从第一级高速缓存中的高速缓存受益且应当被给予驱逐优先级的数据。然而,这是提示,且不同的处理器可以不同的方式实现它,包括完全忽略该提示。
b类指令模板
在b类指令模板的情况下,α字段752被解释为写掩码控制(z)字段752c,其内容区分由写掩码字段770控制的写掩码操作应当是合并还是归零。
在b类非存储器访问705的指令模板的情况下,β字段754的一部分被解释为rl字段757a,其内容区分要执行不同扩充操作类型中的哪一种(例如,针对无存储器访问的写掩码控制部分舍入控制类型操作712的指令模板和无存储器访问的写掩码控制vsize型操作717的指令模板分别指定舍入757a.1和向量长度(vsize)757a.2),而β字段754的其余部分区分要执行指定类型的操作中的哪一种。在无存储器访问705指令模板中,比例字段760、位移字段762a以及位移比例字段762b不存在。
在无存储器访问的写掩码控制的部分舍入控制型操作710的指令模板中,β字段754的其余部分被解释为舍入操作字段759a,并且停用异常事件报告(给定指令不报告任何种类的浮点异常标志且不唤起任何浮点异常处理程序)。
舍入操作控制字段759a-只作为舍入操作控制字段758,其内容区分执行一组舍入操作中的哪一个(例如,向上舍入、向下舍入、向零舍入、以及就近舍入)。由此,舍入操作控制字段759a允许在每一指令的基础上改变舍入模式。在其中处理器包括用于指定舍入模式的控制寄存器的本发明的一个实施例中,舍入操作控制字段750的内容优先于该寄存器值。
在无存储器访问的写掩码控制vsize型操作717的指令模板中,β字段754的其余部分被解释为向量长度字段759b,其内容区分要执行多个数据向量长度中的哪一个(例如,128字节、256字节、或512字节)。
在b类存储器访问720的指令模板的情况下,β字段754的一部分被解释为广播字段757b,其内容区分是否要执行广播型数据操纵操作,而β字段754的其余部分被解释为向量长度字段759b。存储器访问720的指令模板包括比例字段760、以及任选的位移字段762a或位移比例字段762b。
针对通用向量友好指令格式700,示出完整操作码字段774包括格式字段740、基础操作字段742以及数据元素宽度字段764。尽管示出了其中完整操作码字段774包括所有这些字段的一个实施例,但是在不支持所有这些字段的实施例中,完整操作码字段774包括少于所有的这些字段。完整操作码字段774提供操作码(opcode)。
扩充操作字段750、数据元素宽度字段764以及写掩码字段770允许在每一指令的基础上以通用向量友好指令格式指定这些特征。
写掩码字段和数据元素宽度字段的组合创建各种类型的指令,因为这些指令允许基于不同的数据元素宽度应用该掩码。
在a类和b类内出现的各种指令模板在不同的情形下是有益的。在本发明的一些实施例中,不同处理器或者处理器内的不同核可支持仅a类、仅b类、或者可支持两类。举例而言,期望用于通用计算的高性能通用无序核可仅支持b类,期望主要用于图形和/或科学(吞吐量)计算的核可仅支持a类,并且期望用于两者的核可支持两者(当然,具有来自两类的模板和指令的一些混合、但是并非来自两类的所有模板和指令的核在本发明的范围内)。同样,单一处理器可包括多个核,所有核支持相同的类或者其中不同的核支持不同的类。举例而言,在具有单独的图形和通用核的处理器中,图形核中的期望主要用于图形和/或科学计算的一个核可仅支持a类,而通用核中的一个或多个可以是具有期望用于通用计算的仅支持b类的无序执行和寄存器重命名的高性能通用核。不具有单独的图形核的另一处理器可包括既支持a类又支持b类的一个或多个通用有序或无序核。当然,在本发明的不同实施例中,来自一类的特征也可在其他类中实现。可使以高级语言撰写的程序成为(例如,及时编译或者统计编译)各种不同的可执行形式,包括:1)仅具有用于执行的目标处理器支持的类的指令的形式;或者2)具有使用所有类的指令的不同组合而编写的替换例程且具有选择这些例程以基于由当前正在执行代码的处理器支持的指令而执行的控制流代码的形式。
示例性专用向量友好指令格式
图8是示出根据本发明的实施例的示例性专用向量友好指令格式的框图。图8示出专用向量友好指令格式800,其指定位置、尺寸、解释和字段的次序、以及那些字段中的一些字段的值,在这个意义上向量友好指令格式800是专用的。专用向量友好指令格式800可用于扩展x86指令集,并且由此一些字段类似于在现有x86指令集及其扩展(例如,avx)中使用的那些字段或与之相同。该格式保持与具有扩展的现有x86指令集的前缀编码字段、实操作码字节字段、modr/m字段、sib字段、位移字段、以及立即数字段一致。示出来自图7的字段,来自图8的字段映射到来自图7的字段。
应当理解,虽然出于说明的目的在通用向量友好指令格式700的上下文中参考专用向量友好指令格式800描述了本发明的实施例,但是本发明不限于专用向量友好指令格式800,除非另有声明。例如,通用向量友好指令格式700构想各种字段的各种可能的尺寸,而专用向量友好指令格式800被示为具有特定尺寸的字段。作为具体示例,尽管在专用向量友好指令格式800中数据元素宽度字段764被示为一位字段,但是本发明不限于此(即,通用向量友好指令格式700构想数据元素宽度字段764的其他尺寸)。
通用向量友好指令格式700包括以下列出的按照图8a中示出的顺序的如下字段。
