一种面向群智多模态数据的处理方法及系统与流程
本发明涉及群智数据筛选领域,特别涉及一种面向群智多模态数据的处理方法及系统。
背景技术:
近年来,随着社交媒体,如微博,twitter等为代表的社交网络的快速发展,网络上产生了越来越多的用户生成内容,用户生成内容可视为互联网时代中具有代表性的一类群智数据。社交媒体中的群智数据类型主要有文本、图像、视频、音频四大类,其中以文本和图像数据最为常见。由于社交媒体用户众多,平台开放性强,这导致来源于社交媒体的群智数据丰富却冗杂。目前,已有大量相关技术用于选择代表性的文本数据。
目前也有一部分的研究实现了跨模态数据的检索:专利cn105205096a提出了一种跨文本模态和图像模态的数据检索方法,该专利将文本模态数据和图像模态数据的语义向量作为逻辑斯特回归分类器的输出表达,将主亲和力非线性表达中心化后作为输入表达来进行训练,得到多个分类函数,当用户需要检索文本或者图像模态数据样本时,分别计算主亲和力并输入到所述分类函数中,得到文本或者图像模态数据样本的语义层表达,然后归一化处理生成最终表达,利用内积距离计算公式计算检索结果。专利cn103559192a公开了一种基于跨模态稀疏主题建模的跨媒体检索方法,利用联合分析及稀疏关联的方法提供跨模态数据在同一稀疏主题空间内的表示,进而进行跨模态信息检索。专利cn104462489a公开了一种基于深层模型的跨模态检索方法,通过堆叠对应的受限波尔兹曼机corr-rbms深层模型获得目标检索模态的高级表达向量和检索库中每一个被检索模态的高级表达向量,利用目标检索模态的高级表达向量和检索库中每一个被检索模态的高级表达向量计算目标检索模态与检索库中每一个被检索模态的距离以进行信息检索。
这些专利都只考虑了跨模态信息检索,并没有考虑基于跨模态数据关联的数据优选,获得的结果缺乏多样性。
技术实现要素:
本发明的目的是,为了克服现有的跨模态数据检索方法获得的结果缺乏多样性的技术缺陷,提供了一种面向群智多模态数据的处理方法及系统。
为实现上述目的,本发明提供了如下方案:
一种面向群智多模态数据的处理方法,包括如下步骤:
获取社交网络中用户生成内容作为群智数据;
根据群智数据中的文本数据提取文本特征;
根据群智数据中的图像数据提取图像特征;
基于提取的所述图像特征,对图像数据进行聚类;
基于提取的所述文本特征,对文本数据进行哈希编码,得到第一哈希编码;
基于提取的图像特征,对聚类后的每类图像数据的进行哈希编码,得到第二哈希编码;
对每一类图像数据,计算所述第一哈希编码与所述第二哈希编码的海明距离,选取海明距离最小的图像数据加入优选数据集合。
优选地,所述提取文本特征的步骤具体包括:对群智数据中的文本数据,利用lda(latentdirichletallocation)提取文本内容的话题分布作为特征向量,将lda中话题个数定为n,得到维数为n的特征向量,作为文本特征。
优选地,所述提取图像特征的步骤具体包括:
对于群智数据中的图像数据,利用sift(scaleinvariantfeaturetransform,尺度不变特征变换匹配算法)算法从图像中提取特征点;
使用k-means聚类算法对特征点进行聚类,得到词袋模型的单词表,将k-means的聚类个数定义为m,得到大小为m的单词表;
基于单词表对每一张图像计算其m维的tf-idf(termfrequency–inversedocumentfrequency)词向量作为图像特征。
优选的,所述对图像数据聚类的步骤具体包括:利用k-means聚类算法将图像数据聚为r类。
优选地,所述对文本数据进行哈希编码的步骤具体包括:基于提取的文本特征,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算文本数据的哈希编码,得到第一哈希编码。
