基于常规因子的个性化疾病风险等级分析方法与流程
本发明涉及疾病风险分析技术领域,更具体地,涉及一种基于常规因子的个性化疾病风险等级分析方法。
背景技术:
随着社会经济的发展,人们的膳食结构和生活习惯发生了巨大的改变,人们对疾病及健康问题也越来越重视。
根据世界卫生组织的研究报告,人类1/3的疾病能通过预防保健得以避免,1/3的疾病早期发现可以得到有效控制,1/3的疾病通过有效沟通可以提高治疗效果。对于疾病,治疗不是唯一的途径,通过健康管理有效预防、控制疾病并提升疾病治疗的效率才是人类健康的根本。
对于疾病预防来说,对疾病的风险评估是疾病预防的重要手段,但是,现有的疾病风险评估方法,通常是对某些特定人群患某项或某些疾病给出较其他人群具有高风险的评估结论,但是对个人的疾病风险评估并不准确,也不能实时的调整疾病风险评估的结论,即:现有的疾病风险评估方法个性化和实时性较差。
因此,针对上述问题,本发明提出了一种基于常规因子的个性化疾病风险等级分析方法,具有较高的个性化和实时性。
技术实现要素:
有鉴于此,本发明提供了一种基于常规因子的个性化疾病风险等级分析方法,具有较高的个性化和实时性,且准确率更高。
为了解决上述技术问题,本发明有如下技术方案:一种基于常规因子的个性化疾病风险等级分析方法,包括:
根据医学信息和大数据信息,建立常规因子逻辑表,所述常规因子逻辑表,包括:疾病名称、常规因子和所述常规因子的阈值,将一种所述疾病名称与至少一种常规因子进行关联,所述直接关联分为直接1级关联、直接2级关联和直接3级关联,所述间接关联分为间接1级关联、间接2级关联和间接3级关联,且1级关联的关联等级高于二级关联的关联等级高于三级关联的关联等级;
其中,所述常规因子逻辑表根据所述医学信息和/或所述大数据信息的更新进行实时调整;
获取个人信息,所述个人信息,包括:所述常规因子和所述常规因子临床值和/或主诉值,其中,所述临床值优于所述主诉值作为所述常规因子的实际值;
将所述个人信息与所述常规因子逻辑表进行对比,筛选出所述实际值偏离所述阈值的所述常规因子作为个性化因子,按照与所述疾病名称直接关联大于与所述疾病名称间接关联、高级关联大于低级关联以及所述实际值偏离所述阈值越多则权值越大的原则,设置所述个性化因子的权值,并根据所述权值对所述个性化因子进行排序,获得个人标签,所述个人标签,包括:初始疾病组,所述初始疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险;
其中,所述个人标签,根据所述常规因子逻辑表和/或所述个人信息的更新而更新,更新后的所述个人标签,包括:更新疾病组,所述更新疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险;
所述更新疾病组与所述初始疾病组包括同一种所述疾病名称时,所述更新疾病组,包括:该同一种所述疾病名称的变化趋势。
进一步地,所述个人信息,还包括:所述疾病名称;所述初始疾病组,包括:所述个人信息中的所述疾病名称。
进一步地,所述医学信息,包括:佛明翰心血管事件风险评估模型、timi评分模型、汉密尔顿抑郁量表、中国糖尿病防治指南。
进一步地,所述大数据信息,包括:更新的所述个人信息。
进一步地,所述大数据信息,包括:新增用户的个人信息。
进一步地,所述常规因子,包括:性别、年龄、身高、体重、生活习惯、饮食习惯、症状、运动习惯、既往病史、家族史、体征、实验室指标。
进一步地,所述常规因子,还包括:基因信息。
进一步地,所述常规因子,包括:长期因子和短期因子,所述长期因子的权值大于所述短期因子的权值。
进一步地,该方法还包括:对所述个性化因子进行组合获得个性化因子组,将所述个性化因子组按照由高到低的风险等级进行排序。
进一步地,该方法还包括:对所述疾病名称建立关联,至少一种所述疾病名称与另一所述疾病名称的关联度越高,则至少一种所述疾病名称引发另一所述疾病名称的风险越高。
与现有技术相比,本申请所述的基于常规因子的个性化疾病风险等级分析方法,实现了如下的有益效果:
(1)本发明提供的基于常规因子的个性化疾病风险等级分析方法,能够及时根据更新的医学信息和/或大数据信息对常规因子逻辑表进行调整,而且当个人信息更新时,个人标签也会更新,即:疾病风险评估的结果是随着常规因子逻辑表和/或个人信息的更新而随时调整的,因此,疾病风险评估的结果更为准确和具有实时性;
