一种基于二叉树分解的多周期RFID防碰撞算法的制作方法
本发明涉及一种基于二叉树分解的多周期rfid防碰撞算法,属于物联网架构下rfid射频识别领域。
背景技术:
rfid(radiofrequencyidentification)技术,即无线射频识别技术,是目前被广泛运用在物联网感知层的一种通信技术手段。rfid系统由rfid读写器、电子标签和应用软件三部分组成。rfid系统的工作原理根据电子标签有无内置电源略有不同:无源电子标签(被动标签)内部只有内置天线,没有电源,不具有主动发送射频信号的功能手段,需要由rfid读写器的读写模块向电子标签发送射频信号。当无源电子标签接收到来自rfid读写器的射频信号,标签内部产生感应电流,通过内置天线进行应答,将存储于标签存储区的信息发送至rfid读写器,读写器读取标签存储区信息并进行解码,将解码数据通过应用软件进行进一步的处理。对于有源电子标签(主动标签),由于标签内部存在电源,通信距离更长,可以主动向rfid读写器发送射频信号,随后同样由读写器进行解码,并通过应用软件进行处理。
rfid技术作为物联网信息采集层的重要技术手段,具有识别距离远、多标签同时识别的优势,但是多个标签在共享信道内发送信号会以较大概率发生碰撞,进而导致读写器不能够在一定时间内正确地识别所有标签信息。为解决上述问题,rfid防碰撞算法应运而生。目前rfid防碰撞算法分为随机性防碰撞算法、确定性防碰撞算法和混合型防碰撞算法,不同的算法各有优劣。本发明将基于查询树算法的基本原理,引入二叉树分解和响应子周期的概念,以算法的系统吞吐率、时间复杂度和数据传输量三个性能指标为考量,提出一种新型的rfid防碰撞算法。
技术实现要素:
基于上述,本发明提出根据待识别标签的总数量自适应的对初始识别状态进行二叉树分解,根据分解出的m叉树由读写器向待识别标签发送共2m个m位前缀位指令,同时将所有前缀位指令放入前缀位池中。待识别标签根据读写器的前缀位指令进行响应,响应的数据信息为自身id去除前缀位指令的信息,应答的情况在时隙中分为空闲时隙、碰撞时隙和识别时隙,在识别过程中,前缀位池将根据当前搜索过程不断更新,每当一个前缀命令完成一次识别时隙后,则将其从前缀位池中删除。当标签在同一时隙发生碰撞时,将标签的第m+1位进行标记并记为标志位,标志位为“0”进入响应子周期x0中,标志位为“1”进入响应子周期x1中。两个响应子周期在同一搜索深度下完成识别,并将前缀位命令与标签响应的碰撞位前的前缀进行组合,并放入前缀池中。
本发明的优点有:
本发明通过对初始状态二叉树进行分解,提高了初始状态下的共享信道利用率,进而达到提高系统吞吐率的目的。同时将碰撞时隙分解为一个搜索深度下的两个响应子周期,提高了系统响应速度,减小了时间复杂度,并将标签信息进行拆分,减少每次通信的数据传输量。
附图说明
附图1为本发明中算法设计的流程附图;
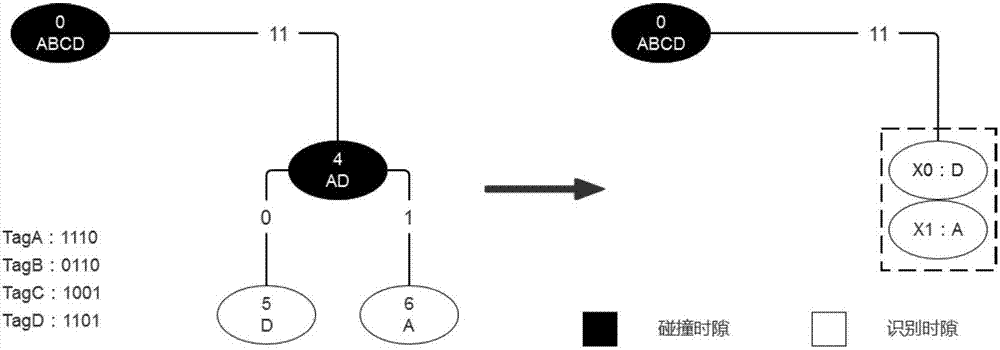
附图2为本发明中响应子周期分解示意图;
附图3为本发明中算法系统吞吐率matlab仿真结果;
附图4为本发明中算法时间复杂度matlab仿真结果;
附图5为本发明中算法在第一层搜索深度中的数据传输量matlab仿真结果。
具体实施方式
(一)实施步骤
为了更加清楚的描述本文提出的基于二叉树分解的多周期rfid防碰撞算法,引入前缀位池和搜索堆栈的概念分别放置读写器发送的前缀位和当前的搜索深度层数,方便向下进行标签查询和重新确定搜索起点。
