一种文章语义向量表示方法和系统与流程
本发明涉及文章语义分析领域,更具体地,涉及一种文章语义向量表示方法和系统。
背景技术:
文章语义的向量表示在与自然语言处理相关的诸多领域发挥着重要的作用,例如文本中心思想的提取、文本的语义分析、文本分类、对话系统以及机器翻译等方面的研究。但是现有的技术做文章的语义表示采用的是基于词向量的方法,在词向量的基础上计算段落的语义表示。
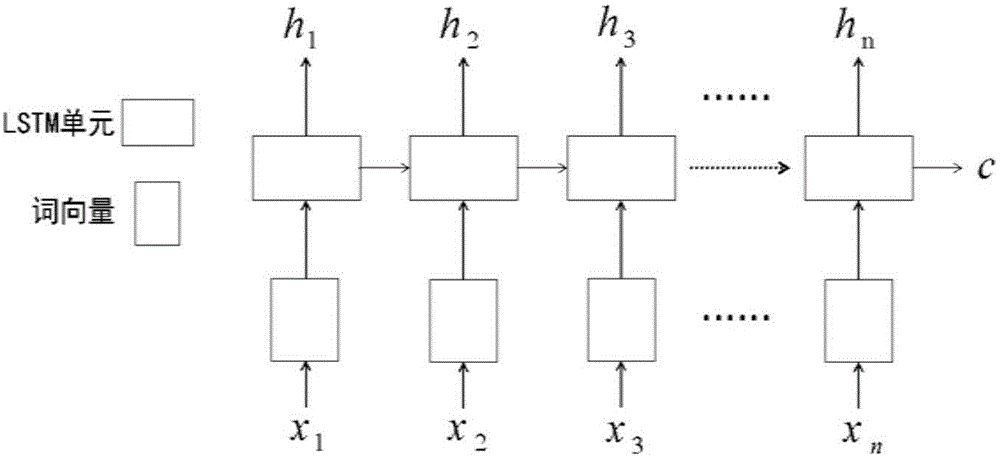
图1为现有技术中的一种基于词向量的文章语义向量表示方法的示意图,请参阅图1,这种方法是基于词向量的语义表示,这种方法的过程是将词向量通过长短时间记忆网络(longshort-termmemory,lstm)直接输出得到句子或者文章的语义向量。这个方法需要先将文本进行分词,分词后进行词汇向量化,得到词向量,将词向量按照句子的时间顺序输入lstm模型。模型的最后的输出结果就是这一句文本最终的语义向量。
其中,{x1,x2,...,xn}为输入的单词序列,通过word2vector获取词向量,理论上模型的最后的输出结果将包含本句话中所有应当保留的信息,因此可以将这个输出结果作为本句话的语义向量表示,但是对语义向量提取采取的方式会极大的影响对文本语义表示的效果。
对于这种基于词向量的句子语义表示方法,以基于神经网络机器翻译(neuralmachinetranslation,nmt)中的sequencetosequence模型为例,向模型中的encode中依次输入字向量或者词向量,直到我们输入这个句子的最后一个字向量或者词向量,此时encode输出整句的语义向量。nmt的特点就是把考虑之前的每一步的输入信息,所以在理论上这个语义向量就能够包含整个句子的信息。但是,实际操作过程中,随着词序列的不断增长,尤其达到段落级别的文本量,发现有如下问题:当序列不断输入时,语义信息无法记忆和表示整个序列的信息;词汇与词汇间的影响因子相似,无法突出文本当中的重点;很难提取段落文本的语义向量表示。
在现有的技术当中,另一种也是最具有代表性的语义向量的表示方法是基于词向量的注意力模型获取语义向量表示。注意力的转移是人的大脑在接收或者处理外部信息时通过感官巧妙而合理地改变对外部信息的关注点,选择性地忽视与自身不太相关的内容,并将自身需要的信息放大。通过改变关注点,人脑对所集中注意力部位的信息的接收灵敏度和信息处理速度都大大增强,能有效的过滤不相关的信息,突出密切相关的信息。总而言之,注意力机制的基本思想并不是一次性把整个场景的每个位置平等对待,而是根据需求将重点集中到特定的位置。一旦特定提取的规则确定,再利用机器学习或者深度神经网络学习到未来要观察图像注意力应该集中的位置。
文本语义向量表示最开始引入注意力机制是用在了nmt上,神经网络机器翻译是一个典型的sequencetosequence模型,其中包含一个encodertodecoder模型。
图2为现有技术中的一种基于词向量注意力模型的文章语义向量表示方法的示意图,如图2所示,现有的基于词向量注意力模型获取语义向量表示是,使用一个循环神经网络(recurrentneuralnetwork,rnn)对源文本中的单词按照时间序列进行编码,编码之后的每一个输出与相应的关注度相乘,最后求和得到一个固定维度的中间语义向量。具体的语义向量表示为:
其中,ci为语义向量,ts为b,b为文章的句子个数,hj为第j个词向量的通过lstm的输出量,exp(eij)为以e为底的eij次方,tx为i,va为词向量通过lstm的输出量,
对于基于词向量的注意力模型的语义向量表示方法,由于引入了注意力机制,使得每个词汇都在经过数据学习后提取同步的关注度,每种词汇具有各自对应的关注度,并经过加权获得的句子的语义表示实现了句子间的重点提取。
但是,这种方法仅仅是简单的将句子语义表示直接相加,对于文章的翻译、文章摘要提取这类长文本很难进行语义向量表示,基于词向量并且不能很好地表示文章或者段落的整体语义。
技术实现要素:
本发明提供一种克服上述问题的一种文章语义向量表示方法和系统。