evex前缀(字节0-3)802-以四字节形式进行编码。
格式字段740(evex字节0,位[7:0])-第一字节(evex字节0)是格式字段740,并且它包含0x62(在本发明的一个实施例中用于区分向量友好指令格式的唯一值)。
第二-第四字节(evex字节1-3)包括提供专用能力的多个位字段。
rex字段805(evex字节1,位[7-5])-由evex.r位字段(evex字节1,位[7]–r)、evex.x位字段(evex字节1,位[6]–x)以及(757bex字节1,位[5]–b)组成。evex.r、evex.x和evex.b位字段提供与对应vex位字段相同的功能,并且使用1补码的形式进行编码,即zmm0被编码为1111b,zmm15被编码为0000b。这些指令的其他字段对如在本领域中已知的寄存器索引的较低三个位(rrr、xxx、以及bbb)进行编码,由此可通过增加evex.r、evex.x以及evex.b来形成rrrr、xxxx以及bbbb。
rex’字段710-这是rex’字段710的第一部分,并且是用于对扩展的32个寄存器集合的较高16个或较低16个寄存器进行编码的evex.r’位字段(evex字节1,位[4]–r’)。在本发明的一个实施例中,该位与以下指示的其他位一起以位反转的格式存储以(在公知x86的32位模式下)与实操作码字节是62的bound指令进行区分,但是在modr/m字段(在下文中描述)中不接受mod字段中的值11;本发明的替换实施例不以反转的格式存储该指示的位以及其他指示的位。值1用于对较低16个寄存器进行编码。换句话说,通过组合evex.r’、evex.r、以及来自其他字段的其他rrr来形成r’rrrr。
操作码映射字段815(evex字节1,位[3:0]–mmmm)–其内容对隐含的前导操作码字节(0f、0f38、或0f3)进行编码。
数据元素宽度字段764(evex字节2,位[7]–w)-由记号evex.w表示。evex.w用于定义数据类型(32位数据元素或64位数据元素)的粒度(尺寸)。
evex.vvvv820(evex字节2,位[6:3]-vvvv)-evex.vvvv的作用可包括如下:1)evex.vvvv对以反转(1补码)的形式指定的第一源寄存器操作数进行编码且对具有两个或两个以上源操作数的指令有效;2)evex.vvvv针对特定向量位移对以1补码的形式指定的目的地寄存器操作数进行编码;或者3)evex.vvvv不对任何操作数进行编码,保留该字段,并且应当包含1111b。由此,evex.vvvv字段820对以反转(1补码)的形式存储的第一源寄存器指定符的4个低阶位进行编码。取决于该指令,额外不同的evex位字段用于将指定符尺寸扩展到32个寄存器。
evex.u768类字段(evex字节2,位[2]-u)-如果evex.u=0,则它指示a类或evex.u0,如果evex.u=1,则它指示b类或evex.u1。
前缀编码字段825(evex字节2,位[1:0]-pp)-提供了用于基础操作字段的附加位。除了对以evex前缀格式的传统sse指令提供支持以外,这也具有压缩simd前缀的益处(evex前缀只需要2位,而不是需要字节来表达simd前缀)。在一个实施例中,为了支持使用以传统格式和以evex前缀格式的simd前缀(66h、f2h、f3h)的传统sse指令,将这些传统simd前缀编码成simd前缀编码字段;并且在运行时在提供给解码器的pla之前被扩展成传统simd前缀(因此pla可执行传统和evex格式的这些传统指令,而无需修改)。虽然较新的指令可将evex前缀编码字段的内容直接作为操作码扩展,但是为了一致性,特定实施例以类似的方式扩展,但允许由这些传统simd前缀指定不同的含义。替换实施例可重新设计pla以支持2位simd前缀编码,并且由此不需要扩展。
α字段752(evex字节3,位[7]–eh,也称为evex.eh、evex.rs、evex.rl、evex.写掩码控制、以及evex.n;也以α示出)-如先前所述,该字段是针对上下文的。
β字段754(evex字节3,位[6:4]-sss,也称为evex.s2-0、evex.r2-0、evex.rr1、evex.ll0、evex.llb;也以βββ示出)-如先前所述,该字段是针对上下文的。
rex’字段710-这是rex’字段的其余部分,并且是可用于对扩展的32个寄存器集合的较高16个或较低16个寄存器进行编码的evex.v’位字段(evex字节3,位[3]–v’)。该位以位反转的格式存储。值1用于对较低16个寄存器进行编码。换句话说,通过组合evex.v’、evex.vvvv来形成v’vvvv。
写掩码字段770(evex字节3,位[2:0]-kkk)-其内容指定写掩码寄存器中的寄存器索引,如先前所述。在本发明的一个实施例中,特定值evex.kkk=000具有暗示没有写掩码用于特定指令的特殊行为(这可以各种方式实现,包括使用硬连线到所有的写掩码或者旁路掩码硬件的硬件来实现)。
实操作码字段830(字节4)还被称为操作码字节。操作码的一部分在该字段中被指定。
modr/m字段840(字节5)包括mod字段842、reg字段844、以及r/m字段846。如先前所述的,mod字段842的内容将存储器访问和非存储器访问操作区分开。reg字段844的作用可被归结为两种情形:对目的地寄存器操作数或源寄存器操作数进行编码;或者被视为操作码扩展且不用于对任何指令操作数进行编码。r/m字段846的作用可包括如下:对引用存储器地址的指令操作数进行编码;或者对目的地寄存器操作数或源寄存器操作数进行编码。
