一种基于深度学习的服务机器人目标检测与定位方法与流程
本发明涉及图像及视频目标检测领域,特别涉及一种基于深度学习的服务机器人目标检测与定位方法
背景技术:
目标检测与定位对于人来说是再简单不过的任务,但是对于机器人来说,很难直接得到图像中有哪些目标这种高层语义概念,也不清楚目标出现在图像中哪个区域。图像中的目标可能出现在任何位置,目标的形态可能存在各种各样的变化,图像的背景千差万别,这些因素导致服务机器人的目标检测与定位并不是一个容易解决的任务。
传统的目标检测方法一般分为三个阶段,首先在给定的图像上选择一些候选区域,然后对这些区域提取特征,最后使用分类器进行分类。
传统方法存在许多问题,比如:提取区域时为了保证不同的长宽比,不同的尺度采取的穷举策略,时间复杂度太高;采用人工的特征提取方法,虽然该方法在特定的特征在特定的目标检测问题中取得了较好的效果,但这种人工的特征提取方法极大地依赖经验,而且在复杂场景下,特征匹配的复杂度高、鲁棒性差;采用分步进行的方法,耗时多且不具有实时性。
本发明设计的方法解决了依赖人工提取特征、复杂场景下鲁棒性差以及不具有实时性的问题,建立了整个服务机器人目标检测与定位系统,可以直接应用于家庭、办公室、机场、酒店等多种场合。
技术实现要素:
本发明的目的在于设计一种基于深度学习的实时性好、准确率高的服务机器人目标检测与定位方法,实现服务机器人在复杂室内环境下的目标实时检测与定位功能。
具体步骤如下:
(1)搭建服务机器人目标检测与识别系统;
(2)采集服务机器人待检测物体的图像并制作包含训练集和验证集的图像数据集;
(3)设计深度卷积神经网络结构,包括特征提取网络、区域提取网络以及分类与位置回归网络;
(4)在深度学习框架下进行训练得到模型,将模型移植到开发板上,并编写脚本程序调用模型以及摄像头进行测试,设计服务机器人目标检测与定位系统;
(5)服务机器人能够根据摄像头捕捉到的图像确定目标的类别同时给出目标在图像中的位置。
在一些实施方式中步骤(1)包括如下步骤:
(1.1)系统由nvidiajetsontx1开发板(以下简称tx1)和usb摄像头组成。tx1以nvidiamaxwelltm架构为基础构建,含有256个cuda核心,提供每秒超过一万亿次的浮点运算的性能;且体积小巧、高度集成,适合嵌入式深度学习、计算机视觉、图形和gpu计算。usb摄像头体积小巧、可调节俯仰角度。
(1.2)通过jetpack2.3给tx1安装ubuntu系统,并实现外部存储空间扩展以及交换空间,为搭建深度学习框架以及深度卷积神经网络提供足够的空间。
(1.3)将usb摄像头与之连接,并测试其可用性。
在一些实施方式中,步骤(2)具体包括如下步骤:
(2.1)通过各种网站上相关图片下载和相机拍摄,采集每类物体的图像,包括彩色的和黑白的,不同角度和光照条件下的,背景复杂程度不同的,图片中物体个数以及物体在图片中所占比例不同的图片。室内物体数据集包含电脑、桌子、椅子、沙发、盆栽、瓶子,共1300张图像;儿童玩具数据集包含螺丝钉模型、螺丝帽模型、钉子模型、锤子模型,共1100张图像。