根据本发明的一个方面,提供一种文章语义向量表示方法,包括:s1、根据所述文章中任一句子的所有词向量,获取所述任一句子的句向量;s2、将依据所述文章的句子正序排列的对应的句向量和倒序排列的对应的句向量均输入双向的长短时间记忆网络模型,获取对应于任一句向量的第一输出量和所述任一句向量对应的关注度句向量的第二输出量,其中,所述任一句向量对应的关注度句向量为:在所述文章的句向量正序排列下,所述任一句向量和所述任一句向量之前的句向量构成的至少一个句向量;s3、根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,获取所述任一句向量对应的句子的语义向量;s4、根据所述文章中的所有句向量对应的句子的语义向量,获取所述文章语义向量。
优选地,步骤s1进一步包括:将所述文章中任一句子的所有词向量的同一维度点进行加和,获取所述任一句子的句向量。
优选地,步骤s2进一步包括:将依据所述文章的句子正序排列的对应的句向量输入双向的长短时间记忆网络模型,获取第一个句向量到所述任一句向量的语义信息和所述第一个句向量到所述关注度句向量的语义信息;将依据所述文章的句子倒序排列的对应的句向量输入双向的长短时间记忆网络模型,获取最后一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息;将所述第一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述任一句向量的语义信息整合,获取对应于任一句向量的第一输出量,并且,将所述第一个句向量到所述关注度句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息整合,获取对应于所述关注度句向量的第二输出量。
优选地,步骤s3中所述对应的关注度句向量对所述任一句向量的关注度通过下式获取:
其中,aij为第j个句向量对第i个句向量的关注度,eij为双线性函数,tx为i,exp(eij)为以e为底的eij次方,第j个句向量为第i个句向量的任一关注度句向量,0<j≤i,0<i≤b,i,j∈z,b为文章的句向量个数,z为整数集。
优选地,步骤s3进一步包括:根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,通过下式获取所述任一句向量对应的句子的语义向量:
其中,ci为第i个句向量对应的句子的语义向量,ts为b,b为文章的句向量个数,aij为第j个句向量对第i个句向量的关注度,hj为第j个句向量的第一输出量,0<j≤i,0<i≤b,i,j∈z,z为整数集。
优选地,所述双线性函数为:
eij=ci-1whj
其中,eij为双线性函数,ci-1为第i-1个句向量对应的句子的语义向量,w为hj的权重矩阵,w∈rh*h,rh*h为h乘h的实数域,h∈r,r为实数集,hj为为第j个句向量的第一输出量,0<j≤i,0<i≤b,i,j∈z,b为文章的句向量个数,z为整数集。
优选地,所述权重矩阵通过反向传播算法获取。
根据本发明的另一个方面,提供一种文章语义向量表示系统,包括:获取句向量模块,用于根据所述文章中任一句子的所有词向量,获取所述任一句子的句向量;获取输出量模块,用于将依据所述文章的句子正序排列的对应的句向量和倒序排列的对应的句向量均输入双向的长短时间记忆网络模型,获取对应于任一句向量的第一输出量和所述任一句向量对应的关注度句向量的第二输出量,其中,所述任一句向量对应的关注度句向量为:在所述文章的句向量正序排列下,所述任一句向量和所述任一句向量之前的句向量构成的至少一个句向量;获取句子语义向量模块,用于根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,获取所述任一句向量对应的句子的语义向量;获取文章语义向量模块,用于根据所述文章中的所有句向量对应的句子的语义向量,获取所述文章语义向量。
