一种PCIe设备与主机之间的多路有序数据传输方法与流程
本发明涉及数据通讯技术领域,具体而言,涉及一种pcie设备与主机之间的多路有序数据传输方法。
背景技术:
pcie(pci-express)是最新的总线和接口标准,越来越多的外置高速设备(如显卡、视频加速卡和千兆网卡)都使用pcie接口与主机通信。这些通过pcie接口与主机通信的外置高速设备被统称为pcie设备。其中最为人熟知的就是显卡(显示接口卡)。显卡与主机之间会以dma(directmemoryaccess)方式进行大量连续数据的传输,并且随着显卡的性能越来越高,能够同时处理的图形图像会更多,必然增加pcie接口带宽的需求和增加大量有序数据的并发传输路数。除了显卡之外,视频加速卡当前也被视频网站大量地使用。当前网络上的视频越来越多,大型的视频网站也越来越多,例如youtube、优酷等网站。每一分钟在线观看视频的人数就达好几亿,为了进一步加快视频的解码速度和压缩速度,越来越多的网络视频提供商在服务器上增加视频加速卡,以加快和并发上千路视频的编解码。当前的视频加速卡和显卡一样大多是使用pcie接口与服务器主机相联。由于视频加速卡需要并发多路甚至上千路视频编解码,为了视频的正常解码和编码,要求同一路视频的数据必须有序,同时还要求达到最大的解码性能和最大的pcie带宽使用率。一般的视频加速卡解码过程是,服务器主机将多路编码流数据通过pcie以dma的方式发送到视频加速卡,然后视频加速卡将编码流解码之后获得yuv(一种颜色编码方法),并将多路yuv通过pcie以dma方式回传到主机。传输过程中,yuv和码流在同一路中必须有序,否则会导致码流不能正常被解码,yuv不能被后续的加工(聚类或者播放等)正常处理。一般的视频加速卡编码过程是,服务器将多路yuv通过pcie以dma方式传送到视频加速卡,然后视频加速卡将yuv进行编码,并将编码之后的码流通过pcie以dma方式回传到主机。传输过程中,yuv和码流在同一路中必须有序,否则会导致码流不能正常被解码或者不能正常有序播放。无论是编码数据还是yuv数据的传输过程都由dma控制器完成,dma控制器将主机dmabuffer中的数据拷贝到视频加速卡上的dmabuffer,或者将视频加速卡上的dmabuffer拷贝到主机的dmabuffer。
由于dma过程中数据长度不一致所以会导致前面dma操作可能会晚于后面的dma操作,如果要保证有序,一般的做法是需要完成了前面的dma操作,才进行后面的dma操作,这样就能够保证传送有序,但是会导致剩余dma通道空闲。即使剩余的dma通道被其他路的数据使用,也需要将dma通道和对应的数据传输路进行捆绑。如果其他路的数据并没有使用该dma通道就换另一路捆绑,为了让所有dma通道能够有效被利用,传统的方式需要一个dma通道捆绑很多路数据传输甚至上千路数据传输,这样会导致数据传输的管理复杂,占用更多的资源、空间和时间。
技术实现要素:
本发明提供一种pcie设备与主机之间的多路有序数据传输方法,用以降低pcie设备与主机之间数据传输管理的复杂度和多余的资源消耗。
为了达到上述目的,本发明提供了一种pcie设备与主机之间的多路有序数据传输方法,该方法用于传输pcie设备与主机之间的多路有序数据,其中,pcie设备和主机均设有源数据dmabuffer单元和目的数据dmabuffer单元,pcie设备的源数据dmabuffer单元包括多个用于缓存发送端欲发送的数据的dmabuffera1~an,pcie设备的目的数据dmabuffer单元包括多个用于缓存接收端接收到的数据的dmabufferb1~bn,主机的目的数据dmabuffer单元包括多个用于接收端接收到的数据的dmabuffera1′~an′,主机的源数据dmabuffer单元包括多个用于缓存发送端发送的数据的dmabufferb1′~bn′,其中,dmabuffera1~an与dmabuffera1′~an′依次对应以构成n个dmabuffer对“db1~dbn”,dmabufferb1~bn与dmabufferb1′~bn′依次对应以构成n个dmabuffer对“db1′~dbn′”,每个dmabuffer对均对应设置有一同步管理单元,每一同步管理单元中均