(2.2)对原始图像做随机旋转、随机翻转、随机改变亮度、随机剪裁等操作,使数据集更丰富。然后对原始图像进行标注,框出每个目标的位置并标注出其标签,制作成xml格式作为标签文件。
(2.3)将每个数据集中的图片均按照1:4的比例分为验证集和训练集。
(2.4)每个数据集均包含三个文件夹,分别为存储图片、标签文件以及训练验证文件。
在一些实施方式中,卷积神经网络结构的设计具体为:
该网络结构由特征提取网络、区域提取网络以及分类与位置回归网络组成。特征提取网络对输入图像进行特征提取,将提取出的原始特征同时输入给区域提取网络和分类与位置回归网络。区域提取网络将原始特征图转化为感兴趣区域特征图,并将其输入给分类与位置回归网络。分类与位置回归网络将输入的原始特征和感兴趣区域特征进行处理,得到目标的类别以及位置信息。
在一些实施方式中步骤(3)中的深度卷积神经网络结构特征提取网络、区域提取网络以及分类与位置回归网络组成。具体包括如下步骤:
(3.1)特征提取网络对输入图像进行特征提取,将提取出的原始特征同时输入给区域提取网络和分类与位置回归网络。
(3.2)区域提取网络将原始特征图转化为感兴趣区域特征图,并将其输入给分类与位置回归网络。
(3.3)分类与位置回归网络将输入的原始特征和感兴趣区域特征进行处理,得到目标的类别以及位置信息。
其中特征提取网络由输入层和5个卷积层(conv)组成,其中第一个、第二个和第五个卷积层后会紧跟一个最大池化层(max-pooling)和非线性化层(relu),每个卷积层后跟一个归一化层(norm)。将数据集输入到特征提取网络中,将第五个卷积层(conv5)得到的特征图作为原始特征同时输入给区域提取网络和分类与位置回归网络。
区域提取网络通过一个小的卷积核在原始特征图上滑动,在每个特征点上产生一系列预测框,根据一定的选择机制得到一个新的特征向量,将其同时输入给分类层和位置预测层,得到感兴趣区域(rois),同样作为分类与位置回归网络的输入。
分类与位置回归网络将特征提取网络得到的原始特征图和区域提取网络得到的感兴趣区域同时输入给一层池化层和两层全连接层,得到感兴趣区域特征图;将感兴趣区域特征图同时输入给softmax逻辑回归层和位置回归层,实现目标分类和定位。
该网络模型实现端对端的操作,只需将数据集输入给输入层即可得到目标的类别及位置信息。
在一些实施方式中,所述步骤(4)包括如下步骤:
(4.1)将所设计的网络结构搭建在caffe框架下。
(4.2)将所设计的数据集输入给卷积神经网络,在geforcegtx1080gpu下训练。
(4.3)经过训练得到目标检测与定位模型。
(4.4)利用训练得到的模型,编写测试脚本程序,调用摄像头,实现实时的目标检测与定位。
附图说明
图1是本发明设计的卷积神经网络整体结构图
图2是本发明设计的特征提取网络结构图
图3是本发明设计的区域提取网络结构图
图4是本发明设计的分类与位置回归网络结构图
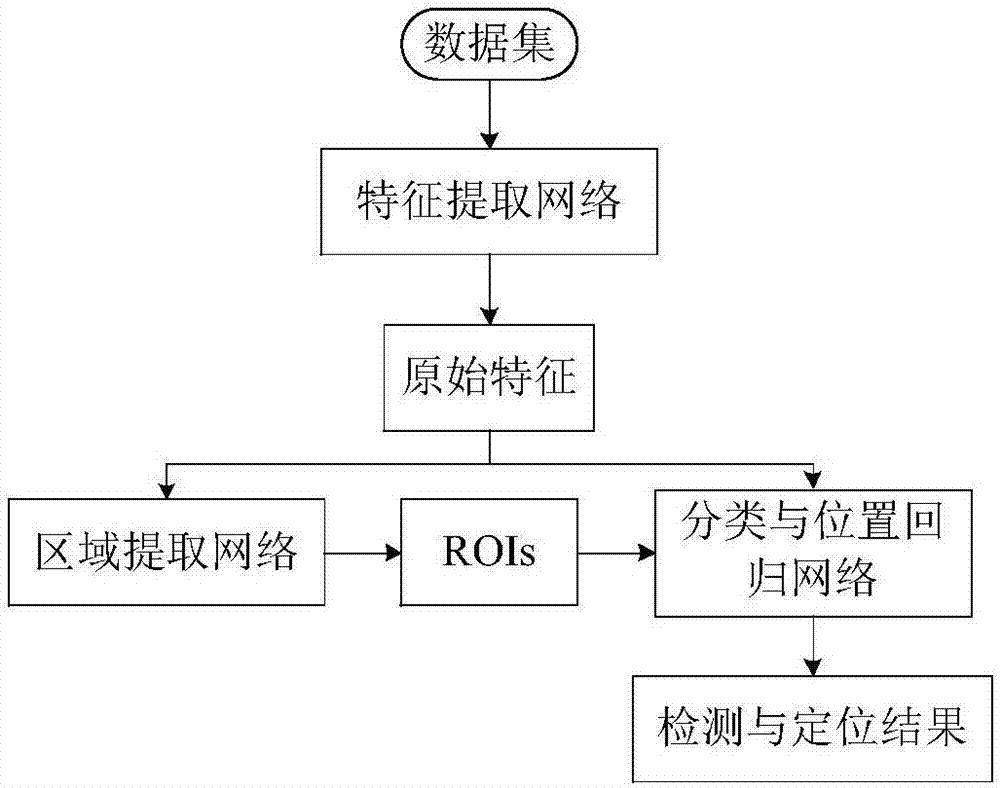