优选地,所述获取输出量模块进一步用于:将依据所述文章的句子正序排列的对应的句向量输入双向的长短时间记忆网络模型,获取第一个句向量到所述任一句向量的语义信息和所述第一个句向量到所述关注度句向量的语义信息;将依据所述文章的句子倒序排列的对应的句向量输入双向的长短时间记忆网络模型,获取最后一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息;将所述第一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述任一句向量的语义信息整合,获取对应于任一句向量的第一输出量,并且,将所述第一个句向量到所述关注度句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息整合,获取对应于所述关注度句向量的第二输出量。
优选地,所述获取句子语义向量模块进一步用于:根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,通过下式获取所述任一句向量对应的句子的语义向量:
其中,ci为第i个句向量对应的句子的语义向量,ts为b,b为文章的句向量个数,aij为第j个句向量对第i个句向量的关注度,hj为第j个句向量的第一输出量,0<j≤i,0<i≤b,i,j∈z,z为整数集。
本发明提供的一种文章语义向量表示方法和系统,通过设置获取了文章中的所有句向量,通过对句向量进行操作最后获取文章语义向量,使得在段落语义提取阶段总体的计算量有了大幅度的减少,并且解决了传统基于词向量的语义向量提取无法实现的段落语义表示的功能,提取出的语义向量包含整篇文章的所有有用的信息。
附图说明
图1为现有技术中的一种基于词向量的文章语义向量表示方法的示意图;
图2为现有技术中的一种基于词向量注意力模型的文章语义向量表示方法的示意图;
图3为本发明实施例中的一种文章语义向量表示方法的流程图;
图4为本发明实施例中的第一输出量获取的示意图;
图5为本发明实施例中的文章语义向量的获取示意图
图6为本发明实施例中的一种文章语义向量表示系统的模块图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
图3为本发明实施例中的一种文章语义向量表示方法的流程图,如图3所示,包括:s1、根据所述文章中任一句子的所有词向量,获取所述任一句子的句向量;s2、将依据所述文章的句子正序排列的对应的句向量和倒序排列的对应的句向量均输入双向的长短时间记忆网络模型,获取对应于任一句向量的第一输出量和所述任一句向量对应的关注度句向量的第二输出量,其中,所述任一句向量对应的关注度句向量为:在所述文章的句向量正序排列下,所述任一句向量和所述任一句向量之前的句向量构成的至少一个句向量;s3、根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,获取所述任一句向量对应的句子的语义向量;s4、根据所述文章中的所有句向量对应的句子的语义向量,获取所述文章语义向量。
具体地,文章中任一句子的所有词向量优选通过word2vector获取。
进一步地,为解决序列问题的数据中序列长度有差距的问题,本领域的技术人员设计了循环神经网络(recurrentneuralnetwork,rnn)来处理序列问题。但是普通的rnn存在两个问题。一是长距离依赖,二是梯度消失和梯度爆炸,这种问题在处理长序列的时候尤为明显。
为了解决以上问题,本领域的技术人员提出了长短时间记忆网络(longshort-termmemory,lstm)模型。这种rnn架构专门用于解决rnn模型的梯度消失和梯度爆炸问题。由三个乘法门控制记忆块的激活状态:输入门(inputgate)、输出门(outputgate)、忘记门(forgetgate)。这种结构可以使之前输入的信息保存在网络中,并一直向前传递,输入门打开时新的输入才会改变网络中保存的历史状态,输出门打开时保存的历史状态会被访问到,并影响之后的输出,忘记们用于清空之前保存的历史信息。
