一种数据处理方法和系统与流程
本发明涉及计算机领域,尤其涉及一种数据处理方法和系统。
背景技术:
目前,随着我国信息化建设不断深化,企业的信息化业务系统越来越依赖于信息通信系统,信息通信系统的安全性和可靠性将直接影响到企业数据信息的安全保密性;然而,数据资源中往往包含大量的敏感信息,一旦泄露或遭到非法利用,将会给个人甚至是国家带来无法弥补的损失。数据库通过用户、角色和权限技术保护数据的安全,但是由于现在大部分应用并没有充分利用数据库的这种保护机制,而是通过应用控制数据的访问,如应用操作人员虽然以不同的身份登录到应用,但都是通过一个数据库用户连接到数据库,这样虽然可以对通过应用访问数据库的用户进行存取访问限制,但无法控制直接通过数据库用户登录到数据库的数据存取。数据库管理员(databaseadministrator:dba)可以通过程序方式批量处理一些敏感数据达到保护敏感数据的目的,不仅操作繁琐复杂,而且现有计算机硬件以及破解软件的算法越来越先进,传统的脱敏算法会很容易被破解。一旦脱敏算法被破解,那么经过批量还原处理就可以获得真实数据,造成敏感数据的严重泄露。
随着大数据分析的成熟和价值挖掘的深入,从看似安全的数据中还原出用户的敏感、隐私信息已不再困难。传统的安全技术已无法直接使用,如何在大数据量的交换、共享及使用等过程中实现对敏感数据的精准定位和保护,达到数据安全、可靠、受控使用的目标,是数据产生者和管理者亟待解决的技术问题。
技术实现要素:
为解决现有技术中存在的问题,本发明提供一种数据处理方法和系统,旨在解决在大数据量的交换、共享及使用等过程中实现对敏感数据的精准定位和保护,达到数据安全、可靠、受控使用的目标。
本发明采用的技术方案为:
本发明的一个实施例提供一种数据处理方法,包括以下步骤:获取待处理的源数据;确定源数据中可以被用来识别数据主体的信息;确定所述用来识别数据主体的信息的类型;根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理;对处理后的数据进行验证。
可选地,所述数据处理方式包括:分别确定所述用来识别数据主体的信息中的各标识属性或敏感属性的数据的加密级别,根据确定的各标识属性或敏感属性的数据的加密级别确定相应的加密方法,以对各标识属性或敏感属性的数据进行加密。
可选地,所述数据处理方式包括:移除所述用来识别数据主体的信息中的直接标识符,移除所述用来识别数据主体的信息中所有记录的部分或所有其他标识属性,为所述用来识别数据主体的信息中的每一数据主体创建唯一标识符代替所述直接标识符。
可选地,根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理包括:确定重身份化风险阈值;确定源数据中可以被用来识别数据主体的信息,所述信息包括:直接标识符、准标识符和高维数据;确定所述信息中的所述直接标识符;直接移除所述直接标识符或者遮蔽所述直接标识符;根据可用于网络攻击的准标识符和非标识符数据值建立攻击模型;根据处理之后的所述源数据的应用场景确定最小可接受数据质量;转换所述准标识符。
