一种面向初等数学领域的命名识别方法及其系统与流程
本发明涉及自然语言处理领域,具体涉及一种面向初等数学领域的命名识别方法及其系统。
背景技术:
随着人工智能的发展和推理技术的深化,自动推理技术得到了有效的应用,同时相关的理论、技术、方法也得到了很大的发展,自动推理在数学方面的应用也更加的广泛深入。
在利用自动推理推理数学方面的问题时,往往有许多的信息不能有效的识别或者识别效率很低。
初等数学的命名识别是一个自动解题系统中的重要一环,它涉及到前端的自然语言处理,一段数学文本信息,提取出文本中的数学方面的信息是最重要的一环,当前自然语言对于初等数学方面的理解并不准确,因此需要一种有效的系统能够准确地识别初等数学里面的各种数学信息,以及隐含的更深一层次的信息。
技术实现要素:
基于此,针对上述问题,有必要提出一种面向初等数学领域的命名识别方法及其系统,本发明可以有效的提取文本中关于数学方面的信息,识别准确、效率高。
本发明提供一种面向初等数学领域的命名识别方法,其技术方案是:
一种面向初等数学领域的命名识别方法,包括如下步骤:
s1、确定一个待识别的数学文本信息,并进行预处理,将其逐字按列排列;
s2、提取步骤s1中已经进行过分词预处理的文字,标注当前文字在词中的位置;
s3、标注完成当前文字在词中的位置后,对当前的分词进行词性标注;
s4、得到词性标注的结果后,判断标注结果是否正确,如果正确,则标注成功;如果不正确,则重新进入步骤s1,并对其文本信息进行重新训练标注。
针对一段数学文本信息,对其进行分词、标注、将文本中的数学信息提取出来,得到实体之间的关系;如此,才能进行接下来的操作。
在本发明中首先确定一个待识别的数学文本信息,将数学文本信息按字逐行排列,然后进行分词操作,分词操作具体为:给定一个字的序列,找出最可能的标签序列,将数学文本按字逐行展开后,对于每个字进行位置标注,即表示该字在词中的位置,例如:该字在词的词首、词中间抑或是在词尾的位置,相应的表示方法为b(开头),m(中间),e(结尾),s(独立成词);随后进行词性标注,词性是词汇基本的语法属性,通常也称为词类,词性标注是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程,标注该词的词性,表示该词是动词、名词或是其他的连接词等等;并且进行命名实体识别,即给定一个词的序列,找出最可能的标签序列,识别出文本中对于数学理解具有特定意义的实体,例如:函数、几何、或者数列等等诸多有效的信息;用于命名实体识别的机器学习方法有隐马尔可夫模型和最大熵模型;最后判定标注结果是否正确,如果正确,则可进行其他操作;如果不正确,则进行重新训练标注。
本发明的面向初等数学领域的命名识别方法可以有效的提取文本中关于数学方面的信息,识别准确、效率高。
作为上述方案的进一步优化,所述步骤s2具体包括以下步骤:
提取文字后,对每个文字进行位置标注,如果该文字在词的词首,则标注为b;如果该文字在词的中间,则标注为m;如果该文字在词的末尾,则标注为e;如果该文字独立成词,则标注为s。
词与词之间没有空格之类的标注来显示指示词的边界,因此,自动分词成了文本处理的首要基础性工作,本发明采取基于统计的方法和规则的方法(基于词表)二者相结合,将文本中的数学信息提取出来,使文本信息中文字的位置清晰、完整的呈现出来,提高了识别初等数学里面的各种数学信息的准确度。
作为上述方案的进一步优化,在步骤s2中采用4-tag标注法标注当前文字在词中的位置。进一步提高了分词标注的准确性,其标注方法更可靠、高效。
作为上述方案的更进一步优化,所述步骤s3具体包括以下步骤:
判断待识别的数学文本信息中每个词的语法范畴,确定其词性并加以标注,如果该词是动词,则标注为v;如果该词是名词,则标注为n;如果该词是连接词,则标注为nd;如果该词是字母,则标注为ws;如果该词是符号,则标注为wp。用于在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程,标注该词的词性,表示该词是动词、名词或是其他的连接词等等;不像英文中的命名实体具有明显的大写标志,中文的命名实体的识别更加困难,因此中文的尤其是针对初等数学的词性标注更加复杂,其词性标注详细,便于分辨,提高了对数学信息的识别准确性,同时提高了识别效率。
本发明还提供一种面向初等数学领域的命名识别系统,其技术方案是:
