一种基于条件生成式对抗网络在ICGA图像上分割漆裂纹的方法与流程
本发明涉及一种基于条件生成式对抗网络在icga图像上分割漆裂纹的方法,属于图像处理技术领域。
背景技术:
近年来,随着大数据的迅速发展,深度学习网络已经被广泛应用于计算机视觉、人工智能等领域。其中,生成式对抗网络(gan)更是解决图像翻译问题的一个重要的网络工具,它被称为是“20年来机器学习领域最酷的想法”。
与传统的图模型相比,gan是更好的生成模型,它在某种意义上避免了马尔科夫链式的学习机制,这使得它能够区别于传统的概率生成模型。传统概率生成模型一般都需要进行马可夫链式的采样和推断,而gan避免了这个计算复杂度特别高的过程,直接进行采样和推断,从而提高了gan的应用效率,所以其实际应用场景也就更为广泛。
其次gan是一个非常灵活的设计框架,各种类型的损失函数都可以整合到gan模型当中,这样使得针对不同的任务,我们可以设计不同类型的损失函数,都会在gan的框架下进行学习和优化。
最重要的一点是,当概率密度不可计算的时候,传统依赖于数据自然性解释的一些生成模型就不可以在上面进行学习和应用。但是gan在这种情况下依然可以使用,这是因为gan引入了一个非常聪明的内部对抗训练机制,可以逼近一些不是很容易计算的目标函数。
因此,使用gan生成图像不需要一个严格生成数据的表达式,唯一需要的仅仅是随机噪声向量以及一系列真实数据,gan中的生成器与判别器通过博弈达到平衡,使网络趋于稳定,得出真实的生成图像。目前,在图像修改方面,包括单图像超分辨率、交互式图像生成、图像编辑和图像到图像的翻译都可以应用gan得到较为完美的解决方案。
另一方面,人工智能在医学领域的应用也在迅速发展。尤其是人们对与眼科疾病的关注,使得眼科影像处理分析成为了当今人工智能领域的热门研究课题。眼睛是心灵的窗户,许多心血管疾病早期都会通过眼睛有所表现。因此,对眼科影像的自动处理与分析,不仅可以减轻医生的负担,高效地对眼科疾病患者进行分析与治疗;同时也可以进行相关疾病的筛查,对疑似患者安排出切实可性的诊断与治疗方案。
近年来,高度近视已成为眼科影像领域重点关注的疾病之一。它所引起的视网膜脱离、黄斑出血和后巩膜葡萄肿等病变,均是导致失明的重要危险因素。在高度近视病变中,漆裂纹样损害和萎缩斑(fuchs斑)是高度近视眼底特有的病变,严重损害视功能,甚至导致失明,日益引起眼科界的重视。
漆裂纹样病变多发生与高度近视眼的进展期,最早由salzmann描述。他在研究高度近视眼的脉络膜病变时,发现玻璃膜有枝状或网状裂隙,眼底表现为不规则的黄白色条纹,形似旧漆器上的裂纹。漆裂纹样病变主要为玻璃膜破裂和色素上皮萎缩所致。发生机制可能与遗传因素相关,更可能与生物力学异常,如眼轴延长、眼压升高,眼内层变形及玻璃膜牵引撕裂等因素有关,同时血液循环障碍、年龄增长也会对其有所影响。
对于漆裂纹样病变的观察,目前主要依靠荧光血管造影图像。相关实验证明使用吲哚菁绿血管造影(icga)图像比荧光素造影图像更容易对漆裂纹样进行判断与识别,因此在吲哚菁绿血管造影图像上对漆裂纹进行分割与定量分析对漆裂纹样的分析与生长预测有着重大的意义。
技术实现要素:
本发明所要解决的技术问题是,提供一种用于解决漆裂纹样病变样本量较少、造影图像获取困难的基于条件生成式对抗网络在icga图像上分割漆裂纹的方法。
为解决上述技术问题,本发明采用的技术方案为:
