用于执行掩码位压缩的系统、装置以及方法与流程
本发明专利申请是国际申请号为pct/us2011/067081,国际申请日为2011年12月23日,进入中国国家阶段的申请号为201180075780.0,名称为“用于执行掩码位压缩的系统、装置以及方法”的发明专利申请的分案申请。
发明领域
本发明的领域一般涉及计算机处理器体系结构,更具体而言,涉及当执行时导致特定结果的指令。
背景
指令集,或指令集体系结构(isa)是涉及编程的计算机体系结构的一部分,并可以包括本机数据类型、指令、寄存器体系结构、寻址模式、存储器体系结构、中断和异常处理以及外部输入和输出(i/o)。在本文中术语指令一般指宏指令——即被提供给处理器(或指令转换器,该指令转换器(例如使用静态二进制翻译、包括动态编译的动态二进制翻译)翻译、变形、仿真、或以其他方式将指令转换成要由处理器处理的一个或多个指令))以用于执行的指令——而不是微指令或微操作(micro-op)——它们是处理器的解码器解码宏指令的结果。
isa与微体系结构不同,微体系结构是实现指令集的处理器的内部设计。带有不同的微体系结构的处理器可以共享共同的指令集。例如,
指令集包括一个或多个指令格式。给定指令格式定义各个字段(位的数量、位的位置)以指定要执行的操作(操作码)以及对其要执行该操作的操作数等。通过指令模板(或子格式)的定义来进一步分解一些指令格式。例如,给定指令格式的指令模板可被定义为具有指令格式的字段(所包括的字段通常按照相同的次序,但是至少一些字段具有不同的位位置,因为包括更少的字段)的不同子集,和/或被定义为令给定字段被不同地解释。由此,isa的每一指令使用给定指令格式(并且如果定义,则在该指令格式的指令模板的给定一个中)来表达,并且包括用于指定操作和操作数的字段。例如,示例性add指令具有专用操作码以及包括指定该操作码的操作码字段和选择操作数的操作数字段(源1/目的地以及源2)的指令格式,并且该add指令在指令流中的出现将具有选择专用操作数的操作数字段中的专用内容。
科学、金融、自动向量化的通用,rms(识别、挖掘以及合成),以及可视和多媒体应用程序(例如,2d/3d图形、图像处理、视频压缩/解压缩、语音识别算法和音频操纵)常常需要对大量的数据项执行相同操作(被称为“数据并行性”)。单指令多数据(simd)是指使处理器对多个数据项执行操作的指令类型。simd技术特别适于能够在逻辑上将寄存器中的位分割为若干个固定尺寸的数据元素的处理器,每一个元素都表示单独的值。例如,256位寄存器中的位可以被指定为要在四个单独的64位打包的数据元素(四字(q)尺寸的数据元素)、八个单独的32位打包的数据元素(双字(d)尺寸的数据元素)、十六单独的16位打包的数据元素(一字(w)尺寸的数据元素)、或三十二个单独的8位数据元素(字节(b)尺寸的数据元素)上操作的源操作数。这种类型的数据被称为打包的数据类型或向量数据类型,这种数据类型的操作数被称为打包的数据操作数或向量操作数。换句话说,打包数据项或向量指的是打包数据元素的序列,并且打包数据操作数或向量操作数是simd指令(也称为打包数据指令或向量指令)的源操作数或目的地操作数。
作为示例,一种类型的simd指令指定要以垂直方式对两个源向量操作数执行的单个向量运算,以利用相同数量的数据元素,以相同数据元素顺序,生成相同尺寸的目的地向量操作数(也称为结果向量操作数)。源向量操作数中的数据元素被称为源数据元素,而目的地向量操作数中的数据元素被称为目的地或结果数据元素。这些源向量操作数是相同尺寸,并包含相同宽度的数据元素,如此,它们包含相同数量的数据元素。两个源向量操作数中的相同位位置中的源数据元素形成数据元素对(也称为相对应的数据元素;即,每个源操作数的数据元素位置0中的数据元素相对应,每个源操作数的数据元素位置1中的数据元素相对应,以此类推)。由该simd指令所指定的操作分别地对这些源数据元素对中的每一对执行,以生成匹配的数量的结果数据元素,如此,每一对源数据元素都具有对应的结果数据元素。由于操作是垂直的并且由于结果向量操作数尺寸相同,具有相同数量的数据元素,并且结果数据元素与源向量操作数以相同数据元素顺序被存储,因此,结果数据元素处于结果向量操作数中与它们的对应的源数据元素对在源向量操作数中相同的位位置。除此示例性类型的simd指令之外,还有各种其他类型的simd指令(例如,只有一个或具有两个以上的源向量操作数的、以水平方式操作的、生成不同尺寸的结果向量操作数的、具有不同尺寸的数据元素的、和/或具有不同的数据元素顺序的)。应该理解,术语目的地向量操作数(或目的地操作数)被定义为执行由指令所指定的操作的直接结果,包括将该目的地操作数存储在某一位置(寄存器或在由该指令所指定的存储器地址),以便它可以作为源操作数由另一指令访问(由另一指令指定该同一个位置)。
诸如由具有包括x86、mmxtm、流式simd扩展(sse)、sse2、sse3、sse4.1以及sse4.2指令的指令集的
附图简述
本发明是作为示例说明的,而不仅限制于各个附图的图形,在附图中,类似的参考编号表示类似的元件,其中:
图1(a)例示了用于kcompress的示例性指令的操作的示例性例示。
图1(b)例示了用于kcompress的示例性指令的操作的另一示例性例示。
图2以vex格式示出了这一指令的格式的更详细实施例。
图3示出处理器中kcompress指令的使用的实施例。
图4示出使用加法来处理kcompress指令的方法的实施例。
图5示出了这一指令的示例性伪码版本。
图6示出根据本发明的一个实施例的一个有效位向量写掩码元素的数量和向量尺寸和数据元素尺寸之间的相关性。
图7a例示了示例性avx指令格式。
图7b示出来自图7a的哪些字段构成完整操作码字段和基础操作字段。
图7c示出来自图7a的哪些字段构成寄存器索引字段。