比例、索引、基址(sib)字节(字节6)-如先前所述的,比例字段750的内容用于存储器地址生成。sib.xxx854和sib.bbb856-先前已经针对寄存器索引xxxx和bbbb提及了这些字段的内容。
位移字段762a(字节7-10)-当mod字段842包含10时,字节7-10是位移字段762a,并且它与传统32位位移(disp32)一样地工作,并且以字节粒度工作。
位移因数字段762b(字节7)-当mod字段842包含01时,字节7是位移因数字段762b。该字段的位置与传统x86指令集8位位移(disp8)的位置相同,它以字节粒度工作。由于disp8是符号扩展的,因此它仅能在-128和127字节偏移量之间寻址;在64字节高速缓存行的方面,disp8使用可被设为仅四个真正有用的值-128、-64、0和64的8位;由于常常需要更大的范围,所以使用disp32;然而,disp32需要4个字节。与disp8和disp32对比,位移因数字段762b是disp8的重新解释;当使用位移因数字段762b时,通过将位移因数字段的内容乘以存储器操作数访问的尺寸(n)来确定实际位移。该类型的位移被称为disp8*n。这减小了平均指令长度(单个字节用于位移,但具有大得多的范围)。这种压缩位移基于有效位移是存储器访问的粒度的倍数的假设,并且由此地址偏移量的冗余低阶位不需要被编码。换句话说,位移因数字段762b替代传统x86指令集8位位移。由此,位移因数字段762b以与x86指令集8位位移相同的方式(因此在modrm/sib编码规则中没有变化)进行编码,唯一的不同在于,将disp8超载至disp8*n。换句话说,在编码规则或编码长度中没有变化,而仅在通过硬件对位移值的解释中有变化(这需要按存储器操作数的尺寸按比例缩放位移量以获得字节式地址偏移量)。
立即数字段772如先前所述地操作。
完整操作码字段
图8b是示出根据本发明的实施例的构成完整操作码字段774的具有专用向量友好指令格式800的字段的框图。具体地,完整操作码字段774包括格式字段740、基础操作字段742、以及数据元素宽度(w)字段764。基础操作字段742包括前缀编码字段825、操作码映射字段815以及实操作码字段830。
寄存器索引字段
图8c是示出根据本发明的一个实施例的构成寄存器索引字段744的具有专用向量友好指令格式800的字段的框图。具体地,寄存器索引字段744包括rex字段805、rex’字段810、modr/m.reg字段844、modr/m.r/m字段846、vvvv字段820、xxx字段854以及bbb字段856。
扩充操作字段
图8d是示出根据本发明的一个实施例的构成扩充操作字段750的具有专用向量友好指令格式800的字段的框图。当类(u)字段768包含0时,它表明evex.u0(a类768a);当它包含1时,它表明evex.u1(b类768b)。当u=0且mod字段842包含11(表明无存储器访问操作)时,α字段752(evex字节3,位[7]–eh)被解释为rs字段752a。当rs字段752a包含1(舍入752a.1)时,β字段754(evex字节3,位[6:4]–sss)被解释为舍入控制字段754a。舍入控制字段754a包括一位sae字段756和两位舍入操作字段758。当rs字段752a包含0(数据变换752a.2)时,β字段754(evex字节3,位[6:4]–sss)被解释为三位数据变换字段754b。当u=0且mod字段842包含00、01或10(表明存储器访问操作)时,α字段752(evex字节3,位[7]–eh)被解释为驱逐提示(eh)字段752b且β字段754(evex字节3,位[6:4]–sss)被解释为三位数据操纵字段754c。
当u=1时,α字段752(evex字节3,位[7]–eh)被解释为写掩码控制(z)字段752c。当u=1且mod字段842包含11(表明无存储器访问操作)时,β字段754的一部分(evex字节3,位[4]–s0)被解释为rl字段757a;当它包含1(舍入757a.1)时,β字段754的其余部分(evex字节3,位[6-5]–s2-1)被解释为舍入操作字段759a,而当rl字段757a包含0(vsize757.a2)时,β字段754的其余部分(evex字节3,位[6-5]-s2-1)被解释为向量长度字段759b(evex字节3,位[6-5]–l1-0)。当u=1且mod字段842包含00、01或10(表明存储器访问操作)时,β字段754(evex字节3,位[6:4]–sss)被解释为向量长度字段759b(evex字节3,位[6-5]–l1-0)和广播字段757b(evex字节3,位[4]–b)。
示例性寄存器架构
图9是根据本发明的一个实施例的寄存器架构900的框图。在所示出的实施例中,有32个512位宽的向量寄存器910;这些寄存器被引用为zmm0到zmm31。较低的16zmm寄存器的较低阶256个位覆盖在寄存器ymm0-16上。较低的16zmm寄存器的较低阶128个位(ymm寄存器的较低阶128个位)覆盖在寄存器xmm0-15上。专用向量友好指令格式800对这些覆盖的寄存器组操作,如在以下表格中所示的。