由于lstm模型的输入是单方向的,往往忽略了未来的上下文信息。双向的长短时间记忆网络的基本思想是使用一个训练序列向前向后各训练一个lstm模型。再将两个模型的输出进行线性组合,以达到序列中每一个节点都能完整的依赖所有上下文信息。
具体地,步骤s2中所述在所述文章的句向量正序排列下,所述任一句向量和所述任一句向量之前的句向量构成的至少一个句向量是指,若任一句向量为文章的第一个句向量,则任一句向量的关注度句向量为第一个句向量,只包括一个句向量。若任一句向量不是文章的第一个句向量,则任一句向量的关注度句向量为正序排列下从第一个句向量到任一句向量中包括的若干个句向量。
需要说明的是,本发明实施例中的第一个句向量均为正序排列下的第一个句向量,本发明实施例中的最后一个句向量均为正序排列下的最后一个句向量。本发明实施例中的若干个指的是两个及两个以上。
本发明提供的一种文章语义向量表示方法,通过设置获取了文章中的所有句向量,通过对句向量进行操作最后获取文章语义向量,使得在段落语义提取阶段总体的计算量有了大幅度的减少,并且解决了传统基于词向量的语义向量提取无法实现的段落语义表示的功能,提取出的语义向量包含整篇文章的所有有用的信息。
基于上述实施例,步骤s1进一步包括:将所述文章中任一句子的所有词向量的同一维度点进行加和,获取所述任一句子的句向量。
具体地,句向量是从未标记的数据中得到的,因此可以被应用在没有太多标签的数据上,并且基于句向量,每个段落甚至每篇文档都能映射在唯一的向量上。
进一步地,句子当中的词向量是句向量的基本组成单元。对于一个句子来说,其包含的每一个词向量的维度一致。将文章中任一句子的所有词向量的同一维度点进行加和,能够获取任一句子的句向量。任一句子的句向量和该句子的所有的词向量的维度一致。
在获取句向量后,下面对上述实施例中的第一输出量和第二输出量的获取做出进一步的解释,在这里需要说明的是,本发明实施例中第一输出量和第二输出量均为通过双向的长短时间记忆网络模型输出的量,具有相同的性质。
图4为本发明实施例中的第一输出量获取的示意图,请参阅图4,上述实施例中的步骤s2进一步包括:将依据所述文章的句子正序排列的对应的句向量输入双向的长短时间记忆网络模型,获取第一个句向量到所述任一句向量的语义信息和所述第一个句向量到所述关注度句向量的语义信息;将依据所述文章的句子倒序排列的对应的句向量输入双向的长短时间记忆网络模型,获取最后一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息;将所述第一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述任一句向量的语义信息整合,获取对应于任一句向量的第一输出量,并且,将所述第一个句向量到所述关注度句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息整合,获取对应于所述关注度句向量的第二输出量。
具体地,任一句向量对应一个第一输出量。
进一步地,双向的长短时间记忆网络模型(bi-lstm)具有正向编码和反向编码的功能,上面所述将依据所述文章的句子正序排列的对应的句向量输入双向的长短时间记忆网络模型,获取第一个句向量到所述任一句向量的语义信息和所述第一个句向量到所述关注度句向量的语义信息为正向编码的过程。相应地,上面所述将依据所述文章的句子倒序排列的对应的句向量输入双向的长短时间记忆网络模型,获取最后一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息为反向编码的过程。句向量是双向的长短时间记忆网络模型(bi-lstm)的输入的基本单元。
进一步地,第一个句向量到所述任一句向量是指,文章的句向量在正序排列下,从第一个句向量顺次序到所述任一句向量。相应地,最后一个句向量到所述任一句向量是指,文章的句子在正序排列下,从最后一个句向量逆次序到所述任一句向量。
进一步地,第一个句向量到所述关注度句向量是指第一个句向量到所述任一句向量的每一关注度句向量。最后一个句向量到所述关注度句向量是指最后一个句向量到所述任一句向量的每一关注度句向量。