(2)本方法是针对个人信息,从个人信息的常规因子中筛选出个性化因子,再通过对个性化因子设置权值和对权值进行排序,实现了疾病风险进行评估,个性化程度高;
(3)本方法增加了对个性化因子组的风险评估,使得对个人的疾病风险的评估更为准确;
(4)本方法通过对疾病名称建立关联,能够对患者可能引发的疾病进行评估,提高了对患者疾病风险评估的准确度。
当然,实施本发明的任一产品必不特定需要同时达到以上所述的所有技术效果。
通过以下参照附图对本发明的示例性实施例的详细描述,本发明的其它特征及其优点将会变得清楚。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本发明实施例1中的基于常规因子的个性化疾病风险等级分析方法的流程图;
图2为本发明中的实施例1中的获得个人标签的流程图;
图3为本发明实施例2中的基于常规因子的个性化疾病风险等级分析方法的流程图;
图4为本发明为本发明中的实施例2中的获得个人标签的流程图;
图5为本发明实施例3中的基于常规因子的个性化疾病风险等级分析方法的流程图;
图6为本发明中的实施例3中的获得个人标签的流程图。
具体实施方式
现在将参照附图来详细描述本发明的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本发明的范围。
以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
在这里示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
实施例1
本实施例提供了一种基于常规因子的个性化疾病风险等级分析方法,如图1所示,该方法包括:
步骤101:建立常规因子逻辑表
根据医学信息和大数据信息,建立常规因子逻辑表,所述常规因子逻辑表,包括:疾病名称、常规因子和所述常规因子的阈值,将一种所述疾病名称与至少一种常规因子进行关联,所述直接关联分为直接1级关联、直接2级关联和直接3级关联,所述间接关联分为间接1级关联、间接2级关联和间接3级关联,且1级关联的关联等级高于二级关联的关联等级高于三级关联的关联等级;其中,所述常规因子逻辑表根据所述医学信息和/或所述大数据信息的更新进行实时调整。
步骤102:获取个人信息
获取个人信息,所述个人信息,包括:所述常规因子和所述常规因子临床值和/或主诉值,其中,所述临床值优于所述主诉值作为所述常规因子的实际值。
步骤103:获取个人标签
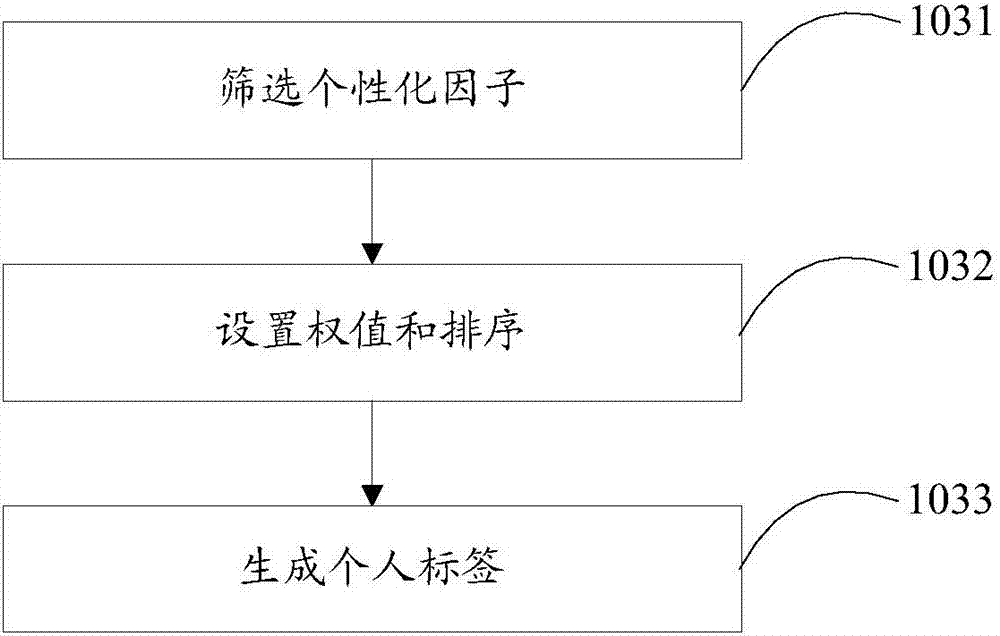
具体地,如图2所示,步骤103具体包括:
步骤1031:筛选个性化因子
将所述个人信息与所述常规因子逻辑表进行对比,筛选出所述实际值偏离所述阈值的所述常规因子作为个性化因子。
步骤1032:设置权值和排序
按照与所述疾病名称直接关联大于与所述疾病名称间接关联、高级关联大于低级关联以及所述实际值偏离所述阈值越多则权值越大的原则,设置所述个性化因子的权值,并根据所述权值对所述个性化因子进行排序,
步骤1033:生成个人标签
获得个人标签,所述个人标签,包括:初始疾病组,所述初始疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险。
步骤104:更新个人标签
所述个人标签,根据所述常规因子逻辑表和/或所述个人信息的更新而更新,更新后的所述个人标签,包括:更新疾病组,所述更新疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险;所述更新疾病组与所述初始疾病组包括同一种所述疾病名称时,所述更新疾病组,包括:该同一种所述疾病名称的变化趋势。
在本实施例中,所述的医学信息,包括但不限于目前全球得到广泛证实和运用的健康模型、疾病模型、生存质量模型以及权威指南文献,例如:佛明翰心血管事件风险评估模型、timi评分模型、汉密尔顿抑郁量表、中国糖尿病防治指南等。
在本实施例中,所述的常规因子来源于所述医学信息,例如:性别、年龄、身高、体重、生活习惯、饮食习惯、症状、运动习惯、既往病史、家族史、体征、实验室指标等。
对于进行过血液、其他体液、或细胞对dna进行检测的患者来说,能够获得该患者可能患有某种疾病的基因信息,因此,基因信息也可以作为评估疾病风险等级的常规因子。
表1.疾病名称与常规因子的关联表