优选地,所述对图像数据进行哈希编码的步骤具体包括:基于提取的图像特征,对每类图像数据,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算图像数据的哈希编码,得到第二哈希编码。
本发明还提供了一种面向群智多模态数据的处理系统,包括提取模块、聚类模块、哈希编码模块和选取模块;
所述提取模块,用于根据群智数据中的文本数据提取文本特征,并根据群智数据中的图像数据提取图像特征;
所述聚类模块,用于基于提取的所述图像特征,对图像数据进行聚类;
哈希编码模块,用于基于提取的所述文本特征,对文本数据进行哈希编码,得到第一哈希编码;并基于提取的图像特征,对聚类后的每类图像数据的进行哈希编码,得到第二哈希编码;
选取模块,用于对每一类图像数据,计算所述第一哈希编码与所述第二哈希编码的海明距离,选取海明距离最小的图像数据加入优选数据集合。
优选地,所述提取模块,用于对群智数据中的文本数据,利用lda提取文本内容的话题分布作为特征向量,将lda中话题个数定为n,得到维数为n的特征向量,作为文本特征,对于群智数据中的图像数据,利用sift算法从图像中提取特征点,使用k-means聚类算法对特征点进行聚类,得到词袋模型的单词表,将k-means的聚类个数定义为m,得到大小为m的单词表,并基于单词表对每一张图像计算其m维的tf-idf词向量作为图像特征。
优选地,所述聚类模块,用于利用k-means聚类算法将图像数据聚为r类。
优选地,所述哈希编码模块,用于基于提取的文本特征,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算文本数据的哈希编码,得到第一哈希编码,基于提取的图像特征,对每类图像数据,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算图像数据的哈希编码,得到第二哈希编码。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
发明公开了一种面向群智多模态数据的处理方法及系统,基于跨模态数据的关联进行数据优选,根据群智数据中的代表性文本数据,结合聚类及跨模态数据关联的方法,对群智数据中的图像数据进行优选,在保证数据语义相关性的同时还提高了数据的多样性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种面向群智多模态数据的处理方法的一个实施例的流程图。
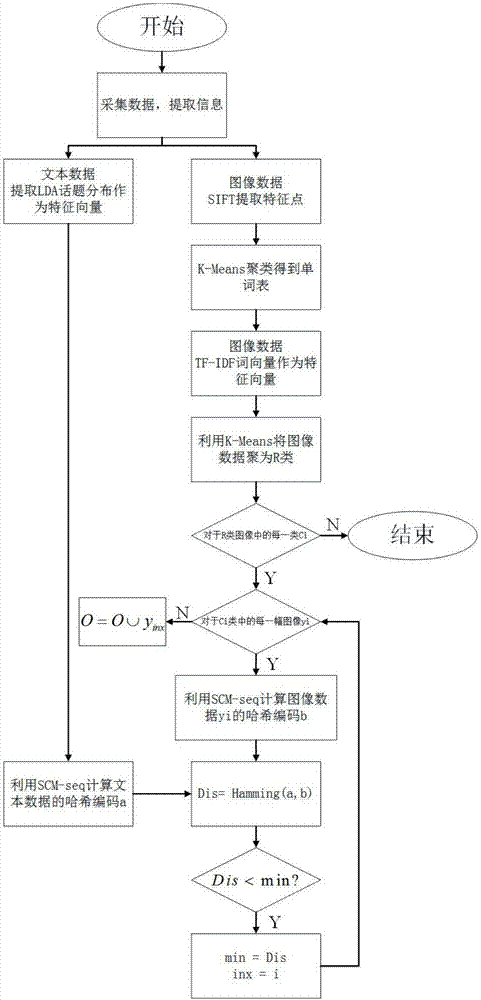
图2为本发明提供的一种面向群智多模态数据的处理方法的另一个实施例的流程图。
图3为本发明提供的一种面向群智多模态数据的处理系统的结构框图。
具体实施方式
本发明的目的是提供一种面向群智多模态数据的处理方法及系统。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,作为一种可实施方式,一种面向群智多模态数据的处理方法,包括如下步骤:
s1、获取社交网络中用户生成内容作为群智数据;
s2、根据群智数据中的文本数据提取文本特征;
s3、根据群智数据中的图像数据提取图像特征;
s4、基于提取的所述图像特征,对图像数据进行聚类;
s5、基于提取的所述文本特征,对文本数据进行哈希编码,得到第一哈希编码;
s6、基于提取的图像特征,对聚类后的每类图像数据的进行哈希编码,得到第二哈希编码;
s7、对每一类图像数据,计算所述第一哈希编码与所述第二哈希编码的海明距离,选取海明距离最小的图像数据加入优选数据集合。
如图2所示,优选地,作为一种可实施方式,步骤s2所述的提取文本特征的步骤具体包括:对群智数据中的文本数据,利用lda提取文本内容的话题分布作为特征向量,将lda中话题个数定为n,得到维数为n的特征向量,作为文本特征,优选地,将lda中话题个数定为10。