进一步地,对于任一句向量来说,将双向的长短时间记忆网络模型(bi-lstm)正向编码和反向编码的语义信息整合起来,获取的任一句向量的第一输出量包含了该句向量之前的句向量的语义信息和该句向量之后的句向量的语义信息。
需要说明的是,vd的在一定程度上也能表示文章的语义向量,但是当段落句子量过大时会有如下问题:语义信息无法记忆和表示整个文章序列的信息;由于所有词汇的影响因子相似,无法突出文章重点且中心思想学习不准确。基于此,本发明进一步提出了步骤s3。
上述实施例中说明了根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,获取所述任一句向量对应的句子的语义向量,本实施例对对应的关注度句向量对所述任一句向量的关注度的获取方式作出解释。
上述实施例中的步骤s3中所述对应的关注度句向量对所述任一句向量的关注度通过下式获取:
其中,aij为第j个句向量对第i个句向量的关注度,eij为双线性函数,tx为i,exp(eij)为以e为底的eij次方,第j个句向量为第i个句向量的任一关注度句向量,0<j≤i,0<i≤b,i,j∈z,b为文章的句向量个数,z为整数集。
具体地,关注度为关注的程度,也可认为是受影响的程度。
本发明提供的一种文章语义向量表示方法,通过设置计算关注度句向量对所述任一句向量的关注度,能够获知文章中的句子间的相互影响程度,使得获取的文章语义向量更加准确。
下面基于上述实施例,对于步骤s3做出进一步描述。
具体地,步骤s3进一步包括:根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,通过下式获取所述任一句向量对应的句子的语义向量:
其中,ci为第i个句向量对应的句子的语义向量,ts为b,b为文章的句向量个数,aij为第j个句向量对第i个句向量的关注度,hj为第j个句向量的第一输出量,0<j≤i,0<i≤b,i,j∈z,z为整数集。
进一步地,本发明实施例中的hj和vd均指代第一输出量。
本发明提供的一种文章语义向量表示方法,通过设置根据第二输出量和对应的关注度句向量对任一句向量的关注度,获取任一句向量对应的句子的语义向量,能有效的对各个句子的贡献度做出区分。
基于上述实施例,所述双线性函数为:
eij=ci-1whj
其中,eij为双线性函数,ci-1为第i-1个句向量对应的句子的语义向量,w为hj的权重矩阵,w∈rh*h,rh*h为h乘h的实数域,h∈r,r为实数集,hj为为第j个句向量的第一输出量,0<j≤i,0<i≤b,i,j∈z,b为文章的句向量个数,z为整数集。
本发明提供的一种文章语义向量表示方法,通过设置双线性函数,使其相比较于基于词向量注意力模型所用的前向神经激励函数能够较好的提升神经网络的性能,并且在应用到如段落中心提取网络下能取得较为良好的结果。
基于上述实施例,所述权重矩阵通过反向传播算法获取。
具体地,反向传播算法(backpropagationalgorithm,bp算法)是一种监督学习算法,常被用来训练多层感知机。bp算法是delta规则的推广,要求每个人工神经元所使用的函数必须是可微的。bp算法特别适合用来训练前向神经网络。
作为一个优选实施例,图5为本发明实施例中的文章语义向量的获取示意图,请参阅图5,文章语义向量的获取具体可包括下述步骤:
首先,将文章中任一句子的所有词向量的同一维度点进行加和,获取任一句子的句向量。
其次,将依据文章的句子正序排列的对应的句向量输入双向的长短时间记忆网络模型,获取第一个句向量到任一句向量的语义信息和第一个句向量到关注度句向量的语义信息;将依据文章的句子倒序排列的对应的句向量输入双向的长短时间记忆网络模型,获取最后一个句向量到任一句向量的语义信息和最后一个句向量到关注度句向量的语义信息;将第一个句向量到任一句向量的语义信息和最后一个句向量到任一句向量的语义信息整合,获取对应于任一句向量的第一输出量,并且,将第一个句向量到关注度句向量的语义信息和最后一个句向量到关注度句向量的语义信息整合,获取对应于关注度句向量的第二输出量。