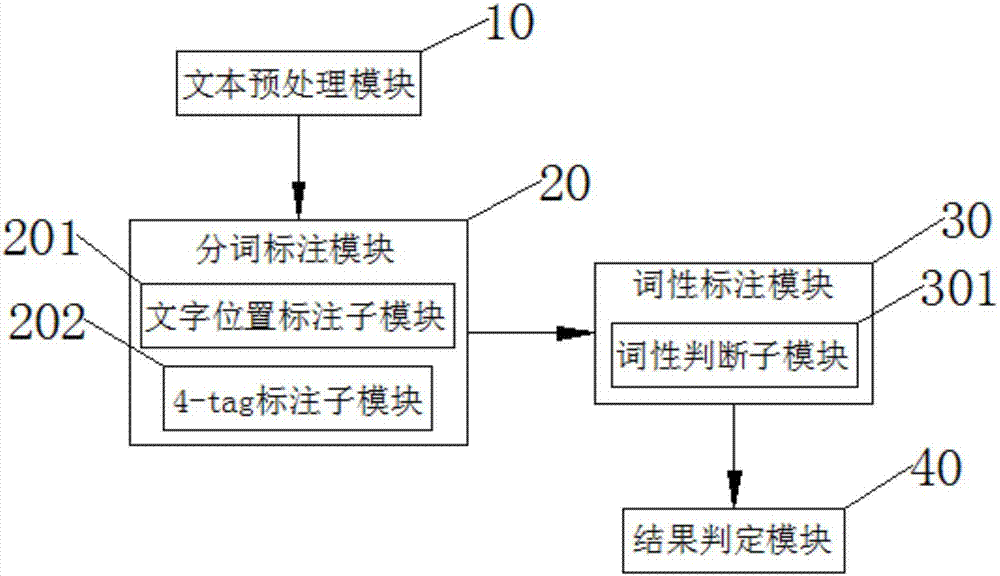
一种面向初等数学领域的命名识别系统,包括文本预处理模块、分词标注模块、词性标注模块和结果判定模块,其中:
文本预处理模块,用于确定一个待识别的数学文本信息,并进行预处理,将其逐字按列排列;
分词标注模块,用于提取已经进行过分词预处理的文字,标注当前文字在词中的位置;
词性标注模块,用于标注完成当前文字在词中的位置后,对当前的分词进行词性标注;
结果判定模块,用于得到词性标注的结果后,判断标注结果是否正确,如果正确,则标注成功;如果不正确,则重新对文本信息进行重新训练标注。
作为上述方案的进一步优化,所述分词标注模块包括文字位置标注子模块,用于对每个文字进行位置标注,如果该文字在词的词首,则标注为b;如果该文字在词的中间,则标注为m;如果该文字在词的末尾,则标注为e;如果该文字独立成词,则标注为s。
作为上述方案的进一步优化,所述分词标注模块还包括4-tag标注子模块,用于采用4-tag标注法标注当前文字在词中的位置。
作为上述方案的更进一步优化,所述词性标注模块包括词性判断子模块,用于判断待识别的数学文本信息中每个词的语法范畴,确定其词性并加以标注,如果该词是动词,则标注为v;如果该词是名词,则标注为n;如果该词是连接词,则标注为nd;如果该词是字母,则标注为ws;如果该词是符号,则标注为wp。
本发明的有益效果是:
1、本发明的面向初等数学领域的命名识别方法可以有效的提取文本中关于数学方面的信息,其识别准确、效率高。
2、词与词之间没有空格之类的标注来显示指示词的边界,因此,自动分词成了文本处理的首要基础性工作,本发明采取基于统计的方法和规则的方法(基于词表)二者相结合,将文本中的数学信息提取出来,使文本信息中文字的位置清晰、完整的呈现出来,提高了识别初等数学里面的各种数学信息的准确度。
3、对于待识别的数学文本信息中每个词的语法范畴进行判定,确定其词性并加以标注,表示该词是动词、名词或是其他的连接词等等;其词性标注详细,便于分辨,提高了对数学信息的识别准确性,同时提高了识别效率。
附图说明
图1是本发明实施例所述面向初等数学领域的命名识别方法的流程图;
图2是本发明实施例所述面向初等数学领域的命名识别系统的原理框图。
附图标记说明:
10-文本预处理模块;20-分词标注模块;201-文字位置标注子模块;202-4-tag标注子模块;30-词性标注模块;301-词性判断子模块;40-结果判定模块。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
实施例1
如图1所示,一种面向初等数学领域的命名识别方法,包括如下步骤:
s1、确定一个待识别的数学文本信息,并进行预处理,将其逐字按列排列;
s2、提取步骤s1中已经进行过分词预处理的文字,标注当前文字在词中的位置;
s3、标注完成当前文字在词中的位置后,对当前的分词进行词性标注;
s4、得到词性标注的结果后,判断标注结果是否正确,如果正确,则标注成功;如果不正确,则重新进入步骤s1,并对其文本信息进行重新训练标注。
针对一段数学文本信息,对其进行分词、标注、将文本中的数学信息提取出来,得到实体之间的关系;如此,才能进行接下来的操作。
在本发明中首先确定一个待识别的数学文本信息,将数学文本信息按字逐行排列,然后进行分词操作,分词操作具体为:给定一个字的序列,找出最可能的标签序列,将数学文本按字逐行展开后,对于每个字进行位置标注,即表示该字在词中的位置,例如:该字在词的词首、词中间抑或是在词尾的位置,相应的表示方法为b(开头),m(中间),e(结尾),s(独立成词);随后进行词性标注,词性是词汇基本的语法属性,通常也称为词类,词性标注是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程,标注该词的词性,表示该词是动词、名词或是其他的连接词等等;并且进行命名实体识别,即给定一个词的序列,找出最可能的标签序列,识别出文本中对于数学理解具有特定意义的实体,例如:函数、几何、或者数列等等诸多有效的信息;用于命名实体识别的机器学习方法有隐马尔可夫模型和最大熵模型;最后判定标注结果是否正确,如果正确,则可进行其他操作;如果不正确,则进行重新训练标注;以下为具体命名实例:
在梯形abcd中,ab//cd,对角线ac⊥bd,ad=cb,bd=6cm,求梯形abcd面积。
如上表,以上四列表示一个完整的初等数学的命名和识别的过程;第一列首先将题目信息进行预处理,将文本按字逐行展开,然后分词,本发明中采用4-tag技术,标注出其在词中的位置;第二列中则代表分词结果,例如:s代表独立词语,b代表词语的开始,m代表词的中间,e代表词的结尾;第三列进行词性标注,例如:b-n为名词的开头,e-n代表名词的结尾,b-ws代表字符串的开始,m-ws代表字符串的中间,e-ws代表字符串的结尾,整个b-ws、m-ws、e-ws代表一个完整的字符串词性;最后第四列为词性标注的结果,例如:b_quadrangle代表四边形实体的开始,四边形实体的其他部分用i_quadrangle表示,同样的b_line表示一条直线实体的开始,i_line则表示直线实体的其他部分,o表示对于该词不进行词性标注;对词性标注以后就可以对该段数学文本进行下一步的处理。
本发明的面向初等数学领域的命名识别方法可以有效的提取文本中关于数学方面的信息,识别准确、效率高。
实施例2
本实施例在实施例1的基础上,所述步骤s2具体包括以下步骤:
提取文字后,对每个文字进行位置标注,如果该文字在词的词首,则标注为b;如果该文字在词的中间,则标注为m;如果该文字在词的末尾,则标注为e;如果该文字独立成词,则标注为s。
词与词之间没有空格之类的标注来显示指示词的边界,因此,自动分词成了文本处理的首要基础性工作,本发明采取基于统计的方法和规则的方法(基于词表)二者相结合,将文本中的数学信息提取出来,使文本信息中文字的位置清晰、完整的呈现出来,提高了识别初等数学里面的各种数学信息的准确度。
实施例3
本实施例在实施例2的基础上,在步骤s2中采用4-tag标注法标注当前文字在词中的位置。进一步提高了分词标注的准确性,其标注方法更可靠、高效。
实施例4
本实施例在实施例1的基础上,所述步骤s3具体包括以下步骤:
判断待识别的数学文本信息中每个词的语法范畴,确定其词性并加以标注,如果该词是动词,则标注为v;如果该词是名词,则标注为n;如果该词是连接词,则标注为nd;如果该词是字母,则标注为ws;如果该词是符号,则标注为wp。用于在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程,标注该词的词性,表示该词是动词、名词或是其他的连接词等等;不像英文中的命名实体具有明显的大写标志,中文的命名实体的识别更加困难,因此中文的尤其是针对初等数学的词性标注更加复杂,其词性标注详细,便于分辨,提高了对数学信息的识别准确性,同时提高了识别效率。
实施例5
本实施例为实施例1的系统,
一种面向初等数学领域的命名识别系统,包括文本预处理模块10、分词标注模块20、词性标注模块30和结果判定模块40,其中:
文本预处理模块10,用于确定一个待识别的数学文本信息,并进行预处理,将其逐字按列排列;
分词标注模块20,用于提取已经进行过分词预处理的文字,标注当前文字在词中的位置;
词性标注模块30,用于标注完成当前文字在词中的位置后,对当前的分词进行词性标注;
结果判定模块40,用于得到词性标注的结果后,判断标注结果是否正确,如果正确,则标注成功;如果不正确,则重新对文本信息进行重新训练标注。
实施例6
本实施例是实施例2的系统,其在实施例5的基础上,
所述分词标注模块20包括文字位置标注子模块201,用于对每个文字进行位置标注,如果该文字在词的词首,则标注为b;如果该文字在词的中间,则标注为m;如果该文字在词的末尾,则标注为e;如果该文字独立成词,则标注为s。
实施例7
本实施例是实施例3的系统,其在实施例6的基础上,
所述分词标注模块20还包括4-tag标注子模块202,用于采用4-tag标注法标注当前文字在词中的位置。
实施例8
本实施例是实施例4的系统,其在实施例5的基础上,
所述词性标注模块30包括词性判断子模块301,用于判断待识别的数学文本信息中每个词的语法范畴,确定其词性并加以标注,如果该词是动词,则标注为v;如果该词是名词,则标注为n;如果该词是连接词,则标注为nd;如果该词是字母,则标注为ws;如果该词是符号,则标注为wp。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!