换句话说,向量长度字段759b在最大长度与一个或多个其他较短长度之间进行选择,其中每一这种较短长度是前一长度的一半,并且不具有向量长度字段759b的指令模板对最大向量长度操作。此外,在一个实施例中,专用向量友好指令格式800的b类指令模板对打包或标量单/双精度浮点数据以及打包或标量整数数据操作。标量操作是对zmm/ymm/xmm寄存器中的最低阶数据元素位置执行的操作;取决于本实施例,较高阶数据元素位置保持与在指令之前相同或者归零。
写掩码寄存器915-在所示的实施例中,存在8个写掩码寄存器(k0至k7),每一写掩码寄存器的尺寸是64位。在替换实施例中,写掩码寄存器915的尺寸是16位。如先前所述的,在本发明的一个实施例中,向量掩码寄存器k0无法用作写掩码;当正常指示k0的编码用作写掩码时,它选择硬连线的写掩码0xffff,从而有效地停用该指令的写掩码操作。
通用寄存器925——在所示出的实施例中,有十六个64位通用寄存器,这些寄存器与现有的x86寻址模式一起使用来寻址存储器操作数。这些寄存器通过名称rax、rbx、rcx、rdx、rbp、rsi、rdi、rsp以及r8到r15来引用。
标量浮点堆栈寄存器组(x87堆栈)945,在其上面使用了别名mmx打包整数平坦寄存器组950——在所示出的实施例中,x87堆栈是用于使用x87指令集扩展来对32/64/80位浮点数据执行标量浮点运算的八元素堆栈;而使用mmx寄存器来对64位打包整数数据执行操作,以及为在mmx和xmm寄存器之间执行的某些操作保存操作数。
本发明的替换实施例可以使用较宽的或较窄的寄存器。另外,本发明的替换实施例可以使用更多、更少或不同的寄存器组和寄存器。
示例性核架构、处理器和计算机架构
处理器核可以用出于不同目的的不同方式在不同的处理器中实现。例如,这样的核的实现可以包括:1)旨在用于通用计算的通用有序核;2)预期用于通用计算的高性能通用无序核;3)旨在主要用于图形和/或科学(吞吐量)计算的专用核。不同处理器的实现可包括:1)包括旨在用于通用计算的一个或多个通用有序核和/或旨在用于通用计算的一个或多个通用无序核的cpu;以及2)包括旨在主要用于图形和/或科学(吞吐量)的一个或多个专用核的协处理器。这样的不同处理器导致不同的计算机系统架构,其可包括:1)在与cpu分开的芯片上的协处理器;2)在与cpu相同的封装中但分开的管芯上的协处理器;3)与cpu在相同管芯上的协处理器(在该情况下,这样的协处理器有时被称为诸如集成图形和/或科学(吞吐量)逻辑等专用逻辑,或被称为专用核);以及4)可以将所描述的cpu(有时被称为应用核或应用处理器)、以上描述的协处理器和附加功能包括在同一管芯上的芯片上系统。接着描述示例性核架构,随后描述示例性处理器和计算机架构。
示例性核架构
有序和无序核框图
图10a是示出根据本发明的各实施例的示例性有序流水线和示例性的寄存器重命名的无序发布/执行流水线的框图。图10b是示出根据本发明的各实施例的要包括在处理器中的有序架构核的示例性实施例和示例性的寄存器重命名的无序发布/执行架构核的框图。图10a-b中的实线框示出了有序流水线和有序核,而可选增加的虚线框示出了寄存器重命名的、无序发布/执行流水线和核。给定有序方面是无序方面的子集的情况下,将描述无序方面。
在图10a中,处理器流水线1000包括取出级1002、长度解码级1004、解码级1006、分配级1008、重命名级1010、调度(也称为分派或发布)级1012、寄存器读取/存储器读取级1014、执行级1016、写回/存储器写入级1018、异常处理级1022和提交级1024。
图10b示出了包括耦合到执行引擎单元1050的前端单元1030的处理器核1090,且执行引擎单元和前端单元两者都耦合到存储器单元1070。核1090可以是精简指令集计算(risc)核、复杂指令集计算(cisc)核、超长指令字(vliw)核或混合或替代核类型。作为又一选项,核1090可以是专用核,诸如例如网络或通信核、压缩引擎、协处理器核、通用计算图形处理器单元(gpgpu)核、或图形核等等。
前端单元1030包括耦合到指令高速缓存单元1034的分支预测单元1032,该指令高速缓存单元1034被耦合到指令转换后备缓冲器(tlb)1036,该指令转换后备缓冲器1036被耦合到指令取出单元1038,指令取出单元1038被耦合到解码单元1040。解码单元1040(或解码器)可解码指令,并生成从原始指令解码出的、或以其他方式反映原始指令的、或从原始指令导出的一个或多个微操作、微代码进入点、微指令、其他指令、或其他控制信号作为输出。解码单元1040可使用各种不同的机制来实现。合适的机制的示例包括但不限于查找表、硬件实现、可编程逻辑阵列(pla)、微代码只读存储器(rom)等。在一个实施例中,核1090包括(例如,在解码单元1040中或否则在前端单元1030内的)用于存储某些宏指令的微代码的微代码rom或其他介质。解码单元1040被耦合到执行引擎单元1050中的重命名/分配单元1052。