步骤s3所述的提取图像特征的步骤具体包括:
对于群智数据中的图像数据,利用sift算法从图像中提取特征点;
使用k-means聚类算法对特征点进行聚类,得到词袋模型的单词表,将k-means的聚类个数定义为m,得到大小为m的单词表,优选地,将k-means的聚类个数定义为128;
基于单词表对每一张图像计算其m维的tf-idf词向量作为图像特征。
步骤s4所述的对图像数据聚类的步骤具体包括:利用k-means聚类算法将图像数据聚为r类,优选地,将图像数据聚类为3类。
步骤s5所述的对文本数据进行哈希编码的的步骤具体包括:基于提取的文本特征,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算文本数据的哈希编码,得到第一哈希编码,优选地,经过哈希映射后得到的第一哈希编码为8位数据编码,具体为11000101。
步骤s6所述的对图像数据进行哈希编码的步骤具体包括:基于提取的图像特征,对每类图像数据,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算图像数据的哈希编码,得到第二哈希编码,优选地,经过哈希映射后得到的第二哈希编码为8位数据编码,具体的3类图像数据集合的哈希编码分别为:{a=11111110,b=11010101},
{c=11101110,e=00001010,f=10100010},
{g=10101010,h=11101010,l=11100000}。
步骤s7所述的获取优选数据集合的步骤具体包括:对于r类图像中每一类图像集合ci,对于图像集合ci中的每一张图像yi,计算图像yi的哈希编码(第二哈希编码)与文本数据哈希编码(第一哈希编码)的海明距离,选择图像集合ci中与文本数据哈希编码海明距离最小的图像加入优选图像集合,最终可得到r张优选图像,优选地,最终的优选图像数据集合为{b,c,l}。
如图3所示,一种面向群智多模态数据的处理系统,包括提取模块1、聚类模块2、哈希编码模块3和选取模块4;
所述提取模块1,用于根据群智数据中的文本数据提取文本特征,并根据群智数据中的图像数据提取图像特征;
所述聚类模块2,用于基于提取的所述图像特征,对图像数据进行聚类;
哈希编码模块3,用于基于提取的所述文本特征,对文本数据进行哈希编码,得到第一哈希编码;并基于提取的图像特征,对聚类后的每类图像数据的进行哈希编码,得到第二哈希编码;
选取模块4,用于对每一类图像数据,计算所述第一哈希编码与所述第二哈希编码的海明距离,选取海明距离最小的图像数据加入优选数据集合。
优选地,所述提取模块1,用于对群智数据中的文本数据,利用lda提取文本内容的话题分布作为特征向量,将lda中话题个数定为n,得到维数为n的特征向量,作为文本特征,对于群智数据中的图像数据,利用sift算法从图像中提取特征点,使用k-means聚类算法对特征点进行聚类,得到词袋模型的单词表,将k-means的聚类个数定义为m,得到大小为m的单词表,并基于单词表对每一张图像计算其m维的tf-idf词向量作为图像特征。
优选地,所述聚类模块2,用于利用k-means聚类算法将图像数据聚为r类。
优选地,所述哈希编码模块3,用于基于提取的文本特征,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算文本数据的哈希编码,得到第一哈希编码,基于提取的图像特征,对每类图像数据,利用跨模态哈希学习算法scm-seq,采用哈希映射的方式,计算图像数据的哈希编码,得到第二哈希编码。
本文中应用了具体个例对发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!