然后,根据第二输出量和对应的关注度句向量对任一句向量的关注度,通过下式获取任一句向量对应的句子的语义向量:
其中,ci为第i个句向量对应的句子的语义向量,ts为b,b为文章的句向量个数,aij为第j个句向量对第i个句向量的关注度,hj为第j个句向量的第一输出量,0<j≤i,0<i≤b,i,j∈z,z为整数集。
上式中的aij通过下式获取:
其中,aij为第j个句向量对第i个句向量的关注度,eij为双线性函数,tx为i,exp(eij)为以e为底的eij次方,第j个句向量为第i个句向量的任一关注度句向量,0<j≤i,0<i≤b,i,j∈z,b为文章的句向量个数,z为整数集。
在最后,获取文章中的所有句向量对应的句子的语义向量,根据文章中的所有句向量对应的句子的语义向量,获取文章语义向量。
基于上述实施例,本发明还提供了一种文章语义向量表示系统,用以实施上述任一实施例的文章语义向量表示方法,图6为本发明实施例中的一种文章语义向量表示系统的模块图,如图6所示,包括:获取句向量模块,用于根据所述文章中任一句子的所有词向量,获取所述任一句子的句向量;获取输出量模块,用于将依据所述文章的句子正序排列的对应的句向量和倒序排列的对应的句向量均输入双向的长短时间记忆网络模型,获取对应于任一句向量的第一输出量和所述任一句向量对应的关注度句向量的第二输出量,其中,所述任一句向量对应的关注度句向量为:在所述文章的句向量正序排列下,所述任一句向量和所述任一句向量之前的句向量构成的至少一个句向量;获取句子语义向量模块,用于根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,获取所述任一句向量对应的句子的语义向量;获取文章语义向量模块,用于根据所述文章中的所有句向量对应的句子的语义向量,获取所述文章语义向量。
基于上述实施例,所述获取输出量模块进一步用于:将依据所述文章的句子正序排列的对应的句向量输入双向的长短时间记忆网络模型,获取第一个句向量到所述任一句向量的语义信息和所述第一个句向量到所述关注度句向量的语义信息;将依据所述文章的句子倒序排列的对应的句向量输入双向的长短时间记忆网络模型,获取最后一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息;将所述第一个句向量到所述任一句向量的语义信息和所述最后一个句向量到所述任一句向量的语义信息整合,获取对应于任一句向量的第一输出量,并且,将所述第一个句向量到所述关注度句向量的语义信息和所述最后一个句向量到所述关注度句向量的语义信息整合,获取对应于所述关注度句向量的第二输出量。
基于上述实施例,所述获取句子语义向量模块进一步用于:根据所述第二输出量和所述对应的关注度句向量对所述任一句向量的关注度,通过下式获取所述任一句向量对应的句子的语义向量:
其中,ci为第i个句向量对应的句子的语义向量,ts为b,b为文章的句向量个数,aij为第j个句向量对第i个句向量的关注度,hj为第j个句向量的第一输出量,0<j≤i,0<i≤b,i,j∈z,z为整数集。
本发明提供的一种文章语义向量表示方法和系统,通过设置获取了文章中的所有句向量,通过对句向量进行操作最后获取文章语义向量,使得在段落语义提取阶段总体的计算量有了大幅度的减少,并且解决了传统基于词向量的语义向量提取无法实现的段落语义表示的功能,提取出的语义向量包含整篇文章的所有有用的信息。通过设置计算关注度句向量对所述任一句向量的关注度,能够获知文章中的句子间的相互影响程度,使得获取的文章语义向量更加准确。通过设置根据第二输出量和对应的关注度句向量对任一句向量的关注度,获取任一句向量对应的句子的语义向量,能有效的对各个句子的贡献度做出区分。通过设置双线性函数,使其相比较于基于词向量注意力模型所用的前向神经激励函数能够较好的提升神经网络的性能,并且在应用到如段落中心提取网络下能取得较为良好的结果。
最后,本发明的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!