图5是本发明中基于深度学习的目标检测与定位方法流程图
具体实施方式
本发明提出了一种基于深度学习的服务机器人目标检测与定位方法,旨在实现服务机器人在复杂环境下高效准确地进行目标检测与定位。首先搭建服务机器人目标检测与识别系统;然后采集服务机器人待检测物体的图像并制作包含训练集和验证集的图像数据集。然后设计深度卷积神经网络结构,包括特征提取网络、区域提取网络以及分类与位置回归网络。接下来在深度学习框架下进行训练得到模型,将模型移植到开发板上,并编写脚本程序调用模型以及摄像头进行测试,在视频中显示多种目标的类别以及在摄像头捕获到的图像中的位置和准确率。在室内复杂环境下,服务机器人能够根据摄像头捕捉到的图像确定目标的类别同时给出目标在图像中的位置,为服务机器人抓取等操作提供有用信息,且准确率高、实时性好。
在一些实施方式中,目标检测与定位系统具体为:
(1)系统由nvidiajetsontx1开发板(以下简称tx1)和usb摄像头组成。tx1以nvidiamaxwelltm架构为基础构建,含有256个cuda核心,提供每秒超过一万亿次的浮点运算的性能;且体积小巧、高度集成,适合嵌入式深度学习、计算机视觉、图形和gpu计算。usb摄像头体积小巧、可调节俯仰角度。
(2)通过jetpack2.3给tx1安装ubuntu系统,并实现外部存储空间扩展以及交换空间,为搭建深度学习框架以及深度卷积神经网络提供足够的空间。
(3)将usb摄像头与之连接,并测试其可用性。
在一些实施方式中,数据集的建立具体为:
(1)通过各种网站上相关图片下载和相机拍摄,采集每类物体的图像,包括彩色的和黑白的,不同角度和光照条件下的,背景复杂程度不同的,图片中物体个数以及物体在图片中所占比例不同的图片。室内物体数据集包含电脑、桌子、椅子、沙发、盆栽、瓶子,共1300张图像;儿童玩具数据集包含螺丝钉模型、螺丝帽模型、钉子模型、锤子模型,共1100张图像。
(2)对原始图像做随机旋转、随机翻转、随机改变亮度、随机剪裁等操作,使数据集更丰富。然后对原始图像进行标注,框出每个目标的位置并标注出其标签,制作成xml格式作为标签文件。
(3)将每个数据集中的图片均按照1:4的比例分为验证集和训练集。
(4)每个数据集均包含三个文件夹,分别为存储图片、标签文件以及训练验证文件。
在一些实施方式中,卷积神经网络结构的设计具体为:
(1)该网络结构由特征提取网络、区域提取网络以及分类与位置回归网络组成。特征提取网络对输入图像进行特征提取,将提取出的原始特征同时输入给区域提取网络和分类与位置回归网络。区域提取网络将原始特征图转化为感兴趣区域特征图,并将其输入给分类与位置回归网络。分类与位置回归网络将输入的原始特征和感兴趣区域特征进行处理,得到目标的类别以及位置信息。
(2)特征提取网络由输入层和5个卷积层(conv)组成,其中第一个、第二个和第五个卷积层后会紧跟一个最大池化层(max-pooling)和非线性化层(relu),每个卷积层后跟一个归一化层(norm)。将数据集输入到特征提取网络中,将第五个卷积层(conv5)得到的特征图作为原始特征同时输入给区域提取网络和分类与位置回归网络。