可选地,所述准标识符包括数值型标识符、日期信息、地理位置信息,所述转换所述准标识符包括基于所述准标识符的类型属性采取相应的转换方式以使得攻击者无法从转换后的信息中识别关于所述主体的信息,其中,对于数值型标识符中的离群点的值,转换成大于或者小于特定值;对于数值型标识符中的连续属性,转换成通过预设方法计算的平均值;对于数值型标识符中的小数值数据,转换成组合数据;对于数值型标识符中具有高可识别性的特殊值,进行直接移除或者转换成估算值;对于数值型标识符中表征所述数据主体属性的数据记录,进行交换处理;对于日期信息中的日期,泛化到年份的维度或者使用其他日期进行替代;对于地理位置信息,采用加入距离噪声的方式进行模糊化处理。
可选地,所述对处理后的数据进行验证包括:对源数据和处理之后的数据统计计算,查看所述处理之后的数据是否包含标识信息,如果还包含标识信息则将所述处理之后的数据重新进行识别和处理直到不含标识信息,并确定所述处理之后的数据是否包含不可接受的更改,并确定是否可以用于预期目的。
本发明的另一实施例提供一种数据处理系统,其特征在于,包括:数据获取单元,用于获取待处理的源数据;第一数据识别单元,用于确定源数据中可以被用来识别数据主体的信息;第二数据识别单元,用于确定所述用来识别数据主体的信息的类型;数据处理单元,用于根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理;数据验证单元,用于对处理后的数据进行验证。
可选地,所述数据处理单元采用的数据处理方式包括:分别确定所述用来识别数据主体的信息中的各标识属性或敏感属性的数据的加密级别,根据确定的各标识属性或敏感属性的数据的加密级别确定相应的加密方法,以对各标识属性或敏感属性的数据进行加密。
可选地,所述数据处理单元采用的数据处理方式包括:移除所述用来识别数据主体的信息中的直接标识符,移除所述用来识别数据主体的信息中所有记录的部分或所有其他标识属性,为所述用来识别数据主体的信息中的每一数据主体创建唯一标识符代替所述直接标识符。
可选地,所述数据处理单元根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理包括:确定重身份化风险阈值;确定源数据中可以被用来识别数据主体的信息,所述信息包括:直接标识符、准标识符和高维数据;确定所述信息中的所述直接标识符;直接移除所述直接标识符或者遮蔽所述直接标识符;根据可用于网络攻击的准标识符和非标识符数据值建立攻击模型;根据处理之后的所述源数据的应用场景确定最小可接受数据质量;转换所述准标识符。
可选地,所述准标识符包括数值型标识符、日期信息、地理位置信息,所述转换所述准标识符包括基于所述准标识符的类型属性采取相应的转换方式以使得攻击者无法从转换后的信息中识别关于所述主体的信息,其中,对于数值型标识符中的离群点的值,转换成大于或者小于特定值;对于数值型标识符中的连续属性,转换成通过预设方法计算的平均值;对于数值型标识符中的小数值数据,转换成组合数据;对于数值型标识符中具有高可识别性的特殊值,进行直接移除或者转换成估算值;对于数值型标识符中表征所述数据主体属性的数据记录,进行交换处理;对于日期信息中的日期,泛化到年份的维度或者使用其他日期进行替代;对于地理位置信息,采用加入距离噪声的方式进行模糊化处理。
可选地,所述数据验证单元对处理后的数据进行验证包括:对源数据和处理之后的数据统计计算,查看所述处理之后的数据是否包含标识信息,如果还包含标识信息则将所述处理之后的数据重新进行识别和处理直到不含标识信息,并确定所述处理之后的数据是否包含不可接受的更改,并确定是否可以用于预期目的。
本发明将需要处理的源数据中可被用来识别数据主体的信息进行处理,并对处理后的数据进行验证,使得无法从处理后的源数据中识别出数据主体,有效地保护了数据主体的私有的、敏感的数据,提高数据的安全性。