表1给出了高血压和糖尿病的常规因子的关联情况,以高血压为例进行说明:高血压(疾病名称)与血压(常规因子)是直接1级关联,与血糖(常规因子)是直接2级关联,与血脂(常规因子)是直接3级关联;高血压(疾病名称)与家族史(常规因子)是间接1级关联,与bmi(常规因子)是间接2级关联,与钠摄入(常规因子)是间接3级关联,其中bmi是指bodymassindex,即:身体质量指数。在权值的设置时,与疾病名称直接关联的常规因子的权值大于与疾病名称间接关联的常规因子的权值;高级关联的权值大于低级关联的权值,即:直接1级关联的权值>直接2级关联的权值>直接3级关联的权值;间接1级关联的权值>间接2级关联的权值>间接3级关联的权值。
表2.常规因子逻辑表
表2中示出了高血压和糖尿病的常规因子逻辑表,以高血压进行说明:
用户a输入的信息为:血压(125)、血糖(5.2)、血脂(1.56)、家族史(高血压)、bmi(20)、钠摄入(12),对此,通过与高血压的常规因子逻辑表进行对比,筛选出用户a的个性化因子为:血压、血脂和家族史,通过关联等级、直接/间接关联及偏离阈值的程度,设置用户a的个性化因子的权值:血压[0.2]、家族史[0.1],用户a的个性化因子的排序结果为:血压>家族史。各项个性化因子的权值之和m的值为0.3,判定为高血压中级风险。
用户b输入的信息为:血压(150)、血糖(5.2)、血脂(1.56)、家族史(无)、bmi(22.6)、钠摄入(6),对此,通过与高血压的常规因子逻辑表进行对比,筛选出用户b的个性化因子为:血压和钠摄入,通过关联等级、直接/间接关联及偏离阈值的程度,设置用户a的个性化因子的权值:血压[0.5]、钠摄入[0.2],用户b的个性化因子的排序结果为:血压>钠摄入;各项个性化因子的权值之和m的值为0.7,判定为高血压高级风险。
对比用户a和用户b:虽然用户a具有高血压家族史,但是用户a的血压(125)并未高出正常值很多,而且饮食中钠摄入的量控制在低风险的范围,高血压的风险等级为中级风险;而用户b虽然没有高血压家族史,但是血压值已经高达150,而且长期摄入过量的钠,高血压的风险等级为高级风险。通过上述用户a和用户b的高血压风险等级的评估结果可以看出,每个用户的个性化因子有所不同,且个性化因子的权值也不同,个性化因子的权值的设置是通过关联等级、直接/间接关联及偏离阈值的程度等多个标准进行确定的,是一个综合的结果,因此权值的设置更为准确,且符合个人的情况,个性化程度更高。
应当理解,个性标签中的疾病名称可以是已患疾病或潜在疾病,本发明不仅对已患疾病的风险等级进行评估,对潜在疾病的风险也进行评估,对潜在疾病的风险等级评估对疾病预防具有重要的指导意义。
需要说明的是,本发明中的常规因子逻辑表中包括常见的疾病及与疾病相关联的常规因子,表2只是示出了其中的高血压和糖尿病两种疾病,只是示例性说明,并不用于限制常规因子逻辑表所包含的疾病名称及常规因子的种类。
所述大数据信息,包括:新增用户的个人信息和更新的所述个人信息。当采用本方法对疾病风险进行评估的用户增多时,统计的信息也会增多,对本方法的评估的准确度也有所提升。例如:吸烟对肺部的影响很大,吸烟(常规因子)与肺癌(疾病名称)直接关联,但是每日的吸烟量不同,患肺癌的风险是不同的,而医学信息对此并没有给出吸烟量与肺癌风险的对应关系,对此,本方法采用大数据信息来进行评估,当大数据信息的基数(用户量)不同时,评估的准确度也不同,大数据信息的基数越大,准确度越高。当所述个人信息更新后,疾病风险的评估结果也可能发生变化,例如:用户c的个人标签中的初始疾病组包括高血压,但用户c的个人信息更新后,用户c的个人信息中血压值趋于正常,而血糖有所升高,因此,更新疾病组包括:高血压风险降低,趋于正常;具有患高血糖的风险。
需要说明的是,本发明中的初始疾病组并非只是第一次获得个人信息后经过疾病风险评估后获得的,而是指每一次所述常规因子逻辑表和/或所述个人信息更新之前的个人标签中所包括的疾病组,即:在下一次所述常规因子逻辑表和/或所述个人信息更新后,之前的所述更新疾病组将作为初始疾病组。
在本实施例中,所述个人信息,还包括:所述疾病名称,所述初始疾病组,包括:所述个人信息中的所述疾病名称。例如:某个人的个人信息中写明了患有糖尿病,那么在对该患者进行疾病风险评估时,自动将糖尿病加入初始疾病组,并将糖尿病及该患者与糖尿病相关的个性化因子作为该患者需要长期监控的个性化因子。