首先,在碰撞时隙未分解的前提下,设二叉树分解的初始时隙数为2m个,m的大小与标签id的总长度l有关。当m大于标签id长度时,会出现大量的空闲时隙,造成信道效率的浪费,故m的取值应不大于l,不小于1。根据二元确定性原理,在2m个时隙中,每个标签所接收到的读写器前缀位命令均为m位。读写器将所有的前缀位命令在前缀位池中保存,并将标签id中的第m+1位标记为标志位。在识别过程中,前缀位池将根据当前搜索过程不断更新,每当一个前缀命令完成一次识别时隙后,则将其从前缀位池中删除;每当前缀位命令发生碰撞,则将从标志位开始直到最后一个碰撞位的id信息与原前缀拼接成为新前缀位命令,并放入前缀池中。电子标签根据接收到的前缀位命令进行响应,前缀位相同的标签在同一个二叉树的时隙中应答,响应的数据信息为自身id去除前缀位指令的信息,应答的情况在时隙中同样分为空闲时隙、碰撞时隙和识别时隙。
在所有上述碰撞时隙中,所有当前时隙下的标签前缀位共m位发生碰撞,此时将标签中的第m+1位标志位进行读取,标志位为“0”的标签进入子响应子周期x0,标志位为“1”的标签进入子响应子周期x1,同时将标志位的值与前缀位的值进行合并,存入前缀位池中。x0与x1两个响应子周期将在同一层次的搜索层中向读写器响应,换句话说,读写器可以在一次查询中,得到两个并列的时隙,这样的算法执行过程有助于减少系统数据交换的总次数,降低算法的时间复杂度。然后,需要判断该碰撞时隙节点所在树是否为满二叉树。“满叉”在本文提出的算法中是指,当前节点向下延伸的二叉树的搜索层数为x时节点数为2x-1。当该子二叉树不为满二叉树时,说明当前搜索深度中还有其他子树没有完成遍历,为了使算法的过程减少重复路径,本文将当前节点的搜索深度s储存搜索堆栈中,令d=s。当该碰撞时隙节点存在继续向下发散的子二叉树,则令s1=s+1,并储存于堆栈d=s的下一位;若已经完成该节点内搜索识别,则在搜索堆栈中删掉可能存在的s1,并将s的值向下一个节点传递,以减少算法的重复路径。此外,标签的响应过程中,所传输的数据仅包括前缀位指令之后的数据,即m+1至l位,相比于二进制树算法大大减少了数据的传输量。当该子二叉树为满二叉树但前缀位池不为空时,说明当前子树已完成识别,但紧邻的右侧子树还未开始识别,需要返回搜索深度为1的初始状态中,由前缀位池发送下一个前缀位命令,进入下一个子树识别流程。
在空闲时隙中,当前所有标签id没有与前缀位匹配的情况发生,依然需要判断当前时隙节点所在子树是否为满二叉树。如果是,则需要查询当前s值,并令s=s-1,返回之前的搜索层数中。在识别时隙中,当前标签中只有一个标签id等于读写器发出的前缀位指令,搜索策略与空闲时隙相同,在完成识别后,前缀位池会删除当前发送的前缀位指令。当识别时隙的节点所在子树为满二叉树,同时前缀位池为空时,则结束识别过程。
(二)算法性能
假设标签的数目为n,标签id的总长度为l,搜索深度为d,在第一层搜索深度(d=1)中假设所有的响应子周期x0,x1仍未被拆分,所有共有2m个前缀位指令从读写器发出,即2m个时隙,其中k个标签在一个时隙中响应读写器前缀位指令的概率服从二项分布:
则在第一层出现空闲时隙、识别时隙和碰撞时隙的概率为:
由于d=1时,共2m个时隙,对上述三个公式计算数学期望,可以估计第一层搜索深度中空闲时隙、识别时隙、碰撞时隙的数量分别是:
分析上式可知,当标签数目n远大于读写器初始发送的2m个前缀位指令时,空闲时隙数量ee和识别时隙数量er趋近于0,碰撞时隙数量ec趋近于2m个,说明在d=1的所有初始时隙中几乎都为碰撞时隙。由于每个碰撞时隙中将根据标签标志位的数量划分为两个响应子周期。当n的值很大时,在每个响应子周期中标签将会以很大的概率继续发生碰撞,则此时分解出的子二叉树为2m+1个,故n个标签平均到每个碰撞子二叉树的数量为n/2m+1个。参考基本二进制树算法的概念可知,当有共2m+1个子二叉树,标签平均到每个子二叉树的数量为n/2m+1个时,将相应变量带入上式可得搜索深度d>1时基于二叉树分解的多周期rfid防碰撞算法的时隙数为:
故基于二叉树分解的多周期rfid防碰撞算法的总时隙数为d=1时的时隙数与d=2时的时隙数相加:
为了使该算法的总时隙数量q尽可能减少,需要对上式进行求导。由于x!为非连续函数,所以引入gamma函数的概念,由gamma函数的概念可知x!=γ(x+1),同时γ(x)等价于
对上式m进行求导可以得到当q取最小值时,初始前缀位长度m与标签总数n的关系为:
此外,防碰撞算法的识别周期数是指从二叉树的根节点搜索到最后一个末端节点的过程,本文将此识别周期数定义为算法的时间复杂度。由附图2可知,在引入响应子周期概念后,每两个连续的响应子周期都被看作一个周期节点,同时该节点包括了原二叉树中一个父节点和两个子节点。因此,本文算法由碰撞时隙划分的响应子周期节点总数与满二叉树的中间节点总数相同,总周期数则为在碰撞时隙划分的响应子周期的节点数与其他空闲时隙、其他识别时隙数量之和。其中,其他空闲时隙由算法原理可知,不会发生在d>1的情况中;其他识别时隙则是由d>1时的识别时隙所组成。当有n个标签时,满二叉树的总节点数为w=2n-1,则当m=1,算法为二叉树形态时,有n个标签均发生碰撞,算法的时间复杂度为wm=n-1。
在基于二叉树分解的多周期rfid防碰撞算法中,当d=1时,发生碰撞的标签个数为:
上式表示算法中将有nc个标签以二叉树形态的响应子周期被继续识别,则nc个标签的时间复杂度为:
算法整体的时间复杂度w(n)为:
现将本文推导出的算法最小时隙数时标签数量n与初始状态前缀位长度m的关系代入上式中可得算法时间复杂度w(n)与标签总数n的关系为:
由系统吞吐率的定义可知,确定性防碰撞算法的系统吞吐率应该为待识别标签总数n与时间复杂度w(n)之比,将前缀位指令位数m与n的关系带入吞吐率s的公式中,得到s与标签总数n的关系为:
在算法的执行过程中,将数据的传输总量定义为通信复杂度f,共有n个标签时,数据的传输总量f(n)由读写器发送的数据fr(n)和标签响应的数据ft(n)组成:
f(n)=fr(n)+ft(n)
由算法原理可知,读写器每次发送的前缀位指令长度lq与标签响应的指令长度lx相加即为标签id总位数l。但是由于响应子周期的存在,标签每个周期向读写器响应的位数为2lx。结合算法的时间复杂度w(n)可得:
f(n)=w(n)·(lq+2lx)
(三)算法性能及分析
本发明通过matlab仿真,将基于二叉树分解的多周期rfid防碰撞算法从系统吞吐率、时间复杂度和数据传输量三个最主要的性能进行评估。仿真条件是给标签赋予epc-96的编码方式,故标签id长度均为96位,标签数量上限选取到300个。
在rfid防碰撞算法的构思和实现过程中,系统的吞吐率是应该被优先考虑的重要指标。不同算法的系统吞吐率的大小主要反映了该算法对读写器和电子标签之间共享信道的利用程度。本发明引入前缀位池和标志位的概念,系统吞吐率如附图3所示,可以基本维持在58%左右。时间复杂度也是rfid防碰撞算法性能优劣的重要参考指标,时间复杂度表示识别周期数与标签总数的商。当时间复杂度越小时,系统可以在很短的周期内完成对待识别标签的读取。本发明中的算法时间复杂度如附图4所示,由于加入了标志位,所以可以加速标签id信息的识别判断,在时间复杂度上随着标签数量的增大曲线趋于稳定。在数据传输量的matlab仿真中,取算法第一层的搜索深度中的数据传输量,如附图5所示,随着标签总数的提高,数据传输量缓慢增长,曲线没有大幅度上扬。
- 还没有人留言评论。精彩留言会获得点赞!