图8是根据本发明的一个实施例的寄存器体系结构的框图。
图9a是示出根据本发明的各实施例的示例性有序流水线和示例性的寄存器重命名的无序发出/执行流水线的框图。
图9b是示出根据本发明的各实施例的要包括在处理器中的有序体系结构核的示例性实施例和示例性的寄存器重命名的无序发出/执行体系结构核的框图。
图10a-b示出了更具体的示例性有序核体系结构的框图,该核将是芯片中的若干逻辑块之一(包括相同类型和/或不同类型的其他核)。
图11是根据本发明实施例可具有一个以上的核、可具有集成存储器控制器以及可具有集成图形器件的处理器的框图。
图12是根据本发明的实施例的系统的框图。
图13是根据本发明的实施例的第一更具体的示例性系统的框图。
图14是根据本发明的实施例的第二更具体的示例性系统的框图。
图15是根据本发明的实施例的soc的框图。
图16是根据本发明的各实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。
详细描述
在下面的描述中,阐述了很多具体细节。然而,应当理解,本发明的各实施例可以在不具有这些具体细节的情况下得到实施。在其他实例中,公知的电路、结构和技术未被详细示出以免混淆对本描述的理解。
在说明书中对“一个实施例”、“一实施例”、“示例实施例”等的引用指示所描述的实施例可以包括特定特征、结构或特性,但并不一定每个实施例都需要包括该特定特征、结构或特性。此外,这样的短语不一定是指同一个实施例。此外,当结合一个影响例描述特定特征、结构或特性时,认为在本领域技术人员学识范围内,可以与其他影响例一起影响这样的特征、结构或特性,无论是否对此明确描述。
概览
在下面的描述中,在描述指令集体系结构中的此特定指令的操作之前,有某些项可能需要说明。一个这样的项被称为“写掩码寄存器”,它通常用于断言操作数以有条件地控制每个元素的计算操作(下文中,还使用术语掩码寄存器,且它指写掩码寄存器,诸如以下讨论的“k”寄存器)。如下面使用的,写掩码寄存器存储多个位(16,32,64等等),其中写掩码寄存器的每一有效位都在simd处理过程中控制向量寄存器的打包的数据元素的操作/更新。通常,有一个以上写掩码寄存器可供处理器核使用。
指令集体系结构包括指定向量操作并且具有从这些向量寄存器中选择源寄存器和/或目的地寄存器的字段的至少某些simd指令(示例性simd指令可以指定要对向量寄存器中的一个或多个的内容执行的向量操作,该向量操作的结果被存储在向量寄存器之一中)。本发明的不同的实施例可以具有不同尺寸的向量寄存器并支持多一些/少一些/不同尺寸的数据元素。
由simd指令指定的多位数据元素的尺寸(例如,字节、字、双字、四字)确定向量寄存器内“数据元素位置”的位定位,并且向量操作数的尺寸确定数据元素的数量。打包的数据元素是指存储在特定位置的数据。换言之,取决于目的地操作数中数据元素的尺寸以及目的地操作数的尺寸(目的地操作数中位的总数)(或换言之,取决于目的地操作数的尺寸和目的地操作数中数据元素的数量),所得到的向量操作数内多位数据元素位置的位定位(bitlocation)改变(例如,如果所得到的向量操作数的目的地是向量寄存器,则多位数据元素位置在目的地向量寄存器内的位定位改变)。例如,多位数据元素的位定位在对32位数据元素(数据元素位置0占用位定位31:0,数据元素位置1占用位定位63:32,依次类推)进行操作的向量操作和对64位数据元素(数据元素位置0占用位定位63:0,数据元素位置1占用位定位127:64,依次类推)进行操作的向量操作之间是不同的。
另外,如图6所示,根据本发明的一个实施例,在一个有效位向量写掩码元素的数量和向量尺寸和数据元素尺寸之间存在相关性。示出了128位、256位以及512位的向量尺寸,虽然其他宽度也是可能的。考虑了8位字节(b)、16位字(w)、32位双字(d)或单精度浮点,以及64位四倍字(q)或双精度浮点的数据元素尺寸,虽然其他宽度也是可能的。如所示,在向量尺寸是128位的情况下,当向量的数据元素尺寸是8位时可将16位用于掩蔽,当向量的数据元素尺寸是16位时可将8位用于掩蔽,当向量的数据元素尺寸是32位时可将4位用于掩蔽,当向量的数据元素尺寸是64位时可将2位用于掩蔽。在向量尺寸是256位的情况下,当打包数据元素宽度是8位时可将32位用于掩蔽,当向量的数据元素尺寸是16位时可将16位用于掩蔽,当向量的数据元素尺寸是32位时可将8位用于掩蔽,当向量的数据元素尺寸是64位时可将4位用于掩蔽。在向量尺寸是512位情况下,当向量的数据元素尺寸是8位时可将64位用于掩蔽,当向量的数据元素尺寸是16位时可将32位用于掩蔽,当向量的数据元素尺寸是32位时可将16位用于掩蔽,当向量的数据元素尺寸是64位时可将8位用于掩蔽。
取决于向量尺寸和数据元素尺寸的组合,无论所有64位,或只有64位的子集,均可以被用作写入掩码。一般而言,当使用单个每元素掩蔽控制位时,向量写掩码寄存器中用于掩蔽(有效位)的位数等于按位计的向量尺寸除以按位计的向量数据元素尺寸。
如上文所指出的,写掩码寄存器包含对应于向量寄存器(或存储器位置)中的元素的掩码位并跟踪应该对其执行操作的元素。因此,希望具有共同的操作,这些操作就向量寄存器而论在这些掩码位上复制类似的行为,一般而言,允许调整写掩码寄存器内的这些掩码位。
以下是通常称为写掩码位压缩(“kcompress”)指令的指令的实施例以及系统、体系结构、指令格式等的实施例,这些系统、体系结构和指令格式可被用于执行将在若干不同区域中有益的指令。kcompress指令的执行使得源写掩码寄存器的写掩码位中的至少一些被设置为“1”,以被写到目的地写掩码寄存器的最低有效位。
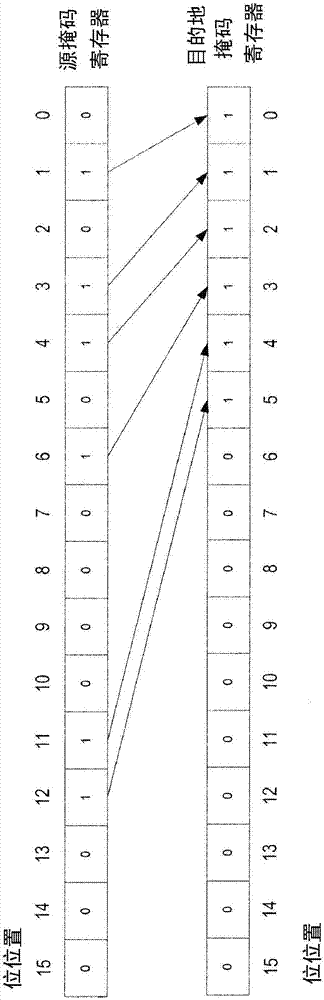