在本实施例中,所述常规因子分为长期因子和短期因子。某人长期居住于潮湿的环境中、煤矿工人长期工作于含有大量粉尘的环境中、某个家庭的成员喜食腌渍食品,长期钠摄入过量;这些环境因素或生活习惯通常都是长期对人体起作用的,因此,潮湿、粉尘、钠摄入过量是长期因子。某人由于参加了同学聚会而喝醉,饮酒对于该人来说是偶尔会发生的情况,只会在饮酒后的一天或者几天内起作用,因此,饮酒对于这个人来说是短期因子。在进行评估时,长期因子的权值要高于短期因子的权值。
本实施例提供的基于常规因子的个性化疾病风险等级分析方法,能够及时根据更新的医学信息和/或大数据信息对常规因子逻辑表进行调整,而且当个人信息更新时,个人标签也会更新,即:疾病风险评估的结果是随着常规因子逻辑表和/或个人信息的更新而随时调整的,因此,疾病风险评估的结果更为准确和具有实时性;本方法是针对个人信息,从个人信息的常规因子中筛选出个性化因子,再通过对个性化因子设置权值和对权值进行排序,实现了疾病风险进行评估,个性化程度高。
实施例2
本实施例提供了一种基于常规因子的个性化疾病风险等级分析方法,如图3所示,该方法包括:
步骤201:建立常规因子逻辑表
根据医学信息和大数据信息,建立常规因子逻辑表,所述常规因子逻辑表,包括:疾病名称、常规因子和所述常规因子的阈值,将一种所述疾病名称与至少一种常规因子进行关联,所述直接关联分为直接1级关联、直接2级关联和直接3级关联,所述间接关联分为间接1级关联、间接2级关联和间接3级关联;其中,所述常规因子逻辑表根据所述医学信息和/或所述大数据信息的更新进行实时调整。
步骤202:获取个人信息
获取个人信息,所述个人信息,包括:所述常规因子和所述常规因子临床值和/或主诉值,其中,所述临床值优于所述主诉值作为所述常规因子的实际值。
步骤203:获取个人标签
具体地,如图4所示,步骤203包括:
步骤2031:筛选个性化因子
将所述个人信息与所述常规因子逻辑表进行对比,筛选出所述实际值偏离所述阈值的所述常规因子作为个性化因子。
步骤2032:设置权值及排序
按照与所述疾病名称直接关联大于与所述疾病名称间接关联、高级关联大于低级关联的原则,设置所述个性化因子的权值,并根据所述权值对所述个性化因子进行排序,
步骤2033:获得个性化因子组
对所述个性化因子进行组合获得个性化因子组,将所述个性化因子组按照由高到低的风险等级进行排序。
步骤2034:生成个人标签
获得个人标签,所述个人标签,包括:初始疾病组,所述初始疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险。
步骤204:更新个人标签
所述个人标签,根据所述常规因子逻辑表和/或所述个人信息的更新而更新,更新后的所述个人标签,包括:更新疾病组,所述更新疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险;
所述更新疾病组与所述初始疾病组包括同一种所述疾病名称时,所述更新疾病组,包括:该同一种所述疾病名称的变化趋势。
在本实施例中,所述的医学信息,包括但不限于目前全球得到广泛证实和运用的健康模型、疾病模型、生存质量模型以及权威指南文献,例如:佛明翰心血管事件风险评估模型、timi评分模型、汉密尔顿抑郁量表、中国糖尿病防治指南等。
在本实施例中,所述的常规因子来源于所述医学信息,例如:性别、年龄、身高、体重、生活习惯、饮食习惯、症状、运动习惯、既往病史、家族史、体征、实验室指标等。
对于进行过血液、其他体液、或细胞对dna进行检测的患者来说,能够获得该患者可能患有某种疾病的基因信息,因此,基因信息也可以作为评估疾病风险等级的常规因子。
疾病名称与常规因子的关联情况如表3所示:
表3.疾病名称与常规因子的关联表
表3给出了高血压和糖尿病的常规因子的关联情况,以高血压为例进行说明:高血压(疾病名称)与血压(常规因子)是直接1级关联,与血糖(常规因子)是直接2级关联,与血脂(常规因子)是直接3级关联;高血压(疾病名称)与家族史(常规因子)是间接1级关联,与bmi(常规因子)是间接2级关联,与钠摄入(常规因子)是间接3级关联,其中bmi是指bodymassindex,即:身体质量指数。在权值的设置时,与疾病名称直接关联的常规因子的权值大于与疾病名称间接关联的常规因子的权值;高级关联的权值大于低级关联的权值,即:直接1级关联的权值>直接2级关联的权值>直接3级关联的权值;间接1级关联的权值>间接2级关联的权值>间接3级关联的权值。