(3)区域提取网络通过一个小的卷积核在原始特征图上滑动,在每个特征点上产生一系列预测框,根据一定的选择机制得到一个新的特征向量,将其同时输入给分类层和位置预测层,得到感兴趣区域(rois),同样作为分类与位置回归网络的输入。
(4)分类与位置回归网络将特征提取网络得到的原始特征图和区域提取网络得到的感兴趣区域同时输入给一层池化层和两层全连接层,得到感兴趣区域特征图;将感兴趣区域特征图同时输入给softmax逻辑回归层和位置回归层,实现目标分类和定位。
(5)该网络模型实现端对端的操作,只需将数据集输入给输入层即可得到目标的类别及位置信息。
在一些实施方式中,识别测试方法具体为:
(1)将所设计的网络结构搭建在caffe框架下。
(2)将所设计的数据集输入给卷积神经网络,在geforcegtx1080gpu下训练。
(3)经过训练得到目标检测与定位模型。
(4)利用训练得到的模型,编写测试脚本程序,调用摄像头,实现实时的目标检测与定位。
下面结合附图对本发明进行详细说明。
(1)网络整体结构
参见图1,该网络结构由特征提取网络、区域提取网络以及分类与位置回归网络组成。特征提取网络对输入图像进行特征提取,将提取出的原始特征同时输入给区域提取网络和分类与位置回归网络。区域提取网络将原始特征图转化为感兴趣区域特征图,并将其输入给分类与位置回归网络。分类与位置回归网络将输入的原始特征和感兴趣区域特征进行处理,得到目标的类别以及位置信息。
(2)特征提取网络
参见图2,特征提取网络由输入层和5个卷积层(conv)组成,其中第一个、第二个和第五个卷积层后会紧跟一个最大池化层(max-pooling)和非线性化层(relu),每个卷积层后跟一个归一化层(norm)。将数据集输入到特征提取网络中,将第五个卷积层(conv5)得到的特征图作为原始特征同时输入给区域提取网络和分类与位置回归网络。
(3)区域提取网络结构
参见图3,区域提取网络通过一个小的卷积核在原始特征图上滑动,在每个特征点上产生一系列预测框,根据一定的选择机制得到一个新的特征向量,将其同时输入给分类层和位置预测层,得到感兴趣区域(rois),同样作为分类与位置回归网络的输入。
(4)分类与位置回归网络结构
参见图4,分类与位置回归网络将特征提取网络得到的原始特征图和区域提取网络得到的感兴趣区域同时输入给一层池化层和两层全连接层,得到感兴趣区域特征图;将感兴趣区域特征图同时输入给softmax逻辑回归层和位置回归层,实现目标分类和定位。
(5)检测与定位方法流程
参见图5,首先采集待识别物体的图像,制作成图像数据集;然后将所设计的网络结构搭建在caffe框架下,将数据集输入卷积神经网络,在geforcegtx1080gpu下进行训练,经过训练得到目标检测与定位模型;编写脚本程序调用该模型,实现对于服务机器人的摄像头捕捉到的图像信息,实时输出图像中目标类别及位置的功能。
- 还没有人留言评论。精彩留言会获得点赞!