图1(a)例示了用于kcompress的示例性指令的操作的示例性例示。在所示示例中,这两个写掩码寄存器尺寸都是16位,具有16个写掩码位(每一个位位置表示一写掩码)。当然,可以使用不同的写掩码寄存器尺寸,如32或64位。
在该示例中,源写掩码寄存器的所有16个位被评估以压缩到目的地写掩码寄存器中。
如图所示,在源写掩码寄存器中,位位置1、3、4、6、11和12具有“1”值。这六个写掩码被压缩到目的地写掩码寄存器的六个最低有效位位置。
图1(b)例示了用于kcompress的示例性指令的操作的另一示例性例示。在所示示例中,这两个写掩码寄存器尺寸都是16位,具有16个写掩码位(每一个位位置表示一写掩码)。与图1(a)一样,可以使用不同的写掩码寄存器尺寸,如32和64位。然而,在该示例中,只评估源写掩码寄存器的8个最低有效位(有效位)来压缩到目的地写掩码寄存器。如图所示,虽然在源写掩码寄存器中,位位置1、3、4、6、7、11、12、14和15具有“1”值,但只有写掩码1、3、4、6和7被压缩到目的地写掩码寄存器的5个最低有效位位置。
如在以下示例性格式中详细描述的,要评估来压缩的位的数量可由与该指令相关联的操作码来确定。
示例性格式
这一指令的示例性格式是“kcompressdk1,k2”,其中k1和k2是写掩码寄存器且kcompressd是该指令的操作码。k2是目的地写掩码寄存器且k1是源掩码寄存器。这一指令的执行使得k2的被设为“1”的所有写掩码位被写到k1的最低有效位。
这一指令的示例性格式是“kcompressqk1,k2”,其中k1和k2是写掩码寄存器且kcompressq是该指令的操作码。k2是目的地写掩码寄存器且k1是源掩码寄存器。这一指令的执行只使得来自k2的8个最低有效写掩码位中设为“1”的写掩码位被写到k1的最低有效位。
图2示出了这一指令的格式的更详细实施例。
示例性执行方法
图3示出处理器中kcompress指令的使用的实施例。在301,取得具有目的地掩码寄存器操作数和源掩码寄存器操作数的kcompress指令。
在303,由解码逻辑解码kcompress指令。取决于指令的格式,在该级可解释各种数据,诸如如果有数据变换,则要写入和检索哪些寄存器、访问什么存储器地址等。在一些实施例中,这一解码取得要评估的掩码位的数量。
在305,检索/读取源操作数值。例如,读取源寄存器。
在307,kcompress指令(或包括诸如微操作等这样的指令的操作)由诸如一个或多个功能单元等执行资源执行,以确定源写掩码寄存器中设为“1”的写掩码位中的哪一些要被写入目的地写掩码寄存器的最低有效位。
在309,所标识的写掩码位被储存在目的地写掩码寄存器的最低有效位中。尽管分别地示出了307和309,但是在一些实施例中,它们是作为指令的执行的一部分一起执行的。
图4示出使用加法来处理kcompress指令的方法的实施例。在此实施例中,假设早先已经执行操作301-305中的某些,如果不是全部,然而,没有示出它们,以便不使下面呈现的细节模糊。例如,没有示出取回和解码,也没有示出操作数检索。在一些实施例中,在401,在基于源写掩码寄存器的任何压缩之前,目的地写掩码寄存器中的所有位被设为“0”。
在403,确定源写掩码寄存器的第一(最低有效)位位置是否被设为“1”。如果被设为“1”,则这指示写掩码已被置位并且应当被压缩到目的地写掩码寄存器。
如果该判断是否定的,则在405,确定源写掩码寄存器的相邻(次最低有效)位位置是否被设为“1”。再一次,如果被设为“1”,则这指示写掩码已被置位并且应当被压缩到目的地写掩码寄存器。
在以上判断中的任一个是肯定的时候,则在407,该“1”被写入目的地写掩码寄存器的其中尚未存储“1”的最低有效位位置中。
在将“1”写入目的地写掩码寄存器或步骤405的判断之后,在409,检查源写掩码寄存器的最后位位置是否已被评估。如上文详细描述的,要评估的位位置的数量可以取决于该指令的操作码而变化。在一些实施例中,不进行这一检查,直至源写掩码寄存器的8个位已被评估为止。
如果要评估的所有位位置已被评估,则该指令的操作完成。如果没有,则该方法在403继续,并且源写掩码寄存器的次最低有效位被评估。
当然,其他变型是可能的。例如,该指令的执行可以使得对于源写掩码寄存器中找到的每一个“1”,计数器值被维持。换言之,确定每一个位位置的值是什么并且对于找到的每一个“1”保持连续的记数。使用该计数器,目的地写掩码的计数器值数量的最低有效位将随后被设为“1”。
图5示出了这一指令的示例性伪码版本。
示例性指令格式
本文中所描述的指令的实施例可以不同的格式体现。另外,在下文中详述示例性系统、体系结构、以及流水线。指令的实施例可在这些系统、体系结构、以及流水线上执行,但是不限于详述的系统、体系结构、以及流水线。
vex指令格式
vex编码允许指令具有两个以上操作数,并且允许simd向量寄存器比128位长。vex前缀的使用提供了三个操作数(或者更多)的句法。例如,先前的两个操作数指令执行改写源操作数的操作(诸如a=a+b)。vex前缀的使用使操作数执行非破坏性操作,诸如a=b+c。
图7a示出示例性avx指令格式,包括vex前缀702、实操作码字段730、modr/m字节740、sib字节750、位移字段762、以及imm8772。图7b示出来自图7a的哪些字段构成完整操作码字段774和基础操作字段742。图7c示出来自图7a的哪些字段构成寄存器索引字段744。