表4.常规因子逻辑表
表4中示出了高血压和糖尿病的常规因子逻辑表,以高血压进行说明:
用户a输入的信息为:血压(125)、血糖(5.2)、血脂(1.56)、家族史(高血压)、bmi(20)、钠摄入(12),对此,通过与高血压的常规因子逻辑表进行对比,筛选出用户a的个性化因子为:血压、血脂和家族史,通过关联等级、直接/间接关联及偏离阈值的程度,设置用户a的个性化因子的权值:血压[0.2]、家族史[0.1],用户a的个性化因子的排序结果为:血压>家族史。各项个性化因子的权值之和m的值为0.3,判定为高血压中级风险。
用户b输入的信息为:血压(150)、血糖(5.2)、血脂(1.56)、家族史(无)、bmi(22.6)、钠摄入(6),对此,通过与高血压的常规因子逻辑表进行对比,筛选出用户b的个性化因子为:血压和钠摄入,通过关联等级、直接/间接关联及偏离阈值的程度,设置用户a的个性化因子的权值:血压[0.5]、钠摄入[0.2],用户b的个性化因子的排序结果为:血压>钠摄入;各项个性化因子的权值之和m的值为0.7,判定为高血压高级风险。
对比用户a和用户b:虽然用户a具有高血压家族史,但是用户a的血压(125)并未高出正常值很多,而且饮食中钠摄入的量控制在低风险的范围,高血压的风险等级为中级风险;而用户b虽然没有高血压家族史,但是血压值已经高达150,而且长期摄入过量的钠,高血压的风险等级为高级风险。通过上述用户a和用户b的高血压风险等级的评估结果可以看出,每个用户的个性化因子有所不同,且个性化因子的权值也不同,个性化因子的权值的设置是通过关联等级、直接/间接关联及偏离阈值的程度等多个标准进行确定的,是一个综合的结果,因此权值的设置更为准确,且符合个人的情况,个性化程度更高。
应当理解,个性标签中的疾病名称可以是已患疾病或潜在疾病,本发明不仅对已患疾病的风险等级进行评估,对潜在疾病的风险也进行评估,对潜在疾病的风险等级评估对疾病预防具有重要的指导意义。
需要说明的是,本发明中的常规因子逻辑表中包括常见的疾病及与疾病相关联的常规因子,表4只是示出了其中的高血压和糖尿病两种疾病,只是示例性说明,并不用于限制常规因子逻辑表所包含的疾病名称及常规因子的种类。
所述大数据信息,包括:新增用户的个人信息和更新的所述个人信息。当采用本方法对疾病风险进行评估的用户增多时,统计的信息也会增多,对本方法的评估的准确度也有所提升。例如:吸烟对肺部的影响很大,吸烟(常规因子)与肺癌(疾病名称)直接关联,但是每日的吸烟量不同,患肺癌的风险是不同的,而医学信息对此并没有给出吸烟量与肺癌风险的对应关系,对此,本方法采用大数据信息来进行评估,当大数据信息的基数(用户量)不同时,评估的准确度也不同,大数据信息的基数越大,准确度越高。当所述个人信息更新后,疾病风险的评估结果也可能发生变化,例如:用户c的个人标签中的初始疾病组包括高血压,但用户c的个人信息更新后,用户c的个人信息中血压值趋于正常,而血糖有所升高,因此,更新疾病组包括:高血压风险降低,趋于正常;具有患高血糖的风险。
需要说明的是,本发明中的初始疾病组并非只是第一次获得个人信息后经过疾病风险评估后获得的,而是指每一次所述常规因子逻辑表和/或所述个人信息更新之前的个人标签中所包括的疾病组,即:在下一次所述常规因子逻辑表和/或所述个人信息更新后,之前的所述更新疾病组将作为初始疾病组。
在本实施例中,所述个人信息,还包括:所述疾病名称,所述初始疾病组,包括:所述个人信息中的所述疾病名称。例如:某个人的个人信息中写明了患有糖尿病,那么在对该患者进行疾病风险评估时,自动将糖尿病加入初始疾病组,并将糖尿病及与该患者的与糖尿病相关的个性化因子作为该患者需要长期监控的个性化因子。
在本实施例中,所述常规因子分为长期因子和短期因子。某人长期居住于潮湿的环境中、煤矿工人长期工作于含有大量粉尘的环境中、某个家庭的成员喜食腌渍食品,长期钠摄入过量;这些环境因素或生活习惯通常都是长期对人体起作用的,因此,潮湿、粉尘、钠摄入过量是长期因子。某人由于参加了同学聚会而喝醉,饮酒对于该人来说是偶尔会发生的情况,只会在饮酒后的一天或者几天内起作用,因此,饮酒对于这个人来说是短期因子。在进行评估时,由于长期因子对人体的影响大于短期因子,因此,长期因子的权值要高于短期因子的权值。