设有一缓存状态指针p1和一缓存数据长度指针p2,每一同步管理单元中均具有本地dmabuffer地址存储器以及远程dmabuffer地址存储器,分别用于存储对应的发送端dmabuffer的地址和接收端dmabuffer的地址,pcie设备端设有指示db1~dbn状态的指针freepointer1、usedpointer1和donepointer1,主机端设有指示db1′~dbn′状态的指针freepointer2、usedpointer2和donepointer2,于一次数据传输过程中,dma操作端位于pcie设备端或主机端,当由发送端向接收端传输p路数据n1~np时,其中,每路数据均包括np1~npm共m个数据段,其中1≤p≤p且p为整数,若pcie设备作为发送端,主机作为接收端,该方法包括以下步骤:
s1:初始状态下,dmabuffera1~an和dmabuffera1′~an′均为“free”状态,也即,对于db1~dbn,均有*p1=free,以及*p2为零,freepointer1、usedpointer1和donepointer1均指向db1;
【数据发送步骤】
s2:发送端根据freepointer1的指向获取到db1的控制权,freepointer1转而指向db2;
s3:发送端令db1的*p1=allocated;
s4:发送端将数据n11拷贝至dmabuffera1中,并令db1的*p1=used,以及*p2=数据n11的长度;
s5:发送端根据freepointer1的指向获取到db2的控制权,freepointer1转而指向db3;
s6:发送端令db2的*p1=allocated;
s7:发送端将数据n21拷贝至dmabuffera2中,并令db2的*p1=used,以及*p2=数据n21的长度;
s8:发送端按照上述步骤s5~s7对p路数据中的第一个数据段依次执行上述操作,直至p路数据均执行完上述步骤或对于db1~dbn均有*p1=used,之后发送端再对每一路数据中的第2个~第m个数据段依次进行数据发送;
【dma步骤】
s9:dma操作端根据usedpointer1的指向获取到db1的控制权,usedpointer1转而指向db2;
s10:dma操作端令db1的*p1=dmaing;
s11:dma操作端获得空闲的dma通道并对db1进行dma操作,以将数据n11从dmabuffera1拷贝至dmabuffera1′;
s12:dma操作端令db1的*p1=done;
s13:dma操作端根据usedpointer1的指向获取到db2的控制权,usedpointer1转而指向db3;
s14:dma操作端令db2的*p1=dmaing;
s15:dma操作端获得空闲的dma通道并对db2进行dma操作,以将数据n21从dmabuffera2拷贝至dmabuffera2′;
s16:dma操作端令db2的*p1=done;
s17:dma操作端按照上述步骤s13~s16对p路数据中的第一个数据段依次执行上述操作,直至p路数据均执行完上述步骤或对于db1~dbn均有*p1=done,之后dma操作端再对每一路数据中的第2个~第m个数据段依次进行dma操作;
【数据接收步骤】
s18:接收端根据donepointer1的指向获取到db1的控制权,donepointer1转而指向db2;
s19:接收端令db1的*p1=reading;
s20:接收端将dmabuffera1′中的数据n11传输到上层应用;
s21:接收端令db1的*p1=free;
s22:接收端根据donepointer1的指向获取到db2的控制权,donepointer1转而指向db3;
s23:接收端令db2的*p1=reading;
s24:接收端将dmabuffera2′中的数据n12传输到上层应用;
s25:接收端令db2的*p1=free;
s26:接收端按照上述步骤s22~s25对p路数据中的第一个数据段依次执行上述操作,直至p路数据均执行完上述步骤或对于db1~dbn均有*p1=free,之后接收端再对每一路数据中的第2个~第m个数据段依次进行数据接收操作;
上述数据发送步骤、dma步骤和数据接收步骤同时进行,其中:
发送端按照db1、db2……dbn-1、dbn、db1、db2的顺序实时循环检测freepointer1指向的dmabuffer对的状态是否为“free”,若为“free”则将当前等待写入的数据写入其对应的发送端的dmabuffer,之后将该dmabuffer对标记为“used”状态,以表示此dmabuffer对中的数据能够执行dma步骤,其中,当一路数据中尚有数据段未完成数据发送时,当前等待写入的数据为该路数据中的下一个数据段,直至p路数据中的每一个数据段均完成数据发送步骤,
dma操作端按照db1、db2……dbn-1、dbn、db1、db2的顺序实时检测usedpointer1指向的dmabuffer对的状态是否为“used”,若为“是”则执行dma操作,以将发送端dmabuffer中的数据拷贝至接收端的dmabuffer中,执行完dma操作则将该dmabuffer对标记为“done”状态,以表示此dmabuffer对中的数据能够执行数据接收步骤,直至p路数据中的每一个数据段均完成dma步骤,
接收端按照db1、db2……dbn-1、dbn、db1、db2的顺序实时检测donepointer1指向的dmabuffer对的状态是否为“done”,若为“done”则对该dmabuffer对进行数据读取操作,以将该dmabuffer对中的数据读取至上层应用,之后将该dmabuffer对标记为“free”状态,以表示此dmabuffer对能够执行数据发送步骤,直至p路数据中的每一个数据段均完成数据接收步骤,
于一次数据传输过程中,若pcie设备作为接收端,主机作为发送端时,上述步骤中应用到的dmabuffer对则为“db1′~dbn′并使用freepointer2、usedpointer2和donepointer2指示“db1′~dbn′的状态,其余步骤不变。
在本发明的一实施例中,dma通道的个数为4个。
在本发明的一实施例中,pcie设备至主机与主机至pcie设备两个方向共享4个dma通道。
本发明提供的pcie设备与主机之间的多路有序数据传输方法不仅不需要将dma通道与数据传输路捆绑,并且仅需要使用三个pointer(指针)即可对dmabuffer进行管理,从而能够保证同一路数据有序的被传送到主机或者pcie设备,不仅降低了pcie设备与主机之间数据传输管理的复杂度和多余的资源消耗,而且还能够完全发挥pcie的带宽,使得实际传输带宽接近pcie的理论峰值带宽。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为pcie设备和主机中的组织架构示意图;
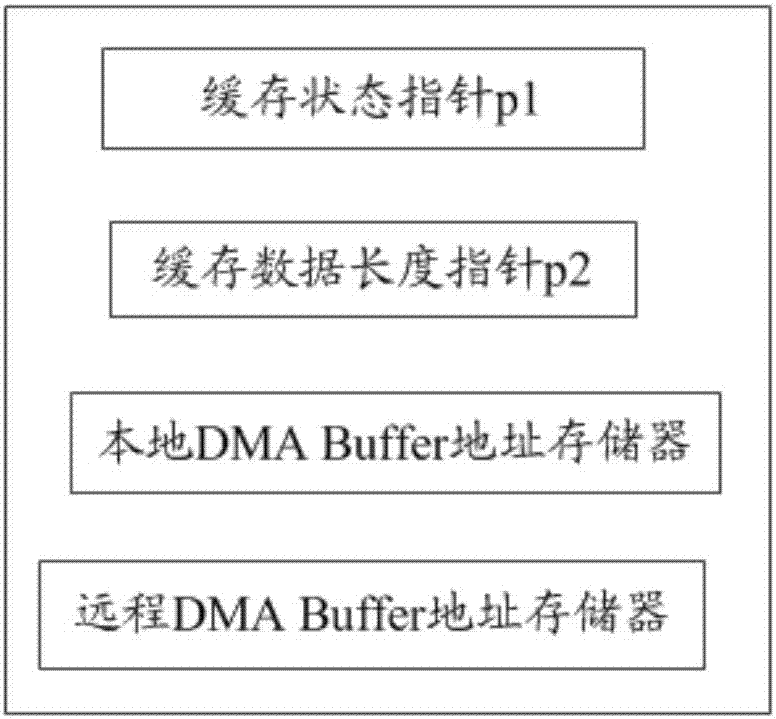
图2为同步管理单元的示意图;
图3为p路数据的示意图;
图4-1~图4-4分别为步骤s3、s4、s6和s7的示意图;
图4-5为p=4时,步骤s8的示意图;
图5-1、图5-2、图5-3和图5-4分别为步骤s10、s12、s14和s16的示意图;
图5-5为p=4时,步骤s17的示意图;
图6-1、图6-2、图6-3和图6-4分别为步骤s19、s21、s23和s25的示意图;
图6-5为p=4时,步骤s26的示意图;
图7为利用本发明对4路视频数据进行发送的示意图。
附图标记说明:1-源数据dmabuffer单元;2-目的数据dmabuffer单元。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了一种pcie设备与主机之间的多路有序数据传输方法,该方法用于传输pcie设备与主机之间的多路有序数据,为了实施该方法,pcie设备和主机需要具备相应的组织架构,如图1所示为pcie设备和主机中的组织架构示意图,其中,pcie设备和主机均设有源数据dmabuffer单元1和目的数据dmabuffer单元2,pcie设备的源数据dmabuffer单元包括多个用于缓存发送端欲发送的数据的dmabuffera1~an,pcie设备的目的数据dmabuffer单元包括多个用于缓存接收端接收到的数据的dmabufferb1~bn,主机的目的数据dmabuffer单元包括多个用于接收端接收到的数据的dmabuffera1′~an′,主机的源数据dmabuffer单元包括多个用于缓存发送端发送的数据的dmabufferb1′~bn′,其中,dmabuffera1~an与dmabuffera1′~an′依次对应以构成n个dmabuffer对“db1~dbn”,dmabufferb1~bn与dmabufferb1′~bn′依次对应以构成n个dmabuffer对“db1′~dbn′”,每个dmabuffer对均对应设置有一同步管理单元,如图2所示为同步管理单元的示意图,每一同步管理单元中均设有一缓存状态指针p1和一缓存数据长度指针p2,每一同步管理单元中均具有本地dmabuffer地址存储器以及远程dmabuffer地址存储器,分别用于存储对应的发送端dmabuffer的地址和接收端dmabuffer的地址,pcie设备端设有指示db1~dbn状态的指针freepointer1、usedpointer1和donepointer1(图中未示出),主机端设有指示db1′~dbn′状态的指针freepointer2、usedpointer2和donepointer2(图中未示出),于一次数据传输过程中,dma操作端位于pcie设备端或主机端,当由发送端向接收端传输p路数据n1~np时(如图3所示为p路数据的示意图),其中,每路数据均包括np1~npm共m个数据段,其中1≤p≤p且p为整数,若pcie设备作为发送端,主机作为接收端,该方法包括以下步骤:
s1:初始状态下,dmabuffera1~an和dmabuffera1′~an′均为“free”状态,也即,对于db1~dbn,均有*p1=free,以及*p2为零,freepointer1、usedpointer1和donepointer1均指向db1;
【数据发送步骤】
s2:发送端根据freepointer1的指向获取到db1的控制权,freepointer1转而指向db2;
s3:发送端令db1的*p1=allocated,如图4-1所示;
s4:发送端将数据n11拷贝至dmabuffera1中,并令db1的*p1=used,以及*p2=数据n11的长度,如图4-2所示;
s5:发送端根据freepointer1的指向获取到db2的控制权,freepointer1转而指向db3;
s6:发送端令db2的*p1=allocated,如图4-3所示;
s7:发送端将数据n21拷贝至dmabuffera2中,并令db2的*p1=used,以及*p2=数据n21的长度,如图4-4所示;
s8:发送端按照上述步骤s5~s7对p路数据中的第一个数据段依次执行上述操作,直至p路数据均执行完上述步骤或对于db1~dbn均有*p1=used,之后发送端再对每一路数据中的第2个~第m个数据段依次进行数据发送;
在本发明的一实施例中,当p=4即共有n1~n4共4路数据时,步骤s8如图4-5所示,db1~db4均有*p1=used,freepointer1指向db5。
【dma步骤】
s9:dma操作端根据usedpointer1的指向获取到db1的控制权,usedpointer1转而指向db2;
s10:dma操作端令db1的*p1=dmaing,如图5-1所示;
s11:dma操作端获得空闲的dma通道并对db1进行dma操作,以将数据n11从dmabuffera1拷贝至dmabuffera1′;
s12:dma操作端令db1的*p1=done,如图5-2所示;
s13:dma操作端根据usedpointer1的指向获取到db2的控制权,usedpointer1转而指向db3;
s14:dma操作端令db2的*p1=dmaing,如图5-3所示;
s15:dma操作端获得空闲的dma通道并对db2进行dma操作,以将数据n21从dmabuffera2拷贝至dmabuffera2′;
s16:dma操作端令db2的*p1=done,如图5-4所示;
s17:dma操作端按照上述步骤s13~s16对p路数据中的第一个数据段依次执行上述操作,直至p路数据均执行完上述步骤或对于db1~dbn均有*p1=done,之后dma操作端再对每一路数据中的第2个~第m个数据段依次进行dma操作;