vex前缀(字节0-2)702以三字节形式进行编码。第一字节是格式字段740(vex字节0,位[7:0]),该格式字段740包含明确的c4字节值(用于区分c4指令格式的唯一值)。第二-第三字节(vex字节1-2)包括提供专用能力的大量位字段。具体地,rex字段705(vex字节1,位[7-5])由vex.r位字段(vex字节1,位[7]–r)、vex.x位字段(vex字节1,位[6]–x)以及vex.b位字段(vex字节1,位[5]–b)组成。这些指令的其他字段对如在本领域中已知的寄存器索引的较低三个位(rrr、xxx以及bbb)进行编码,由此rrrr、xxxx以及bbbb可通过添加vex.r、vex.x以及vex.b来形成。操作码映射字段715(vex字节1,位[4:0]–mmmmm)包括对隐含的领先操作码字节进行编码的内容。w字段764(vex字节2,位[7]–w)由记号vex.w表示,并且取决于该指令提供了不同的功能。vex.vvvv720(vex字节2,位[6:3]-vvvv)的作用可包括如下:1)vex.vvvv对第一源寄存器操作数进行编码,该操作数指定为翻转(1的补码)的形式,且对具有两个或两个以上源操作数的指令有效;2)vex.vvvv目的地寄存器操作数进行编码,该操作数指定为针对特定向量移位的1的补码的形式;或者3)vex.vvvv不对任何操作数进行编码,保留该字段,并且应当包含1111b。如果vex.l768尺寸字段(vex字节2,位[2]-l)=0,则它指示128位向量;如果vex.l=1,则它指示256位向量。前缀编码字段725(vex字节2,位[1:0]-pp)提供了用于基础操作字段的附加位。
实操作码字段730(字节3)还被称为操作码字节。操作码的一部分在该字段中指定。
modr/m字段740(字节4)包括mod字段742(位[7-6])、reg字段744(位[5-3])、以及r/m字段746(位[2-0])。reg字段744的作用可包括如下:对目的地寄存器操作数或源寄存器操作数(rfff中的rrr)进行编码;或者被视为操作码扩展且不用于对任何指令操作数进行编码。r/m字段746的作用可包括如下:对引用存储器地址的指令操作数进行编码;或者对目的地寄存器操作数或源寄存器操作数中任一个进行编码。
缩放索引基址(sib)-缩放字段750(字节5)的内容包括用于存储器地址生成的ss752(位[7-6])。先前已经针对寄存器索引xxxx和bbbb提到了sib.xxx754(位[5-3])和sib.bbb756(位[2-0])的内容。
位移字段762和立即数字段(imm8)772包含地址数据。
示例性寄存器体系结构
图8是根据本发明的一个实施例的寄存器体系结构800的框图。在所示出的实施例中,有32个512位宽的向量寄存器810;这些寄存器被称为zmm0到zmm31。较低的16zmm寄存器的较低次序的256个位覆盖在寄存器ymm0-16上。较低的16zmm寄存器的较低次序的128个位(ymm寄存器的较低次序的128个位)覆盖在寄存器xmm0-15上。
写掩码寄存器815-在所示的实施例中,存在8个写掩码寄存器(k0至k7),每一写掩码寄存器的尺寸是64位。在替换实施例中,写掩码寄存器815的尺寸是16位。如先前所述的,在本发明的一个实施例中,向量掩码寄存器k0无法用作写掩码;当正常可指示k0的编码用作写掩码时,它选择硬连线的写掩码0xffff,从而有效地停用该指令的写掩码。
通用寄存器825——在所示出的实施例中,有十六个64位通用寄存器,这些寄存器与现有的x86寻址模式来寻址存储器操作数一起使用。这些寄存器通过名称rax、rbx、rcx、rdx、rbp、rsi、rdi、rsp以及r8到r15来引用。
标量浮点堆栈寄存器文件(x87堆栈)845,在其上面混叠mmx打包整型平坦寄存器文件850——在所示出的实施例中,x87堆栈是用于使用x87指令集扩展来对32/64/80位浮点数据执行标量浮点运算的八元素堆栈;而mmx寄存器被用来对64位打包整型数据执行操作,以及为在mmx和xmm寄存器之间执行的某些操作保存操作数。
本发明的替换实施例可以使用较宽的或较窄的寄存器。另外,本发明的替换实施例可以使用多一些,少一些或不同的寄存器文件和寄存器。
示例性核体系结构、处理器和计算机体系结构
处理器核可以用出于不同目的的不同方式在不同的处理器中实现。例如,这样的核的实现可以包括:1)旨在用于通用计算的通用有序核;2)旨在用于通用计算的高性能通用无序核;3)主要旨在用于图形和/或科学(吞吐量)计算的专用核。不同处理器的实现可包括:包括旨在用于通用计算的一个或多个通用有序核和/或旨在用于通用计算的一个或多个通用无序核的cpu;以及2)包括主要旨在用于图形和/或科学(吞吐量)的一个或多个专用核的协处理器。这样的不同处理器导致不同的计算机系统体系结构,其可包括:1)在与cpu分开的芯片上的协处理器;2)在与cpu同一封装中但在分开的管芯上的协处理器;3)与cpu在同一管芯上的协处理器(在该情况下,这样的协处理器有时被称为诸如集成图形和/或科学(吞吐量)逻辑等专用逻辑,或被称为专用核);以及4)可以将所描述的cpu(有时被称为应用核或应用处理器)、以上描述的协处理器和附加功能包括在同一管芯上的片上系统。接着描述示例性核体系结构,随后描述示例性处理器和计算机体系结构。
示例性核体系结构
有序和无序核框图
图9a是示出根据本发明的各实施例的示例性有序流水线和示例性的寄存器重命名的无序发出/执行流水线的框图。图9b是示出根据本发明的各实施例的要包括在处理器中的有序体系结构核的示例性实施例和示例性的寄存器重命名的无序发出/执行体系结构核的框图。图9a-b中的实线框示出了有序流水线和有序核,而虚线框中的可选附加项示出了寄存器重命名的、无序发出/执行流水线和核。给定有序方面是无序方面的子集的情况下,无序方面将被描述。
在图9a中,处理器流水线900包括取回级902、长度解码级904、解码级906、分配级908、重命名级910、调度(也称为分派或发出)级912、寄存器读取/存储器读取级914、执行级916、写回/存储器写入级918、异常处理级922和提交级924。