附图说明
图1为本发明一实施例提供的数据处理方法的流程示意图。
图2为本发明一实施例的对识别数据主体的信息进行处理的流程示意图。
图3为本发明另一实施例提供的数据处理系统的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明一实施例提供的数据处理方法的流程示意图。如图所示,本发明的一实施例提供的数据处理方法包括以下步骤:
s101、获取待处理的源数据;
s102、确定源数据中可以被用来识别数据主体的信息;
s103、确定所述用来识别数据主体的信息的类型;
s104、根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理;
s105、对处理后的数据进行验证。
本发明提供的数据处理方法将需要处理的源数据中可被用来识别数据主体的信息进行处理,并对处理后的数据进行验证,使得无法从处理后的源数据中识别出数据主体,有效地保护了数据主体的隐私。
在本发明的一个实施例中,所述数据处理方式可包括:分别确定所述用来识别数据主体的信息中的各标识属性或敏感属性的数据的加密级别,根据确定的各标识属性或敏感属性的数据的加密级别确定相应的加密方法,以对各标识属性或敏感属性的数据进行加密。例如,最重要的数据的加密级别可以确定为一级,次重要的数据的加密级别确定为二级,依次类推。
在一个示意性实施例中,可采用保序加密、同态加密、保留格式加密等加密方法来进行加密。
保序加密是一种非随机对称加密形式,可利用加密值替代数据记录中的任何标识属性或敏感属性。保序加密比较适用于加密数值型和字符型数据。保序加密的特性是,采用统一私钥加密的两个值会保持各个值在密文中的排序。例如,如果两个值具有固定的排序,则相同排序会在加密的值中保持。保序加密可产生可搜索(实现范围匹配)与分析(对频率或分布的连续分析)的微数据,能够保持数据的有效性,实现有限的统计处理与有限的隐私保护数据挖掘,以及对数据的安全外包存储与处理。对保序加密数据的分析操作局限于等价检查与次序关系(如大于或小于)。保序加密数据的全部去标识化仅可能适用于拥有合适密钥的一方,关联性攻击的成功取决于对应用于属性的保序加密方案的参数选择。
同态加密是一种随机加密形式,可利用加密值替代数据记录中的任何标识属性或敏感属性。同态加密的特性是,采用相同公约加密的两个值可与加密方案的同态算法相结合,以产生代表去标识化值的运算结果的新密文。同态加密可实现对去标识化数据的有限处理,而无需对数据进行身份重标识。同态加密产生可在同态操作的限制范围内处理的微数据,可提供至少一种以上的安全运算,如对加密值的安全相加与相乘,无需对值进行解密,具有语义上的安全性,使得身份重标识攻击无法实现,无需具备访问合适的私钥的权限,能够保持数据的有效性,实现有限的统计处理与位有限的隐私保护数据挖掘,以及对数据的安全外包存储与处理。同态加密数据的完全身份重标识仅可能适用于拥有与用来加密数据的公约相匹配的私钥的一方。
保留格式加密适用于不必是二进制的数据。特别是,在给出任何有限符号集(如十进制数字符号)的情况下,保留格式加密的方法会转换具有符号顺序格式的数据,以致加密的数据形式(包括长度)具有与原始数据相同的格式。例如,一个经保留格式加密的9位社会保险号会是一系列9位十进制数字。保留格式加密有助于实现敏感信息的去标识化与假名化,同时对加密技术进行重构,以适应传统应用程序。