在本发明的一实施例中,当p=4即共有n1~n4共4路数据时,步骤s17如图5-5所示,db1~db4均有*p1=done,freepointer1指向db5,实际上,dma操作端对p路数据中的第一个数据段进行dma操作的同时,发送端正在对p路数据中的第二个数据段进行数据发送操作。
dma操作需要选择空闲的dma通道。一般通道数为4个左右,所以使用轮询搜索方法就可以快速获得空闲的通道。每当dma通道被使用,就将其标记为used状态,dma操作完成之后,该通道就被标记位free状态。只要dma通道处于free状态,无论哪个方向的数据传输都可以使用其进行dma操作。在这种方式下,dma通道能够为两个方向的dma操作分配空闲的dma通道,而且所有dma通道是共享,能够实现两个传输方向的按需分配。
【数据接收步骤】
s18:接收端根据donepointer1的指向获取到db1的控制权,donepointer1转而指向db2;
s19:接收端令db1的*p1=reading,如图6-1所示;
s20:接收端将dmabuffera1′中的数据n11传输到上层应用;
s21:接收端令db1的*p1=free,如图6-2所示;
s22:接收端根据donepointer1的指向获取到db2的控制权,donepointer1转而指向db3;
s23:接收端令db2的*p1=reading,如图6-3所示;
s24:接收端将dmabuffera2′中的数据n12传输到上层应用;
s25:接收端令db2的*p1=free,如图6-4所示;
s26:接收端按照上述步骤s22~s25对p路数据中的第一个数据段依次执行上述操作,直至p路数据均执行完上述步骤或对于db1~dbn均有*p1=free,之后接收端再对每一路数据中的第2个~第m个数据段依次进行数据接收操作;
在本发明的一实施例中,当p=4即共有n1~n4共4路数据时,步骤s26如图6-5所示,db1~db4均有*p1=free,freepointer1、usedpointer1和donepointer1均指向db5,实际上,接收端对p路数据中的第一个数据段进行数据操作时,dma操作端正在对p路数据中的第二个数据段进行dma操作以及数据发送端正在对p路数据中的第三个数据段进行数据发送操作。
上述图4-1~图4-5、图5-1~图5-5、图6-1~图6-5均仅呈现了第一个数据段于各步骤中各个指针的变化以及dmabuffer的状态变化,其他数据段未予显示。
上述数据发送步骤、dma步骤和数据接收步骤同时进行,其中:
发送端按照db1、db2……dbn-1、dbn、db1、db2的顺序实时循环检测freepointer1指向的dmabuffer对的状态是否为“free”,若为“free”则将当前等待写入的数据写入其对应的发送端的dmabuffer,之后将该dmabuffer对标记为“used”状态,以表示此dmabuffer对中的数据能够执行dma步骤,其中,当一路数据中尚有数据段未完成数据发送时,当前等待写入的数据为该路数据中的下一个数据段,直至p路数据中的每一个数据段均完成数据发送步骤,例如,如图3所示,当第一路数据n1尚有数据段(例如最后一个数据段n1m)未完成发送时,当前等待写入的数据即为数据段n1m。
dma操作端按照db1、db2……dbn-1、dbn、db1、db2的顺序实时检测usedpointer1指向的dmabuffer对的状态是否为“used”,若为“是”则执行dma操作,以将发送端dmabuffer中的数据拷贝至接收端的dmabuffer中,执行完dma操作则将该dmabuffer对标记为“done”状态,以表示此dmabuffer对中的数据能够执行数据接收步骤,直至p路数据中的每一个数据段均完成dma步骤,
接收端按照db1、db2……dbn-1、dbn、db1、db2的顺序实时检测donepointer1指向的dmabuffer对的状态是否为“done”,若为“done”则对该dmabuffer对进行数据读取操作,以将该dmabuffer对中的数据读取至上层应用,之后将该dmabuffer对标记为“free”状态,以表示此dmabuffer对能够执行数据发送步骤,直至p路数据中的每一个数据段均完成数据接收步骤。