图9b示出了包括耦合到执行引擎单元950的前端单元930的处理器核990,且执行引擎单元和前端单元两者都耦合到存储器单元970。核990可以是精简指令集计算(risc)核、复杂指令集计算(cisc)核、非常长的指令字(vliw)核或混合或替换核类型。作为又一选项,核990可以是专用核,诸如例如网络或通信核、压缩引擎、协处理器核、通用计算图形处理器单元(gpgpu)核、或图形核等等。
前端单元930包括耦合到指令高速缓存单元934的分支预测单元932,该指令高速缓存单元934被耦合到指令转换后备缓冲器(tlb)936,该指令转换后备缓冲器936被耦合到指令取回单元938,指令取回单元938被耦合到解码单元940。解码单元940(或解码器)可解码指令,并生成从原始指令解码出的、或以其他方式反映原始指令的、或从原始指令导出的一个或多个微操作、微代码入口点、微指令、其他指令、或其他控制信号作为输出。解码单元940可使用各种不同的机制来实现。合适的机制的示例包括但不限于查找表、硬件实现、可编程逻辑阵列(ola)、微代码只读存储器(rom)等。在一个实施例中,核990包括存储(例如,在解码单元940中或否则在前端单元930内的)某些宏指令的微代码的微代码rom或其他介质。解码单元940耦合至执行引擎单元950中的重命名/分配器单元952。
执行引擎单元950包括重命名/分配器单元952,该重命名/分配器单元952耦合至隐退单元954和一个或多个调度器单元956的集合。调度器单元956表示任何数目的不同调度器,包括预留站、中央指令窗等。调度器单元956被耦合到物理寄存器文件单元958。每个物理寄存器文件单元958表示一个或多个物理寄存器文件,其中不同的物理寄存器文件存储一种或多种不同的数据类型,诸如标量整型、标量浮点、打包整型、打包浮点、向量整型、向量浮点、状态(例如,作为要执行的下一指令的地址的指令指针)等。在一个实施例中,物理寄存器文件单元958包括向量寄存器单元、写掩码寄存器单元和标量寄存器单元。这些寄存器单元可以提供体系结构向量寄存器、向量掩码寄存器、和通用寄存器。物理寄存器文件单元958与隐退单元954重叠以示出可以用来实现寄存器重命名和无序执行的各种方式(例如,使用重新排序缓冲器和隐退寄存器文件;使用将来的文件、历史缓冲器和隐退寄存器文件;使用寄存器映射和寄存器池等等)。隐退单元954和(物理寄存器文件单元958被耦合到执行群集960。执行群集960包括一个或多个执行单元962的集合和一个或多个存储器访问单元964的集合。执行单元962可以执行各种操作(例如,移位、加法、减法、乘法),以及对各种类型的数据(例如,标量浮点、打包整型、打包浮点、向量整型、向量浮点)执行。尽管某些实施例可以包括专用于特定功能或功能集合的多个执行单元,但其他实施例可仅包括均执行全部功能的一个执行单元或多个执行单元。调度器单元956、物理寄存器文件单元958和执行群集960被示为可能有多个,因为某些实施例为某些类型的数据/操作(例如,标量整型流水线、标量浮点/打包整型/打包浮点/向量整型/向量浮点流水线,和/或各自具有其自己的调度器单元、物理寄存器文件单元和/或执行群集的存储器访问流水线——以及在分开的存储器访问流水线的情况下,实现其中仅该流水线的执行群集具有存储器访问单元964的某些实施例)创建分开的流水线。还应当理解,在分开的流水线被使用的情况下,这些流水线中的一个或多个可以为无序发出/执行,并且其余流水线可以为有序发出/执行。
存储器访问单元964的集合被耦合到存储器单元970,该存储器单元970包括耦合到数据高速缓存单元974的数据tlb单元972,其中数据高速缓存单元974耦合到二级(l2)高速缓存单元976。在一个示例性实施例中,存储器访问单元964可包括加载单元、存储地址单元和存储数据单元,其中的每一个均耦合至存储器单元970中的数据tlb单元972。指令高速缓存单元934还耦合到存储器单元970中的二级(l2)高速缓存单元976。l2高速缓存单元976被耦合到一个或多个其他级的高速缓存,并最终耦合到主存储器。
作为示例,示例性寄存器重命名的、无序发出/执行核体系结构可以如下实现流水线900:1)指令取回938执行提取和长度解码级902和904;2)解码单元940执行解码级906;3)重命名/分配器单元952执行分配级908和重命名级910;4)调度器单元956执行调度级912;5)物理寄存器文件单元958和存储器单元970执行寄存器读取/存储器读取级914;执行群集960执行执行级916;6)存储器单元970和物理寄存器文件单元958执行写回/存储器写入级918;7)各单元可牵涉到异常处理级922;以及8)隐退单元954和物理寄存器文件单元958执行提交级924。
核990可支持一个或多个指令集(例如,x86指令集(具有随较新版本添加的某些扩展);加利福尼亚州桑尼维尔市的mips技术公司的mips指令集;加利福尼州桑尼维尔市的arm控股的arm指令集(具有诸如neon等可选附加扩展)),其中包括本文中描述的各指令。在一个实施例中,核990包括支持打包数据指令集扩展(例如,avx1、avx2)的逻辑,由此允许被许多多媒体应用使用的操作将使用打包数据来执行。
应当理解,核可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,此各种方式包括时分多线程化、同时多线程化(其中单个物理核为物理核正同时多线程化的各线程中的每一个线程提供逻辑核)、或其组合(例如,时分取回和解码以及此后诸如用