一种基于条件生成式对抗网络在icga图像上分割漆裂纹的方法,包括以下步骤:
(1)收集原始icga图像,提取完整的眼底造影图像,对其进行金标准标注,将眼底造影图像与金标准进行归一化处理后,拼接为一组图像作为样本数据,按比例将样本分配为训练集与测试集;
(2)基于条件生成式对抗网络原理,构建生成器和判别器网络;
(3)将训练集数据输入网络进行对抗训练,定义损失函数,训练生成器生成与原图对应的漆裂纹图像;
(4)测试阶段,输入测试集数据,通过训练好的生成器g,得到对应的漆裂纹分割结果图。
步骤(1)中包括对原有数据进行扩充来提高训练样本量,扩充方法为在保证图像中基本特征合理的情况下对拼接后的图像进行水平翻转或垂直翻转。
步骤(3)中所述损失函数由三部分组成,包括cgan的损失函数
其中x为眼底造影图像,y为金标准,z为随机向量,n为图像中总像素个数,i表示1-n之间的整数,d(x,y)表示判别器对实际造影图像金标准的真实性判别概率,用0-1来表示,1表示图像100%为真实图像,0表示图像100%为合成图像;g(x,z)表示生成器根据造影图像与随机向量所生成的分割结果;d(x,g(x,z))表示判别器对一组生成器生成图像的真实性判别概率,用0-1来表示,1表示图像100%为真实图像,0表示图像100%为合成图像;yi表示造影图像金标准中第i个像素的灰度值,灰度值范围在0-255之间;g(x,z)i表示生成器生成的分割结果中第i个像素的灰度值,灰度值范围在0-255之间,ex,y~pdata(x,y),z~pz(z)[]表示x,y均属于造影图像与金标准数据集且z服从随机分布情况下的具体期望值;μ和λ分别为l1损失函数和dice损失函数的权重系数。
所述生成器采用u-net卷积网络结构,将输入图像经过若干卷积层以及反卷积层后生成分割结果图像,每个卷积层包含卷积操作、特征图批量归一化以及线性整流激活函数,每个反卷积层包含反卷积操作、特征图批量归一化以及线性整流激活函数。
所述线性整流激活函数采用带泄露线性整流函数,其负值区域斜率为0.2。
所述判别器采用patchgan模型对生成的图像进行判别,将需判断的图像与金标准拼接后,经过多个卷积层,将图像分成若干个n*n大小的区域,之后对每一个区域进行真实性判别,最终将所有结果进行平均汇总,得到整个图像最终的真实性概率。
本发明所达到的有益效果:通过对图像进行水平或垂直翻转,来增大训练数据集,可以保证后续网络训练的有效性与准确性;针对icga图像选取合适的误差函数,可以显著提高分割结果的准确性,采用unet网络结构用于生成器,可以使生成的图像具有更好的细节信息,更加接近于真实图片,选择patchgan模型作为判别器进行判别,可以显著提高运算速度,同时不影响判别器的准确性。
附图说明
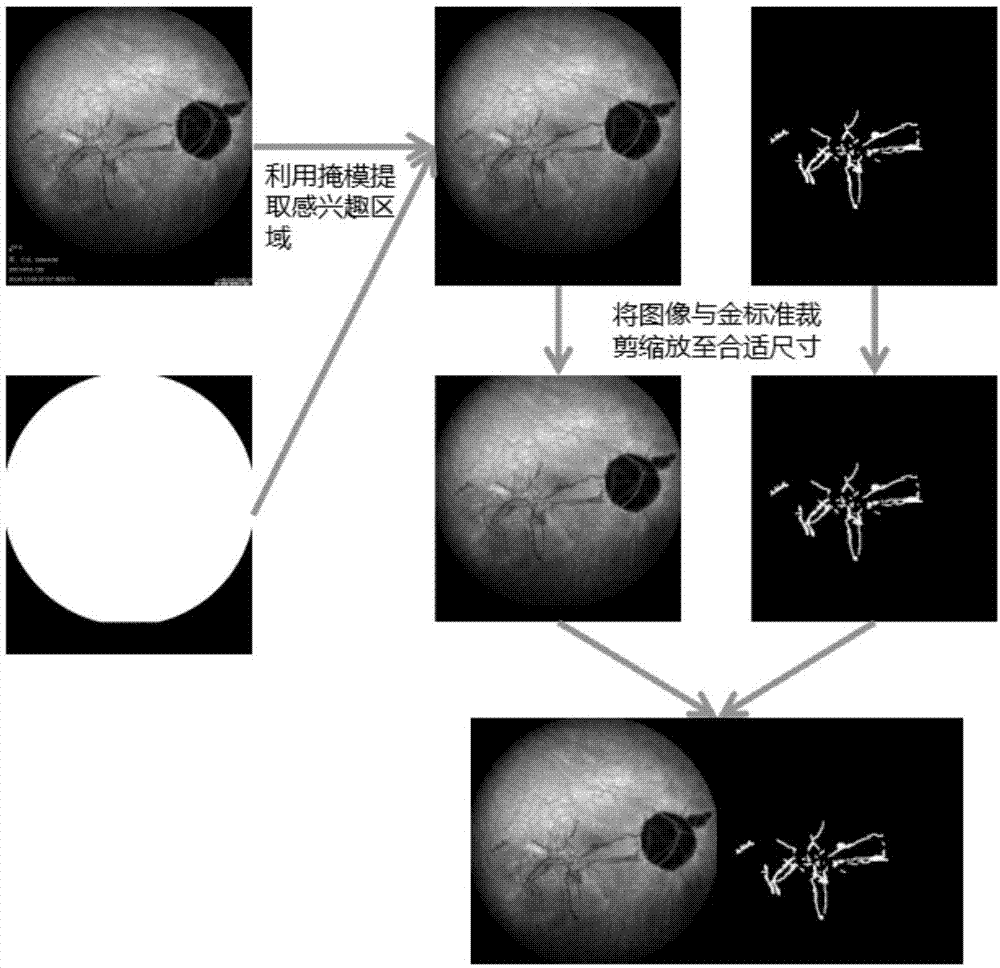
图1是本发明中图像数据处理示意图;
图2是本发明中数据扩增示意图;
图3是本发明中条件生成式对抗网络结构示意图;
图4是本发明中生成器结构示意图;
图5是本发明中辨别器结构示意图;
图6是本发明实施例中部分测试集实验结果。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
1.数据准备