在本发明的一个实施例中,所述数据处理方式可包括:移除所述用来识别数据主体的信息中的直接标识符,移除所述用来识别数据主体的信息中所有记录的部分或所有其他标识属性,为所述用来识别数据主体的信息中的每一数据主体创建唯一标识符代替所述直接标识符。
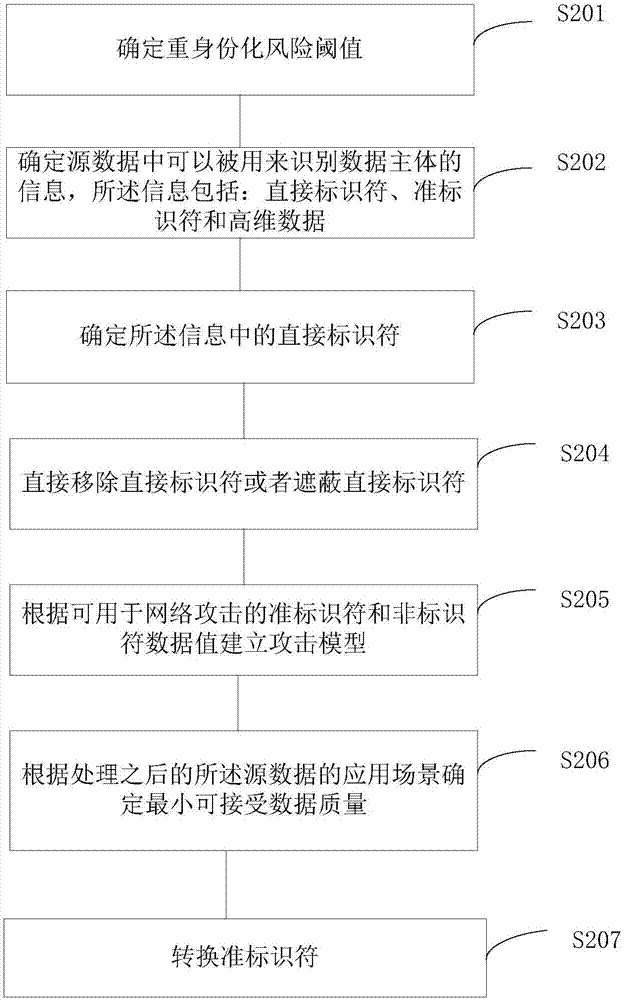
在本发明的一个实施例中,如图2所示,根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理可包括:
s201、确定重身份化风险阈值。
基于先验假设和相关标准,确定源数据可以承受的风险、可能的缓解措施。
s202、确定源数据中可以被用来识别数据主体的信息,所述信息包括:直接标识符、准标识符和高维数据。
其中,直接标识符包括姓名、电话号码以及其他可以准确识别个人的信息等。准标识符为链式攻击利用的对象,特别地,准标识符可以定位到多个群体,然后通过对群体的一定方式的转换又定位到特定个人。高维数据为可以用来筛选数据记录的数据,因此,可以用来构造独一无二的特征,一旦在二次链接中掌握这些特征数据,则它便成为了一个可识别的标记。
s203、确定所述信息中的直接标识符。
直接标识符可由专家来人为指定。
s204、直接移除直接标识符或者遮蔽直接标识符。
可采用如下方式来直接移除或者遮蔽直接标识符:
(1)直接移除或者用特殊字符来标记某个属性下的属性值空缺,例如用null或者na来标记。
(2)用重复的字符进行遮蔽,例如用xxxxx或者99999等字符进行遮蔽。
(3)加密。可采用各种加密技术,例如,保序加密、同态加密、保留格式加密等。加密以后,可将密钥来销毁掉,以防解密或者暴力攻击行为。但是,如果某些情况下需要在不同时间点进行相同的转化,则需要妥善保存密钥而不是将其销毁。
(4)用关键词代替,例如用“患者”代替“患者张三”。
(5)用其他实际值代替,例如用“张三”代替“李四”,如果在替代过程中,没有用同一个假名交叉代替不同的值,那么可以采用这种代替方法。
如果希望数据用来服务深度调查或者计划公开多个数据,那么转换的过程需要重复操作,以确保最终的转换结果是匿名的。直接标识符和匿名间的映射关系可以用一个可查询的表或者一个重复的转化模型来进行,并需要对查询表或者有关转化的信息高度保护起来。
s205、根据可用于网络攻击的准标识符和非标识符数据值建立攻击模型。
可由相关组织考量攻击者可能利用那些附加信息来达到重身份化的目的,包括准标识符和其他非标识的数据值,从而基于这些准标识符和非标识符数据建立攻击模型。
s206、根据处理之后的所述源数据的应用场景确定最小可接受数据质量。
相关组织确定对这些进行处理的数据可以应用在或者将会应用在什么样的场景中,然后基于此,确定最小可接受数据质量,即对源数据进行到何种程度的处理。
具体地,相关组织需要了解对数据进行处理的本质,并且需要确定相关政策和标准来决定不同情形下的数据可用性、数据处理和去身份化风险的不同可接受的程度级别,以对发布的数据的隐私、数据可用性和数据使用目标有一个明确的认知。例如,在一个示例中,可通过参考如下方式来进行:
(1)确定这些数据的来源;
(2)确认采集这些数据时做出过的承诺;
(3)了解相关法律规章对该类数据隐私和发布的要求;
(4)确定数据发布的目的;
(5)确认数据发布后的预计的用途;
(6)确定采用的数据共享模型;
(7)确认针对该数据采用的数据保护或者数据处理的标准;
(8)确认相关项目可以承受的风险级别;