尽管在无序执行的上下文中描述了寄存器重命名,但应当理解,可以在有序体系结构中使用寄存器重命名。尽管所解说的处理器的实施例还包括分开的指令和数据高速缓存单元934/974以及共享l2高速缓存单元976,但替换实施例可以具有用于指令和数据两者的单个内部高速缓存,诸如例如一级(l1)内部高速缓存或多个级别的内部缓存。在某些实施例中,该系统可包括内部高速缓存和在核和/或处理器外部的外部高速缓存的组合。或者,所有高速缓存都可以在核和/或处理器的外部。
具体的示例性有序核体系结构
图10a-b示出了更具体的示例性有序核体系结构的框图,该核将是芯片中的若干逻辑块之一(包括相同类型和/或不同类型的其他核)。这些逻辑块取决于应用通过高带宽的互连网络(例如,环形网络)与某些固定的功能逻辑、存储器i/o接口和其它必要的i/o逻辑通信。
图10a是根据本发明的各实施例的单个处理器核连同它与管芯上互连网络1002的连接以及其二级(l2)高速缓存1004的本地子集的框图。在一个实施例中,指令解码器1000支持具有打包数据指令集扩展的x86指令集。l1高速缓存1006允许对标量和向量单元中的高速缓存存储器的低等待时间访问。尽管在一个实施例中(为了简化设计),标量单元1008和向量单元1010使用分开的寄存器集合(分别为标量寄存器1012和向量寄存器1014),并且在这些寄存器之间传输的数据被写入到存储器并随后从一级(l1)高速缓存1006读回,但是本发明的替换实施例可以使用不同的方法(例如使用单个寄存器集合或包括允许数据在这两个寄存器文件之间传输而无需被写入和读回的通信路径)。
l2高速缓存的本地子集1004是全局l2高速缓存的一部分,该全局l2高速缓存被划分成多个分开的本地子集,即每个处理器核一个本地子集。每个处理器核具有到其自己的l2高速缓存1004的本地子集的直接访问路径。被处理器核读出的数据被存储在其l2高速缓存子集1004中,并且可以被快速访问,该访问与其他处理器核访问其自己的本地l2高速缓存子集并行。被处理器核写入的数据被存储在其自己的l2高速缓存子集1004中,并在必要的情况下从其它子集清除。环形网络确保共享数据的相关性。环形网络是双向的,以允许诸如处理器核、l2高速缓存和其它逻辑块之类的代理在芯片内彼此通信。每个环形数据路径为每个方向1012位宽。
图10b是根据本发明的各实施例的图10a中的处理器核的一部分的展开图。图10b包括作为l1高速缓存1004的一部分的l1数据高速缓存1006a,以及关于向量单元1010和向量寄存器1014的更多细节。具体地说,向量单元1010是16位宽向量处理单元(vpu)(见16位宽alu1028),该单元执行整型、单精度浮点以及双精度浮点指令中的一个或多个。该vpu通过混合单元1020支持对寄存器输入的混合、通过数值转换单元1022a-b支持数值转换,并通过复制单元1024支持对存储器输入的复制。写掩码寄存器1026允许断言所得的向量写入。
具有集成存储器控制器和图形器件的处理器
图11是根据本发明的实施例的可具有一个以上核、可具有集成存储器控制器、并且可具有集成图形器件的处理器1100的框图。图11的实线框示出了处理器1100,处理器1100具有单个核1102a、系统代理1110、一组一个或多个总线控制器单元1116,而可选附加的虚线框示出了替换处理器1100,替换处理器1100具有多个核1102a-n、系统代理单元1110中的一组一个或多个集成存储器控制器单元1114以及专用逻辑1108。
因此,处理器1100的不同实现可包括:1)cpu,其中专用逻辑1108是集成图形和/或科学(吞吐量)逻辑(其可包括一个或多个核),并且核1102a-n是一个或多个通用核(例如,通用的有序核、通用的无序核、这两者的组合);2)协处理器,其中核1102a-n是主要旨在用于图形和/或科学(吞吐量)的大量专用核;以及3)协处理器,其中核1102a-n是大量通用有序核。因此,处理器1100可以是通用处理器、协处理器或专用处理器,诸如例如网络或通信处理器、压缩引擎、图形处理器、gpgpu(通用图形处理单元)、高吞吐量的集成众核(mic)协处理器(包括30个或更多核)、嵌入式处理器等。该处理器可以被实现在一个或多个芯片上。处理器1100可以使用诸如例如bicmos、cmos或nmos等的多个加工技术中的任何一个技术成为一个或多个衬底的一部分,和/或可以将其实现在一个或多个衬底上。
存储器层次结构包括在各核内的一个或多个级别的高速缓存、一个或多个共享高速缓存单元1106的集合、以及耦合至集成存储器控制器单元1114的集合的外部存储器(未示出)。该共享高速缓存单元1106的集合可以包括一个或多个中间级高速缓存,诸如二级(l2)、三级(l3)、四级(l4)或其他级别的高速缓存、末级高速缓存(llc)、和/或其组合。尽管在一个实施例中,基于环的互连单元1112将集成图形逻辑1108、共享高速缓存单元1106的集合以及系统代理单元1110/集成存储器控制器单元1114互连,但替换实施例可使用任何数量的公知技术来将这些单元互连。在一个实施例中,在一个或多个高速缓存单元1106与核1102a-n之间维持相关性。
在某些实施例中,核1102a-n中的一个或多个核能够多线程化。系统代理1110包括协调和操作核1102a-n的那些组件。系统代理单元1110可包括例如功率控制单元(pcu)和显示单元。pcu可以是或包括调整核1102a-n和集成图形逻辑1108的功率状态所需的逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
核1102a-n在体系结构指令集方面可以是同构的或异构的;即,这些核1102a-n中的两个或更多个核可能能够执行相同的指令集,而其他核可能能够执行该指令集的仅仅子集或不同的指令集。
示例性计算机体系结构
图12-15是示例性计算机体系结构的框图。本领域已知的对膝上型设备、台式机、手持pc、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般来说,能够纳入本文中所公开的处理器和/或其它执行逻辑的大量系统和电子设备一般都是合适的。