在本实施例中,个性化因子组由与某一疾病名称相关联的多个个性化因子组成,个性化因子组所包含的个性化因子不同,则患某种疾病的风险不同。表5给出了高血压的个性化因子组的风险表:
表5.高血压的个性化因子组的风险表
表5中示出了不同的个性化因子组对高血压的影响不同,例如:假设a1是血压、b1是家族史、c1是血糖、d1是吸烟、e1是饮酒、f1是血脂、f2是感冒史,则由a1&b1&c1&d1&e1&f1组成的个性化因子组患高血压的风险值明显高于有a1&b1&c1&d1&e1&f2组成的个性化因子组的风险值,不同的个性化因子组对应的风险值不同,个性化因子组对应的风险值越高,则生成的个人标签中的风险等级越高。
35%的个性化因子组所对应的风险等级为高级风险,35%的个性化因子组所对应的风险等级为中级风险,30%的个性化因子组所对应的风险等级为低级风险。其中:
当个性化因子组对应的风险值n≥0.65时,则该个性化因子组对应的疾病名称的风险等级为高级风险;当个性化因子组对应的风险值0.3<n<0.35时,则该个性化因子组对应的疾病名称的风险等级为中级风险;当个性化因子组对应的风险值n≤0.3时,则该个性化因子组对应的疾病名称的风险等级为低级风险。
需要说明的是,在本实施例中,虽然表5只示出了不同的个性化因子组对高血压的,但这只是一个示例性说明,并不用于限制疾病名称和常规因子的组合。
本实施例提供的基于常规因子的个性化疾病风险等级分析方法,能够及时根据更新的医学信息和/或大数据信息对常规因子逻辑表进行调整,而且当个人信息更新时,个人标签也会更新,即:疾病风险评估的结果是随着常规因子逻辑表和/或个人信息的更新而随时调整的,因此,疾病风险评估的结果更为准确和具有实时性;本方法是针对个人信息,从个人信息的常规因子中筛选出个性化因子,再通过对个性化因子设置权值和对权值进行排序,实现了疾病风险进行评估,个性化程度高;增加了对个性化因子组的风险评估,使得对个人的疾病风险的评估更为准确。
实施例3
本实施例提供了一种基于常规因子的个性化疾病风险等级分析方法,如图5所示,该方法包括:
步骤301:建立常规因子逻辑表
根据医学信息和大数据信息,建立常规因子逻辑表,所述常规因子逻辑表,包括:疾病名称、常规因子和所述常规因子的阈值,将一种所述疾病名称与至少一种常规因子进行关联,所述直接关联分为直接1级关联、直接2级关联和直接3级关联,所述间接关联分为间接1级关联、间接2级关联和间接3级关联;其中,所述常规因子逻辑表根据所述医学信息和/或所述大数据信息的更新进行实时调整。
步骤302:获取个人信息
获取个人信息,所述个人信息,包括:所述常规因子和所述常规因子临床值和/或主诉值,其中,所述临床值优于所述主诉值作为所述常规因子的实际值。
步骤303:获取个人标签
具体地,如图6所示,步骤303具体包括:
步骤3031:筛选个性化因子
将所述个人信息与所述常规因子逻辑表进行对比,筛选出所述实际值偏离所述阈值的所述常规因子作为个性化因子。
步骤3032:设置权值和排序
按照与所述疾病名称直接关联大于与所述疾病名称间接关联、高级关联大于低级关联以及所述实际值偏离所述阈值越多则权值越大的原则,设置所述个性化因子的权值,并根据所述权值对所述个性化因子进行排序,
步骤3033:对疾病名称建立关联
将至少一种所述疾病名称与另一所述疾病名称进行关联,至少一种所述疾病名称与另一所述疾病名称的关联度越高,则至少一种所述疾病名称引发另一所述疾病名称的风险越高。
步骤3034:生成个人标签
获得个人标签,所述个人标签,包括:初始疾病组,所述初始疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险。
步骤304:更新个人标签
所述个人标签,根据所述常规因子逻辑表和/或所述个人信息的更新而更新,更新后的所述个人标签,包括:更新疾病组,所述更新疾病组包括至少一种所述疾病名称和所述疾病名称对应的风险等级,所述风险等级,包括:高级风险、中级风险和低级风险;所述更新疾病组与所述初始疾病组包括同一种所述疾病名称时,所述更新疾病组,包括:该同一种所述疾病名称的变化趋势。
在本实施例中,所述的医学信息,包括但不限于目前全球得到广泛证实和运用的健康模型、疾病模型、生存质量模型以及权威指南文献,例如:佛明翰心血管事件风险评估模型、timi评分模型、汉密尔顿抑郁量表、中国糖尿病防治指南等。