(9)确定是否符合该级别的风险;
(10)确定限制重身份化的目标:达到只有少数人可以被重身份化、达到只有少数人在理论上可以被重身份化但是在实际中没有可以被重身份化、或者是达到被重身份化的概率很小。
(11)明确一旦重身份化会导致的后果以及确定采用什么样的技术手段来缓解此类的伤害。
s207、转换准标识符。
可基于准标识符的类型属性采取相应的转换方式以使得攻击者无法从转换后的信息中识别关于所述主体的信息,特别是包含日期和地理位置信息的那些数据,考量采用直接移除还是做标记的方法进行处理。日期可以是出身年月日,也可以是一个偶然的日期,也可以是具体的数字,例如距离1900年1月1日后的第几天。日期还可能是非结构化的文本数据来描述。日期也可能存在图像中,例如,图像表示的日历,包含日期信息的电脑屏幕图片。地理位置信息在数据集中的表现形式多种多样。地理位置可以通过地图坐标推断出来(例如,39.1351966,-77.2164013),可以通过街道地址(例如清华园10号)或者邮编(20899)推断出来,地理位置也可能引隐藏中文本数据中。一些地理位置是不可标识的,例如,一个拥挤的火车站,而另一些是高度可表示的,例如,一个单身汉居住的房子。其他一些情况就是有的位置在某些情况下可标识,在另一些情况下不可标识。单独的地址可能并不可标识,但是如果将它们标识的位置与个人相关联则会成为可标识的信息。
在一个示例中,准标识符可包括数值型标识符、日期信息、地理位置信息。
其中,对于数值型标识符中的离群点的值,转换成大于或者小于特定值。例如,对于年纪超过89岁的一律用“大于90岁”来描述。
对于数值型标识符中的连续属性,转换成通过预设方法计算的平均值。对于每种连续属性,或对于所选的一组连续属性,源数据中的所有记录都进行了分组,以致具有最近属性值的记录属于同一组,而且每一组中至少有k个记录。每一种属性的新值经过计算后成为该属性的值在该组中的平均值,每组中的各个值越接近,数据的有效性就保持的越好。
对于数值型标识符中的小数值数据,转换成组合数据。比如,在一些数据集中,包含小数值的数据可以用组合起来发布。例如,用“有四个人,他们分别是蓝色、绿色和浅褐色的眼睛”来代替“有1个人是蓝色眼睛,2个人是绿色的眼睛,1个人是浅褐色的眼睛”。
对于数值型标识符中具有高可识别性的特殊值,进行直接移除或者转换成估算值。
对于数值型标识符中表征所述数据主体属性的数据记录,进行交换处理。例如,在一个城市汇总不同乡镇下的两个家庭间的数据可以相互交换。“交换破坏了对某一个体的百分百的确定性的定位”的同时,在统计求和和求平均上又保证其正确性。例如,通过交换上述两个家庭的单元格的值,对于每个家庭中平均包含孩子的个数的统计不会因为数据的交换而有所改变。
对于日期信息中的日期,泛化到年份的维度或者使用其他日期进行替代。例如用1776年代替1776年7月4日,又例如,可以用1777年9月10日-9月15日代替1776年7月4日-7月9日。
对于地理位置信息,采用加入距离噪声的方式进行模糊化处理。例如,在中心范围内通过加减100m的范围,而偏远地区通过加减5km来得到充足的模糊化结果。一个既定的规则是,如果某种方法导致结果数据涵盖了多种人口密度,但是在其他准标识符上没能实现去标识化,那么它也是不可应用的。添加噪声时也要考虑噪声对数据真实性的影响。例如,讲一个居民的沿海住所搬迁到内陆甚至跨政治领域范畴的另一个国家,这种方式是不可取的。