现在参考图12,示出了根据本发明的一个实施例的系统1200的框图。系统1200可以包括一个或多个处理器1210、1215,这些处理器耦合到控制器中枢1220。在一个实施例中,控制器中枢1220包括图形存储器控制器中枢(gmch)1290和输入/输出中枢(ioh)1250(其可以在分开的芯片上);gmch1290包括存储器1240和协处理器1245耦合到的存储器和图形控制器;ioh1250将输入/输出(i/o)设备1260耦合到gmch1290。替换地,存储器和图形控制器中的一个或两个在处理器(如本文中所描述的)内集成,存储器1240和协处理器1245直接耦合到处理器1210、以及具有ioh1250的单一芯片中的控制器中枢1220。
附加处理器1215的任选性质用虚线表示在图12中。每一处理器1210、1215可包括本文中描述的处理核中的一个或多个,并且可以是处理器1100的某一版本。
存储器1240可以是例如动态随机存取存储器(dram)、相变存储器(pcm)或这两者的组合。对于至少一个实施例,控制器集线器1220经由诸如前端总线(fsb)之类的多站总线(multi-dropbus)、诸如快速通道互连(qpi)之类的点对点接口、或者类似的连接1295与处理器1210、1215进行通信。
在一个实施例中,协处理器1245是专用处理器,诸如例如高吞吐量mic处理器、网络或通信处理器、压缩引擎、图形处理器、gpgpu、或嵌入式处理器等等。在一个实施例中,控制器中枢1220可以包括集成图形加速器。
按照包括体系结构、微体系结构、热、功耗特征等等优点的度量谱,物理资源1210、1215之间存在各种差别。
在一个实施例中,处理器1210执行控制一般类型的数据处理操作的指令。嵌入在这些指令中的可以是协处理器指令。处理器1210将这些协处理器指令识别为具有应当由附连的协处理器1245执行的类型。因此,处理器1210在协处理器总线或者其他互连上将这些协处理器指令(或者表示协处理器指令的控制信号)发出到协处理器1245。协处理器1245接受并执行所接收的协处理器指令。
现在参考图13,示出了根据本发明的一个实施例的第一更具体的示例性系统1300的框图。如图13所示,多处理器系统1300是点对点互连系统,并包括经由点对点互连1350耦合的第一处理器1370和第二处理器1380。处理器1370和1380中的每一个都可以是处理器1100的某一版本。在本发明的一个实施例中,处理器1370和1380分别是处理器1210和1215,而协处理器1338是协处理器1245。在另一实施例中,处理器1370和1380分别是处理器1210和协处理器1245。
处理器1370和1380被示为分别包括集成存储器控制器(imc)单元1372和1382。处理器1370还包括作为其总线控制器单元的一部分的点对点(p-p)接口1376和1378;类似地,第二处理器1380包括点对点接口1386和1388。处理器1370、1380可以使用点对点(p-p)电路1378、1388经由p-p接口1350来交换信息。如图13所示,imc1372和1382将各处理器耦合至相应的存储器,即存储器1332和存储器1334,这些存储器可以是本地附连至相应的处理器的主存储器的一部分。
处理器1370、1380可各自经由使用点对点接口电路1376、1394、1386、1398的各个p-p接口1352、1354与芯片组1390交换信息。芯片组1390可以可选地经由高性能接口1339与协处理器1338交换信息。在一个实施例中,协处理器1338是专用处理器,诸如例如高吞吐量mic处理器、网络或通信处理器、压缩引擎、图形处理器、gpgpu、或嵌入式处理器等等。
共享高速缓存(未示出)可以被包括在任一处理器之内或对两个处理器而言都在外部但仍经由p-p互连与这些处理器连接,从而如果将某处理器置于低功率模式时,可将任一处理器或两个处理器的本地高速缓存信息存储在该共享高速缓存中。
芯片组1390可经由接口1396耦合至第一总线1316。在一个实施例中,第一总线1316可以是外围部件互连(pci)总线,或诸如pciexpress总线或其它第三代i/o互连总线之类的总线,但本发明的范围并不受此限制。
如图13所示,各种i/o设备1314可以连同总线桥1318耦合到第一总线1316,总线桥1318将第一总线1316耦合至第二总线1320。在一个实施例中,诸如协处理器、高吞吐量mic处理器、gpgpu的处理器、加速器(诸如例如图形加速器或数字信号处理器(dsp)单元)、场可编程门阵列或任何其他处理器的一个或多个附加处理器1315被耦合到第一总线1316。在一个实施例中,第二总线1320可以是低引脚计数(lpc)总线。各种设备可以被耦合至第二总线1320,在一个实施例中这些设备包括例如键盘/鼠标1322、通信设备1327以及诸如可包括指令/代码和数据1330的盘驱动器或其它海量存储设备的存储单元1328。此外,音频i/o1324可以被耦合至第二总线1320。注意,其它体系结构是可能的。例如,代替图13的点对点体系结构,系统可以实现多站总线或其它这类体系结构。
现在参考图14,示出了根据本发明的一个实施例的第二更具体的示例性系统1400的框图。图13和图14中的相同元件用相同附图标记表示,并从图14中省去了图13中的某些方面,以避免使图14的其它方面模糊。
图14示出处理器1370、1380可分别包括集成存储器和i/o控制逻辑(“cl”)1372和1382。因此,cl1372、1382包括集成存储器控制器单元并包括i/o控制逻辑。图14示出不仅存储器1332、1334耦合至cl1372、1382的,而且i/o设备1414也耦合至控制逻辑1372、1382。传统i/o设备1415被耦合至芯片组1390。