可见,本发明中的dmabuffer对的状态只能按照free->allocated->used->dmaing->done->reading->free的顺序变化,不能反向变化或跳变,本发明因此能够维持主机和pcie设备对dmabuffer对的互斥访问。free状态表示当前的dmabuffer对是空闲的,可以被使用。在获得free状态的dmabuffer对之后,发送端马上将其设置为allocated状态,表示该dmabuffer对被占用。当将被发送的数据拷贝到dmabuffer对的源dmabuffer之后,发送端将dmabuffer对的状态设置为used状态,表示该dmabuffer对已经可以进行dma操作。当dmabuffer对在进行dma操作的过程中,dma控制器端(含有dma控制器的一端)将dmabuffer对设置为dmaing状态,表示正在进行dma操作。当dma操作完成之后,dma控制器端将dmabuffer对设置为done状态,表示可以上层应用可以接收数据。当接收端接收数据过程中,会将dmabuffer对的状态设置reading状态,表示该dmabuffer对的数据正在被上层应用接收。上层应用完成数据接收之后,接收端将dmabuffer对的状态设置为free状态,表示该dmabuffer对可以重新用于传输数据。
于一次数据传输过程中,若pcie设备作为接收端,主机作为发送端时,上述步骤中应用到的dmabuffer对则为“db1′~dbn′并使用freepointer2、usedpointer2和donepointer2指示“db1′~dbn′的状态,其余步骤不变。
在本发明的一实施例中,dma通道的个数例如可以为4个,pcie设备至主机与主机至pcie设备两个方向可以共享4个dma通道,以提高dma通道的利用率。
图7为利用本发明对4路视频数据进行发送的示意图,如图所示,数据a1、b1、c1和d1为第1路视频数据中的数据段,数据a2、b2、c2和d2为第2路视频数据中的数据段,数据a3、b3、c3和d3为第3路视频数据中的数据段,数据a4、b4、c4和d4为第4路视频数据中的数据段,如图7下方的时间线所示,当发送端对数据a1、a2、a3和a4完成数据发送操作并且数据a1、a2、a3和a4进入dma操作时,发送端就利用其余的处于free状态的dmabuffer对每一路中的下一段数据b1、b2、b3和b4进行数据发送操作;当数据a1、a2、a3和a4进行数据接收操作时,数据b1、b2、b3和b4进入dma操作,并且发送端利用其余的处于free状态的dmabuffer对每一路中的下一段数据c1、c2、c3和c4进入数据发送操作。可见,本发明能够使得发送端、dma端以及接收端均能够不间断的工作,发送端不间断利用处于free状态的dmabuffer对进行数据发送,发送流程为:每一路数据中的第1个数据段→每一路数据中的第2个数据段→……→每一路数据中的最后一个数据段;dma操作端不间断的利用空闲的dma通道对已完成数据发送的数据进行dma操作;接收端不间断的将已完成dma操作的数据传输到上层应用。另外,由图7可知,同时使用的dmabuffer对的数目为数据路数的三倍,因此,在设计dmabuffer对时应尽量使得dmabuffer对的数目不低于数据路数的三倍,以免因需要等待空闲的dmabuffer对而降低数据传输速率。
本发明提供的pcie设备与主机之间的多路有序数据传输方法不仅不需要将dma通道与数据传输路捆绑,并且仅需要使用三个pointer(指针)即可对dmabuffer进行管理,从而能够保证同一路数据有序的被传送到主机或者pcie设备,不仅降低了pcie设备与主机之间数据传输管理的复杂度和多余的资源消耗,而且还能够完全发挥pcie的带宽,使得实际传输带宽接近pcie的理论峰值带宽。
本领域普通技术人员可以理解:附图只是一个实施例的示意图,附图中的模块或流程并不一定是实施本发明所必须的。
本领域普通技术人员可以理解:实施例中的装置中的模块可以按照实施例描述分布于实施例的装置中,也可以进行相应变化位于不同于本实施例的一个或多个装置中。上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!