在本实施例中,所述的常规因子来源于所述医学信息,例如:性别、年龄、身高、体重、生活习惯、饮食习惯、症状、运动习惯、既往病史、家族史、体征、实验室指标等。对于进行过血液、其他体液、或细胞对dna进行检测的个人来说,以获得个人可能患有某种疾病的基因信息,因此,基因信息也可以作为评估疾病风险等级的常规因子。
表6.疾病名称与常规因子的关联表
表6给出了高血压和糖尿病的常规因子的关联情况,以高血压为例进行说明:高血压(疾病名称)与血压(常规因子)是直接1级关联,与血糖(常规因子)是直接2级关联,与血脂(常规因子)是直接3级关联;高血压(疾病名称)与家族史(常规因子)是间接1级关联,与bmi(常规因子)是间接2级关联,与钠摄入(常规因子)是间接3级关联,其中bmi是指bodymassindex,即:身体质量指数。在权值的设置时,与疾病名称直接关联的常规因子的权值大于与疾病名称间接关联的常规因子的权值;高级关联的权值大于低级关联的权值,即:直接1级关联的权值>直接2级关联的权值>直接3级关联的权值。
表7.常规因子逻辑表
表7中示出了高血压和糖尿病的常规因子逻辑表,以高血压进行说明:
用户a输入的信息为:血压(125)、血糖(5.2)、血脂(1.56)、家族史(高血压)、bmi(20)、钠摄入(12),对此,通过与高血压的常规因子逻辑表进行对比,筛选出用户a的个性化因子为:血压、血脂和家族史,通过关联等级、直接/间接关联及偏离阈值的程度,设置用户a的个性化因子的权值:血压[0.2]、家族史[0.1],用户a的个性化因子的排序结果为:血压>家族史。各项个性化因子的权值之和m的值为0.3,判定为高血压中级风险。
用户b输入的信息为:血压(150)、血糖(5.2)、血脂(1.56)、家族史(无)、bmi(22.6)、钠摄入(6),对此,通过与高血压的常规因子逻辑表进行对比,筛选出用户b的个性化因子为:血压和钠摄入,通过关联等级、直接/间接关联及偏离阈值的程度,设置用户a的个性化因子的权值:血压[0.5]、钠摄入[0.2],用户b的个性化因子的排序结果为:血压>钠摄入;各项个性化因子的权值之和m的值为0.7,判定为高血压高级风险。
对比用户a和用户b:虽然用户a具有高血压家族史,但是用户a的血压(125)并未高出正常值很多,而且饮食中钠摄入的量控制在低风险的范围,高血压的风险等级为中级风险;而用户b虽然没有高血压家族史,但是血压值已经高达150,而且长期摄入过量的钠,高血压的风险等级为高级风险。通过上述用户a和用户b的高血压风险等级的评估结果可以看出,每个用户的个性化因子有所不同,且个性化因子的权值也不同,个性化因子的权值的设置是通过关联等级、直接/间接关联及偏离阈值的程度等多个标准进行确定的,是一个综合的结果,因此权值的设置更为准确,且符合个人的情况,个性化程度更高。
应当理解,个性标签中的疾病名称可以是已患疾病或潜在疾病,本发明不仅对已患疾病的风险等级进行评估,对潜在疾病的风险也进行评估,对潜在疾病的风险等级评估对疾病预防具有重要的指导意义。
需要说明的是,本发明中的常规因子逻辑表中包括常见的疾病及与疾病相关联的常规因子,表7只是示出了其中的高血压和糖尿病两种疾病,只是示例性说明,并不用于限制常规因子逻辑表所包含的疾病名称及常规因子的种类。
所述大数据信息,包括:新增用户的个人信息和更新的所述个人信息。当采用本方法对疾病风险进行评估的用户增多时,统计的信息也会增多,对本方法的评估的准确度也有所提升。例如:吸烟对肺部的影响很大,吸烟(常规因子)与肺癌(疾病名称)直接关联,但是每日的吸烟量不同,患肺癌的风险是不同的,而医学信息对此并没有给出吸烟量与肺癌风险的对应关系,对此,本方法采用大数据信息来进行评估,当大数据信息的基数(用户量)不同时,评估的准确度也不同,大数据信息的基数越大,准确度越高。当所述个人信息更新后,疾病风险的评估结果也可能发生变化,例如:用户c的个人标签中的初始疾病组包括高血压,但用户c的个人信息更新后,用户c的个人信息中血压值趋于正常,而血糖有所升高,因此,更新疾病组包括:高血压风险降低,趋于正常;具有患高血糖的风险。
需要说明的是,本发明中的初始疾病组并非只是第一次获得个人信息后经过疾病风险评估后获得的,而是指每一次所述常规因子逻辑表和/或所述个人信息更新之前的个人标签中所包括的疾病组,即:在下一次所述常规因子逻辑表和/或所述个人信息更新后,之前的所述更新疾病组将作为初始疾病组。
