一种基于替代模型的VIC参数多目标优选新方法与流程
本发明属于水文模型领域,涉及一种vic水文模型参数率定的新方法,尤其涉及一种基于替代模型的vic参数多目标优选新方法。
背景技术
vic模型(variableinfiltrationcapacitymacroscalehydrologicmodel)是一种大尺度分布式水文模型,由华盛顿大学、加利福尼亚大学伯克利分校以及普林斯顿大学共同开发。vic模型将流域划分为网格形式,在网格内以水量平衡和能量平衡的原理进行水文模拟,具有较好的模拟性能。
在水文模型建立时,模型中有些参数往往无法进行实际测量,因此需要根据实际流量等数据对水文模型中这些无法测量的参数进行率定。vic模型作为大尺度分布式水文模型,其格点计算量很大,单次运行时间较长。在采用优化算法进行自动参数率定时常常需要进行数万次的模型调用,尤其随着率定参数和率定目标函数个数的增加,vic模型调用次数也会随之增加,这在模型建立过程中造成了极高的计算代价。
技术实现要素:
为解决现有技术不足,本发明的目的在于提供一种基于替代模型的vic参数多目标优选新方法,以提高vic模型参数率定的效率,在算力条件较低的情况下高效、准确地对vic模型参数进行自动率定,有效地降低计算代价。
为实现上述目标,一种基于替代模型的vic参数多目标优选新方法,包括如下步骤:
1)利用ε-nsgaii算法选取样本,利用adaboost-bpnn方法构造二阶段vic水文模型替代模型。
2)采用ε-nsgaii算法率定替代模型参数。
上述技术方案中,步骤1)中二阶段替代模型的具体定义为:
1)根据模型率定的特征参数,替代模型可以表示为待率定参数与纳西效率系数(nse)和偏离度(bias)的函数关系,如下所示:
nse=g1(x)
bias=g2(x)
2)优化算法最终会将序列的纳西效率系数(nse)最终集中到1附近,通常取0.8-1,偏离度(bias)集中在0附近,通常为0-0.2,因此将该范围定义为较优范围。在较优范围内,希望替代模型的计算结果更加精确。
3)第一阶段替代模型,主要是在全局范围内进行低精度(poor-fidelitysimulation)模拟,并将落在较优范围内部分的结果从所有的结果中筛选出来。
4)第二阶段替代模型,将较优范围内部分采用高精度(high-fidelitysimulation)模式,使得模拟结果具有较小误差。
构建替代模型的具体过程为:
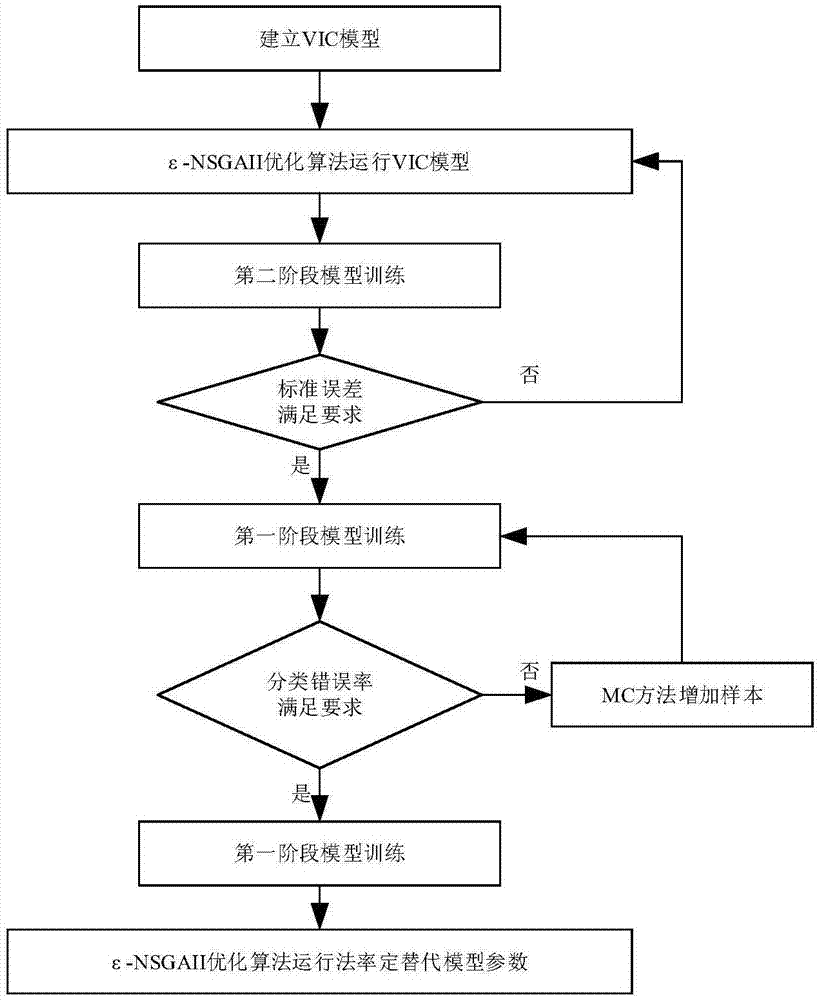
1)采用ε-nsgaii算法对vic模型进行参数优化。优化算法每计算完一代结果后,提取样本结果并去除其中的重复结果,作为替代模型训练和验证的样本。
2)提取较优范围内的样本,随机抽取其中70%作为第二阶段的模型训练样本,30%作为第二阶段的验证样本。如果第二阶段替代模型的验证结果小于给定误差,则终止优化,第二阶段替代模型建立成功,进入3)步骤;如果替代模型的验证结果未达到要求,则回到1)步骤ε-nsgaii算法进入下一代优化,继续循环。
3)进行第一阶段模型训练。利用1)步骤中产生的样本进行训练和验证,抽取其中70%作为第一阶段的模型训练样本以及30%作为第一阶段的模型验证样本,如果第一阶段替代模型的验证结果小于给定误差,则模型完成;如果第一阶段替代模型的验证结果不满足要求,则通过蒙特卡洛统计方法产生n组样本,随机选取其中70%加入训练样本,剩余30%加入验证样本,再一次训练并验证模型,如此重复直至模型验证通过为止。
二阶段模型效果的验证方式具体为:
1)第一阶段模型的评估将以分类的错误率来判断,公式如下所示:
其中e1表示将非较优范围内的结果判断为较优范围内结果的次数,e2表示将较优范围内的结果判断为非较优范围内结果的次数,ne为落在较优范围内的样本长度。
2)第二阶段模型训练结果优劣以标准误差判断,公式如下所示:
其中,n为序列长度,si为替代模型计算的纳西效率系数/偏离度,即模拟值;oi为同一参数条件下vic模拟序列与实际观测序列的纳西效率系数/偏离度,即真实值。
通过采用上述技术手段,本发明的有益效果为:
(1)其采用新方法得到的模型率定结果与传统方法直接对vic模型率定所得的结果基本一致;
(2)在率定结果没有明显差异的情况下,新方法的率定效率得到了大幅度提升。
(3)采用新方法进行参数率定可以极大地节省计算机算力。
附图说明
图1为本发明的一个流程示意图;
图2为a站率定期流量过程线。
图3为a站验证期流量过程线。
图4为b站率定期流量过程线。
图5为b站验证期流量过程线。
具体实施方式
下面通过实例,并结合附图,对本发明的技术方案做进一步详细说明。
如图1所示为整个计算流程。
将某流域b站以上流域划分为0.25°×0.25°网格,结合srtm3数字地形高程模型、westdc系列土地覆盖数据产品、hwsd世界土壤数据库等地理信息,该流域及周围的27个气象站点降雨、辐射、湿度、气压、温度等气象数据,建立vic模型。将其中b站和以及上游a站1998-2004年日径流量序列用于模型参数率定,2010年-2015年日径流量序列用作模型参数验证。模型中待率定的参数主要有7个参数,包括:基流分割比(ds)、基流最大速度(dsmax)、非线性基流发生时的最大土壤蓄水容量因子(wx)、下渗参数(binfil)、第二层土壤深度(d2)、第三层土壤深度(d3)、雪糙率(sr)。率定的目标函数共有四个,分别为a站和b站的模拟径流序列与实际径流序列的纳西效率系数(nse)和偏离度(bias)。
将bp神经网络作为弱预测器,采用经典的三层式(7-10-1)结构,并将10个弱预测器耦合成强预测器。将ε-nsgaii优化算法每代的初始样本数设定为24。提取较优范围内的样本,随机抽取其中70%作为第二阶段的模型训练样本,30%作为第二阶段的验证样本。不断增加代数,直至模型算的纳西效率系数标准误差小于样本均值的1%,偏离度的标准误差小于样本均值的10%。根据计算,当优化算法至25代时,满足条件。
将25代样本构建第一阶段模型,第一阶段模型依然将bp神经网络作为弱预测器,采用经典的三层式(7-10-1)结构,并将10个弱预测器耦合成强预测器。随机抽取样本中70%作为模型训练样本,30%作为模型验证样本。根据计算,25代样本训练的模型分类错误率小于5%,可以满足分类要求,不需要补充样本。
构造的二阶段模型计算结果如表1所示,放入ε-nsgaii优化算法进行参数率定。在测试中,vic模型均在centos6系统下,以intelxeoncpue5-4620v2@2.60ghz下24核并行运行(i运行条件);替代模型在ubuntu16.04系统下,以intelcorecpui7-4620@3.40ghz下单核运行(ii运行条件)。如表2所示为分别利用ε-nsgaii算法对vic模型和替代模型进行参数率定的运算效率比较;如表3所示为分别利用ε-nsgaii算法对vic模型和替代模型进行率定所得参数的比较;如表4所示为为分别利用ε-nsgaii算法对vic模型和替代模型进行率定所得目标函数的比较。
将替代模型率定所得参数,放入vic模型进行计算。图2为a站率定期流量过程线,图3为a站验证期流量过程线,图4为b站率定期流量过程线,图5为b站验证期流量过程线。表5为a、b两站率定期和验证期实际计算所得的目标函数。
表1替代模型计算结果
表2vic模型和替代模型自动率定运算效率
表3vic模型和替代模型率定所得参数
表4vic模型和替代模型率定所得目标函数
表5a、b站率定期和验证期目标函数
以上所述仅对本发明的实例实施而已,并不用于限制本发明。本发明中对待率定参数、率定目标函数也可根据不同的研究问题具体制定。对于本领域的研究者来说,本发明可以有各种更改和变化。凡是在本发明的权利要求限定范围内,所做的任何修改、等同替换、改进等,均应在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!