执行引擎单元1050包括重命名/分配器单元1052,该重命名/分配器单元1052耦合至引退单元1054和一个或多个调度器单元1056的集合。调度器单元1056表示任何数目的不同调度器,包括预留站、中央指令窗等。调度器单元1056被耦合到物理寄存器组单元1058。每个物理寄存器组单元1058表示一个或多个物理寄存器组,其中不同的物理寄存器组存储一种或多种不同的数据类型,诸如标量整数、标量浮点、打包整数、打包浮点、向量整数、向量浮点、状态(例如,作为要执行的下一指令的地址的指令指针)等。在一个实施例中,物理寄存器组单元1058包括向量寄存器单元、写掩码寄存器单元和标量寄存器单元。这些寄存器单元可以提供架构向量寄存器、向量掩码寄存器、和通用寄存器。物理寄存器组单元1058与引退单元1054重叠以示出可以用来实现寄存器重命名和无序执行的各种方式(例如,使用重新排序缓冲器和引退寄存器组;使用将来的文件、历史缓冲器和引退寄存器组;使用寄存器映射和寄存器池等等)。引退单元1054和物理寄存器组单元1058被耦合到执行群集1060。执行群集1060包括一个或多个执行单元1062的集合和一个或多个存储器访问单元1064的集合。执行单元1062可以对各种类型的数据(例如,标量浮点、打包整数、打包浮点、向量整型、向量浮点)执行各种操作(例如,移位、加法、减法、乘法)。尽管某些实施例可以包括专用于特定功能或功能集合的多个执行单元,但其他实施例可包括全部执行所有功能的仅一个执行单元或多个执行单元。调度器单元1056、物理寄存器组单元1058和执行群集1060被示为可能有多个,因为某些实施例为某些类型的数据/操作(例如,标量整型流水线、标量浮点/打包整型/打包浮点/向量整型/向量浮点流水线,和/或各自具有其自己的调度器单元、物理寄存器组单元和/或执行群集的存储器访问流水线——以及在分开的存储器访问流水线的情况下,实现其中仅该流水线的执行群集具有存储器访问单元1064的某些实施例)创建分开的流水线。还应当理解,在使用分开的流水线的情况下,这些流水线中的一个或多个可以为无序发布/执行,并且其余流水线可以为有序发布/执行。
存储器访问单元1064的集合被耦合到存储器单元1070,该存储器单元1070包括耦合到数据高速缓存单元1074的数据tlb单元1072,其中数据高速缓存单元1074耦合到二级(l2)高速缓存单元1076。在一个示例性实施例中,存储器访问单元1064可以包括加载单元、存储地址单元和存储数据单元,这些单元中的每一个单元被耦合到存储器单元1070中的数据tlb单元1072。指令高速缓存单元1034还被耦合到存储器单元1070中的二级(l2)高速缓存单元1076。l2高速缓存单元1076被耦合到一个或多个其他级的高速缓存,并最终耦合到主存储器。
作为示例,示例性寄存器重命名的、无序发布/执行核架构可以如下实现流水线1000:1)指令取出1038执行取出和长度解码级1002和1004;2)解码单元1040执行解码级1006;3)重命名/分配器单元1052执行分配级1008和重命名级1010;4)调度器单元1056执行调度级1012;5)物理寄存器组单元1058和存储器单元1070执行寄存器读取/存储器读取级1014;执行群集1060执行执行级1016;6)存储器单元1070和物理寄存器组单元1058执行写回/存储器写入级1018;7)各单元可牵涉到异常处理级1022;以及8)引退单元1054和物理寄存器组单元1058执行提交级1024。
核1090可支持一个或多个指令集(例如,x86指令集(具有与较新版本一起添加的某些扩展);加利福尼亚州桑尼维尔市的mips技术公司的mips指令集;加利福尼州桑尼维尔市的arm控股的arm指令集(具有诸如neon等可选附加扩展)),其中包括本文中描述的各指令。在一个实施例中,核1090包括用于支持打包数据指令集扩展(例如,avx1、avx2和/或先前描述的一些形式的一般向量友好指令格式(u=0和/或u=1))的逻辑,从而允许很多多媒体应用使用的操作能够使用打包数据来执行。
应当理解,核可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,此各种方式包括时分多线程化、同步多线程化(其中单个物理核为物理核正在同步多线程化的各线程中的每一个线程提供逻辑核)、或其组合(例如,时分取出和解码以及此后诸如用
尽管在无序执行的上下文中描述了寄存器重命名,但应当理解,可以在有序架构中使用寄存器重命名。尽管所示出的处理器的实施例还包括分开的指令和数据高速缓存单元1034/1074以及共享l2高速缓存单元1076,但替换实施例可以具有用于指令和数据两者的单个内部高速缓存,诸如例如一级(l1)内部高速缓存或多个级别的内部缓存。在某些实施例中,该系统可包括内部高速缓存和在核和/或处理器外部的外部高速缓存的组合。或者,所有高速缓存都可以在核和/或处理器的外部。
具体的示例性有序核架构
图11a-b示出了更具体的示例性有序核架构的框图,该核将是芯片中的若干逻辑块之一(包括相同类型和/或不同类型的其他核)。根据应用,这些逻辑块通过高带宽的互连网络(例如,环形网络)与某些固定的功能逻辑、存储器i/o接口和其它必要的i/o逻辑通信。
图11a是根据本发明的各实施例的单个处理器核以及它与管芯上互连网络1102的连接及其二级(l2)高速缓存1104的本地子集的框图。在一个实施例中,指令解码器1100支持具有打包数据指令集扩展的x86指令集。l1高速缓存1106允许对进入标量和向量单元中的高速缓存存储器的低等待时间访问。尽管在一个实施例中(为了简化设计),标量单元1108和向量单元1110使用分开的寄存器集合(分别为标量寄存器1112和向量寄存器1114),并且在这些寄存器之间转移的数据被写入到存储器并随后从一级(l1)高速缓存1106读回,但是本发明的替换实施例可以使用不同的方法(例如使用单个寄存器集合或包括允许数据在这两个寄存器组之间传输而无需被写入和读回的通信路径)。