具体地,对于数值型标识符,可采取如下方式进行处理:
(1)上下编码。离群点的值处理成大于或者小于一个特定值。例如,hipaa中对于年纪超过89岁的一律用“大于90岁”来描述。
(2)微聚集。微聚集是对单独的微数据进行分组,以保证各个维度上的统计特性,同时以一定程度上防止信息泄露。
(3)对于小数值数据的泛化。比如,在一些数据集中,包含小数值的数据可以用组合起来发布。例如,用“有四个人,他们分别是蓝色、绿色和浅褐色的眼睛”来代替“有1个人是蓝色眼睛,2个人是绿色的眼睛,1个人是浅褐色的眼睛”。
(4)数据抑制。事故表中的单元格的值如果比阈值要小,那么要么对它采取抑制,以防通过小数据联系将属性值涉及的个体推断出来。
(5)清除和估算。特殊数值往往具有高识别性,那么要么直接删除,要么用估值来代替。
(6)属性或记录的交换。在某种情况下,表征个体的数据记录和数据属性产生交换。例如,在一个城市汇总不同乡镇下的两个家庭间的数据可以相互交换。“交换破坏了对某一个体的百分百的确定性的定位”的同时,在统计求和和求平均上又保证其正确性。例如,通过交换上述两个家庭的单元格的值,对于每个家庭中平均包含孩子的个数的统计不会因为数据的交换而有所改变。
(7)噪声添加。又叫“部分合成数据”,是将随机的小数字加入到属性中。例如,称一个人年龄是79(噪声年龄)来代替其真实年龄84.噪声添加增加了数据的多样性,对回归系数和属性间的关系度的度量都会带来一定的负面影响。
对于日期信息,可采用如下方式进行处理:
(1)hipaa中规定,日期信息必须被泛化到年份的维度。例如用1776年代替1776年7月4日。
(2)涉及个人记录的日期要系统地加以泛化。例如,入院和出院日期,可以用相同间隔天数的日期加以替代,例如,可以用1777年9月10日-9月15日代替1776年7月4日-7月9日。
(3)除了以上的处理,针对时间间隔可以加以泛化,以防止时间间隔带来的重身份化的风险,同时要确保保持时间发生的有序性不被破坏。
(4)数据在改变时不可不考虑数据可用性。例如,天在一周中的位置要保证是工作日还是休息日,日节假日还是其他事件活动日。
(5)同样的,年龄数据的调整一些情况下不影响数据可用性,另一些情况则会影响。例如,个人年龄如果超过25岁可以微调上下2岁,大多数情况下不会影响数据可用性,但对于年龄只有1~3岁的情况将会造成较大影响。
对于地理位置信息,可采用扰动和泛化的方式来进行处理。扰动是对原数据中正确的数值做一些变换,比如加上一个随机量,而且当扰动做完后,要保证分析扰动数据的结果和原数据的结果一致。泛化是指从一个合适的范围内选择新值将原值替换,例如将日期随机替换为一年内的某一天。许多未经过处理的数据都包括用户的姓名、身份证号等,这些属性在公开前可以直接删除,也可以看作泛化的一种形式,即把范围当作无限大。
在对地理位置信息进行处理的过程中,采用的噪声数量很大程度上取决于外界因素。例如,在中心范围内通过加减100m的范围,而偏远地区通过加减5km来得到充足的模糊化结果。一个既定的规则是,如果某种方法导致结果数据涵盖了多种人口密度,但是在其他准标识符上没能实现去标识化,那么它也是不可应用的。添加噪声时也要考虑噪声对数据真实性的影响。例如,讲一个居民的沿海住所搬迁到内陆甚至跨政治领域范畴的另一个国家,这种方式是不可取的。
进一步地,对处理后的数据进行验证可包括:对源数据和处理之后的数据统计计算,查看所述处理之后的数据是否包含标识信息,如果还包含标识信息则将所述处理之后的数据重新进行识别和处理直到不含标识信息,并确定所述处理之后的数据是否包含不可接受的更改,并确定是否可以用于预期目的。如此,可有效地保护数据主体的隐私。