数据准备流程如图1所示。首先从原始icga造影图像中提取得到图像感兴趣区域掩模。通过该掩模可以去除掉原始图像下半部的文字信息,留下完整的眼底造影图像。接着对完整的眼底造影图像进行金标准标注。由于原图像下方有整块黑色区域不包含任何图像信息,因此对眼底图像和金标准分别裁剪至768×768像素大小后再缩放至256×256像素大小,以便于后续条件生成式对抗网络对图像的卷积操作。最后将眼底图像与标注的金标准拼接起来结合成一幅256×512的图像,作为一组数据准备完成。
2.数据扩充
漆裂纹病样大多只在造影图像上有所显现,而造影图像相较眼底彩照与oct图像来说拍摄过程较为复杂,因此漆裂纹样病例图像数量十分有限。为了保证训练所得的生成网络的有效性与稳定性,我们需要对原有的数据进行扩增。
鉴于眼底造影图像的基本特征,我们仅对组合后的图像进行水平翻转与垂直翻转。在保证图像中视盘位置和血管方向等基本特征合理的情况下,适当的扩大训练数据,以提高模型泛化能力。
3.算法模型
3.1目标
我们使用条件生成式对抗网络对训练集数据进行训练。条件生成式对抗网络实质上是对原始的生成式对抗网络进行的一个扩展。
gan主要用于在数据量缺乏的场景下,帮助生成数据,提高数据质量。生成对抗网络由生成器和判别器组成。以图像生成来说,生成器的目标就是生成一张真实的图片,而与此同时判别器的目标则是判断一张图片是生成出来的还是真实存在的。这个场景也可以映射成图片生成器和判别器之间的博弈:首先生成器生成一些图片,紧接着判别器学习区分生成的图片和真实的图片,然后生成器根据判别器改进自己,生成新的图片,如此循环往复。cgan的原理和gan一致,不同之处在于生成器和判别器都增加额外信息作为条件,来约束生成图像。
在漆裂纹分割的问题中cgan会根据训练数据中的金标准来通过随机噪声生成各种各样类似漆裂纹分割结果的图像,而每一组数据的原始图像则相当于是对生成出漆裂纹图像的约束,使得生成出来的漆裂纹图像能与原始图像相匹配,这样也就达到了从原始图像中分割漆裂纹的目标。
对于这样一个从原始图像翻译出分割结果的任务来说,生成器g的输入部分是眼底造影图像x和随机向量z,输出的是生成的分割结果g(x,z)。判别器d部分接收的是生成的分割结果g(x,z)或金标准y,输出的是图像真实性的概率。这样使生成器和判别器联手,不断地调整g和d,直到判别器不能把生成的结果与金标准区分出来,这时生成器就能直接生成我们需要的分割结果。因此cgan的损失函数可以表示为:
在调整过程中需要优化d,使它尽可能判别出生成的图片不是真实的,也就是让l(g,d)最大;同时需要优化g,使它尽可能让d混淆,也就是让l(g,d)最小。
另外,在图像分割任务中,输入x和输出y之间共享了许多图像信息,输入x相当于对输出结果进行了约束。因此为了保证输入图像和输出图像之间的相似度,我们还加入了l1损失函数:
由于在眼底造影图像中,所需分割的目标漆裂纹所占整个图像的比例较小,因此在训练过程中,图像的目标像素数量与背景像素数量之间存在不平衡的问题,会导致最终的分割结果倾向于数量较多的一方,为了有效缓解该数据不平衡问题,我们在最终的损失函数中还加入了dice损失函数:
所以总体的损失函数为:
其中x为眼底造影图像,y为金标准,z为随机向量,n为图像中总像素个数,i表示1-n之间的整数,d(x,y)表示判别器对实际造影图像金标准的真实性判别概率,用0-1来表示,1表示图像100%为真实图像,0表示图像100%为合成图像;g(x,z)表示生成器根据造影图像与随机向量所生成的分割结果;