l2高速缓存的本地子集1104是全局l2高速缓存的一部分,该全局l2高速缓存被划分成多个分开的本地子集,即每个处理器核一个本地子集。每个处理器核具有到其自己的l2高速缓存1104的本地子集的直接访问路径。被处理器核读出的数据被存储在其l2高速缓存子集1104中,并且可以与其他处理器核访问其自己的本地l2高速缓存子集并行地被快速访问。被处理器核写入的数据被存储在其自己的l2高速缓存子集1104中,并在必要的情况下从其它子集清除。环形网络确保共享数据的一致性。环形网络是双向的,以允许诸如处理器核、l2高速缓存和其它逻辑块之类的代理在芯片内彼此通信。每个环形数据路径为每个方向1012位宽。
图11b是根据本发明的各实施例的图11a中的处理器核的一部分的展开图。图11b包括l1高速缓存1104的l1数据高速缓存1106a部分,以及关于向量单元1110和向量寄存器1114的更多细节。具体地说,向量单元1110是16宽向量处理单元(vpu)(见16宽alu1128),该单元执行整型、单精度浮点以及双精度浮点指令中的一个或多个。该vpu通过混合单元1120支持对寄存器输入的混合、通过数值转换单元1122a-b支持数值转换,并通过复制单元1124支持对存储器输入的复制。写掩码寄存器1126允许断言所得的向量写入。
具有集成存储器控制器和图形器件的处理器
图12是根据本发明的各实施例可能具有一个以上核、可能具有集成存储器控制器、以及可能具有集成图形器件的处理器1200的框图。图12中的实线框示出具有单个核1202a、系统代理1210、一个或多个总线控制器单元1216的集合的处理器1200,而虚线框中的可选附加项示出具有多个核1202a-n、系统代理单元1210中的一个或多个集成存储器控制器单元1214的集合以及专用逻辑1208的替代处理器1200。
因此,处理器1200的不同实现可包括:1)cpu,其中专用逻辑1208是集成图形和/或科学(吞吐量)逻辑(其可包括一个或多个核),并且核1202a-n是一个或多个通用核(例如,通用的有序核、通用的无序核、这两者的组合);2)协处理器,其中核1202a-n是旨在主要用于图形和/或科学(吞吐量)的多个专用核;以及3)协处理器,其中核1202a-n是多个通用有序核。因此,处理器1200可以是通用处理器、协处理器或专用处理器,诸如例如网络或通信处理器、压缩引擎、图形处理器、gpgpu(通用图形处理单元)、高吞吐量的集成众核(mic)协处理器(包括30个或更多核)、或嵌入式处理器等。该处理器可以被实现在一个或多个芯片上。处理器1200可以是一个或多个衬底的一部分,和/或可以使用诸如例如bicmos、cmos或nmos等的多个加工技术中的任何一个技术将其实现在一个或多个衬底上。
存储器层次结构包括在各核内的一个或多个级别的高速缓存、一个或多个共享高速缓存单元1206的集合、以及耦合至集成存储器控制器单元1214的集合的外部存储器(未示出)。该共享高速缓存单元1206的集合可以包括一个或多个中间级高速缓存,诸如二级(l2)、三级(l3)、四级(l4)或其他级别的高速缓存、末级高速缓存(llc)、和/或其组合。尽管在一个实施例中,基于环的互连单元1212将集成图形逻辑1208、共享高速缓存单元1206的集合以及系统代理单元1210/集成存储器控制器单元1214互连,但替代实施例可使用任何数量的公知技术来将这些单元互连。在一个实施例中,可以维护一个或多个高速缓存单元1206和核1202a-n之间的一致性(coherency)。
在某些实施例中,核1202a-n中的一个或多个核能够多线程化。系统代理1210包括协调和操作核1202a-n的那些组件。系统代理单元1210可包括例如功率控制单元(pcu)和显示单元。pcu可以是或包括用于调整核1202a-n和集成图形逻辑1208的功率状态所需的逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
核1202a-n在架构指令集方面可以是同构的或异构的;即,这些核1202a-n中的两个或更多个核可能能够执行相同的指令集,而其他核可能能够执行该指令集的仅仅子集或不同的指令集。
示例性计算机架构
图13-16是示例性计算机架构的框图。本领域已知的对膝上型设备、台式机、手持pc、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般来说,能够包含本文中所公开的处理器和/或其它执行逻辑的多个系统和电子设备一般都是合适的。
现在参见图13,所示为根据本发明的一个实施例的系统1300的框图。系统1300可以包括一个或多个处理器1310、1315,这些处理器耦合到控制器中枢1320。在一个实施例中,控制器中枢1320包括图形存储器控制器中枢(gmch)1390和输入/输出中枢(ioh)1350(其可以在分开的芯片上);gmch1390包括存储器和图形控制器,存储器1340和协处理器1345耦合到该存储器和图形控制器;ioh1350将输入/输出(i/o)设备1360耦合到gmch1390。或者,存储器和图形控制器中的一个或两者可以被集成在处理器内(如本文中所描述的),存储器1340和协处理器1345被直接耦合到处理器1310以及控制器中枢1320,控制器中枢1320与ioh1350处于单个芯片中。
