一种基于深度摄像头的演示辅助系统的制作方法
本发明涉及电子技术领域,特别是一种基于深度摄像头的演示辅助系统。
背景技术:
目前,在大型会议、教学等演示任务中,通常将电脑中需要演示的文件通过投影仪投放到大屏幕上,而演讲人通常站在大屏幕旁边进行演示,不方便同时操控电脑,在这种情况下,演讲人通常需要另外一名人员帮忙辅助控制电脑,以控制大屏幕上显示的内容。
现有技术中,演讲人可以通过使用光笔来实现采用激光点来提示听众演讲的重点,或者进行简单的翻页等功能,但此类光笔能实现的功能简单、单一,无法满足现在演示辅助设备的需求。
技术实现要素:
针对上述问题,本发明旨在提供一种基于深度摄像头的演示辅助系统。
本发明的目的采用以下技术方案来实现:
一种基于深度摄像头的演示辅助系统,包括:数据采集模块、位置控制模块、手势识别模块、演示功能控制模块,其中:
数据采集模块,包括深度摄像头,深度摄像头安放于云台上并通过电机控制云台旋转角度,用于采集用户的手势深度图像;
位置控制模块,根据采集的手势深度图像识别出用户手势位置操控所述云台转动,实现实时跟踪;
手势识别模块,根据采集的手势深度图像识别出用户手势,并转化为相应的操作指令;
演示功能控制模块,用于根据所述操作指令执行演示辅助功能。
本发明的有益效果为:本系统通过采集演讲者的手势图像,并对手势进行精准的识别,并将不同的手势转化成不同的执行命令,对演示系统进行操作,操作简单、方便;可以根据实际需要设定并执行不同的演示辅助功能,功能性强,满足演讲者在实际演示过程中所需的操作要求;通过位置控制控制深度摄像头跟随演讲者移动,使演讲者不受摄像头范围的限制,灵活性强;本系统兼容性强,能适用于现有的演示系统。
附图说明
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
图1为本发明的框架结构图;
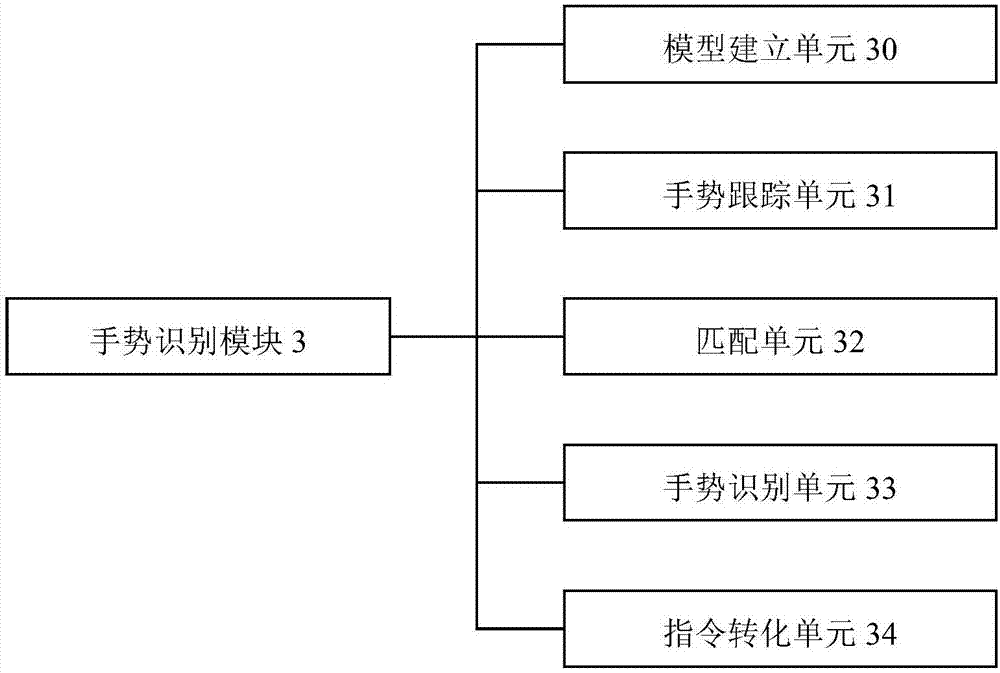
图2为本发明手势识别模块的框架结构图
图3为本发明位置控制模块中重点监控区域展示图。
附图标记:
数据采集模块1、位置控制模块2、手势识别模块3、演示功能控制模块4、模型建立单元30、手势跟踪单元31、匹配单元32、手势识别单元33和指令转化单元34
具体实施方式
结合以下应用场景对本发明作进一步描述。
参见图1,一种基于深度摄像头的演示辅助系统,其特征在于,包括:数据采集模块1、位置控制模块2、手势识别模3、演示功能控制模块4,其中:
数据采集模块1,包括深度摄像头,深度摄像头安放于云台上并通过电机控制云台旋转角度,用于采集用户的手势深度图像;
位置控制模块2,根据采集的手势深度图像识别出用户手势位置操控所述云台转动,实现实时跟踪,保证演讲者的手部一直在摄像头采集的图像采集范围内。
手势识别模块3,根据采集的手势深度图像识别出用户手势,并转化为相应的操作指令;
演示功能控制模块4,用于根据所述操作指令执行演示辅助功能。
其中,所述位置控制模块具体包括:在深度摄像头采集到的手势图像中心设定重点监控区域(具体参见图3),所述重点监控区域为图像中心的矩形区域,当检测到手势离开了所述重点监控区域后,控制云台转动,通过调整云台转动,将演讲者手势重新定位在所述重点监控区域的中心,当演讲者手势仅仅在重点监控区域内移动时,所述位置控制模块不控制云台转动。
本发明上述实施例,通过采集演讲者的手势图像,并对手势进行精准的识别,并将不同的手势转化成不同的执行命令,对演示系统进行操作,操作简单、方便;可以根据实际需要设定并执行不同的演示辅助功能,功能性强,满足演讲者在实际演示过程中所需的操作要求;通过位置控制控制深度摄像头跟随演讲者移动,使演讲者不受摄像头范围的限制,灵活性强;本系统兼容性强,能适用于现有的演示系统。
优选地,所述演示辅助功能包括但不仅限于画笔注释、翻页、图片展示和视频播放。
本优选实施例,本系统可以根据实际应用需求设定不同演示辅助功能,不同的功能可以通过演讲者采用不同的手势实现,功能性强,满足演讲者在实际演示过程中所需的操作要求。