d(x,g(x,z))表示判别器对一组生成器生成图像的真实性判别概率,用0-1来表示,1表示图像100%为真实图像,0表示图像100%为合成图像;yi表示造影图像金标准中第i个像素的灰度值,灰度值范围在0-255之间;g(x,z)i表示生成器生成的分割结果中第i个像素的灰度值,灰度值范围在0-255之间,ex,y~pdata(x,y),z~pz(z)[]表示x,y均属于造影图像与金标准数据集且z服从随机分布情况下的具体期望值;μ和λ分别为l1损失函数和dice损失函数的权重系数,通过实验测试,本方法中取μ为100,λ为200。
3.2网络结构
对于生成器,我们采用u-net结构以生成细节更好的图片。u-net是德国freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先下采样到低维度,再上采样到原始分辨率的编码-解码网络结构相比,u-net还在编码器和解码器之间加入了跳跃连接,将下采样时每一层的特征图与上采样时同样大小的特征图按通道拼接在一起,用来保留不同分辨率下像素级的细节信息,使得解码器可以更好地修复图像目标细节。这也使我们的cgan中的生成器生成的图像具有更好的细节信息,更加接近于真实图片。
图4展现了本实施例中生成器的网络结构,其中ck表示了一个有k个卷积核的卷积层或反卷积层。cdk表示了一个有k个卷积核,dropout率为50%的卷积层或反卷积层,其中dropout是舍弃掉该层部分的卷积和,来防止训练时过拟合的现象。每一个卷积层依次包含了卷积操作、特征图批量归一化以及线性整流(relu)激活函数。反卷积层则包含了反卷积操作、特征图批量归一化以及relu激活函数。所有激活函数均采用带泄露的relu函数,其负值区域斜率为0.2,本网络结构抛弃了传统网络结构所使用的池化层,而将卷积核的卷积步长改为2,以达到逐级压缩图像维度的效果。
对于判别器,我们采用了patchgan模型来对生成的图像进行判别。patchgan的思想是,由于gan只负责处理图像的低频部分,因此判别器没有必要以一整张图像作为输入,而只需要对图像的每一个n*n大小的部分去进行判别。这样做的好处是使得判别器中输入图像的维度大大降低,参数数量减少,运算速度也大大提升,同时不影响判别器的准确性。
图5展现了本实施例中判别器的网络结构,其中ck表示了一个有k个卷积核,batch为标准化大小,激活函数为relu的卷积层。第一层256*256*6的图像是将所需判断的图像与输入图像进行拼接而得到。经过5层和生成器中类似的卷积层后,得到了30*30*1的图像,其中每个像素的视野域为70*70,即每个像素体现了原图对应位置上一个70*70大小的局部图像真实性概率,以达到patchgan的判别目的。
4.实验结果
我们将准备好的80组训练数据输入搭建好的模型中进行训练,将训练所得的模型保存后对测试集进行测试。部分实验结果如图6所示(第一列为预处理后的眼底造影图像;第二列为算法模型得出的分割结果;第三列为金标准)。从结果中可以看出,我们构建的模型在造影图像上可以较好地分割出漆裂纹部分。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!