附加处理器1315的任选性质用虚线表示在图13中。每一处理器1310、1315可包括本文中描述的处理核中的一个或多个,并且可以是处理器1200的某一版本。
存储器1340可以是例如动态随机存取存储器(dram)、相变存储器(pcm)或这两者的组合。对于至少一个实施例,控制器中枢1320经由诸如前端总线(fsb)之类的多分支总线(multi-dropbus)、诸如快速通道互连(qpi)之类的点对点接口、或者类似的连接1395与处理器1310、1315进行通信。
在一个实施例中,协处理器1345是专用处理器,诸如例如高吞吐量mic处理器、网络或通信处理器、压缩引擎、图形处理器、gpgpu、或嵌入式处理器等等。在一个实施例中,控制器中枢1320可以包括集成图形加速器。
在物理资源1310、1315之间可以存在包括架构、微架构、热、和功耗特征等的一连串品质度量方面的各种差异。
在一个实施例中,处理器1310执行控制一般类型的数据处理操作的指令。嵌入在这些指令中的可以是协处理器指令。处理器1310将这些协处理器指令识别为应当由附连的协处理器1345执行的类型。因此,处理器1310在协处理器总线或者其他互连上将这些协处理器指令(或者表示协处理器指令的控制信号)发布到协处理器1345。协处理器1345接受并执行所接收的协处理器指令。
现在参考图14,所示为根据本发明的一实施例的更具体的第一示例性系统1400的框图。如图14所示,多处理器系统1400是点对点互连系统,并包括经由点对点互连1450耦合的第一处理器1470和第二处理器1480。处理器1470和1480中的每一个都可以是处理器1200的某一版本。在本发明的一个实施例中,处理器1470和1480分别是处理器1310和1315,而协处理器1438是协处理器1345。在另一实施例中,处理器1470和1480分别是处理器1310和协处理器1345。
处理器1470和1480被示为分别包括集成存储器控制器(imc)单元1472和1482。处理器1470还包括作为其总线控制器单元的一部分的点对点(p-p)接口1476和1478;类似地,第二处理器1480包括点对点接口1486和1488。处理器1470、1480可以使用点对点(p-p)电路1478、1488经由p-p接口1450来交换信息。如图14所示,imc1472和1482将各处理器耦合至相应的存储器,即存储器1432和存储器1434,这些存储器可以是本地附连至相应的处理器的主存储器的部分。
处理器1470、1480可各自经由使用点对点接口电路1476、1494、1486、1498的各个p-p接口1452、1454与芯片组1490交换信息。芯片组1490可以可选地经由高性能接口1439与协处理器1438交换信息。在一个实施例中,协处理器1438是专用处理器,诸如例如高吞吐量mic处理器、网络或通信处理器、压缩引擎、图形处理器、gpgpu、或嵌入式处理器等等。
共享高速缓存(未示出)可以被包括在任一处理器之内,或被包括在两个处理器外部但仍经由p-p互连与这些处理器连接,从而如果将某处理器置于低功率模式时,可将任一处理器或两个处理器的本地高速缓存信息存储在该共享高速缓存中。
芯片组1490可经由接口1496耦合至第一总线1416。在一个实施例中,第一总线1416可以是外围部件互连(pci)总线,或诸如pciexpress总线或其它第三代i/o互连总线之类的总线,但本发明的范围并不受此限制。
如图14所示,各种i/o设备1414可以连同总线桥1418耦合到第一总线1416,总线桥1418将第一总线1416耦合至第二总线1420。在一个实施例中,诸如协处理器、高吞吐量mic处理器、gpgpu的处理器、加速器(诸如例如图形加速器或数字信号处理器(dsp)单元)、现场可编程门阵列或任何其他处理器的一个或多个附加处理器1415被耦合到第一总线1416。在一个实施例中,第二总线1420可以是低引脚计数(lpc)总线。各种设备可以被耦合至第二总线1420,在一个实施例中这些设备包括例如键盘/鼠标1422、通信设备1427以及诸如可包括指令/代码和数据1430的盘驱动器或其它大容量存储设备的存储单元1428。此外,音频i/o1424可以被耦合至第二总线1420。注意,其它架构是可能的。例如,代替图14的点对点架构,系统可以实现多分支总线或其它这类架构。
现在参考图15,所示为根据本发明的实施例的更具体的第二示例性系统1500的框图。图14和图15中的相同部件用相同附图标记表示,并从图15中省去了图14中的某些方面,以避免使图15的其它方面变得模糊。
图15示出处理器1470、1480可分别包括集成存储器和i/o控制逻辑(“cl”)1472和1482。因此,cl1472、1482包括集成存储器控制器单元并包括i/o控制逻辑。图15不仅示出存储器1432、1434耦合至cl1472、1482,而且还示出i/o设备1514也耦合至控制逻辑1472、1482。传统i/o设备1515被耦合至芯片组1490。