优选地,参见图2,所述手势识别模块包括模型建立单元30,手势跟踪单元31,匹配单元32、手势识别单元33和指令转化单元34,其中:
模型建立单元30,用于在虚拟空间中建立三维手部模型和状态特征模型;
匹配单元31,用于将获取的手势深度图像中的手势和所述三维手部模型进行实时匹配,将用户手势变化投射到三维手部模型中;
手势跟踪单元32,用于对所述三维手部模型进行跟踪,获取三维手部模型的状态变化;
手势识别单元33,用于根据所述三维手部模型的状态变化,对三维手部模型表达的手势进行识别,输出用户手势识别结果;
指令转化单元34,用于根据所述用户手势识别结果,输出相应的操作指令。
本优选实施例,通过建立三维手部模型,将手势深度图像和虚拟空间中的三维手部模型进行匹配,当演讲者手势发生变化时,三维手部模型发生同步变化,在虚拟空间中通过对三维手部模型进行跟踪,获取三维手部模型的手势变化,并对其进行识别,获取最终的识别结果,通过对三维手部模型识别演讲者手势,鲁棒性强,准确度高。
优选地,所述状态特征模型包括:三维手部模型状态特征
其中,mcp(metacarpophalangealpoint)表示掌指关节,pip(proximalinterphalangealpoint)表示近侧指间关节,dip(distalinterphalangealpoint)表示远侧指间关节,ip(interphalangealpoint)表示指间关节,tm(trapezio-metacarpal)关节表示角骨关节。
本优选实施例,采用上述方式建立三维手部状态特征模型,采用特殊设计的26自由度模型,能够很好地适应模型的精准度和计算的复杂度,提高系统性能。
优选地,所述匹配单元32,具体包括:当所述手势深度图像中用户手势发生变化时,对三维手部模型作出相应的状态变化假设,计算三维手部模型的状态参数和图像中手势之间的状态匹配误差,选取匹配误差最小的状态参数作为三维手部模型的最优解,并根据所述最优解更新三维手部模型的状态,保持三维手部模型和图像中手势的同步匹配,
其中,采用的状态匹配误差函数为:
式中,
优选地,匹配单元32通过使用三维手部模型上一帧(上一状态)所获得的最优解来预测下一帧(下一状态)的状态参数,有效地缩小了状态参数的搜索空间。
本优选实施例,采用上述的方法对手势深度图像和三维手部模型进行匹配,通过结合三维手部模型的剪影特征、深度特征和平滑状态,在上一状态的基础上搜索匹配度最高的状态作为当前状态的特征参数,并且根据此特征参数更新三维手部模型的状态特征,实现三维手部模型与手势深度图像的同步匹配,适应性强,准确度高,实时性良好,为系统后续对三维手部模型手势的跟踪识别奠定了基础。
优选地,手势跟踪单元32,用于对所述三维手部模型进行跟踪,获取三维手部模型的状态变化,具体包括:
对手势跟踪单元32进行初始化:从先验分布
获取粒子初始位置,将最新观测值引入待优化目标函数中,具体采用的粒子初始化函数为:
式中,
对粒子进行迭代演化,驱动粒子向高似然概率区域运动,具体采用的迭代函数为:
式中,
利用观测似然更新粒子权值
根据权值大小对样本集
根据样本集变化输出三维手部模型的状态变化,对粒子进行持续的迭代演化,直到跟踪结束。
优选地,在上述实施例中,为了避免粒子过早收敛,导致效果不好,每次粒子迭代演化后采用下列函数来提高粒子的多样性:
式中,
本优选实施例,在粒子滤波框架下,采用上述的方法对三维手部模型的状态特征变化进行跟踪,能够准确地获取三维手部模型的状态特征变化,适应性强,准确度高;通过记录粒子样本集的变化,能够准确地获取三维手部模型的状态变化,为后续对手势的识别奠定了基础。
优选地,所述状态特征模型还不限于仅仅建立三维手部模型,还能对例如球体进行建模,在后续的匹配单元和手势跟踪单元能同时对三位首部模型和球体模型进行匹配和跟踪,获取人手与物体交互过程的跟踪识别。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当分析,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!