现在参考图15,示出了根据本发明的一个实施例的soc1500的框图。在图11中,相似的元件具有同样的附图标记。另外,虚线框是更先进的soc的可选特征。在图15中,互连单元1502被耦合至:应用处理器1510,该应用处理器包括一个或多个核202a-n的集合以及共享高速缓存单元1106;系统代理单元1110;总线控制器单元1116;集成存储器控制器单元1114;一组或一个或多个协处理器1520,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(sram)单元1530;直接存储器存取(dma)单元1532;以及用于耦合至一个或多个外部显示器的显示单元1540。在一个实施例中,协处理器1520包括专用处理器,诸如例如网络或通信处理器、压缩引擎、gpgpu、高吞吐量mic处理器、或嵌入式处理器等等。
本文公开的机制的各实施例可以被实现在硬件、软件、固件或这些实现方法的组合中。本发明的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
可将程序代码(诸如图13中示出的代码1330)应用于输入指令,以执行本文描述的各功能并生成输出信息。输出信息可以按已知方式被应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有诸如例如数字信号处理器(dsp)、微控制器、专用集成电路(asic)或微处理器之类的处理器的任何系统。
程序代码可以用高级过程语言或面向对象的编程语言来实现,以便与处理系统通信。程序代码也可以在需要的情况下用汇编语言或机器语言来实现。事实上,本文中描述的机制不仅限于任何特定编程语言的范围。在任一情形下,语言可以是编译语言或解释语言。
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性指令来实现,该指令表示处理器中的各种逻辑,该指令在被机器读取时使得该机器制作用于执行本文所述的技术的逻辑。被称为“ip核”的这些表示可以被存储在有形的机器可读介质上,并被提供给各个客户或生产设施以加载到实际制造该逻辑或处理器的制造机器中。
这样的机器可读存储介质可以包括但不限于通过机器或设备制造或形成的物品的非瞬态、有形安排,其包括存储介质,诸如硬盘;任何其它类型的盘,包括软盘、光盘、紧致盘只读存储器(cd-rom)、紧致盘可重写(cd-rw)的以及磁光盘;半导体器件,例如只读存储器(rom)、诸如动态随机存取存储器(dram)和静态随机存取存储器(sram)的随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、闪存、电可擦除可编程只读存储器(eeprom);相变存储器(pcm);磁卡或光卡;或适于存储电子指令的任何其它类型的介质。
因此,本发明的各实施例还包括非瞬态、有形机器可读介质,该介质包含指令或包含设计数据,诸如硬件描述语言(hdl),它定义本文中描述的结构、电路、装置、处理器和/或系统特性。这些实施例也被称为程序产品。
仿真(包括二进制变换、代码变形等)
在某些情况下,指令转换器可用来将指令从源指令集转换至目标指令集。例如,指令转换器可以翻译(例如使用静态二进制翻译、包括动态编译的动态二进制翻译)、变形、仿真或以其它方式将指令转换成将由核来处理的一个或多个其它指令。指令转换器可以用软件、硬件、固件、或其组合实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上部分在处理器外。
图16是根据本发明的各实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。在所示的实施例中,指令转换器是软件指令转换器,但替换地,该指令转换器可以用软件、固件、硬件或其各种组合来实现。图16示出了用高级语言1602的程序可以使用x86编译器1604来编译,以生成可以由具有至少一个x86指令集核1616的处理器本机执行的x86二进制代码1606。具有至少一个x86指令集核1616的处理器表示任何处理器,这些处理器能通过兼容地执行或以其他方式处理以下内容来执行与具有至少一个x86指令集核的英特尔处理器基本相同的功能:1)英特尔x86指令集核的指令集的本质部分,或2)针对在具有至少一个x86指令集核的英特尔处理器上运行的应用或其它软件的目标代码版本,以便达到与具有至少一个x86指令集核的英特尔处理器基本相同的结果。x86编译器1604表示用于生成x86二进制代码1606(例如,目标代码)的编译器,该二进制代码1606可通过或不通过附加的链接处理在具有至少一个x86指令集核的处理器1616上执行。类似地,图16示出用高级语言1602的程序可以使用替换指令集编译器1608来编译,以生成可以由不具有至少一个x86指令集核的处理器1614(例如具有执行加利福尼亚州桑尼维尔市的mips技术公司的mips指令集,和/或执行加利福尼亚州桑尼维尔市的arm控股公司的arm指令集的核的处理器)在本机执行的替换指令集二进制代码1610。指令转换器1612被用来将x86二进制代码1606转换成可以由不具有x86指令集核1614的处理器本机执行的代码。该转换后的代码不大可能与替换指令集二进制代码1610相同,因为能够这样做的指令转换器难以制造;然而,转换后的代码将完成一般操作并由来自替换指令集的指令构成。因此,指令转换器1612表示通过仿真、模拟或任何其它过程来允许不具有x86指令集处理器或核的处理器或其它电子设备执行x86二进制代码1606的软件、固件、硬件或其组合。
- 还没有人留言评论。精彩留言会获得点赞!