现在参考图16,所示为根据本发明的一实施例的soc1600的框图。在图12中,相似的部件具有同样的附图标记。另外,虚线框是更先进的soc的可选特征。在图16中,互连单元1602被耦合至:应用处理器1610,该应用处理器包括一个或多个核202a-n的集合以及共享高速缓存单元1206;系统代理单元1210;总线控制器单元1216;集成存储器控制器单元1214;一组或一个或多个协处理器1620,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(sram)单元1630;直接存储器存取(dma)单元1632;以及用于耦合至一个或多个外部显示器的显示单元1640。在一个实施例中,协处理器1620包括专用处理器,诸如例如网络或通信处理器、压缩引擎、gpgpu、高吞吐量mic处理器、或嵌入式处理器等等。
本文公开的机制的各实施例可以被实现在硬件、软件、固件或这些实现方法的组合中。本发明的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
可将程序代码(诸如图14中示出的代码1430)应用于输入指令,以执行本文描述的各功能并生成输出信息。可以按已知方式将输出信息应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有诸如例如数字信号处理器(dsp)、微控制器、专用集成电路(asic)或微处理器之类的处理器的任何系统。
程序代码可以用高级程序化语言或面向对象的编程语言来实现,以便与处理系统通信。在需要时,也可用汇编语言或机器语言来实现程序代码。事实上,本文中描述的机制不仅限于任何特定编程语言的范围。在任一情形下,语言可以是编译语言或解释语言。
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的表示性指令来实现,指令表示处理器中的各种逻辑,指令在被机器读取时使得该机器制作用于执行本文所述的技术的逻辑。被称为“ip核”的这些表示可以被存储在有形的机器可读介质上,并被提供给多个客户或生产设施以加载到实际制造该逻辑或处理器的制造机器中。
这样的机器可读存储介质可以包括但不限于通过机器或设备制造或形成的物品的非瞬态的有形安排,其包括存储介质,诸如硬盘;任何其它类型的盘,包括软盘、光盘、紧致盘只读存储器(cd-rom)、紧致盘可重写(cd-rw)的以及磁光盘;半导体器件,例如只读存储器(rom)、诸如动态随机存取存储器(dram)和静态随机存取存储器(sram)的随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、闪存、电可擦除可编程只读存储器(eeprom);相变存储器(pcm);磁卡或光卡;或适于存储电子指令的任何其它类型的介质。
因此,本发明的各实施例还包括非瞬态的有形机器可读介质,该介质包含指令或包含设计数据,诸如硬件描述语言(hdl),它定义本文中描述的结构、电路、装置、处理器和/或系统特征。这些实施例也被称为程序产品。
仿真(包括二进制变换、代码变形等)
在某些情况下,指令转换器可用来将指令从源指令集转换至目标指令集。例如,指令转换器可以变换(例如使用静态二进制变换、包括动态编译的动态二进制变换)、变形、仿真或以其它方式将指令转换成将由核来处理的一个或多个其它指令。指令转换器可以用软件、硬件、固件、或其组合实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上且部分在处理器外。
图17是根据本发明的各实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。在所示的实施例中,指令转换器是软件指令转换器,但作为替代,该指令转换器可以用软件、固件、硬件或其各种组合来实现。图17示出可以使用x86编译器1704来编译利用高级语言1702的程序,以生成可以由具有至少一个x86指令集核的处理器1716原生执行的x86二进制代码1706。具有至少一个x86指令集核的处理器1716表示任何处理器,这些处理器能通过兼容地执行或以其他方式处理以下内容来执行与具有至少一个x86指令集核的英特尔处理器基本相同的功能:1)英特尔x86指令集核的指令集的本质部分,或2)目标为在具有至少一个x86指令集核的英特尔处理器上运行的应用或其它程序的目标代码版本,以便取得与具有至少一个x86指令集核的英特尔处理器基本相同的结果。x86编译器1704表示用于生成x86二进制代码1706(例如,目标代码)的编译器,该二进制代码1706可通过或不通过附加的链接处理在具有至少一个x86指令集核的处理器1716上执行。类似地,图17示出可以使用替代的指令集编译器1708来编译利用高级语言1702的程序,以生成可以由不具有至少一个x86指令集核的处理器1714(例如具有执行加利福尼亚州桑尼维尔市的mips技术公司的mips指令集、和/或执行加利福尼亚州桑尼维尔市的arm控股公司的arm指令集的核的处理器)原生执行的替代指令集二进制代码1710。指令转换器1712被用来将x86二进制代码1706转换成可以由不具有x86指令集核的处理器1714原生执行的代码。该转换后的代码不大可能与替换性指令集二进制代码1710相同,因为能够这样做的指令转换器难以制造;然而,转换后的代码将完成一般操作并由来自替代指令集的指令构成。因此,指令转换器1712通过仿真、模拟或任何其它过程来表示允许不具有x86指令集处理器或核的处理器或其它电子设备执行x86二进制代码1706的软件、固件、硬件或其组合。
- 还没有人留言评论。精彩留言会获得点赞!