基于同一发明构思,本发明的实施例还提供了一种数据处理系统,由于该系统所解决问题的原理与前述数据处理方法相似,因此该系统的实施可以参见前述方法的实施,重复之处不再赘述。
本发明的实施例提供的一种数据处理系统,如图3所示,包括数据获取单元1、第一数据识别单元2、第二数据识别单元3、数据处理单元4和数据验证单元5。其中,数据获取单元1用于获取待处理的源数据;第一数据识别单元2用于确定源数据中可以被用来识别数据主体的信息;第二数据识别单元3用于确定所述用来识别数据主体的信息的类型;数据处理单元4用于根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理;数据验证单元5用于对处理后的数据进行验证。
在本发明的一实施例中,所述数据处理单元4采用的数据处理方式包括:分别确定所述用来识别数据主体的信息中的各标识属性或敏感属性的数据的加密级别,根据确定的各标识属性或敏感属性的数据的加密级别确定相应的加密方法,以对各标识属性或敏感属性的数据进行加密。
在本发明的一实施例中,所述数据处理单元4采用的数据处理方式包括:移除所述用来识别数据主体的信息中的直接标识符,移除所述用来识别数据主体的信息中所有记录的部分或所有其他标识属性,为所述用来识别数据主体的信息中的每一数据主体创建唯一标识符代替所述直接标识符。
在本发明的一实施例中,所述数据处理单元4根据所述用来识别数据主体的信息类型采用相应的处理方式来对所述信息进行处理包括:确定重身份化风险阈值;确定源数据中可以被用来识别数据主体的信息,所述信息包括:直接标识符、准标识符和高维数据;确定所述信息中的所述直接标识符;直接移除所述直接标识符或者遮蔽所述直接标识符;根据可用于网络攻击的准标识符和非标识符数据值建立攻击模型;根据处理之后的所述源数据的应用场景确定最小可接受数据质量;转换所述准标识符。
其中,所述准标识符包括数值型标识符、日期信息、地理位置信息,所述转换所述准标识符包括基于所述准标识符的类型属性采取相应的转换方式以使得攻击者无法从转换后的信息中识别关于所述主体的信息,其中,对于数值型标识符中的离群点的值,转换成大于或者小于特定值;对于数值型标识符中的连续属性,转换成通过预设方法计算的平均值;对于数值型标识符中的小数值数据,转换成组合数据;对于数值型标识符中具有高可识别性的特殊值,进行直接移除或者转换成估算值;对于数值型标识符中表征所述数据主体属性的数据记录,进行交换处理;对于日期信息中的日期,泛化到年份的维度或者使用其他日期进行替代;对于地理位置信息,采用加入距离噪声的方式进行模糊化处理。
在本发明的一实施例中,所述数据验证单元5对处理后的数据进行验证包括:对源数据和处理之后的数据统计计算,查看所述处理之后的数据是否包含标识信息,如果还包含标识信息则将所述处理之后的数据重新进行识别和处理直到不含标识信息,并确定所述处理之后的数据是否包含不可接受的更改,并确定是否可以用于预期目的。
上述各单元的功能可对应于图1和图2所示流程中的相应处理步骤,在此不再赘述。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以作出适当改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!