在本实施例中,所述个人信息,还包括:所述疾病名称,所述初始疾病组,包括:所述个人信息中的所述疾病名称。例如:某个人的个人信息中写明了患有糖尿病,那么在对该患者进行疾病风险评估时,自动将糖尿病加入初始疾病组,并将糖尿病及糖尿病相关的常规因子作为该患者需要长期监控的个性化因子。
在本实施例中,所述常规因子分为长期因子和短期因子。某人长期居住于潮湿的环境中、煤矿工人长期工作于含有大量粉尘的环境中、某个家庭的成员喜食腌渍食品,长期钠摄入过量;这些环境因素或生活习惯通常都是长期对人体起作用的,因此,潮湿、粉尘、钠摄入过量是长期因子。某人由于参加了同学聚会而喝醉,饮酒对于该人来说是偶尔会发生的情况,只会在饮酒后的一天或者几天内起作用,因此,饮酒对于这个人来说是短期因子。在进行评估时,长期因子的权值要高于短期因子的权值。
本实施例中,通过对疾病名称建立关联,能够对由用户的可能引发的疾病进行评估,表8给出了各种疾病对高血压的引发风险:
表8.各种疾病对高血压的引发风险表
表8中示出了各种疾病对高血压的引发风险,如果某个患者同时患有糖尿病&脑卒中&代谢综合症&动脉粥样硬化&心房颤动&心肌梗塞等疾病,则这个患者患有高血压的风险极高,即:这几个疾病组合极易引发高血压;但如果某个患者只具有感冒史,那么,该患者几乎没有患高血压的风险,即:感冒对高血压几乎没有引发的可能。
某一种或几种疾病对另一种疾病的引发风险值w越高,则生成的个人标签中的患该另一种疾病的风险等级越高。
为了便于说明,将上述某一种或几种疾病成为疾病组,35%的疾病组所对应的风险等级为高级风险,35%的疾病组所对应的风险等级为中级风险,30%的疾病组所对应的风险等级为低级风险。其中:
当疾病组对应的风险值n≥0.65时,则该疾病组对应的疾病名称的风险等级为高级风险;当疾病组对应的风险值0.3<n<0.35时,则该疾病组对应的疾病名称的风险等级为中级风险;当疾病组对应的风险值n≤0.3时,则该疾病组对应的疾病名称的风险等级为低级风险。
本实施例提供的基于常规因子的个性化疾病风险等级分析方法,能够及时根据更新的医学信息和/或大数据信息对常规因子逻辑表进行调整,而且当个人信息更新时,个人标签也会更新,即:疾病风险评估的结果是随着常规因子逻辑表和/或个人信息的更新而随时调整的,因此,疾病风险评估的结果更为准确和具有实时性;本方法是针对个人信息,从个人信息的常规因子中筛选出个性化因子,再通过对个性化因子设置权值和对权值进行排序,实现了疾病风险进行评估,个性化程度高;通过对疾病名称建立关联,能够对患者的可能引发的疾病进行评估,提高了对患者的疾病风险的评估的准确度。
通过以上实施例可知,本申请提供的基于常规因子的个性化疾病风险等级分析方法达到了如下有益效果:
(1)本发明提供的基于常规因子的个性化疾病风险等级分析方法,能够及时根据更新的医学信息和/或大数据信息对常规因子逻辑表进行调整,而且当个人信息更新时,个人标签也会更新,即:疾病风险评估的结果是随着常规因子逻辑表和/或个人信息的更新而随时调整的,因此,疾病风险评估的结果更为准确和具有实时性;
(2)本方法是针对个人信息,从个人信息的常规因子中筛选出个性化因子,再通过对个性化因子设置权值和对权值进行排序,实现了疾病风险进行评估,个性化程度高;
(3)本方法增加了对个性化因子组的风险评估,使得对个人的疾病风险的评估更为准确;
(4)本方法通过对疾病名称建立关联,能够对患者的可能引发的疾病进行评估,提高了对患者的疾病风险的评估的准确度。
当然,实施本发明的任一产品必不特定需要同时达到以上所述的所有技术效果。
本领域内的技术人员应明白,本发明的实施例可提供为方法、装置、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。
虽然已经通过例子对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上例子仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员应该理解,可在不脱离本发明的范围和精神的情况下,对以上实施例进行修改。本发明的范围由所附权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!